Signal et Silence sont deux applications pour Smartphone permettant de chiffrer les échanges que l'on peut faire par SMS (et en plus par la voix dans le cas de la première application).
Afin d'avoir un support pour des conférences, ateliers ou autres (Support pour aider lors des Cafés vie privée, Chiffrofête, Cryptoparty), j'ai commencé à mettre en place ce support.
Ca reprend au départle billet que Taziden a posté sur son bloghttps://www.libre-parcours.net, qu'il avait mis à disposition selon les termes de la Licence Creative Commons BY-SA 4.0 International.
Les contributions sont les bienvenues et surtout n'hésitez pas à reprendre et diffusez.
Dans la todo/Raf, il y a entre autre, dans ce que je prévois :
Ajouter "Comment l'utiliser" avec une présentation d'un premier échange chiffré...
comment valider le correspondant via sa clef...
Ajouter des images et illustrations...
Pour la 23ème semaine de 2017, voici 10 liens intéressants que vous avez peut-être ratés, relayés par le Journal du hacker, votre source d’informations pour le Logiciel Libre francophone !
De plus le site web du Journal du hacker est « adaptatif (responsive) ». N’hésitez pas à le consulter depuis votre smartphone ou votre tablette !
Le Journal du hacker fonctionne de manière collaborative, grâce à la participation de ses membres. Rejoignez-nous pour proposer vos contenus à partager avec la communauté du Logiciel Libre francophone et faire connaître vos projets !
Et vous ? Qu’avez-vous pensé de ces articles ? N’hésitez pas à réagir directement dans les commentaires de l’article sur le Journal du hacker ou bien dans les commentaires de ce billet :)
De nos jours, les emojis sont partout. Sur nos smartphones, les différentes messageries, les réseaux sociaux… À tel point que Sony Pictures à même prévu de leur consacrer un film d’animation : Le Monde secret des Emojis
Que ce soit sur macOS, Android ou iOS, il n’y a rien de plus simple que d’insérer ces petites images. Même Microsoft a enfin décidé de faciliter leur usage en incluant dans la Build 16215 de Windows 10 un sélecteur d’emojis invocable par l’utilisateur depuis n’importe quelle zone textuelle.
Mais qu’en est-il de notre plateforme ? Les développeurs de GNOME se sont bien penchés sur la question, mais malheureusement, rien n’a encore été implémenté
Qu’à cela ne tienne ! Vous l’aurez sans doute deviné, il existe encore une extension pour combler cette lacune
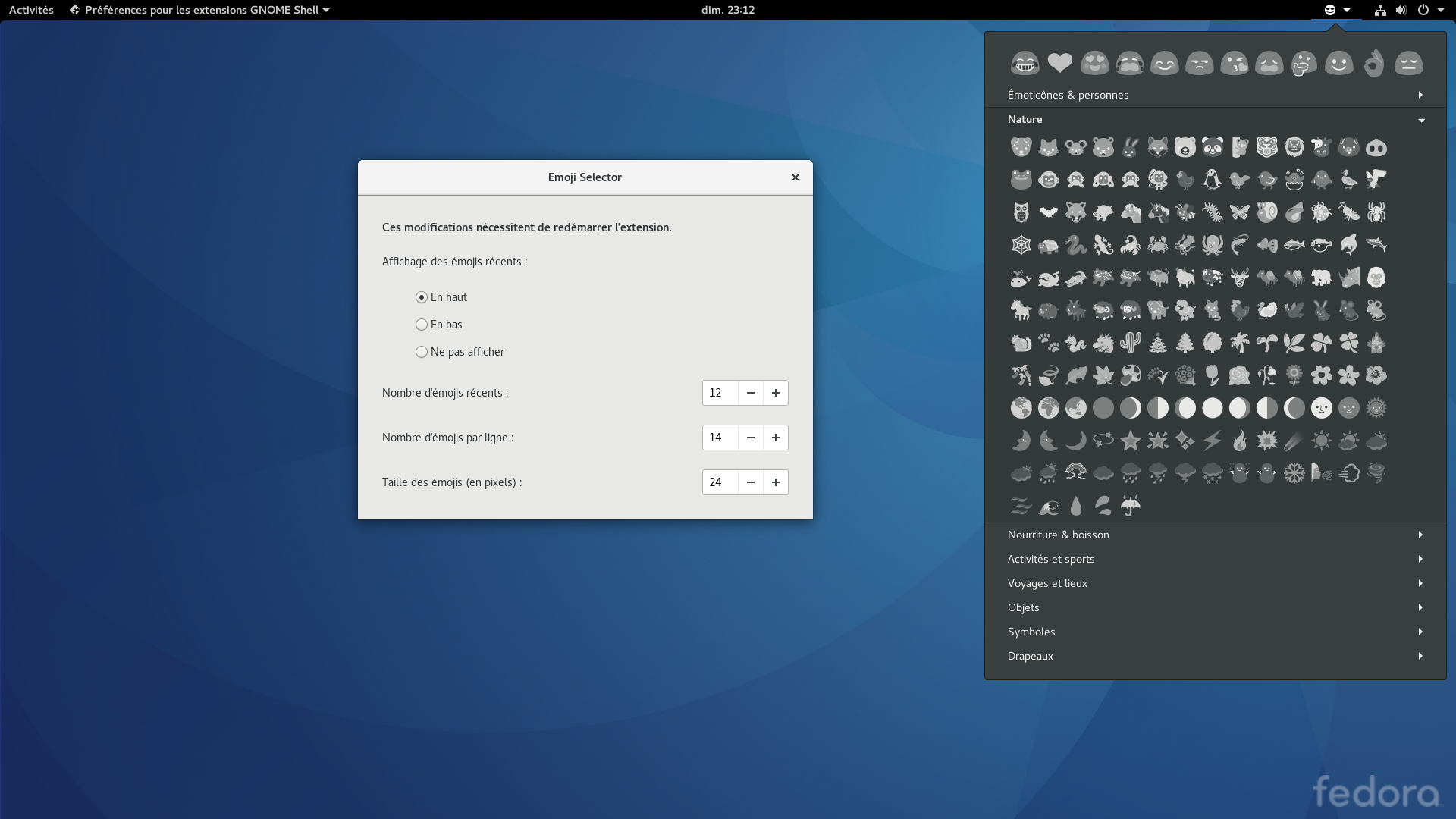
