Framablog : Dégooglisons Internet : on publie les chiffres !
mercredi 14 décembre 2016 à 16:07Quelques semaines après le lancement de la 3e année de Dégooglisons (et des six nouveaux services qui l’ont accompagné), nous avons fait une photographie des statistiques d’utilisations (anonymisées, rassurez-vous ^^), afin de vous livrer un petit bilan de ce projet…
Des grands classiques qui marchent bien
On ne le cache pas, Framadate, notre alternative à Doodle, est le site le plus visité par chez nous. Avec 591 000 sondages créés depuis son lancement et plus de 1 100 sondages créés par jour, on peut dire que vous aimez planifier des choses en toute liberté !
Framapad (pour écrire collaborativement vos documents) n’est pas en reste. Mais, depuis que les pads que nous hébergeons s’effacent au bout d’un certain temps d’utilisation, il est difficile de donner des chiffres significatifs. Ah si, tiens : MyPads (qui vous permet de créer un compte pour avoir des pads permanents et d’en modérer l’accès), héberge à ce jour plus de 41 500 pads… Autant vous dire qu’on a un serveur en béton (et un admin-sys super-saiyan) !

Luc, gardant son calme face aux nombre de pads sur le serveur MyPads (allégorie)
Photo CC-BY-SA Hikaru Kazushime
À leurs côtés, Framacalc (les feuilles de calcul collaboratives) et Framindmap (pour travailler à plusieurs sur des cartes heuristiques) feraient presque figure d’outsiders. Sauf qu’ils sont respectivement les 4e et 3e services les plus visités de notre réseau, avec plus de 105 000 comptes et 133 000 cartes heuristiques créées par vos soins sur Framindmap !
Des outils pratiques et pratiqués
Ça a été dur de choisir parmi tous les services existants. Donc on a choisi de vous en dire le plus possible. Prêt⋅e⋅s pour une liste à la Prévert (en moins poétique car plus chiffrée…) ?
Ok, c’est parti !
- Visiblement, vous aimez dessiner sur la géographie, vu qu’il y a eu 403 comptes et plus de 5 800 cartes créées sur Framacarte.
- Avec 5 084 comptes et 1,1 To de données synchronisées, Framadrive (notre alternative à Dropbox) affiche complet… Mais nous ne désespérons pas de trouver une solution (peut-être même qu’une est en cours de route…). Et, pour plus d’espace disque, vous pouvez toujours prendre un compte chez IndieHosters qui nous aide à maintenir ce service, ou chez un autre des CHATONS…
- Par contre, notre lecteur de flux RSS Framanews ne fera pas mieux : 500 utilisateurs et utilisatrices y synchronisent et consultent déjà plus de 10 800 flux RSS.
- Avec 11 420 comptes créés, Framabag (l’alternative à Pocket) vous permet de conserver vos articles préférés dans la poche. Pensez à soutenir les créateurs du logiciel Wallabag en prenant directement un compte à prix modique chez eux. Vous pourrez ainsi bénéficier d’une nouvelle version majeure avec plus de fonctionnalités !
