C'est le jour J, Debian 9 Stretch est prête et passe dans le canal stable ! Cela signifie que Debian 8 Jessie passe en oldstable et 7 Wheezy en oldoldstable (il serait peut-être temps de mettre à jour si vous y êtes toujours !)
Hormis le nouveau fond d'écran et le nouveau nom, qu'est-ce qui change ? Ben les paquets pardi ! Les paquets de Jessie commencent à vieillir, tandis que Stretch en apporte de bien plus frais, la période de gel ayant débuté il y a 6 mois.

Quoi de neuf ?
Après 26 mois de développement, le projet Debian est fier d'annoncer sa nouvelle version stable n° 9 (nom de code Stretch
), qui sera gérée pendant les cinq prochaines années grâce à l'effort combiné de l'équipe de sécurité de Debian ainsi qu'à celui de l'équipe de gestion à long terme de Debian.
Debian 9 est dédiée à Ian Murdock fondateur du projet, disparu le 28 décembre 2015.
Dans Stretch
, la variante par défaut de MySQL est maintenant MariaDB. Le remplacement des paquets de MySQL 5.5 ou 5.6 par la variante MariaDB 10.1 se produira automatiquement lors de la mise à niveau.
Firefox et Thunderbird sont de retour dans Debian avec la publication de Stretch
, et remplacent leurs versions sans marque Iceweasel et Icedove présentes dans l'archive pendant plus de 10 ans.
Grâce au projet des Constructions reproductibles, plus de 90 % des paquets source fournis dans Debian 9 construiront des paquets binaires identiques au bit près. Cette propriété de vérificabilité protège les utilisateurs des tentatives malveillantes pour altérer les compilateurs et les réseaux de construction. Les versions futures de Debian incluront des outils et des métadonnées de manière à ce que les utilisateurs finaux puissent valider la provenance des paquets dans l'archive.
Les administrateurs et ceux qui sont dans des environnements sensibles au niveau de la sécurité seront soulagés d'apprendre que le système d'affichage X ne réclame plus les droits du superutilisateur
pour son exécution.
La publication de Stretch
est la première version de Debian à fournir la branche moderne
de GnuPG dans le paquet gnupg
. Celle-ci apporte la cryptographie par courbe elliptique, de meilleurs paramétrages par défaut, une architecture plus modulaire et une amélioration de la prise en charge des cartes à puce (« smartcard »). Nous continuerons à fournir la branche classique
de GnuPG dans le paquet gnupg1
pour ceux qui en auraient besoin, mais elle est désormais obsolète.
Les paquets de débogage sont plus faciles à obtenir et utiliser dans Debian 9 Stretch
. Un nouveau dépôt dbg-sym
peut être ajouté à la liste de sources d'APT pour obtenir automatiquement les symboles de débogage pour de nombreux paquets.
La gestion de l'UEFI (Unified Extensible Firmware Interface
), introduite dans Wheezy
continue à être grandement améliorée dans Stretch
, et permet aussi l'installation en présence de micrologiciel UEFI 32 bits avec un noyau 64 bits. Comme nouvelle fonctionnalité, les images autonomes « live » de Debian incluent maintenant aussi la gestion de l'amorçage UEFI.
Voici quelques mises à jour notables, avec entre parenthèses la version disponible sous Jessie.
Côté web :
- PHP 7.0 (5.6) (YES !!)
- Nginx 1.10 (1.6) (YES !!)
- Apache 2.4.25 (2.4.10)
- MariaDB 10.1 (MySQL 5.5)
- PostgreSQL 9.6 (9.4)
- Redis 3.2 (2.8)
Du côté desktop :
- GNOME 3.22 (3.14)
- KDE/Plasma 5.8 (4.11)
- XFCE 4.12 (4.10)
- Mate 1.16 (1.8)
- Cinnamon 3.2.7 (2.2.16)
- GTK+ 3.22 (3.14)
- QT 5.7 (5.3)
Plein de nouveautés donc ! L'arrivée de PHP 7 dans les dépôts est vraiment appréciable, et celle de OpenSSL 1.1.0, apportant CHACHA20 et de nouvelles curves mérite une mise à jour de mon article sur HTTPS et Nginx. :)
Mettre à jour Debian
Je vous conseille de jeter un œil aux notes de publication, ça peut vous intéresser et vous aider.
Bon, première règle : on backup tout ! Allez hop hop on ne plaisante pas avec ça.
Je vous conseille de tester d'abord la mise à niveau vers Debian 9 Stretch sur une machine peu critique, comme un PC de secours ou un serveur qui sert pas à grand chose. Normalement, tout devrait bien se passer, le plus gros risque c'est qu'une mise à niveau d'un paquet casse la conf et l'empêche de fonctionner après la mise à jour, mais normalement vous êtes alertés durant la mise à jour.
Bien sûr, le plus propre reste de faire une fresh install. C'est ce que je compte faire sur une bonne partie de mes serveurs, mais bon là j'ai le bac cette semaine donc on va éviter. Et oui je fais cet article pendant le bac, mais bon ils sont relous chez Debian à sortir ça maintenant aussi :D .
Première chose à faire : s'assurer qu'on est bien à jour sur Jessie :
apt update
apt full-upgrade
Ensuite, on met à jour le fichier /etc/apt/sources.list en remplaçant jessie par stretch. Si vous avez stable dans votre fichier, alors vous êtes déjà sûrement sous Stretch !
