Martin T. : Pump.io, un nouveau réseau social libre et décentralisé
mardi 2 avril 2013 à 13:55Faut-il encore présenter StatusNet ? Il est généralement considéré comme le clone libre et décentralisé de Twitter de référence. Une réussite toute relative comparé au nombre d’utilisateurs sur la version propriétaire mais un bon succès quand même par rapport aux autres projets libres du genre. Cependant, pour Evan Prodromou, son créateur, il était temps d’avoir quelque chose de nouveau et plus moderne. Il est donc passé de PHP à NodeJS, de MySQL à NoSQL, de Gitorious à Github et a créé Pump.io. Les concepts de fonctionnement sont légèrement différents : StatusNet est clairement calqué sur Twitter avec la limite de 140 caractères alors que Pump utilise un formatage riche en wysiwyg sans limite de taille, le tout à la sauce Bootstrap. Cependant le public StatusNet est visé puisqu’une migration forcée d’identi.ca (instance de StatusNet rassemblant une très grosse partie des utilisateurs) vers Pump est prévue en avril. La messe étant dite, faisons une présentation de ce nouveau venu.

Avec un nom pareil, je trouve quand même que ça part mal.
Protocole
J’avais parlé de ce problème dans mon article précédent : Pump n’utilise pas OStatus (le groupe de protocoles utilisé par StatusNet) et ne sera donc pas compatible avec ce dernier. C’est nul, je sais. Cependant les standards utilisés ne diffèrent pas trop non plus. Les activity streams sont au cœur du réseau (déjà présents dans OStatus sous forme XML mais l’on va encore plus loin cette fois). Activity Stream est un standard initié par Facebook, Google, Microsoft (et plein d’autres gens bien) pour unifier la façon de représenter des actions sur les réseaux sociaux et faciliter l’interopérabilité. Un message d’un serveur Activity Stream à un autre est par exemple :
{
"id": "http://coding.example/api/activity/bwkposthw",
"actor": {
"id": "acct:bwk@coding.example",
"displayName": "Brian Kernighan",
"objectType": "person",
"url": "http://coding.example/bwk"
},
"verb": "post",
"object": {
"id": "http://coding.example/api/note/helloworld",
"content": "Hello, World!"
"objectType": "note"
},
"published": "1973-01-01T00:00:00"
}
Dans pump, une activité est authentifiée via OAuth, ce qui permet de séparer complètement l’authentification du contenu
POST /api/user/bwk/feed HTTP/1.1
Host: coding.example
Authorization: OAuth oauth_consumer_key="[...]",
oauth_token="[...]", [...]
Content-Type: application/json
{
"verb": "follow",
"object": {
"id": "acct:ken@coding.example",
"objectType": "person"
}
}
C’est simple et clair. Un exemple assez sympa de proof of contest est openframgame.com. C’est un site très simple de simulation de ferme. Vous avez de l’argent avec lequel vous achetez des parcelles, des semences et de l’eau. Vous plantez des semences, vous arrosez vos plantes et les revendez une fois atteinte la maturité. Rien de très intéressant dans le fonctionnement interne mais là où ça peut être intéressant est qu’il communique avec un compte Pump via des activty streams. Le fait que votre plante ait soif ou que vous ayez revendu une parcelle de tomates est une activité envoyée au serveur. Vous pourriez ainsi prévoir des réactions automatisées comme l’envoi de l’action d’arroser lorsque une plante a soif ou poster un message de victoire dès votre premier million amassé. On peut facilement imaginer les nombreuses possibilités si certains services utilisaient le couple activity streams – PubSubHubbub. En parlant de PuSH, Evan a annoncé dans un status vouloir l’intégrer dans pump.io.
Pourquoi pas du RSS (l’enfant pauvre et délaissé du web actuel) me diriez-vous ? Je ne suis pas dans la tête d’Evan mais il a un jour fait une réflexion disant que si Google abandonnait Google Reader (et donc le RSS), c’était sans doute car le RSS est très primitif. Pas de principe de conversation, on reste dans un schéma de producteur-consommateur qui ne correspond pas web social actuel. Personnellement, je ne pense pas que le RSS soit dépassé (car le schéma producteur-consommateur convient très bien à certains types de contenu) mais le rejoins sur le fait qu’il n’est pas adapté aux réseaux sociaux. Un flux public en RSS pour suivre les messages d’une personne peut être utile (je l’avais suggéré) mais ne doit pas être le protocole central pour l’interaction (ce qui était le cas dans StatusNet).
Ce qui est génial avec cette utilisation des activity streams est qu’il n’y a plus de formats différents pour l’API publique, la communication entre serveurs ou le flux d’un utilisateur : tout est activité (ou liste d’activités) au format JSON. J’envoie une activité (après authentification avec OAuth) avec le verbe « follow » à mon serveur pour donner l’ordre de suivre quelqu’un et je reçois en réponse, en cas de succès, l’activité qui apparaîtra dans mon flux. Même l’interface web est en fait un client web utilisant des activités avec le serveur. La plupart des actions (par exemple l’enregistrement d’un nouvel utilisateur) se fait via des activités.
