Nicolargo : Voici Glances 2.1 qui pointe son nez
mardi 2 septembre 2014 à 08:53La branche de développement de Glances a été figée en RC ouvrant ainsi la phase de tests de la future version 2.1. Il est donc temps de vous en présenter les nouveautés et de demander votre aide pour tester cette version sur le maximum d'architectures différentes.
Comment tester cette version 2.1 ?
Il y a une page sur le Wiki qui explique comment faire sans "casser" votre Glances stable.
Amélioration de l'affichage des processus
Cette version de Glances apporte les fonctionnalités suivantes pour l'affichage des processus dans Glances:
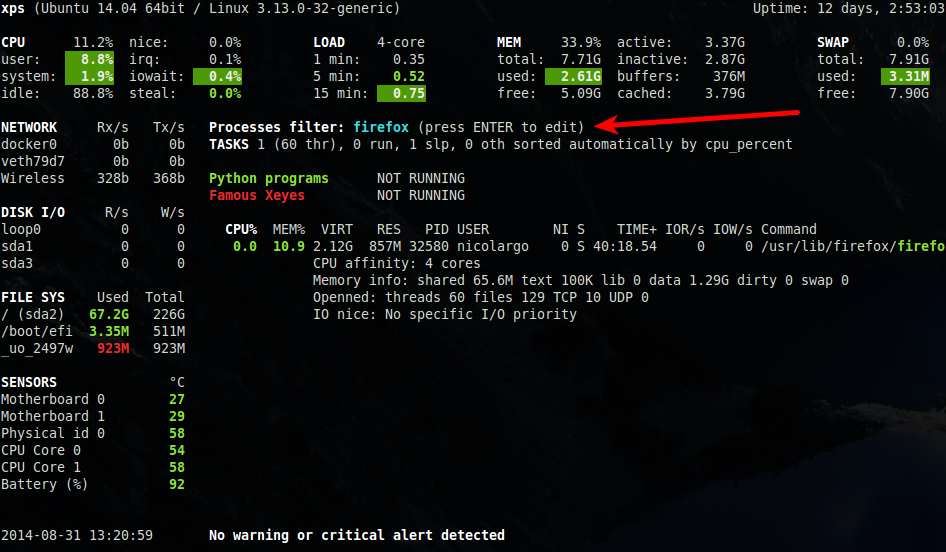
- possibilité d'appliquer un filtre (sous la forme d'une expression régulière) sur le nom et la ligne de commande des processus à afficher. Pour cela, il suffit d'appuyer sur la touche ENTREE puis de saisir le filtre. Par exemple, le filtre firefox va afficher le ou les processus du navigateur Firefox tandis que le filtre .*firefox.* va afficher tous les programmes ou le mot clé Firefox apparaît dans la ligne de commande (à noter que cette nouvelle fonction est, pour l'instant, uniquement disponible dans le mode standalone de Glances).
