Dans un article très didactique paru sur LinuxFr.org, le développeur du correcteur grammatical Grammalecte fait un appel au financement participatif pour la création d’une version fonctionnant avec Firefox. Pour le moment, ce logiciel n’est compatible qu’avec LibreOffice et OpenOffice. Son fonctionnement est expliqué dans cet article et illustré d’exemples qui intéresseront tous les curieux qui aiment savoir, comme le disait Michel Chevalet, « comment ça marche » !
« Pas d'auteurs, pas de livres. » a-t-on pu entendre cette année dans les allées du Salon du livre. Derrière cet irréfutable slogan se cachent des acteurs de la chaîne éditoriale qui sont sur la défensive actuellement, notamment vis-à-vis du rapport Reda.
Or n'oublions pas qu'il y a des auteurs d'aujourd'hui qui expérimentent d'autres modèles et, comme nous allons le voir ci-dessous, des auteurs du passé qui peuvent être republiés avec succès lorsque les éditeurs font preuve d'innovation aidés en cela par la liberté d'entreprendre qu'offre le domaine public.
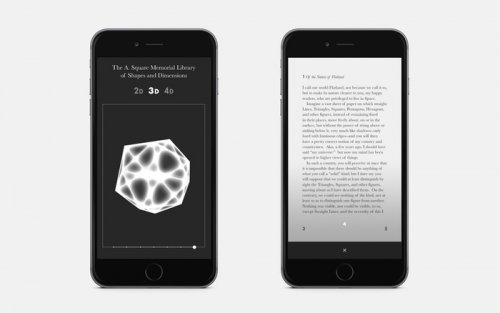
Le livre Flatland est allégorie mathématico-philosophique pleine d'humour écrite en 1884 par l'anglais Edwin Abbott Abbott. Nous lui avions consacré un article il y a un an.
Son auteur étant mort en 1926, le livre est depuis longtemps dans le domaine public. En conséquence de quoi il a été publié et republié de nombreuses fois, et on peut le télécharger librement (et gratuitement) en intégralité dans sa version numérique sur des sites tels que Internet Archive, Wikisource ou Gutenberg. Deux arguments qui pourraient freiner les velléités d'un éditeur à en proposer une énième nouvelle impression. Et pourtant...
Epilogue est un nouveau projet d'édition à l'intersection de l'art, de la technologie et du texte. Le livre physique est au centre de son activité mais on a ici le souci du design, de l'objet bien fait qui suscite le désir et de la valeur ajoutée apportée par le numérique. Flatland se veut être le premier volume d'un projet qui souhaite publier ainsi de nombreux autres auteurs anciens du domaine public.
On nous propose ici un bel objet livre enrichi par un site complémentaire autour des formes géométriques à plusieurs dimensions évoquées dans le livre. Le livre papier est en pré-vente à 45$ (ce qui n'est pas donné), sa version numérique sera disponible gratuitement et le site librement accessible à tous avec les formes développées pour l'occasion sous licence libre sur GitHub. Autant d'éléments qui laisseraient à penser que l'entreprise est hasardeuse et pourtant ça marche !
En effet, le projet est actuellement en financement participatif sur KickStarter (voir la vidéo de présentation fort bien faite sur le site). À l'heure où nous écrivons ces lignes il a déjà accumulé près de 45000$, dépassant de loi son objectif initial alors même qu'il lui reste encore 22 jours de campagne. Les souscripteurs ont visiblement adhéré au projet et souhaité avoir ce Flatland dans leur bibliothèque quand bien même sa version numérique soit présente partout sur Internet.