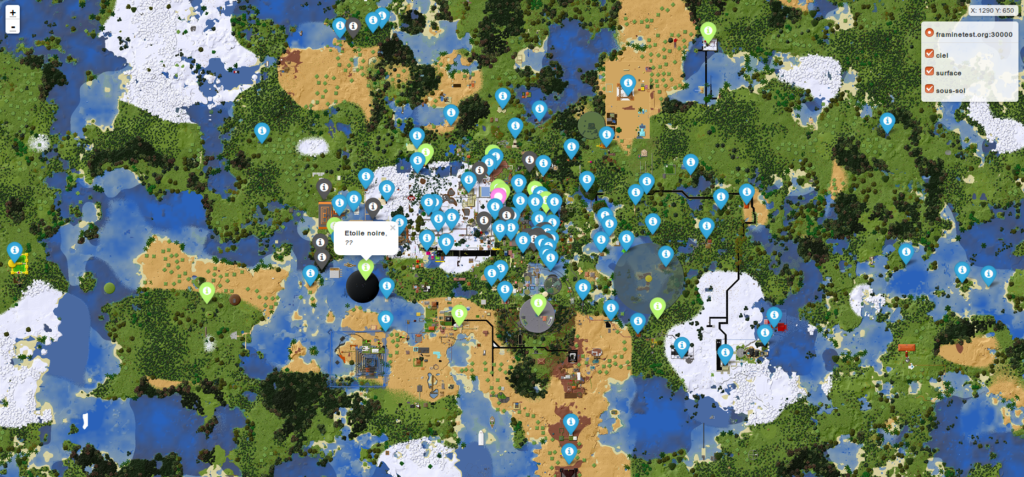
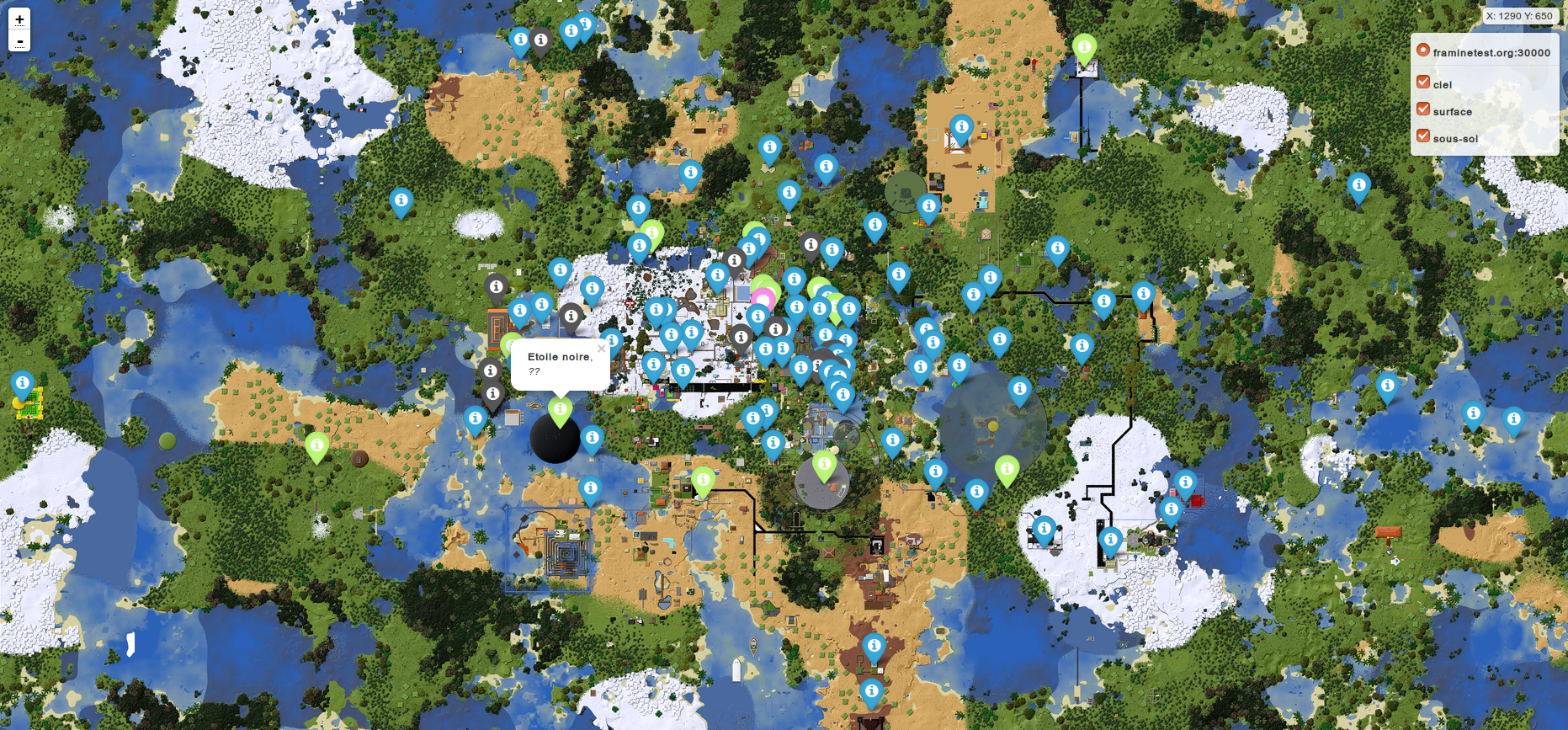
Prenons une pause au milieu de tous ces chiffres pour admirer la carte de vos créations sur notre serveur Framinetest, une alternative à Minecraft
- Framadrop est un cas particulier : cette alternative à WeTransfer (le chiffrement en plus) efface automatiquement les fichiers après que vous les aurez partagés. On ne peut donc que vous donner des instantanés ! À l’heure où nous préparons cet article, vous échangez plus de 48 000 fichiers pesant 874 Go…
- Framapic, notre hébergeur d’images, permet lui aussi un effacement au bout de X temps. Actuellement, c’est plus de 141 800 images qui sont sur nos serveurs.
