Pour la 52ème semaine de l'année 2020, voici 12 liens intéressants que vous avez peut-être ratés, relayés par le Journal du hacker, votre source d’informations pour le Logiciel Libre francophone !
De plus le site web du Journal du hacker est « adaptatif (responsive) ». N’hésitez pas à le consulter depuis votre smartphone ou votre tablette !
Le Journal du hacker fonctionne de manière collaborative, grâce à la participation de ses membres. Rejoignez-nous pour proposer vos contenus à partager avec la communauté du Logiciel Libre francophone et faire connaître vos projets !
Et vous ? Qu’avez-vous pensé de ces articles ? N’hésitez pas à réagir directement dans les commentaires de l’article sur le Journal du hacker :)
Mon ordinateur est équipé de deux écrans. Par conséquent, j’ai fait en sorte que mon interface de bureau moulé à la louche, prenne en compte ce cas de figure. Dans un premier temps, j’ai utilisé le module multiprocessing. Cela me semblait être la solution idéale pour lancer simultanément un process sur chaque écran.
Seulement, il y a un léger problème. threading et multiprocessing rentrent en conflit avec des interfaces graphiques telles que tkinter. Le résultat final présente des signes d’instabilité qui ne sont pas du meilleur effet. En théorie, on peut utiliser multiprocessing avec tkinter mais toutes les interactions avec l’interface graphique doivent se faire par un seul et unique thread. Le module multiprocessing peut traiter des données et faire des calculs dans plusieurs threads, mais il ne peut pas « multithreader » tkinter! Les deux processus doivent être séparés.
Donc, dans un souci d’amélioration continue, je me suis mis en quête d’une solution alternative, et je pense avoir codé quelque chose qui répond à mes attentes en terme de stabilité, car même dans un projet amateur, il est important d’être ceinture-bretelles. Alors comment ai-je procédé? En fait, je suis parti de l’idée toute simple que pour deux écrans, il faut avoir non pas deux threads d’un même programme mais deux programmes! Et je voulais que tout le processus se déroule de manière automatique. Pas question pour l’usager, d’ouvrir un fichier de configuration pour en modifier le contenu. L’objectif était vraiment de coder quelque chose qui s’installe tout seul et qui vit sa vie sans intervention de maintenance. Mais comment faire pour donner l’illusion de lancer et d’arrêter deux threads?
Situation initiale
Voici la configuration initiale avec multiprocessing.
2. Suppression de multiprocessing, modification du code et explications détaillées
Au démarrage de l’ordinateur, le programme se lance grâce au fichier start.py dont le chemin se trouve dans ~/.config/openbox/autostart.
Ouvrons, si vous le voulez bien, le fichier lanceur start.py… La première opération exécutée par ce script consiste à détruire tous les fichiers et répertoires antérieurs qui ne correspondent pas à la configuration par défaut (en monomoniteur, si vous me permettez ce néologisme). Il est nécessaire de partir sur une base propre:
Version standard monomoniteur
Pourquoi détruire la configuration multi-écrans à chaque démarrage? Eh bien parce que l’utilisateur peut très bien décider, un beau matin, de suppprimer un écran ou d’en rajouter un troisième. Je ne suis pas dans sa tête et je ne connais pas ses intentions.
Ensuite, vient le moment de déterminer le nombre de moniteurs. Plutôt que de compter avec ses doigts, confions cette tâche à la commande suivante:
Je crois que c’est clair… Maintenant, le programme va créer autant de répertoires qu’il y a de moniteurs supplémentaires, et il va copier le contenu de labortablo dans chacun d’entre eux. Si vous avez quatre écrans, il va donc créer en sus de labortablo (qui est en quelque sorte le « répertoire zéro« ):
labortablo_1
labortablo_2
labortablo_3
Nous nous retrouvons donc avec cette configuration:
Version quadrimoniteur
Voici la ligne de code qui effectue cette opération:
if i > 0:
shutil.copytree(
f'{self.cwd}/labortablo',
f'{self.cwd}/labortablo_{i}'
)
De cette manière, si je veux apporter des modifications au code avant de le pousser dans mon dépôt Git, il me suffit de modifier labortablo, le « répertoire zéro ». Je sais qu’au prochain démarrage, les modifications seront prises en compte pour tous les autres programmes.