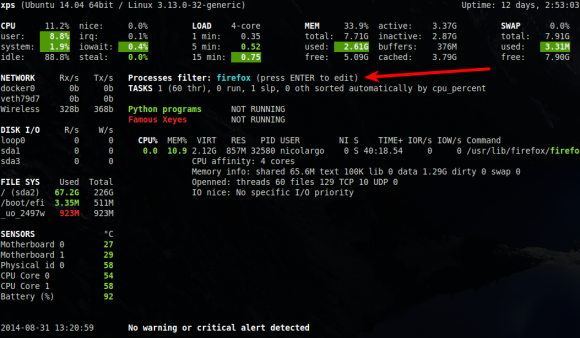
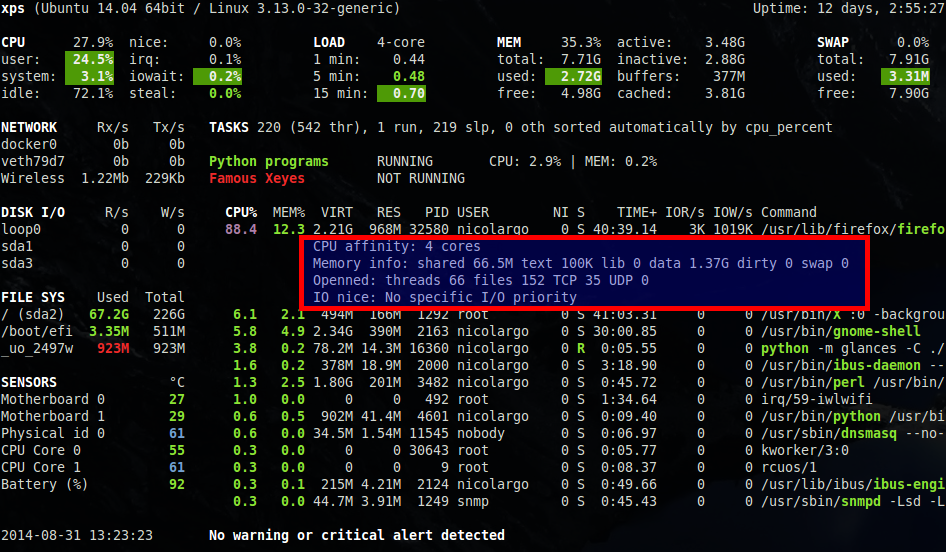
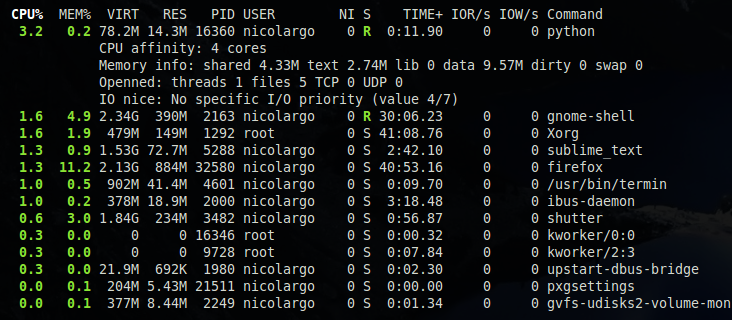
- informations complémentaire pour le 'top process' (le processus que Glances juge le plus consommateur de ressources): CPU affinity, extended memory information (shared, text, lib, datat, dirty, swap), openned threads/files and TCP/UDP network sessions, IO nice level (à noter que cette nouvelle fonction est, pour l'instant, uniquement disponible dans le mode standalone de Glances).
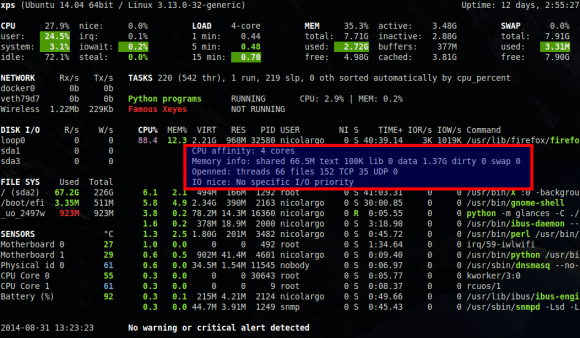
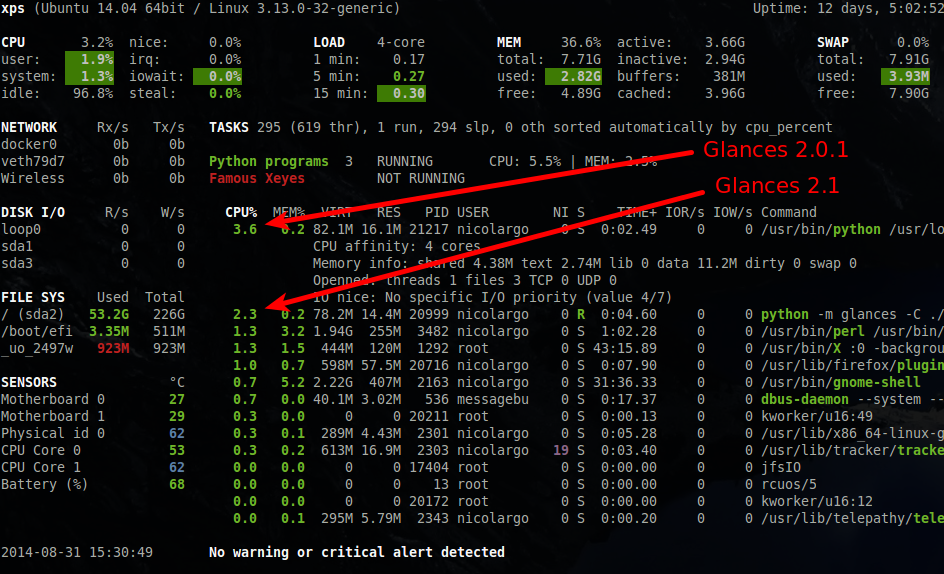
- optimisation du nombre de processus surveillés par Glances: dans les anciennes versions, Glances recupérait l'ensemble des statisiques pour tous les processus (même ceux qui n'étaient pas affichés). Dans cette version le nombre de processus est configurable via la clé de configuration max_processes du fichier de configuration (par défaut top 10) .