À l'instar des éditions Prairial, voilà un projet d'édition qui témoigne que le secteur n'est pas forcément si sinistré que cela lorsque l'on suscite l'envie de lire, de posséder un bel objet livre et que l'on utilise le numérique à bon escient. Il illustre également la valeur économique du domaine public pourvu qu'on ne lui jette pas des bâtons dans les roues. Les vieux auteurs et leurs nouveaux éditeurs ont un bel avenir devant eux ;)
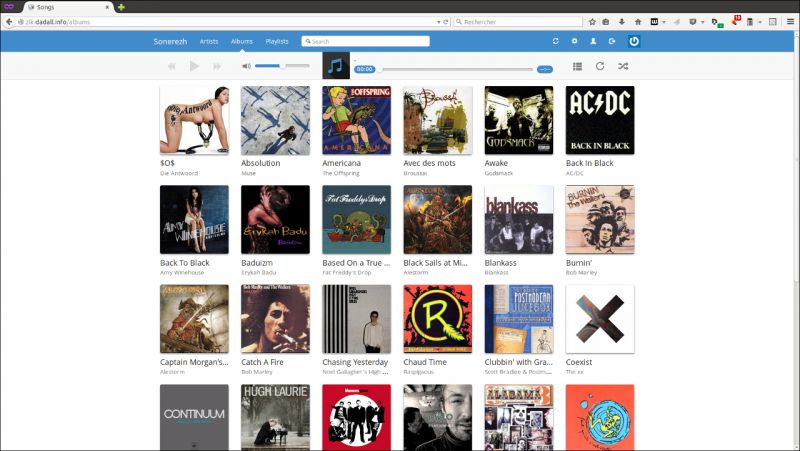
Je me rends compte que les gens rencontrent des difficultés à installer le lecteur de musique en ligne Sonerezh alors voici un rapide tutoriel pour s'en sortir.
Vous trouverez ci-dessous de quoi installer la branche master, celle qui marche directement tout en contenant quelques petits bugs peu gênants.
Je passe sur l'installation de LAMP, vous trouverez les infos qu'il vous faut par ici.
Voici la liste des modules pour Apache2 que j'utilise actuellement. Cette liste en contient surement qui ne sont pas utiles à Sonerezh mais je pars du principe que si cette liste marche chez moi, ça marchera chez vous ;)
core_module (static)
log_config_module (static)
logio_module (static)
version_module (static)
mpm_event_module (static)
http_module (static)
so_module (static)
actions_module (shared)
alias_module (shared)
auth_basic_module (shared)
authn_file_module (shared)
authz_default_module (shared)
authz_groupfile_module (shared)
authz_host_module (shared)
authz_user_module (shared)
autoindex_module (shared)
cgi_module (shared)
cgid_module (shared)
deflate_module (shared)
dir_module (shared)
env_module (shared)
fastcgi_module (shared)
headers_module (shared)
mime_module (shared)
negotiation_module (shared)
proxy_module (shared)
proxy_balancer_module (shared)
proxy_http_module (shared)
reqtimeout_module (shared)
rewrite_module (shared)
setenvif_module (shared)
ssl_module (shared)
status_module (shared)
S'il vous en manque, un a2enmod nondumodule vous permettra de l'activer.
Vérification des dépendances pour PHP5
libapache2-mod-php5
php5
php5-cgi
php5-cli
php5-common
php5-curl
php5-fpm
php5-gd
php5-imagick
php5-mcrypt
php5-mysql
php-acp
Il en manque ? apt-get install nomdupaquet pour l'installer.
Configuration du virtualhost
Adaptez ce virtualhost à votre installation.
ServerAdmin admin@monserv.tld ServerName www.monserv.tld DocumentRoot /var/www/sonerezh Options -Indexes AllowOverride all Order allow,deny allow from all
Heka, dont j’avais parlé brièvement dans ce précédent billet, est un logiciel de traitement de flux Open Source développé par Mozilla. Le développement avance bon train puisque nous en sommes déjà à la 0.9.1 au moment d’écrire ces lignes.
Heka se veut être le couteau suisse de la collecte et du traitement de données, utile pour une grande variété de tâches différentes, parmi lesquelles il est possible de citer :
Chargement et analyse des fichiers journaux à partir d’un système de fichiers.
Accepter les données en entrée au « format » statsd et les transmettre vers des bases de données de séries chronologiques Graphite ou InfluxDB.
Lancement de processus externes pour recueillir les données et métriques du système local.
Analyse en temps réel et détection d’anomalies sur les données circulant à travers le pipeline Heka.
Envoi de données d’un endroit à un autre par l’intermédiaire d’un transport extérieur (comme AMQP) ou directement (via TCP).
Fourniture de données traitées à un ou plusieurs puits de données persistantes.
Heka est écrit en langage Go, qui est reconnu comme bien adapté à la construction d’un pipeline de données à la fois souple et rapide. Les tests initiaux montre qu’une simple instance de Heka est capable de recevoir et de router plus de 10 gigabits de messages par seconde ! Ces chiffres impressionnants sont fournis par les développeurs de Heka.