Ensuite le script start.py se charge de traiter les informations relatives aux écrans. Puis, il créé un fichier coords.txt pour chaque interface de bureau. Ce fichier est construit de telle sorte qu’il puisse se transformer très facilement en dictionnaire. Je trouve que cette syntaxe facilite bien la vie.
Ainsi, je peux passer rapidement ces paramètres aux classes qui en ont besoin. Tous les éléments graphiques vont récupérer ces informations pour configurer l’interface de bureau de chaque écran.
args = dict()
with open('coords.txt', 'r') as rfile:
for line in rfile.readlines():
args[line.split(':')[0]] = int(line.strip().split(':')[1])
Le moment est venu de créer le fichier start.sh. Il va contenir tous les programmes à lancer et il sera détruit au prochain démarrage. Donc, dans le cas de figure ou il y a quatre écrans, voici à quoi ressemble ce script:
Alors, vous allez me dire qu’il ne s’agit pas d’un script Python. Par conséquent, je ne devrais pas affirmer que Labortablo est une interface de bureau entièrment codée en Python. C’est vrai. Je le reconnais. Mais je n’ai pas d’autres choix si je veux lancer mon métaprogramme. On peut très bien lancer des fichiers *.py à partir d’un fichier Python mais j’ai ouï-dire que ce genre d’hérésie conduisait tout droit au bûcher.
Avec Python, on lance des modules, pas des fichiers, et à ce stade des opérations, je ne peux pas car il faudrait que j’utilise threading ou multiprocessing. C’est le python qui se mord la queue!
Enfin, dernière opération, je rend le fichier start.sh exécutable. Il faut le faire à chaque fois car il est détruit à chaque démarrage. Puis start.sh est lancé par start.py.
Conclusion
J’ai bien conscience du fait que cette manière de procéder est loin d’être académique mais d’une part, je m’en fiche un peu, et d’autre part ça tourne comme une horloge. J’utilise cette interface de bureau tous les jours, non pas dans une machine virtuelle mais sur mon PC principal. Il faut encore que je lui rajoute la gestion des catégories et des applications (ajouts/suppressions). Il faut aussi que je fasse le point sur tout ce qu’il y a à installer pour faire tourner le programme (xrandr, wmctrl, xprop etc…)
Voilà… Je n’oublie pas de vous souhaiter un Joyeux Nowouel et une bonne vaccination à toutes et à tous.
When dealing with log management, obvious solutions emerge earlier, often before you even discussed the purpose of the log management. We can discuss about ELK, Graylog, Splunk, … Those are great tools but they may not fit will all your needs. Lately, I had to work for one of my customer on enforcing log management for billing purposed. Rsyslog was already set to collect and centralize all the logs (and manage their backups). MongoDB seemed as a perfect tips for storing JSON extract of the logs to generate the proper stats.
JSON (JavaScript Object Notation) is a lightweight data-interchange format. It is easy for humans to read and write. It is easy for machines to parse and generate. It is based on a subset of the JavaScript Programming Language Standard ECMA-262 3rd Edition - December 1999. JSON is a text format that is completely language independent but uses conventions that are familiar to programmers of the C-family of languages, including C, C++, C#, Java, JavaScript, Perl, Python, and many others. These properties make JSON an ideal data-interchange language.
