Marre de tous ces tutos qui commencent avec un "Bonjour monde". J'aime pas le monde moi. À la place, je vous propose de faire une visionneuse d'images que nous appelerons "tkv" afin d'aller mater les dessins de Péhä.
Vous aurez besoin de :
- tkinter avec python3 (python2 sapu, et puis même debian le lâche, il était temps ! ). Installez donc les paquets python3-tk sous debian ou python-tkinter-3.4.5 sous OpenBSD,
- La bibliothèque de manipulation d'images PIL ou pillow (python3-pil sous debian ou py3-Pillow sous OpenBSD),
- Un éditeur de texte,
- 20 minutes,
- Un slip propre.
Voici le code qui va nous servir de point de départ, à enregistrer dans un fichier tkv.py :
#!/usr/bin/env python3
# -*- coding:Utf-8 -*-
import urllib.request
from tkinter import *
from PIL import Image, ImageTk
Vous pouvez tester ce code avec la commande :
python3.4 tkv.py
Hé, mais c'est nul ton truc !
Patience ^^ . Il ne se passe rien pour l'instant, mis à part l'import des bibliothèques qui vont nous être utiles. S'il y a des erreurs, c'est qu'il vous manque tkinter ou la bibliothèque PIL.
Quelques commentaires maintenant, intégrés au code :
#!/usr/bin/env python3
# -*- coding:Utf-8 -*-
import urllib.request # On veut télécharger des trucs
from tkinter import * # Là, on appelle tkinter
from PIL import Image, ImageTk # On va afficher des images
On code en dessous de ces lignes. Pour commencer, on affiche la fenêtre avec :
w = Tk()
w.mainloop()
Si vous lancez le script, vous verrez un carré gris.
On est encore un peu loin de ce que l'on souhaite :)
La première ligne crée une instance de notre fenêtre, et l'appel de w.mainloop() la "démarre".
Avant cette dernière ligne, nous allons personnaliser notre application.
Afin d'afficher les images, on va ajouter dans la fenêtre un espace qui servira de conteneur. Il s'agit d'une "Frame" :
mainframe = Frame(w)
mainframe.pack(fill=BOTH, expand=True, padx=15, pady=15)
Remarquez qu'on passe à Frame(w) le widget dans laquelle elle est contenue. On parle de widget "parent".
Ensuite, on attache notre widget avec la fonction "pack". Nous indiquons quelques paramètres afin qu'elle remplisse bien toute la fenêtre (fill=BOTH, expand=True). De plus, on définit une marge, totalement facultative avec les paramètres padx et pady.
Si vous lancez le code, vous ne verrez aucun changement pour l'instant.
Maintenant, on va récupérer une image à afficher. On commence douvement avec une image qui est en ligne que l'on affichera dans mainframe.
Pour télécharger l'image, on utilise les lignes suivantes. C'est du python très bête, puisque ce n'est pas l'objet de l'article. Cette image sera enregistrée dans /tmp/image.jpg.
url="https://pbs.twimg.com/media/C1Zv9ZbXEAA4-W0.jpg"
urllib.request.urlretrieve(url, "/tmp/image.jpg")
Une fois cette image récupérée, nous la chargeons en mémoire :
image = Image.open(img_path)
img = ImageTk.PhotoImage(image)
Ne reste plus qu'à mettre cette image dans un widget. Ici, je vais la mettre dans un widget de type "Label", habituellement utilisé pour afficher du texte, mais qui peut aussi contenir une image :
img_widget = Label(mainframe, image=img)
img_widget.pack()
Remarquez que l'on met l'image dans le conteneur "mainframe", puis qu'on l'accroche dedans avec la fonction "pack".
Testez le code tel qu'il est actuellement :
#!/usr/bin/env python
# -*- coding:Utf-8 -*-
import urllib.request
from tkinter import *
from PIL import Image, ImageTk
# Notre fenêtre principale
w = Tk()
# Un conteneur dans la fenêtre
mainframe = Frame(w)
mainframe.pack(fill=BOTH,expand=True, padx=15, pady=15)
# Téléchargement de l'image
url="https://pbs.twimg.com/media/C1Zv9ZbXEAA4-W0.jpg"
img_path="/tmp/image.jpg"
urllib.request.urlretrieve(url, img_path)
# Chargement de l'image
image = Image.open(img_path)
img = ImageTk.PhotoImage(image)
# Insertion de l'image dans le conteneur.
img_widget = Label(mainframe, image=img)
img_widget.pack()
# Démarrage du programme
w.mainloop()
Tout fonctionne comme prévu, sauf que l'image est trop grande. On va donc chercher à savoir s'il faut la redimensionner.