Je vous laisse lire la page API.md pour plus de détails mais cela explique bien le fonctionnement général. C’est simple et propre, j’aime.
Tester
À quoi ressemble ce service ? C’est très facile, allez sur la page Try it qui vous redirigera aléatoirement vers une des 10 instances déployées par Evan. Contrairement à StatusNet qui avait identi.ca comme point central du réseau (au point où les gens confondaient parfois les deux et certains clients ne supportaient qu’identi.ca), Evan a voulu que Pump fonctionne réellement comme une fédération d’instances décentralisées.
Inscrivez-vous sur une instance, suivez d’autres gens (en passant par Login -> Account on another server? dans le cas d’utilisateurs sur d’autres serveurs), envoyez des messages et des images. On n’a pas encore toutes les fonctionnalités de StatusNet mais ce n’est pas loin.
Installation
Bon fini de rire, comment on déploie son instance sur son serveur ? Bonne nouvelle : il est assez simple de faire tourner un site en NodeJS. Mauvaise nouvelle : pour ceux qui font tourner plusieurs services sur une même machine via Apache ou Nginx, déployer Pump risque de vous poser des problèmes. Votre serveur web habituel écoutant sur le port 80 ou 443, il y a conflit avec NodeJS voulant écouter sur le même port.
Plusieurs possibilités s’offrent à vous :
- utiliser pump seul sur le port 80 ou 443 (pas pratique)
- utiliser pump sur une IP interne ou différente de celle utilisée par Apache/Nginx (pas facile, peut être fait en utilisant une machine virtuelle par exemple, configuration ici pour apache et ici pour nginx)
- utiliser un port différent pour NodeJS avec un proxy redirigeant vos connexions vers le port 80 (perte de performance)
Il faut savoir que NodeJS a une bonne gestion de la concurrence ce qui lui permet, entre autres, de si bons benchmark. En utilisant un proxy, vous empêchez cette concurrence et réduisez les performances de Node à celles d’Apache. C’est dommage mais pas insurmontable non plus.
Après recherche, j’ai finalement trouvé deux systèmes fonctionnant pas trop mal avec Varnish (système de cache) et Apache : soit tout fonctionnant sur le port 80 avec Varnish servant de proxy, soit avec Pump écoutant sur le port 443 et Apache sur le port 80. Voulant utiliser du SSL pour pump, j’ai choisi la deuxième solution avec un certificat CaCert. Ci-dessous les explications des deux méthodes :
Tout sur le port 80
Première méthode : on n’utilise pas de SSL et fait tout tourner sur le port 80. Pour cela, j’utilise Varnish pour faire la différence, en m’aidant de ce tutoriel.
Configurez Varnish pour écouter sur le port 80 en modifiant le fichier /etc/default/varnish
DAEMON_OPTS="-a :80 \\
-T localhost:6082 \\
-f /etc/varnish/default.vcl \\
-S /etc/varnish/secret \\
-s malloc,256m"
Créez le fichier /etc/varnish/default.vcl pour indiquer la redirection
backend apache {
.host = "127.0.0.1";
.port = "6001";
}
backend node {
.host = "127.0.0.1";
.port = "6002";
}
sub vcl_recv {
if(req.http.host == "pump.mart-e.be") {
set req.backend = node;
} else {
set req.backend = apache;
}
if (req.http.Upgrade ~ "(?i)websocket") {
return (pipe);
}
}
sub vcl_pipe {
if (req.http.upgrade) {
set bereq.http.upgrade = req.http.upgrade;
}
}
En cas de domaine contenant « pump.mart-e.be », on redirige vers le port 6002, autrement vers le port 6001. Les commandes avec « pipe » étant pour permettre le fonctionnement des websockets à travers Varnish. Il vous faudra ensuite faire écouter Apache sur le port 6001 au lieu de 80 en modifiant le fichier /etc/apache2/ports.conf.
NameVirtualHost *:6001 Listen 6001
et en changent tous vos
En ce qui concerne pump en lui même ce n’est pas trop compliqué. Le fait qu’on utilise le port 6002 pour pump vous permet de lancer node avec un utilisateur non-root. Pump ne fonctionne pas (encore) bien avec la version 0.10 de NodeJs (il manque même certaines dépendances je pense), préférez donc la 0.8. Comme pump.io est encore en développement actif, on préférera la version git à mettre à jour régulièrement. Les explications ci-dessous utilisent mongodb mais vous pouvez utiliser un autre service tel que Redis ou même laisser le « disk » par défaut pour ne pas avoir de base de donnée (attention aux performances).