On top of that format, we can used a more structured syntax, adapted to log management: CEE Log Syntax. This defined format is well used by various tools you might use, in the present case: nginx, rsyslog, and mongodb. Up to a certain level…
Nginx knows about @cee
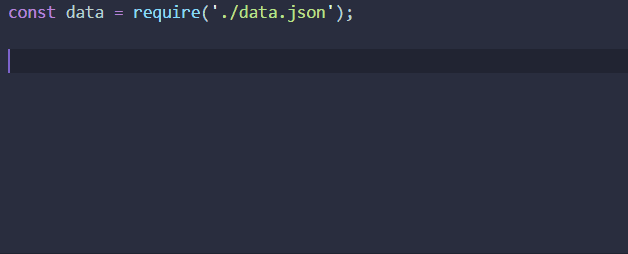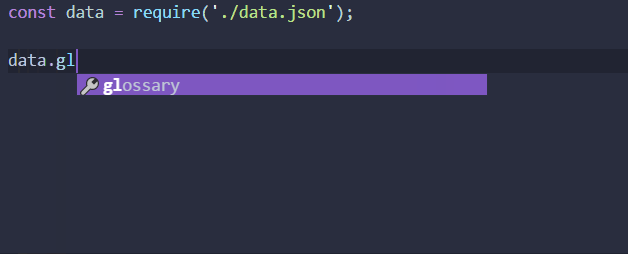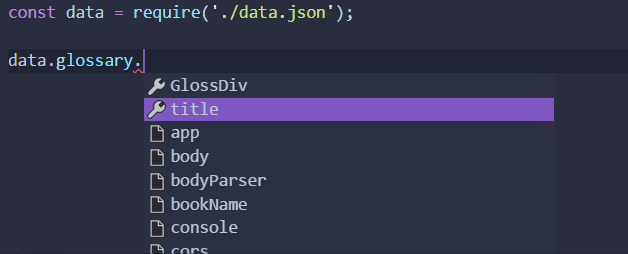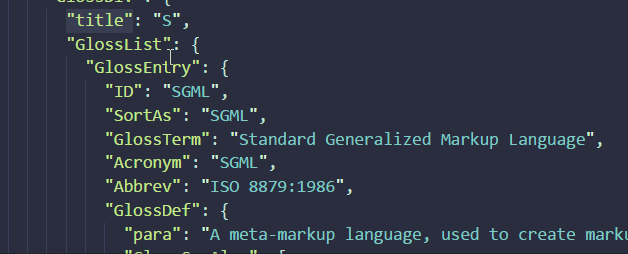
Sort of. Nginx has a native syslog export for both error_log and access_log. Out of the box, it will simply push all logs from the default log formats to syslog. This won’t be very convenient for proper management afterwards. But nginx is easy to use, and you can define your own custom format. You’ll find plenty of blogposts, tutorials, and others as Any IT here? Help me! describing the proper @cee JSON log format you need:
They all give you the very same structure. Not sure who started it, but that’s not the point: they’re all wrong about it!
I am this close - Terminator 2
They are close, indeed, but some details have to be fixed first. Why are they wrong? Because JSON, and especially the @cee version of it, has datatypes. Numbers (integers and floats) should not be encapsulated between quotes: quotes are for string only.
For sure, you can adapt the faciliy, the tag and the severity of it, along with the log format name.
Rsyslog is great. Its documentation is not.
That’s a fact, technical documentation, made by technical individuals, for technical persons, are not the best. Rsyslog might be one of the best example about this statement. Rainer Gerhards did a great work with his tool, one of the best syslog manager in my humble opinion. Thought, the documentation is a hell to read. Add to this fact, that it not as accurate as it should be.
In the use case I was working on, the infrastructure is benefiting from rsyslog v8-sable. And as stated, we want to use the mongodb exported, aka ommongodb. Seems easy and straight forward? Almost. But remember this IT mantra:
If all goes well, we forget something.
For reasons out of my mind while writing down this post, I can tell you that it just do not work. Several aspects are to be considering before dealing with those logs.
You need to ensure about the encodingi: BSON (the JSON variant mongodb uses internally) only supports valid UTF-8 character. For that, you need to properly fix the encoding before sending them. There is a module for that.
The structured @cee sent using the default configuration to mongodb will just push data “as-is”: first issue and main issue you’ll hit is about the date which will be pushed as a regular string.
But why? - Ryan Reynolds
Why? Simply because rsyslog only understand numbers and strings as datatypes on one end, and mongodb doesn’t auto detect date and timestamps on the other end. Is it an issue at the end? If you want to benefit from mongodb filtering features on dates, yes it is. For that purpose, you need to use the ISODate() functions that mongodb only knows about.