Cette version apporte donc un gain de footprint CPU d'environ 15% à 30%:
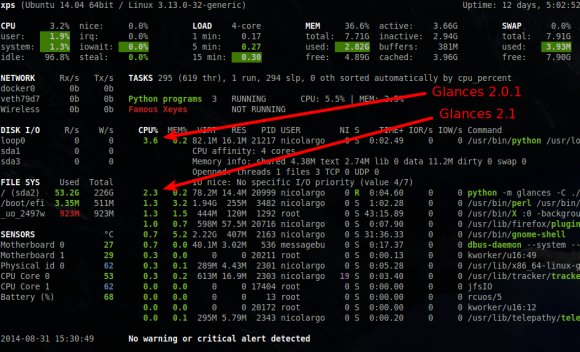 Ainsi, pour augmenter à 20 le nombre de processus affiché, il suffit d'éditer le ficheir de configuration de la manière suivante:
Ainsi, pour augmenter à 20 le nombre de processus affiché, il suffit d'éditer le ficheir de configuration de la manière suivante:[processlist] # Maximum number of processes to show in the UI # Note: Only limit number of showed processes (not the one returned by the API) # Default is 20 processes (Top 20) max_processes=20
Note: si aucune configuration n'est faite alors Glances affichera tous les processus.
- il est maintenant possible de basculer entre l'affichage actuel du nom du processus (qui affiche le nom court ou la ligne de commande complète selon la place disponible) et un mode ou uniquement le nom court est affiché. Pour cela, on peut utiliser le tag --process-short-name au niveau de la ligne de commande ou bien la touche '/' pendant le fonctionnement de Glances.Mode shortname:
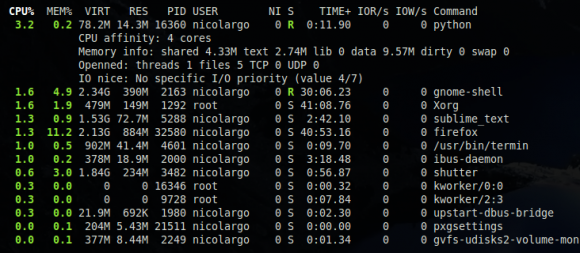 Mode standard:
Mode standard: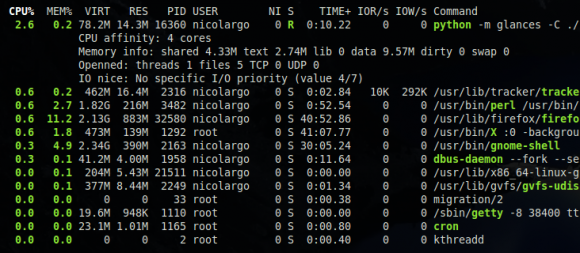
Alias pour le nom des disques, interfaces réseau et sensors
Les noms des disques (sda par exemple sous Linux), des interfaces réseau (eth0, wlan0) et des sensors (temp1) n'est pas forcement très parlant pour un humain normalement constitué (!geek). Glances permet donc de configurer des alias qui seront affichés en lieu et place des noms "barbares". La définition se fait dans le fichier de configuration:
[network] # WLAN0 alias name wlan0_alias=Wireless [diskio] # Alias for sda1 sda1_alias=IntDisk [sensors] # Sensors alias temp1_alias=Motherboard 0 temp2_alias=Motherboard 1 core 0_alias=CPU Core 0 core 1_alias=CPU Core 1
Rien de bien compliqué. On doit utiliser la syntaxe:
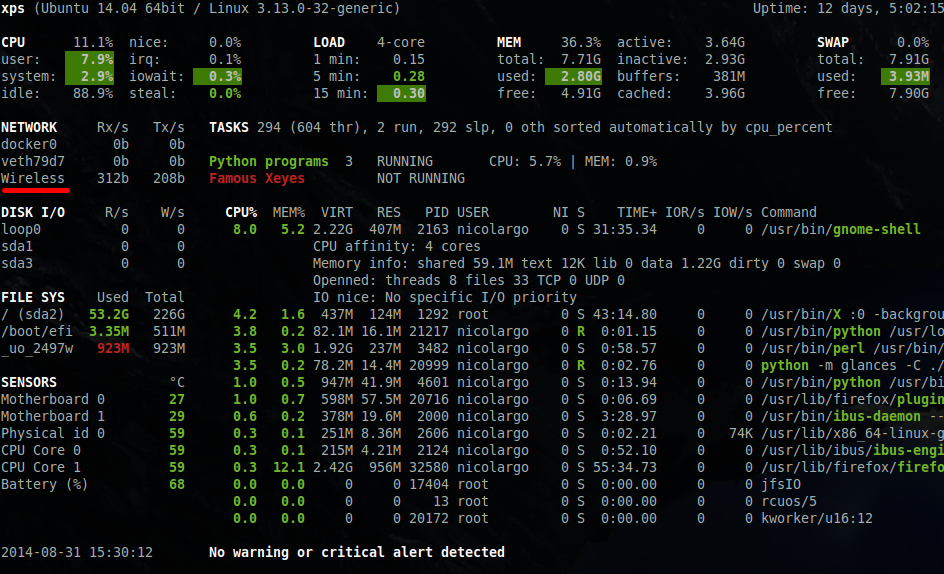