# git clone https://github.com/e14n/pump.io
# cd pump.io
# npm install
# cd node_modules/databank
# npm install databank-mongodb
Utilisez le fichier pump.io.json.sample pour créer le fichier /etc/pump.io.json. Voici le mien :
{
"driver": "mongodb",
"params": {"host": "localhost", "port": 27017},
"secret": "azerty12345",
"noweb": false,
"site": "pump-e",
"owner": "mart-e",
"ownerURL": "http://mart-e.be",
"port": 80,
"serverUser": "www-data",
"hostname": "pump.mart-e.be",
"address": "127.0.0.1",
"nologger": false,
"uploaddir": "/var/www/pump/uploads",
"debugClient": false,
"firehose": "ofirehose.com"
}
Installez bien le paquet mongodb et démarrez le démon (ici sur le port 27017). N’oubliez pas non plus de créer le dossier uploaddir mentionné. Lancez pump via
ou utilisez la commande forever (npm install -g forever) pour quelque chose de plus stable. Si vous sauvegardez les logs dans un fichier, vous pouvez les consulter via bunyan (npm install -g bunyan et puis tail -f pumpd.log | bunyan), ça en facilitera grandement la lecture.
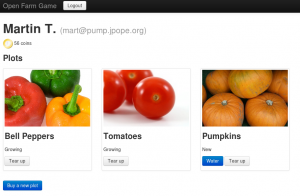
Et ceci était un des premiers services à interagir avec pump, c’est beau !
Pump en SSL
La config précédente est bien, mais c’est encore mieux si on utilise du HTTPS ! Trouvez-vous donc un certificat SSL (openssl req -nodes -new -keyout server.key -out server.crt) et envoyez-le sur votre serveur. Comme on ne veut pas produire de page d’erreur quand les gens essayent d’accéder à pump en HTTP, on va utiliser Varnish pour faire une redirection, status HTTP 302. Le fichier /etc/varnish/default.vcl devient donc :
backend apache {
.host = "127.0.0.1";
.port = "6001";
}
sub vcl_recv {
if(req.http.host == "pump.mart-e.be" && req.http.X-Forwarded-Proto !~ "(?i)https") {
set req.http.x-Redir-Url = "https://pump.mart-e.be" req.url;
error 750 req.http.x-Redir-Url;
} else {
set req.backend = apache;
}
if (req.http.Upgrade ~ "(?i)websocket") {
return (pipe);
}
}
sub vcl_error {
if (obj.status == 750) {
set obj.http.Location = obj.response;
set obj.status = 302;
return(deliver);
}
}
sub vcl_pipe {
if (req.http.upgrade) {
set bereq.http.upgrade = req.http.upgrade;
}
}
Attention, si vous avez la version 3 ou plus de Varnish (dans Debian stable c’est encore la 2), la concaténation se fait avec un +, la ligne de calcul d’URL devient donc : set req.http.x-Redir-Url = "https://pump.mart-e.be" + req.url;
Varnish ne gère pas le trafic SSL donc on est obligé de rester sur le port 80 pour ce dernier.
Rien de change du coté d’apache (par contre faites bien attention dans le fichier ports.conf de ne pas écouter sur le port 443) mais le fichier de config de pump devient :
{
"driver": "mongodb",
"params": {"host": "localhost", "port": 27017},
"secret": "monkey1",
"noweb": false,
"site": "pump-e",
"owner": "mart-e",
"ownerURL": "http://mart-e.be",
"port": 443,
"serverUser": "www-data",
"hostname": "pump.mart-e.be",
"address": "pump.mart-e.be",
"nologger": false,
"uploaddir": "/var/www/pump/uploads",
"debugClient": false,
"firehose": "ofirehose.com",
"key": "/etc/ssl/server.key",
"cert": "/etc/ssl/server.crt"
}
Notez que le champ « address » est passé de 127.0.0.1 à pump.mart-e.be. Sans cela, je n’ai pas réussi à accéder à mon serveur depuis l’extérieur. Ajoutez également l’URL de votre serveur pump (pump.mart-e.be ici) dans le fichier /etc/hosts pointant vers 127.0.0.1. Ainsi, la boucle est bouclée pour l’accès en local.
Via mes tests, j’ai noté que les serveurs semblaient retenir les précédentes informations de connexion. C’est-à-dire que les serveurs avec lesquels j’avais interagi à l’époque de mauvaises configs ou lorsque je tournais sur le port 80 semblent avoir retenu ces infos et je n’arrive plus à les contacter. J’ai ouvert un bug report à ce sujet. En attendant que cela soit réglé, faites bien attention de choisir votre mode de connexion et de vous y tenir.