After a tremendous number of attempts, trying to deal with the documentation to find the proper format, I decided to read the ommongodb module source code. Pretty easy as it’s a well written C code:
/* Convert text to ISODATE when needed */if(strncmp(name,"date",5)==0||strncmp(name,"time",5)==0){
You’ve just read it well: the code does not expect the fieldname to start with a date or time, but it expect the fieldname to be date or time.
Two solutions there:
either update the log format, in nginx configuration, from time_iso8601: to date:
update your rsyslog configuration
I’m not found of the string exporter used in the default documentation of rsyslog for mongodb: we’re using JSON as an input, we expect JSON at the output, why should we use strings in between?
For that reason, I moved to a JSON manipulation, thanks to the JSON parse module, and list type for the template:
Following that changes, nginx logs are pushed to mongodb, allowing easy statistics aggregation for billing purpose. As we just want to push these lines to mongodb, best is to proceed with something like:
if ($syslogfacility-text == 'local7' and $syslogseverity-text == 'info') then {
action(type="mmutf8fix")
action(type="mmjsonparse")
action(type="ommongodb" uristr="mongodb://--REDACTED--:--REDACTED--@--REDATED--:27017/?authSource=logs&authMechanism=SCRAM-SHA-1" db="logs" collection="nginx" template="json-syslog")
& stop
}
The uristr is a bit different from the the documentation because, once again, the document is not really explicit enough about it. For most real-life scenarios, even if you use a mongodb cluster, you want to rely on dedicated database and dedicated user, with the proper set of permissions. To benefit from it, you need to add some details within the uristr as the user:password but also some query parameters:
authSource: the db to rely on for authentication, as you user has only permissons on it
authMechanism: you’re pushing a password via the dsn
At the end
We went through. We’ve set up nginx to push JSON @cee-compliant logs to syslog, then we prepare the logs to be properly pushed to mongodb, and we publish them.
Now our folks can run their micro-batching to generate live billing and usage statistics for the customers.
How would you have tackled this kind of need? Did you suffer from technical documentations not adequate or not uptodate?
Ha, « informatique », un mot qui fleure bon le siècle dernier. J'ai hésité avec numérique, avant de décider d'assumer pleinement le premier. En tout cas, on ne parlera pas de Covid dans ce billet (mince, trop tard).
Mon blogue
Il y a eu pas mal de nouveautés concernant mon blogue !
Tout d'abord je l'ai déménagé de Toile Libre (qui semble bloqué sur PHP 5.5) vers TuxFamily. Grâce à la simplicité et à la flexibilité du moteur de blogue PluXml, il m'a suffit de déplacer les fichiers composant mon blogue d'un espace à l'autre (à condition de faire attention à bien employer des URL relatives pour les éventuels liens internes au blogue).
Ensuite j'ai changé le sous-titre du blogue. Pour rappel, le sous-titre du blogue a longtemps été : bloc-notes d'un affranchi, en référence à l'époque où je n'utilisais pas encore de logiciels libres.
Je l'ai changé :
– une première fois, le 4 février 2014, pour Passer à GNU/Linux n'est pas une fin : c'est un commencement en m'inspirant de la formule d'un lecteur (otyugh),
– puis, le 1er novembre dernier, en logiciels libres, formats ouverts, libertés numériques & éducation pour être cohérent avec le fait que ce dernier thème fait désormais partie du blogue.
Car, et c'est sans doute le plus gros changement, cette année j'ai élargi la thématique du blogue pour publier également en lien avec mon métier de CPE. Notez que, pour ne rien vous imposer, j'ai tiré des flux RSS distincts.
Enfin, ceci expliquant cela, cela faisait longtemps que je n'avais pas publié autant ici. J'en suis à 18 billets cette année et il faut remonter à 2014 pour retrouver pareil nombre (j'ai bien conscience que ce nombre peut paraître faible : tout est relatif). Mieux, 13 billets ont été publiés au cours des deux derniers mois. C'est, en ce qui me concerne, une fréquence rarement (jamais ?) atteinte. Les nouvelles thématiques semble m'inspirer puisque, sur les 13 derniers billets, seulement 3 évoquent l'informatique.
