Ilphrin : Traduction: Guide du débutant en recherche UX
samedi 2 septembre 2017 à 06:00Cet article est une traduction de “Complete Beginner’s Guide to UX Research”, écrit par le site UXBooth. Je ne suis en aucun cas l’auteur de cet article, j’ai simplement eu envie de le traduire car le sujet m’intéresse et que je considère que beaucoup de ressources anglophones devraient/pourraient être aussi à la portée de personnes qui ne parlent pas anglais.
Guide du débutant en Recherche UX
Dans une industrie centrée sur les utilisateurs de nos services, applications et produits, la recherche est promordiale. Nous questionnons, notons, apprenons tout ce qu’il est possible sur le public cible, et procédons à des tests itératifs de notre travail tout au long d’un processus de conception.
La Recherche UX - ou, comme elle est souvent appelée, la Recherche de Design - sert à de nombreuses choses dans le processus de conception. Il nous sert à prouver ou infirmer des hypothèses, trouver des points communs entre les membres de nos publics cibles, et reconnaitre leurs besoins, objectif et modèles mentaux. De façon générale, la recherche renseigne notre travail, améliore notre compréhension, et valide nos décisions.
Dans ce Guide du Débutant, nous allons aborder les différents aspects de la Recherche de Design, à partir d’interviews et d’observations, des tests utilisateurs aux tests A/B. Les lecteurs auront un point de départ sur la façon d’utiliser les techniques de recherche dans leur travail, pour améliorer l’expérience des utilisateurs.
Qu’est-ce que la Recherche UX
La Recherche UX regroupe une large gamme de méthode de méthodes d’investigations qui aident à ajouter du contexte et des idées au processus de conception. Contrairement à d’autres sous-domaines de l’UX, la Recherche ne s’est pas développée dans d’autres domaines ou sous-domaines. Elle s’est simplement crée à partir d’autres formes de recherches. En d’autres termes, ceux qui pratiquent de l’UX empruntent des techniques d’universités, de scientifiques, des études de marché, etc. Cependant, il y a encore des types de recherche unique au monde de l’UX.
L’objectif principal de la Recherche de Design est d’aviser le processus de conception du point de vue de l’utilisateur final. C’est une recherche qui permet d’éviter de concevoir pour une personne: nous-mêmes. Il est commun de dire que le but de l’UX, ou conception utilisateur, est de faire un design avec l’utilisateur final en tête, et c’est la recherche qui permet de nous dire quelle est cette personne, dans quel contexte elle va utiliser le produit ou le service, et en quoi elle a besoin de nous.
Avec cette idée en tête, la recherche à deux parties: Récolter des données, et les synthétiser pour améliorer l’utilisation. Au début d’un projet, la recherche de conception sur l’apprentissage des requis du projet de la part des parties prenantes, et connaître les objectifs et besoins des utilisateurs finaux. Les chercheurs feront des interviews, des questionnaires, observer la perspectives des utilisateurs, et analyser les écrits, données et analyses existants. Ensuite, dans un travail de conception itératif, la recherche va se concentrer sur l’utilisation et les sentiments. Les chercheurs peuvent faire des tests d’utilisation ou des tests A/B, des interviews d’utilisateur sur le processus, et des hypothèses générales qui amélioreront le design.
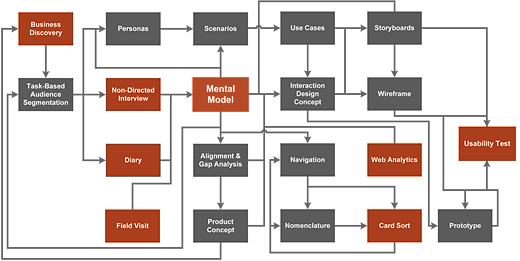
Nous pouvons aussi diviser les méthodes de recherche UX en deux catégories: quantitatives et qualitatives:
- La recherche quantitative est toute recherche qui peut être mesurée de façon numérique. Cela répond à des questions comme “Combien de personnes ont cliquées ici?” ou “Quel pourcentage d’utilisateurs arrive à faire telle action?”. Il est intéressant de comprendre ce genre de statistiques et ce qui arrive sur un site ou une application.