Une fois installée, Emoji Selector se place dans la barre supérieure et permet de parcourir plusieurs centaines d’emojis classées par catégories : émoticônes et personnes, nature, nourriture et boisson, activités et sports, voyages et lieux, objets, symboles, drapeaux…
Emoji Selector v3
Il n’y a qu’à cliquer sur l’emoji qui nous intéresse pour que cette dernière soit automatiquement copiée dans le presse-papier. Puis de retour dans notre application, il n’y a plus qu’à la coller et le tour est joué. Alors oui, ce n’est pas aussi bien intégré que si c’était directement proposé par GNOME, où une simple sélection insérerait automatiquement l’emoji au bon endroit, mais c’est toujours mieux que d’apprendre la table Unicode par cœur
Il est par contre bien dommage que les emojis soient affichées sous leur forme monochrome plutôt que dans leur version colorée, bien plus simple à identifier. Firefox ayant de son côté choisi d’inclure la fonte Emoji One pour remédier à ce problème. Dommage également que l’on ne puisse pas effectuer de recherche, souvent bien plus rapide que de chercher visuellement l’emoji dont nous avons besoin.
Au niveau des options, plutôt succinctes, nous pouvons choisir d’afficher ou non une liste d’emojis récemment utilisées, ainsi que la taille des emojis et leur nombre par ligne.
Ça fait son office, mais on peut tout de même espérer de voir GNOME rapidement combler son retard. Et il se trouve justement que cet été, notre projet préféré fêtera ses vingt ans. Ça serait génial que durant le GUADEC 2017, il y ait un petit hackathon pour implémenter tout ça. Puisque que serait un anniversaire sans toutes ces emojis joyeuses et colorées ?
L'association Borsalinux-Fr vous invite à venir découvrir Fedora 26 à la Cité des Sciences et de l'Industrie le samedi 1
juillet 2017 de 14h à 18h. L'évènement prendra place en complément du
traditionnel samedi du libre, dans le Carrefour numérique de la Cité. Venez
installer votre machine sous cette toute nouvelle mouture de Fedora, observer
les avancements faits depuis la dernière version ou même simplement discuter
avec les contributeurs francophones du projet Fedora ou d'autres
distributions.
Deux modules de conférences seront proposés durant ces rencontres : le
premier sera une présentation générale du projet Fedora, ainsi que des
nouveautés de Fedora 26. Le second portera sur l'effort de traduction au sein
de Fedora, suivi d'un atelier participatif sur ce même thème.