Question hardware, mon PC fixe me convient tel qu'il est depuis un moment. Son cerveau a été changé il y a huit ans tout comme l'écran. Ne jouant pas, j'avais misé sur la sobriété pour tous les éléments, sauf la mémoire vive que j'avais prévue large par expérience (j'ai toujours assemblé mes PC depuis mon premier : un Pentium MMX 166MHz). Je sais que je devrais changer la pâte thermique de mon CPU mais la motivation me manque encore…
Côté smartphone, un sujet que je n'ai encore jamais abordé sur le blogue (j'utilise surtout les fonctions SMS, appareil photo et voix – dans cet ordre), j'en suis à mon quatrième. Après un ZTE OpenC sous Firefox OS, les suivants ont tous tourné sous LineageOS : Sony Xperia Z5 Compact, Samsung Galaxy A3 2017 et le petit dernier que je viens de recevoir, un Samsung Galaxy S5 (oui, oui, un modèle de 2014). Mes critères sont en général la qualité de l'appareil photo, l'autonomie, une taille raisonnable, et bien sûr la prise en charge de LineageOS. C'est une chute de trop (malgré leur étui de protection) qui m'a poussé à remplacer successivement les Xperia Z5 Compact (plus de mise au point de l'appareil photo) et Galaxy A3 2017 (hémorragie de cristaux liquides inondant l'écran). Pour des objets du quotidien, ces appareils sont très peu solides.
Mes projets
Je travaille sur un projet ambitieux, libre et gratuit, que j'aimerais bien voir se finaliser en début d'année prochaine. Des obstacles techniques et humains restent à franchir, nous verrons bien. J'en parlerai bien évidemment prioritairement ici si le projet aboutit.
Hommage à bloguelinux.ca
Je termine avec une pensée pour mes podcasts informatiques préférés qui s'arrêtent les uns après les autres : après Parole de Tux en 2014, c'est au tour de bloguelinux de tirer sa révérence. Deux podcasts qui avaient pour points communs Linux, l'humour et la bienveillance.
Cette année très particulière m'a quand même permis de consacrer plus de
temps pour le logiciel libre que l'an passé.
Mes efforts se sont naturellement dirigés vers les outils que j'utilise et c'est
Nextcloud et son écosystème sur lesquels je me suis concentré.
Mon plus gros projet de 2020 est Custom menu, une application pour Nextcloud qui
permet de modifier le menu par défaut en proposant d'autres affichages. Je suis
très content du résultat et beaucoup d'administrateurs ont décidé de l'installer
sur leur instance. En effet, toutes versions confondues, Custom menu a été
téléchargé plus de 102 mille fois et les dernières versions sont installées sur
environ 9000 instances.
J'ai réalisé du code pour faire évoluer l'application Forms on y ajoutant de
nouveaux types de champ. Cela n'a pas du tout été évident d'échanger avec
l'équipe de développement mais j'espère voir arriver ces évolutions dans une
prochaine version.
Ensuite, j'ai traduis Analytics en français même si je ne suis pas satisfait.
Je vais faire de nouvelles traductions l'année prochaine ! Cette application
permet de mettre en graphique des données stockées sur Nextcloud ou accessibles
depuis une API. C'est encore relativement basique mais c'est tout de même très pratique.
Même si le développement n'est pas très actif, j'utilise l'application Printer
et j'ai proposé du code pour gérer les permissions et réduire les risques
d'injection de code.
Dans un contexte très différent de Nextcloud, j'ai apporté un correctif au
projet PDNS Manager, une interface web qui permet de gérer les enregistrements
d'un serveur Powerdns.
J'ai récemment publié Mail RSS, une application pour transformer des
emails en flux RSS. Enfin, un peu plus tôt cette année, j'ai mis en ligne les sources du
site web qui permet de monitorer le terrarium de la maison.
Je crois avoir fait le tour de mon activité en espérant poursuivre en 2021 !