- La recherche qualitative, parfois appelé la recherche “soft”. Elle nous aide à comprendre pourquoi les gens font ce qu’ils font, et prend souvent la forme d’interviews ou de discussions. Les questions habituelles incluent “Pourquoi les utilisateurs ne voient pas le call to action?” ou “Qu’ont remarqué d’autres les utilisateurs?”. Bien que les chercheurs peuvent se spécialiser dans certains types d’interviews ou de tests, la plupart sont capables d’utiliser la majorité des techniques. Tous les chercheurs récupérent des informations qui nous permettent de concevoir d’une manière avertie, contextuelle, et centrée sur l’utilisateur.
Techniques communes
La gamme de recherches UX vont des interviews d’une personne aux tests A/B non modéré, avec tout ce qui existe entre les deux, bien qu’ils soient cohérents dans le fait qu’ils se basent tous sur les même méthodes-clés: observation, compréhension, et analyse.
Observation
La première étape d’une recherche consiste à apprendre à observer le monde autour de nous. Tout comme les débutants photographe, les nouveaux chercheurs doivent apprendre à voir. Ils doivent remarquer les tics qui indiquent que la personne questionné est stréssée ou indécise, et prendre des références, d’apparence mineure, qui peuvent refléter des croyances ou pensées de longue-date qui devraient être approfondies.
L’obeservation peur paraître simple, mais elle peut être nuancée par des reflexes ou préjugés inconscients, ce que tout le monde a. Les chercheurs en conception/design s’entrainent à observer et prendre des notes, pour qu’ils puissent plus tard trouver des modèles entres différents groupes de personnes.
Compréhension
Comme l’observation, la compréhension est quelque chose que nous faisons quotidiennement. Nous essayons de comprendre nos collègues, nos familles, et nos amis, souvent en voulant comprendre une dispute ou un concept avec lequel nous ne sommes pas familier. Mais pour les chercheurs UX, la compréhension à moins a voir avec ces désagréments, qu’avec les modèles mentaux.
Un modèle mental est l’image qu’une personne a en tête lorsqu’elle pense à une phrase ou une situation en particulier. Par exemple: Si quelqu’un possède un SUV, son modèle mental d’une “voiture” différera de quelqu’un qui dispose d’une voiture connecté. Le modèle mental nous renseigne sur les décisions que nous prenons. Dans le cas d’un propriétaire de voiture, lorsque nous demandons “Combien de temps cela prend pour aller jusqu’à Paris?”, sa réponse dépendra du kilométrage de sa voiture, entre autres.
Les chercheurs en design ont besoin de connaître les modèles mentaux des personnes qu’il interviewent ou testent, pour deux raisons. La première c’est que nous parlons tous avec un certaines abbréviations et langages technique parfois. Les chercheurs ont besoin de reconnaitre ces langages en se basant sur le modèle mental de l’interlocuteur. Ensuite, si le chercheur peut définir avec précision le modèle mental des utilisateurs, il ou elle peut partager ces informations avec l’équipe de design, et faire une conception en raccord avec ce modèle.
Analyse
La recherche en elle-même est utile, mais afin d’utiliser les idées pour renseigner la conception, elle a besoin d’être analysée et finalement présentée à une équipe. L’Analyse est le procédé par lequel le chercheur identifie des modèles dans la recherche, propose les raisonnements et solutions possibles, et fait des recommandations.
Les techniques d’analyses incluent la création de personas ou de scénarios, décrire des modèles mentaux, ou faire des graphiques qui représentent des statistiques ou des comportements utilisateurs. Bien que certaines techniques se concentrent principalement sur la conduite de recherches, il est important de se souvenir que la recherche n’est valable que si elle est partagée. Elle ne sert à rien si elle reste cloisonnée dans un cabinet, ou oubliée par l’excitation du design.