Cela sera également l'occasion peut être de découvrir et tester le projet Fedorator.
L'évènement aura lieu au Carrefour Numérique de la Cité
des Sciences. La Cité se situe au 30 Avenue Corentin Cariou à Paris et le
Carrefour Numérique est au 1ier sous-sol. Elle est desservie par la ligne 7 du
métro (station Porte de la Villette) ainsi que par le tramway (T3b).
Notons qu'à l'heure actuelle Fedora 26 est finalement prévue pour le 11
juillet, c'est-à-dire après l'évènement. Cependant à ce stade du développement
les nouveautés sont figées et le résultat sera assez stable pour vous le
présenter et peut être même vous l'installer si vous le souhaitez.
Venez nombreux, personnellement je ferais le déplacement. o/
Dans ce chapitre, nous allons découvrir un module très intéressant puisqu’il permet d’enregistrer des données dans un fichier binaire et de les restituer ultérieurement avec leur type initial.
Pickles
En effet, jusqu’ici, dans les deux chapitres précédents, nous n’avons enregistré que des données de type string dans les fichiers que nous avons créés. Si nous voulions par exemple enregistrer le nombre entier 9, il fallait d’abord convertir ce dernier en chaîne de caractères (ligne n° 3) et effectuer ensuite l’opération inverse pour pouvoir l’additionner avec un autre nombre entier (ligne n° 6).
number = 9
with open("mon_fichier", 'w') as file_:
file_.write(str(number))
with open("mon_fichier", 'r') as file_:
number = file_.readline()
result = 4 + int(number)
print("4 + {} = {}".format(number, result))
Le module pickle
Mais ça, c’était avant!… Avant de découvrir le module pickle qui va nous permettre d’enregistrer dans un fichier binaire, des nombres entiers (type int), des nombres décimaux (type float), des listes (type list), des dictionnaires (type dict) et même des objets que l’on a soi-même instanciés! Ce procédé, d’une grande utilitude, porte un nom : la sérialisation des données. Voici comment cela fonctionne. J’ai commenté chaque ligne de ce code (un peu plus bas):
import pickle
int_number = 23
float_number = 15.89
first_names = ["Pamphile", "Théophane", "Esclarmonde"]
dictionary = {"Pamphile" : 32, "Théophane" : 54, "Esclarmonde" : 45}
class First_name(object):
def __init__(self, first_names):
self.p = first_names[0]
self.t = first_names[1]
self.e = first_names[2]
def majuscules(self):
return "{}, {} et {}".format(self.p.upper(), self.t.upper(), self.e.upper())
upper_names = First_name(first_names)
with open("donnees_enregistrees", 'wb') as file_:
pickle.dump(int_number, file_)
pickle.dump(float_number, file_)
pickle.dump(first_names, file_)
pickle.dump(dictionary, file_)
pickle.dump(upper_names, file_)
with open("donnees_enregistrees", 'rb') as file_:
i = pickle.load(file_)
print(i, type(i))
j = pickle.load(file_)
print(j, type(j))
k = pickle.load(file_)
print(k, type(k))
l = pickle.load(file_)
print(l, type(l))
m = pickle.load(file_)
print(m.majuscules(), type(m))
n = pickle.load(file_)
print(n, type(n))
Exécution du code :
23 15.89 [‘Pamphile’, ‘Théophane’, ‘Esclarmonde’] {‘Théophane’: 54, ‘Pamphile’: 32, ‘Esclarmonde’: 45} PAMPHILE, THÉOPHANE et ESCLARMONDE Traceback (most recent call last): File « /home/benoit/test_pickle.py », line 35, in n = pickle.load(file_) EOFError: Ran out of input
Enregistrement des données
Ligne n° 1 : Importation du module pickle
Lignes n° 3 à 6 : création de quatre objets de type différents (int, float, list et dict)
Lignes n° 8 à 14 : Définition d’une classe First_name avec la méthode majuscules() qui permet de mettre en majuscules, une liste de prénoms passée en argument
Ligne n° 16 : Création de l’objet upper_names par instanciation de la classe First_name.