- Frama.link raccourcit d’ores et déjà 46 900 URL (adresses web) bien trop longues, et ce, nous l’espérons, de manière aussi fiable que durable.
- Vous aimez discuter dans vos groupes : Framateam (l’alternative à Slack et aux groupes Facebook) vient de franchir la barre des 10 000 utilisateurs et utilisatrices, se partageant pas loin de 2 770 équipes, et plus de 734 000 messages. Chez Framasoft, nous l’utilisons beaucoup, mais de là à dire que les plus bavard⋅e⋅s d’entre nous seraient à l’origine de 42 % des messages, ce serait un mensonge :p.
- Enfin Framavox, qui vous sert à prendre des décisions en équipe, compte désormais plus de 1 500 groupes où se répartissent 3 626 personnes. Alors, c’est-y pas jubilatoire d’avoir un outil de prises de décisions transversales ?
Les petits nouveaux ne sont pas en reste !
En septembre, avant de fêter les deux ans de Dégooglisons, nous avons tout de même sorti deux services : Framinetest Édu (une alternative à Minecraft Éducation, dont vous avez vu la carte plus haut), et Framémo. Ce petit tableau pour organiser ses idées collaborativement, en direct et en ligne, remporte une fière adhésion, puisqu’en moins d’un trimestre vous avez déjà créé plus de 5 800 tableaux de notes !
Petit retour sur les chiffres des six nouvelles applications que nous avons lancées durant une folle semaine de début octobre :
- Il y a aujourd’hui plus de 1 850 listes sur Framalistes, notre alternative à Google Groups, servant près de 1 050 emails par jour à plus de 21 500 utilisateurs et utilisatrices ;
- Notre alternative à Evernote, Framanotes, héberge aujourd’hui plus de 3 060 comptes, dont les 12 900 notes sont chiffrées de bout en bout, ce qui fait que nous ne pouvons rien savoir de ce qu’elles contiennent ;
- Près de 1 800 formulaires sont publiés grâce à Framaforms, l’outil qui permet de ne pas transmettre les réponses de vos questionnaires à Google Forms ;
- Avec une moyenne de 1 000 salons d’audio/visio conférences créés par semaine, Framatalk vous libère de plus en plus de Skype (et ne nécessite aucune installation logicielle) ;
- Plus de 4 500 d’entre vous se sont libéré⋅e⋅s (délivrééééééééééééé⋅e⋅s) de Google / Apple / Microsoft agenda en se créant un compte sur Framagenda : félicitations !
- MyFrama, l’alternative à Del.icio.us (qui vous permet en plus de trier et conserver les adresses web des Frama-services que vous utilisez) est utilisé par plus de 2 650 personnes.

Nous n’avons par contre aucun chiffre sur votre chasse aux trolls grâce à Framatroll
Tous ces chiffres nous donnent le tournis, tant ils nous enchantent et nous inquiètent.
Ils nous enchantent car ils renforcent notre conviction qu’une alternative aux services centralisateurs, intrusifs et privatifs des GAFAM est attendue et utilisée. Cela signifie qu’un nombre croissant de personnes sont conscientes des enjeux de la centralisation du web et cherchent à prendre des mesures pour protéger leurs données, leur vie numérique.