Les clients
C’est bien beau d’avoir une bonne API mais qu’en est-il des clients externes ? Hélas, on n’en est qu’aux débuts. Il existe actuellement une librairie en python PyPump, utilisée par Muon, un client ncurse l’utilisant. C’est tout à ma connaissance…
Le fonctionnement de l’API semblant assez simple, ça ne devrait qu’être une question de temps avant l’apparition de plus de clients mais actuellement c’est un frein certain à l’adoption de pump. Si vous voulez recevoir la reconnaissance de toute une communauté (1170 personnes aux dernières nouvelles), c’est l’occasion rêvée pour faire un peu de développement !
Les services externes
Si vous voulez passer à Pump, une fonctionnalité intéressante est les bridges avec les autres réseaux. C’est dans ce but que pump2status a été créé. Pour l’instant, ce site vous permet de lier votre compte pump à votre compte StatusNet et vous permet de découvrir les gens ayant fait la transition (comme moi !). Dans le futur, ce site vous permettera de publier sur StatusNet vos activités Pump. Sont également prévus, par ordre de priorité et hackerliness Google+, Twitter, Facebook sans doute même des Foursquare, LinkedIn et Instagram plus tard. En raison du bug des anciennes configs mémorisées, pas certain que vous me trouverez (si vous voyez mart@pump.jpope.org, c’est mon compte de test, je ne devrais plus l’utiliser).
Là où Status.Net englobait un maximum de fonctionnalités, le but de Pump.io est d’être beaucoup plus minimaliste dans son mode de fonctionnement et de se baser sur des services externes. Les fonctionnalités de gestion du spam sont par exemple déléguées à activityspam (dont spamicity.info est une instance, wiki) ou le service OFireHose est utilisé pour faciliter la fédération du contenu public (dont ofirehose.com est une instance).
Les passerelles fonctionneraient avec ce même principe. On pourrait ainsi avoir une application externe s’occupant de récupérer du contenu venant de Twitter et de le convertir en activités poussées vers un compte pump. C’est une des possibilités parmi d’autres mais le principe reste d’utiliser des services externes.
L’idée (pas mauvaise) est de garder le coeur de Pump.io minimale pour avoir quelque chose de robuste et hack-friendly. Mon seul regret est l’absence d’extensions, je ne suis pas certain que le modèle de services externes fonctionne dans tous les cas de figure (pour une modification des templates par exemple).
Le futur
Dans une présentation datant de février dernier, Evan annoncait vouloir migrer les serveurs identi.ca de Status.Net vers pump.io en avril 2013. Les inscriptions sur identi.ca sont bloquées depuis quelques jours. On verra si ça pourra se faire mais je pense que le logiciel n’est clairement pas encore assez mature pour faire la transition aujourd’hui.
Vous en avez rêvé, e14n n’a fait : le bouton « Je n’aime pas » !
Un des soucis potentiel est que la transition casserait tous les clients Status.Net (n’utilisant plus l’API à la Twitter). Une possibilité serait de maintenir une compatibilité avec un bridge entre les deux. J’avais vu cette suggestion faite par Evan (mais n’arrive plus à retrouver le lien). Cela faciliterait grandement les choses le temps de la transition.
Si la sauce prend bien, Evan espère voir les gens adopter massivement pump.io et développer pour celui-ci. Les possibilités d’utilisation du réseau sont assez larges et intéressantes. Openfarmgame était une démo simple. Ih8.it en est une autre. On pourrait même imaginer des analyses globales des comportements via les publications poussées sur ofirehose (de la pub ?). Les principes de fédérations semblent bien réfléchis, et l’on devrait éviter les travers rencontrés avec StatusNet et identi.ca.
Si vous ne voulez pas passer à Pump.io (parce que ça ne correspond pas à ce que vous cherchez), faites une sauvegarde de votre compte identi.ca et utilisez Status.Net sur une autre instance (c’est le moment de passer à l’auto-hébergement). N’oubliez pas, ce n’est pas parce qu’identi.ca et Evan passent à Pump.io que la communauté est obligée de suivre. C’est du libre après tout.
Pump est encore un peu jeune mais néanmoins déjà utilisable. Essayez-le, faites-vous un avis et choississez ensuite si vous voulez rester sur StatusNet ou passer à Pump (ou utiliser les deux ou aucun). Je ne compte pas encore remplacer mon compte StatusNet par Pump mais ça sera sans doute le cas un jour (et me permettra d’abandonner définitivement mon compte Friendica inutilisé). En tout cas, espérons que ce réseau ne soit pas encore « un parmi tant d’autres ».
Original post of Martin T..Votez pour ce billet sur Planet Libre.

Articles similaires
- Martin T. : Les API mortes se ramassent à la pelle (04/03/2013)
- theClimber : Un regard en avant vers GNOME 3.0 (02/04/2009)
- Planet Libre : Nouveau sur le Planet-Libre : les brèves de la semaine ! (13/02/2012)