Cette fonction est surtout utile pour les utilisateurs de Windows ou les noms sont vraiment... comment dire... Windowsiens...
API RESTFull pour le serveur Web
Le serveur HTTP intégrant l'interface Web (option -w) disponible dans Glances depuis la version 2.0 ne disposait pas d'une API RESFull. C'est maintenant le cas. Il est donc possible à partir d'une application tierce de faire des requêtes du type suivant:
http://
qui donnera une réponse HTTP avec un code 200 et:
{"available": 5071183872, "used": 3255848960, "cached": 1827352576, "percent": 39.1, "free": 5071183872, "inactive": 1388982272, "active": 3679604736, "total": 8327032832, "buffers": 477982720}La documentation complète de l'API est disponible sur la page suivante dans le Wiki.
Fonction expérimentale de génération de graphes
J'ai ajouté dans cette version une fonction expérimentale (uniquement disponible dans le mode standalone de Glances) qui sera améliorée dans les prochaines versions en cas de demande de la part des utilisateurs. L'objectif de cette fonction est de générer des graphiques des statistiques (CPU, LOAD et MEM) quand l'utilisateur clique sur la touche 'g'. Concrètement, Glances va mémoriser les statistiques et les "grapher" en utilisant la librairy Matplotlib (qui doit être présente sur votre système).
Les graphes sont générés dans le répertoire /tmp:
ll /tmp/glances*.png -rw-rw-r-- 1 nicolargo nicolargo 22911 août 31 16:09 /tmp/glances_cpu.png -rw-rw-r-- 1 nicolargo nicolargo 19962 août 31 16:09 /tmp/glances_load.png -rw-rw-r-- 1 nicolargo nicolargo 12059 août 31 16:09 /tmp/glances_mem.png
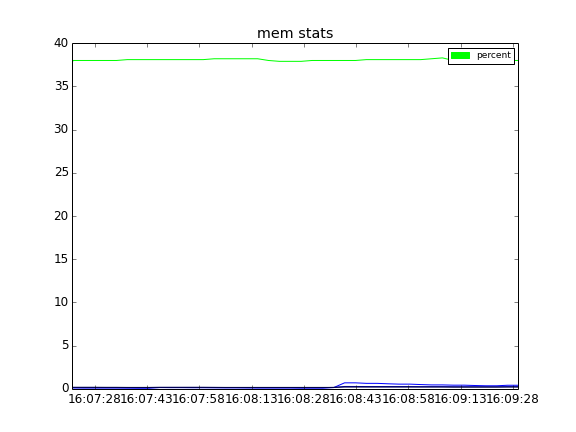
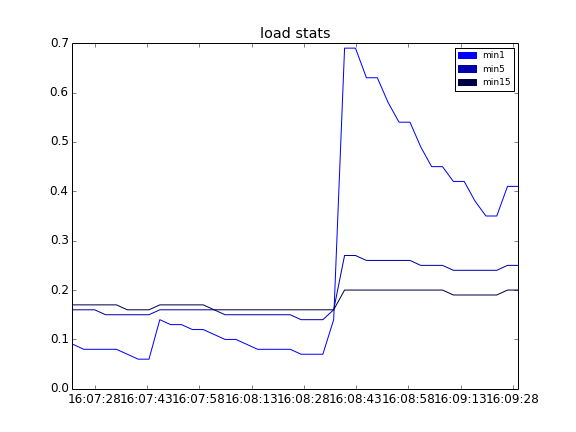
 En appuyant sur la touche 'r', l'utilisateur peut ré-initialiser l'historique et donc repartir avec un nouveau graphe (attention pour l'instant les graphes sont écrasés à chaque appui sur le bouton 'g').