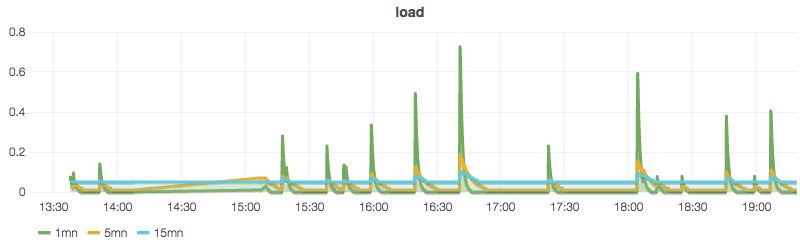
Heka possède un tableau de bord qui présente la particularité d’être mis à jour en temps réel et ça c’est la classe ! Les données arrivent, elles sont affichées, pas de navigateur à recharger, y compris pour les graphiques.
Cette courte vidéo montre un graphique Heka représentant les entrées-sorties disque. Dès que l’on écrit sur le disque, le graphe se met à jour en temps réel.
Tout est plugin
Il y a six types de plugins différents dans Heka plus un type un peu particulier appelé « Sandbox ». Ce type offre un environnement d’exécution dynamique et confiné pour l’analyse et la transformation des données.
Entrées
Les plugins de type entrée permettent d’acquérir des données et de les injecter dans le pipeline Heka. Ils peuvent le faire en lisant les fichiers d’un système local, en activant des connexions réseau sur des serveurs distants, en écoutant sur une socket réseau, en lançant des processus sur le système local ou toute autre mécanisme.
Splitters
Les plugins de type splitter reçoivent les données qui sont en cours d’acquisition par un plugin d’entrée et les découpe dans des enregistrements séparés.
Décodeurs
Les plugins de type décodeur permettent de convertir les données entrant par les plugins d’entrée. Ils sont utiles pour l’analyse, la désérialisation ou l’extraction de la structure à partir de données non structurées.
Filtres
Les plugins de type filtre sont les moteurs de traitement de Heka. Ils sont configurés pour recevoir des messages correspondant à certaines caractéristiques spécifiques et sont en mesure d’effectuer l’agrégation et/ou le traitement des données. Les filtres sont également en mesure de générer de nouveaux messages qui peuvent être réinjectés dans le pipeline Heka, tels que les messages de synthèse contenant les données agrégées, les messages de notification dans les cas où des anomalies sont détectées.
Encodeurs
Les plugins de type encodeur sont l’inverse des décodeurs. Ils gèrent donc la sérialisation et le formatage de la sortie avant envoi vers des logiciels tiers.
Sorties
Les plugins de type sortie envoient des données vers une destination externe. Ils gèrent tous les détails de l’interaction avec le réseau, le système de fichiers ou toute autre ressource externe. Ils sont, comme les filtres, configurés à l’aide du « Message Matcher » qui permet de ne transmettre que les messages correspondant à certaines caractéristiques.
Tout est message
Toutes les données sont traitées par Heka sous forme de messages structurés comme suit :
uuid (requis) : Un identifiant unique.
timestamp (requis) : Nombre de nanosecondes écoulées depuis epoch UNIX.
type (optionnel) : Type de message ex. “WebLog”.
logger (optionnel) : Source de données ex. “Apache”, “TCPInput”, “/var/log/test.log”.
severity (optionnel) : Niveau de sévérité Syslog.
payload (optionnel) : Données textuelles ex. ligne de log, nom de fichier.
pid (optionnel) : ID du processus qui a généré le message.
hostname (optionnel) : Nom de l’hôte qui a généré le message.
fields (optionnel): Tableau contenant des structures de données.
Routage des messages
Heka fait appel à un mécanisme de Message Matcher pour router les messages vers les filtres adéquats en fonction de leur contenu. En voici un exemple simple :
Type == “test” && Severity == 6
Chaque filtre vers lequel le message est routé reçoit alors une copie de ce message.
Installation
L’installation est simple puisque Heka est packagé pour Linux type Debian et Redhat ainsi que pour OS X. Sur mon ubuntu, un simple dpkg -i suffit donc pour installer la chose.
Une fois installé, vous disposez de 6 nouveaux binaires sur votre système :
heka-cat
hekad
heka-flood
heka-inject
heka-logstreamer
heka-sbmgr
Le plus important est bien sûr hekad qui est le démon responsable de la collecte et du traitement des données. Les autres binaires sont essentiellement des utilitaires qui facilitent la configuration et permettent de la tester.
A ce stade, n’essayez pas de démarrer hekad, le démon principal car il ne se passera rien. Aucun fichier de configuration n’est fourni par défaut. Il faut donc écrire un fichier minimum de configuration pour ce faire. Un fichier minimal de configuration type « Hello World » pourrait ressembler à ceci :
Cette configuration permet simplement de lire le fichier /tmp/input ligne par ligne pour les recracher dans /tmp/output. Aucun traitement n’est appliqué. Lisez ce billet en anglais d’où est tiré cet exemple pour en savoir plus.