Pour les feignants :
sed -i 's|jessie|stretch|' /etc/apt/sources.list
Vérifiez aussi les dépôts dans /etc/apt/sources.list.d/ ! Il n'y en a qui ne sont peut-être pas disponibles sous Stretch ou qui sont devenus inutiles.
Votre fichier sources.list doit donc ressembler à ceci, par exemple :
deb http://httpredir.debian.org/debian stretch main
deb http://httpredir.debian.org/debian stretch-updates main
deb http://security.debian.org/ stretch/updates main
Et ensuite, on est reparti pour un tour :
apt update
Suite à un problème de clé, vous devez installer ce paquet pour récupérer la clé manquante afin de vérifier la signature GPG des paquets. Merci Sp3r4z :)
apt install debian-archive-keyring
apt update
apt full-upgrade
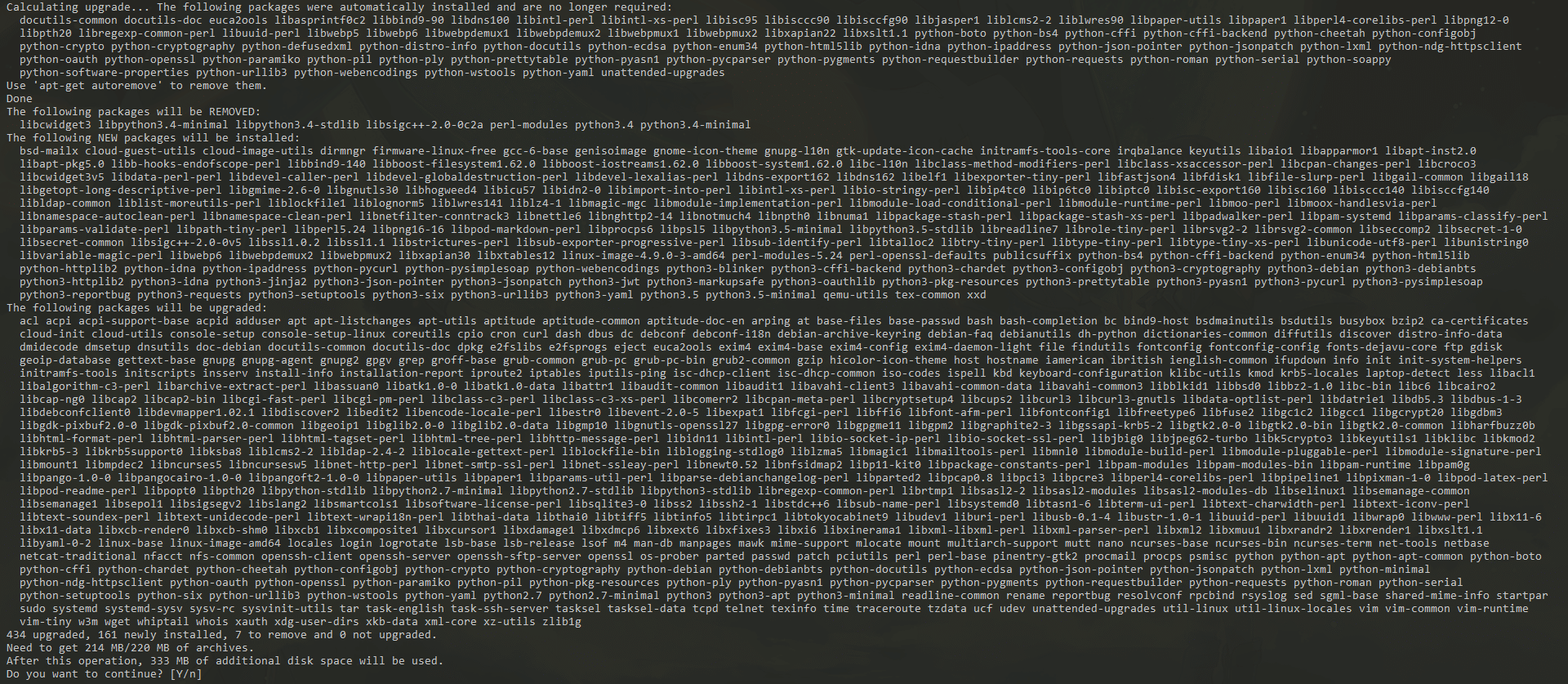
Voilà ce que ça donne pour un serveur fraîchement installé sous Debian 8 :
Va falloir un peu de patience !
Après un petit reboot, on vérifie que tout est à jour :
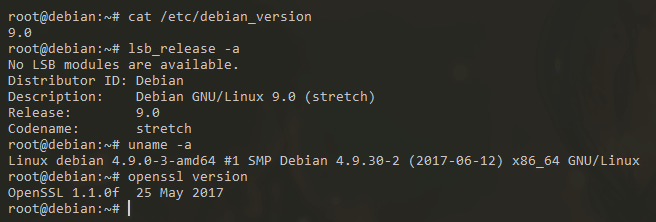
Et voilà, maintenant profitez de vos paquets tous neufs ! :D
Fanart par
Takaju 👌
L'article Mettre à jour Debian 8 Jessie vers Debian 9 Stretch a été publié sur Angristan

Original post of Angristan.Votez pour ce billet sur Planet Libre.