En appuyant sur la touche 'r', l'utilisateur peut ré-initialiser l'historique et donc repartir avec un nouveau graphe (attention pour l'instant les graphes sont écrasés à chaque appui sur le bouton 'g').
Des logs et un mode debug
Il manquait à Glances un vrai mode débug avec un fichier de log permettant de facilement identifier les problèmes d'utilisation et d'exécution de ce logiciel. C'est maintenant chose faite avec cette version 2.1 ou un gros travail a été fait sur la généralisation des message de logs standards et debug (en utilisant l'option -d au niveau de la ligne de commande).
Le fichier de log de Glances est disponible dans le fichier /tmp/glances.log, en voici un extrait en mode normal (sans le -d):
2014-08-31 15:52:00,312 -- INFO -- Start Glances 2.1_RC7 2014-08-31 15:52:00,312 -- INFO -- CPython 2.7.6 and PSutil 2.1.1 detected 2014-08-31 15:52:00,316 -- INFO -- Read configuration file ./conf/glances-test.conf 2014-08-31 15:52:00,316 -- INFO -- Start standalone mode 2014-08-31 15:52:10,465 -- INFO -- Set process filter to firefox 2014-08-31 15:52:15,180 -- INFO -- Stop Glances
et en mode debug (-d):
2014-08-31 15:52:47,185 -- INFO -- Start Glances 2.1_RC7 2014-08-31 15:52:47,185 -- INFO -- CPython 2.7.6 and PSutil 2.1.1 detected 2014-08-31 15:52:47,190 -- INFO -- Read configuration file ./conf/glances-test.conf 2014-08-31 15:52:47,190 -- INFO -- Start standalone mode 2014-08-31 15:52:47,218 -- DEBUG -- Available plugins list: ['load', 'core', 'uptime', 'fs', 'monitor', 'percpu', 'mem', 'cpu', 'help', 'system', 'alert', 'psutilversion', 'memswap', 'diskio', 'hddtemp', 'processcount', 'batpercent', 'now', 'processlist', 'sensors', 'network'] 2014-08-31 15:52:47,219 -- DEBUG -- Monitor plugin configuration detected in the configuration file 2014-08-31 15:52:47,220 -- DEBUG -- Limit maximum displayed processes to 20 2014-08-31 15:52:47,220 -- DEBUG -- Extended stats for top process is enabled (default behavor) 2014-08-31 15:52:53,140 -- DEBUG -- User enters the following process filter patern: firefox 2014-08-31 15:52:53,140 -- INFO -- Set process filter to firefox 2014-08-31 15:52:53,140 -- DEBUG -- Process filter regular expression compilation OK: firefox 2014-08-31 15:52:57,344 -- INFO -- Stop Glances
Cette nouvelle fonction permettra, je l'espère, de facilité les rapports de bugs remontés dans GitHub.
Et pour finir...
En plus des corrections de bugs et amélioration diverses et variés, Glances 2.1 permet un affichage optimisé pour les tordus d'entre vous utilisant un fond blanc pour leur terminal (option --theme-white) ainsi que le support des routeurs Cisco et des serveurs VMWare ESXi pour le fallback SNMP en mode client/serveur.
Comme d'habitude, les bugs/demandes de fonctions sont à remonter dans GitHub en suivant cette procédure.
Merci à vous !
Cet article Voici Glances 2.1 qui pointe son nez est apparu en premier sur Le blog de NicoLargo.
Original post of Nicolargo.Votez pour ce billet sur Planet Libre.

Articles similaires
- Nicolargo : Glances a son application Android (15/04/2013)
- Nicolargo : Quelques nouvelles de Glances (et sa version 1.4.1) (07/09/2012)
- Nicolargo : Bêta test de Glances 1.5 (02/11/2012)
- Nicolargo : Glances 1.5 est arrivé (08/11/2012)
- Nicolargo : Glances 1.5.2: Les nouveautés (30/12/2012)