Déjà, on récupère les dimensions de l'écran :
gap = 100 # marge par rapport aux bords de l'écran
screen_width = w.winfo_screenwidth() - gap
screen_height = w.winfo_screenheight() - gap
On les compare aux dimensions de l'image. Si nécessaire, on la redimensionne avec un bête calcul de proportionnalité :
if image.width > screen_width :
image = image.resize((screen_width, int(image.height * screen_width / image.width)), Image.ANTIALIAS)
if image.height > screen_height :
image = image.resize((int(image.width * screen_height / image.height), screen_height), Image.ANTIALIAS)
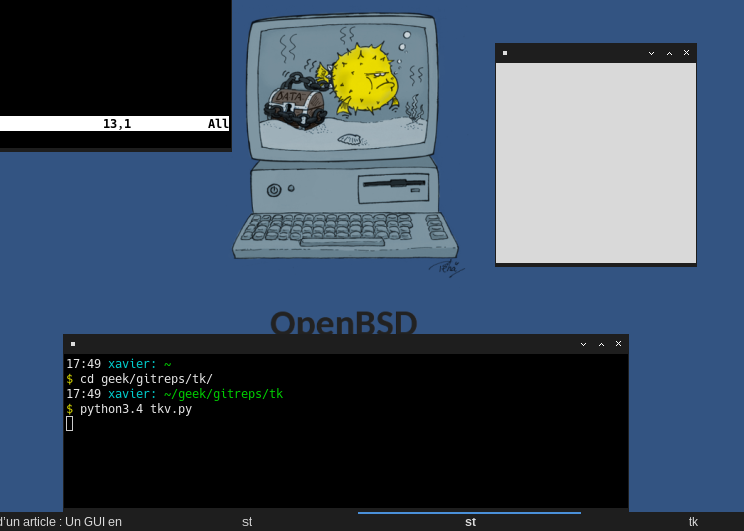
Et voilà, notre image apparaît maintenant correctement :
Avant de se quitter à la fin de ce gros TP, on va améliorer un petit peu l'apparence de notre fenêtre.
On va déjà lui donner un titre :
w.title("tkv : visionneuse d'images")
Puis on définit un fond noir :
w.configure(background='#000000')
C'est la fenêtre qui est mise en noir. Et puisqu'on a laissé une marge lorsqu'on a ajouté le conteneur principal, ça nous permet de la voir.
C'est déjà un peu mieux :
Ouf, ça fait déjà beaucoup pour une première étape. Vous aurez remarqué que les parties les plus difficiles concernent le téléchargement de l'image et son redimensionnement. À côté de ça, l'utilisation de tkinter est d'une grande simplicité.
La prochaine fois, nous verrons comment choisir une image sur le disque de l'ordinateur et comment ajouter quelques boutons pour faire défiler les images.
À bientôt !
ps : voici le code final :
#!/usr/bin/env python
# -*- coding:Utf-8 -*-
import urllib.request
from tkinter import *
from PIL import Image, ImageTk
# Notre fenêtre principale
w = Tk()
w.title("tkv : visionneuse d'images") # Un titre
w.configure(background='#000000') # Fond noir
# Un conteneur dans la fenêtre
mainframe = Frame(w)
mainframe.pack(fill=BOTH,expand=True, padx=15, pady=15)
# Téléchargement de l'image
url="https://pbs.twimg.com/media/C1Zv9ZbXEAA4-W0.jpg"
img_path="/tmp/image.jpg"
urllib.request.urlretrieve(url, img_path)
# Ouverture de l'image
image = Image.open(img_path)
# Dimensions de l'écran :
gap = 100 # marge par rapport aux bords de l'écran
screen_width = w.winfo_screenwidth() - gap
screen_height = w.winfo_screenheight() - gap
if image.width > screen_width :
image = image.resize((screen_width, int(image.height * screen_width / image.width)), Image.ANTIALIAS)
if image.height > screen_height :
image = image.resize((int(image.width * screen_height / image.height), screen_height), Image.ANTIALIAS)
# Chargement de l'image en mémoire
img = ImageTk.PhotoImage(image)
# Insertion de l'image dans le conteneur.
img_widget = Label(mainframe, image=img)
img_widget.pack()
# Démarrage du programme
w.mainloop()
Original post of Thuban.Votez pour ce billet sur Planet Libre.