Ils nous inquiètent parce que, même si on est à des années-lumière des statistiques d’utilisation de Google et Cie, il existe une possibilité de re-centraliser et concentrer vos données personnelles, ce que nous ne voulons pas. Une initiative moins scrupuleuse que la nôtre pourrait donc en profiter pour peu qu’elle vous propose une certaine éthique, ou du chiffrement, ou du logiciel libre…
Il existe donc une nouvelle « niche de marché » pour conquérir l’or 3.0 que sont vos données, et les géants du Web sont d’ores et déjà en train de s’y attaquer (exemples ici, là ou encore là).
Nous ne le répéterons jamais assez, les services que nous proposons sont des démonstrations à grande échelle, et nous ne sommes jamais autant heureux⋅ses que lorsque vous les quittez parce que :
- Vous avez utilisé des tutos pour installer ces logiciels libres pour votre famille, asso, syndic, administration, entreprise, etc. ;
- Vous avez confié vos données à un CHATON près de chez vous ;
- Vous avez mis en place une solution d’auto-hébergement facile de type Yunohost/La Brique Internet, MyCozyCloud, Sandstorm…
Bref : lorsque votre passage par Framasoft vous a mené vers plus d’indépendance et de liberté dans votre vie numérique !
Le point sur les dons : l’hiver est rude !
Tous ces chiffres ne sont possibles que grâce à vos dons. Nous avons (enfin !) rattrapé notre retard afin de publier nos rapports d’activités 2014 et 2015 agrémentés des données statistiques et financières de l’association (dont les comptes sont, depuis l’exercice 2015, validés par un commissaire aux comptes). À nos yeux (et comme pour tous les membres du collectif CHATONS), la transparence n’est pas négociable : promis, nous ne prendrons pas autant de temps pour publier notre rapport sur 2016 ;)
En 2015, plus de 90 % de nos ressources proviennent de votre soutien financier, qui nous offre cette indépendance et cette liberté si chères à nos yeux.
Ces dons servent principalement à financer, dé-précariser et pérenniser les 6 postes des personnes employées par Framasoft. Car, si le bénévolat est essentiel, il ne permet pas tout : la stabilité des services, les développements spécifiques, le suivi des 1 046 demandes (d’aide, de soutien technique, de réponses et d’interventions) reçues ces trois derniers mois, depuis le lancement de l’an 3 de Dégooglisons… mais aussi l’organisation et la logistique derrière tous ces projets : cela demande du temps et du savoir-faire que l’on ne peut exiger de la part de bénévoles (en tous cas, pas sans les épuiser -_-…)

Framasoft essayant d’atteindre son budget 2016 (allégorie.)
À ce jour, nous avons du mal à boucler le budget 2016 tel que nous l’envisagions. Sur 205 000 € de budget souhaité pour 2016, nous en sommes à environ 185 000 €. Rien d’alarmant, on ne va pas mettre la clé sous la porte !
Mais de ces financements découleront directement les énergies que nous pourrons mettre dans nos projets pour cette nouvelle année : les derniers services à Dégoogliser (YouTube, Meetup, Twitter, blog, pétitions, voire le mail !), la transmission d’expérience et la promotion du collectif CHATONS, la participation au développement de solutions d’auto-hébergement… ce ne sont pas les envies qui manquent !
Alors une fois encore, nous nous permettons de vous rappeler que vous pouvez participer financièrement à nos actions, par un don ponctuel ou mensuel, déductible des impôts pour les contribuables Français. Par exemple, un don de 100€ ne vous coûtera (après déduction fiscale) que 34€.
Si vous le pouvez et le voulez, rendez-vous donc sur : Soutenir.framasoft.org

Original post of Framablog.Votez pour ce billet sur Planet Libre.

Articles similaires
- Framablog : Les nouveaux Léviathans I — Histoire d’une conversion capitaliste (a) (04/07/2016)
- Framablog : Les nouveaux Léviathans I — Histoire d’une conversion capitaliste (b) (05/07/2016)
- Framablog : Les nouveaux Léviathans II — Surveillance et confiance (a) (06/07/2016)
- Framablog : Les nouveaux Léviathans II — Surveillance et confiance (b) (07/07/2016)
- Framablog : Les anciens Léviathans I — Le contrat social fait 128 bits… ou plus (08/07/2016)