Ligne n° 18 : Création et ouverture d’un fichier en mode ‘wb’ c’est-à-dire en mode écriture et binaire. Le fichier s’appelle « donnees_enregistrees »
Lignes n° 19 à 23 : Enregistrement dans le fichier, de données de cinq types différents, à savoir int, float, list, dict et objet personnel. Cet enregistrement s’effectue grâce à la fonction dump() du module pickle. Cette fonction prend deux arguments qui sont la variable à enregistrer et l’objet correspondant au fichier cible (L’objet file_ correspond au fichier donnees_enregistrees)
À ce stade, vous pouvez vous amuser à ouvrir le fichier binaire « donnees_enregistrees », vous obtiendrez un incompréhensible baragouin où surnagent quelques prénoms qui n’ont pas encore sombré dans les abysses de la conscience-machine.
Restitution des données
Ligne n° 25 : Ouverture du fichier « donnees_enregistrees » en mode ‘rb’ c’est-à-dire en mode lecture et binaire. C’est la fonction load() du module pickle qui va nous permettre de restituer chaque donnée en respectant leur type d’origine! La fonction load() prend un argument qui est l’objet (file_) correspondant au fichier « donnees_enregistrees ».
Ligne n° 26 : restitution de l’objet correspondant au nombre entier 23 que nous stockons dans la variable i.
Ligne n° 27 : Le print de i et de son type nous confirme qu’il s’agit bien du nombre entier 23.
Lignes n° 28 à 33 : Même opération avec les variables j, k et l qui récupèrent respectivement un objet de type float (15.89), une liste et un dictionnaire.
Ligne n°34 : Ici, c’est un peu particulier… La variable m stocke l’objet que nous avons nous-mêmes créé par instanciation de la classe First_name.
Ligne n° 35 : Nous faisons un print() de m.majuscules(), c’est-à-dire que j’applique la méthode majuscules(),définie dans la classe First_name, sur l’objet m. Le résultat qui s’affiche est PAMPHILE, THÉOPHANE et ESCLARMONDE.
Ligne n° 36 : Toutes les données ont été restituées si bien que la dernière variable (n) n’a plus rien à stocker. C’est la raison pour laquelle Python nous retourne une exception (EOFError: Ran out of input).
Découper une base de données en plusieurs fichiers portant l’extension .pkl
Nous pouvons bien évidemment modifier les valeurs extraites et les enregistrer de nouveau à l’aide de la fonction dump(). Cela dit, si la base de données est très importante, le processus risque d’être un peu lourd et par conséquent, il s’en trouvera fortement ralenti.
Une solution consiste à découper la base de données en plusieurs fichiers portant l’extension ‘.pkl’. Analysons le code ci-dessous:
import pickle
import glob
int_number = 23
float_number = 15.89
first_names = ["Pamphile", "Théophane", "Esclarmonde"]
dictionary = {"Pamphile" : 32, "Théophane" : 54, "Esclarmonde" : 45}
class First_name(object):
def __init__(self, first_names):
self.p = first_names[0]
self.t = first_names[1]
self.e = first_names[2]
def majuscules(self):
return "{}, {} et {}".format(self.p.upper(), self.t.upper(), self.e.upper())
upper_names = First_name(first_names)
objects_list = [("int_number", int_number),
("float_number", float_number),
("first_names", first_names),
("dictionary", dictionary),
("upper_names", upper_names)]
for (x, y)in objects_list:
with open(x + '.pkl', 'wb')as file_:
pickle.dump(y, file_)
for f in glob.glob('*.pkl'):
with open(f, 'rb') as file_:
data = pickle.load(file_)
if type(data) == dict:
print(data)
data['Théophane'] = 89
print(data)
with open(f, 'wb') as file_:
pickle.dump(data, file_)
Ligne n° 2 : importation du module glob qui va nous permettre de faire l’inventaire du répertoire courant (/home/benoit) en lui appliquant un filtre (en l’occurrence l’extension *.pkl)
Ligne n° 19 : Nous créons une liste de tuples contenant les cinq objets de type différent que nous avons précédemment instanciés, associés au nom de leur futur fichier .pkl .
Lignes n° 25 à 27 : À l’aide d’une boucle for, nous créons le chemin de chaque fichier (x + ‘.pkl’) et nous enregistrons les données qui lui correspondent (y).
Ligne n° 29 : Nous faisons appel au module glob pour lister les fichiers portant l’extension .pkl.
Ligne n° 31 : Extraction des données
Ligne n° 32 : Nous créons une condition (Si les données sont de type dictionnaire…).
Ligne n° 34 : Nous modifions l’âge de Théophane.
Lignes n° 35 et 36 : Nous enregistrons les données modifiées dans le fichier binaire.
Au bout du compte, nous n’avons déchargé et chargé que les données que nous souhaitions modifier.