Principes de configuration
Heka utilise une syntaxe TOML pour sa configuration. Celle-ci peut être éclatée en autant de fichiers que nécessaires à condition que ceux-ci se trouve dans le même dossier et qu’ils finissent par le suffixe .toml.
Les fichiers sont alors chargés par ordre alphabétique, et en cas de conflit pour un réglage, c’est le dernier précisé qui gagne.
La configuration est éclatée en sections qui représente chacune l’instanciation unique d’un plugin. Voici un exemple de section décrivant la configuration du plugin tcp:5565 :
[tcp:5565]
type = "TcpInput"
decoder = "ProtobufDecoder"
address = ":5565"
Même si la configuration fait un peu mal au crâne au début, le temps de comprendre chacune des étapes que traverse une données dans le pipeline Heka, il ne m’aura pas fallu plus d’une heure pour réussir à collecter les données de charge de mon serveur, les envoyer dans InfluxDb et les grapher avec Grafana. Rien d’impossible donc même si ce début est très basique !
Graphe temps réel dans Heka
Je ne vais pas entrer dans le détail de la configuration de Heka dans ce billet car je suis malgré tout loin d’être au point. Ce sera pour un ou plusieurs autres articles en fonction de l’intérêt que vous portez à celui-ci et de vos commentaires… Alors faîtes du bruit !
Premiers sentiments
Si vous êtes comme moi un vieux routier de Nagios ou de solutions similaires, Heka va vous « secouer » sérieusement; au moins au départ. Sommes-nous en présence d’un « clone » de Logstash, un super Collectd ou est-ce un peu tout ça à la fois ? La comparaison la plus proche pourrait être Riemann qui fonctionne aussi sur le principe de pipeline de traitement de données.
J’ai commencé à tester le potentiel de Heka dans un setup plutôt classique pour moi désormais.
Un serveur Elasticsearch pour stocker les messages type log.
Un serveur InfluxDB pour stocker les métriques.
Un serveur Kibana/Grafana pour la visualisation de ces différents types de données.
Les deux pièces de mon puzzle habituel qui sont remplacées sont Logstash et Collectd. Pas sûr cependant de pouvoir complètement remplacer Collectd mais nous n’en sommes pas encore au bilan.
Dans tous les cas, c’est un bien bel engin que nous met à disposition la fondation Mozilla. Complet puisque capable à la fois de collecter, filtrer, en/décoder, alerter, détecter des anomalies, il ne prétend pas tout faire et laisse toute la partie stockage et restitution des données à d’autres logiciels prévus pour ça.
J’apprécie la discrétion et la légéreté de Heka à la fois en terme de CPU et de mémoire. Même en envoyant des métriques toutes les secondes vers InfluxdDB, la charge ne bouge pas de 0 ! On est très loin de la goinfrerie de Logstash à ce niveau. Et c’est tant mieux pour ceux qui fonctionnent avec des VPS souvent légers en RAM… Si on veut rester dans une gamme de prix raisonnable bien sûr.
Et même si les plugins sont moins nombreux que Logstash, il y en a quelques uns comme le Docker Log Input ou le Nginx Access Log Decoder qui vont démanger les nombreux aficionados de ces technos.
Écrire des extensions ou des plugins pour Heka ne se fait pas aussi simplement que pour Nagios puisqu’il faut écrire tout ça en Go ou Lua. Pas forcément les langages de programmation les plus pratiqués par des profils admin système.
Sur ce je vous laisse, je retourne à la configuration de mon Heka. J’ai encore du boulot avant de pouvoir envoyer mes logs + métriques provenant de Nginx, php5-fpm et autres MySQL vers InfluxDB et Elasticsearch.
En ce mardi 21 avril, le Projet Fedora est fier de vous annoncer la sortie
de Fedora 22 Béta. Bien entendu, qui dit Alpha, dit instabilité, développement,
tests et bugs. Ne l'installez pas si vous ne savez pas ce que vous faites.
Cependant, il est important de la tester. En rapportant les bogues
maintenant, la Fedora 22 stable sera plus stable encore et aura moins de risque
de sortir en retard. Les versions en développements manquent de testeurs et de
retours pour mener à bien leurs buts. La Fedora 22 stable devrait sortir aux
alentours du 26 mai.
Par rapport à l'Alpha, si ce n'est des logiciels plus stables, il n'y a pas
de changements importants. Voici un rappel de ce qu'il nous apporte :
Bureautique
Gnome 3.16 ;
Les notifications de Gnome-Shell ont été refondues, elles apparaissent
dorénavant au sein du widget calendrier ;
Gnome terminal peut vous donner une notification quand une longue tâche est
terminée ;
GDM, l'écran de connexion, utilise Wayland en lieu et place de X11. Le
reste de Gnome utilise X11 par défaut (bien que Wayland soit disponible pour
les plus courageux) ;
Gnome Logiciel prend la place de Gnome Packagekit pour installer les codecs
ou polices additionnelles à la volée ;
ABRT (l'assistant de rapport de bogues) exploite les notifications et les
contrôles de confidentialité de Gnome pour mieux réussir sa mission ;
L'intégration de Qt au sein du thème de Gnome Shell (Adwaita) est fini. De
plus le thème par défaut de Gnome-Shell a été remanié ;
Nautilus a subi une plus forte intégration à Gnome-Shell, notamment pour
les menus contextuels ;
libinput, celui qui gère les entrées de périphériques de Wayland, est
utilisé par défaut dans X11 et Wayland, amorçant la transition vers Wayland
;
Plasma 5 est maintenant la version par défaut de KDE spin ;
WINE utilise le support de mesa pour Direct3D pour la vidéo (meilleures
performances et meilleure compatibilité) ;
Support de qtile, un gestionnaire de fenêtre pavant en Python ;
Administration système
Le gestionnaire de paquet Yum, par défaut depuis Fedora Core 1, laisse
place à DNF par défaut ;
DNF cherche et installe les extensions de langages de vos logiciels
préférés (comme Libreoffice ou KDE) depuis la langue du système ;
Python 3 poursuit sa progression comme version par défaut du langage du
système ;
Ajout d'un assistant de migration de version de Fedora pour s'assurer que
tout se passe bien et qu'on n'oublie rien ;
Ajout de Vagrant, un utilitaire pour automatiser la création de VM de
développement ;
Par ailleurs, Vagrant peut exploiter les images Fedora Atomic Host et
Fedora Cloud pour générer les images ;
Ajout de Tunir, un logiciel d'aide à intégration continue utilisée
notamment pour les images de Fedora Cloud ;
Ajout de dbxtool, pour autoriser la mise à jours de logiciels signés pour
l'UEFI si la version utilisée du programme est vulnérable tout en refusant dans
les autres cas ;
BIND 9.10 ;
Projet Fedora
Gradle 2.0 ;
Fedora Atomic Host : une implémentation du projet Fedora du Projet Atomic
;
Développement
DJango 1.8 ;
wXPython 3.0 ;
Python dateutil 2.4 ;
Boost 1.58 ;
GCC 5 ;
Ruby 2.2 ;
Ruby on Rails 4.2 ;
Perl 5.20 ;
GHC 5.8 ;
Glibc supporte Uricode 7.0 ;
Et d'autres encore ! Notons que les préparatifs pour Fedora 23 débutent
doucement. Il est annoncé que Wayland remplacera X11 par défaut avec XWayland
pour la compatibilité en option. De même, Python 3 sera installé par défaut,
Python 2 ne sera disponible que dans les dépôts.
Si l'aventure vous intéresse, les images sont disponibles par Torrent :
http://torrent.fedoraproject.org/ En cas de bogue, n'oubliez pas de relire la
documentation pour signaler les anomalies sur le BugZilla.
 Dans un article très didactique paru sur LinuxFr.org, le développeur du correcteur grammatical Grammalecte fait un appel au financement participatif pour la création d’une version fonctionnant avec Firefox. Pour le moment, ce logiciel n’est compatible qu’avec LibreOffice et OpenOffice. Son fonctionnement est expliqué dans cet article et illustré d’exemples qui intéresseront tous les curieux qui aiment savoir, comme le disait Michel Chevalet, « comment ça marche » !
Dans un article très didactique paru sur LinuxFr.org, le développeur du correcteur grammatical Grammalecte fait un appel au financement participatif pour la création d’une version fonctionnant avec Firefox. Pour le moment, ce logiciel n’est compatible qu’avec LibreOffice et OpenOffice. Son fonctionnement est expliqué dans cet article et illustré d’exemples qui intéresseront tous les curieux qui aiment savoir, comme le disait Michel Chevalet, « comment ça marche » !