Tâches quotidiennes et Livrables
Chaque projet d’UX est différent, et les tâches que fera le chercheur différeront de ce qui pourrait être approprié dans une autre situation. Les formes de recherche les plus connues sont: les interviews, les questionnaires et sondages, la tri de carte, les tests d’utilisation, les tests d’arbre, et les tests A/B.
Interviews
L’interview en face-à-face est une méthode testée et approuvée de communication entre un chercheur et un utilisateur ou un intervenant. Il existe trois types d’interviews, chacune utilisée dnas un contexte différen et avec un objectif différent.
Les Interviews dirigés sont les plus fréquents. Ce sont des interviews typiques de question-réponse, où le chercheur pose des questions spécifiques. Cela peut être intéressant lorsqu’on questionne un grand nombre d’utilisateurs, ou pour comparer et contraster les réponses de plusieurs utilisateurs.
Les Interviews non dirigés sont le meilleur moyen d’apprendre sur des sujets plus délicats, ou l’utilisateur ou l’intervenant puisse être déstabilisé avec une question directe. Avec un interview non dirigé, l’interviewer met en places quelques lignes de conduites et ouvre une conversation avec la personne questionnée. L’interviewer va principalement écouter durant cette “conversation”, parlant uniquement pour demander à l’utilisateur de fournir des détails supplémentaires ou expliquer des concepts.
Les Interviews Ethnographiques consiste à observer des personnes agir dans leur “habitat naturel”. Dans cette catégorie d’interview, l’utilisateur montre comment accomplir certaines tâches, en mettant en immersion l’interviewer dans son travail ou sa culture. Cela peut aider les chercheurs à comprendre l’écart entre ce que les gens font, et ce qu’ils disent faire, et peut éclairer sur ce que font les utilisateurs lorsqu’ils se sentent le plus à l’aise.
Questionnaires et Sondages
Les questionnaires et les sondages sont un moyen facile de récupérer de grosses quantités d’informations sur un goupe en un minimum de temps. Ce sont de très bon choix pour la recherche sur les projets avec une vaste diversité de types d’utilisateurs, ou pour les groupes soucieux de l’anonymat. Un chercheur peut créer des sondages avec des outils tels que Wufoo ou Google Docs, les envoyer par email, et recevoir des centaines de réponses en quelques minutes.
Il existe des défaut cependant aux questionnaires et aux sondages. Le chercheur ne peut intéragir directement avec les questionnés ou les encadrer si la question n’est pas parfaite, et ont généralement peu de possibilités pour recontacter. Les sondages recoivent beaucoup plus de réponses s’il n’y a pas besoin de s’inscrire ou d’entrer des informations de contact, et cette anonymat rend impossible le fait de pouvoir demander une clarification ou des détails.
Card Sort (Tri de Cartes)
Les Tri de cartes sont parfois utilisés comme moyen d’interview ou comme test utilisateur. Dans un Tri de cartes, l’utilisateur reçoit un paquet de cartes, et il est demandé de les trier en catégories. Dans un Tri de cartes fermé, les noms des catégories sont aussi donnés; alors que dans un Tri de cartes ouvert l’utilisateur peut créer les catégories qu’il désire.
L4objectif du Tri de cartes est d’explorer les relations entre les différents contenus, et mieux comprendre la hiérarchie perçue par un utilisateur. Plusieurs stratégistes de contenu et d’architectes d’information se base sur cet outil pour tester des théories de hiérarchie ou commencer un plan de site.
Tests Utilisateur (Usability Tests)
Les Tests utilisateur nécéssitent de demander à quelqu’un, un utilisateur par exemple d’un produit ou service, de compléter une série de tâches et d’observer leur comportement afin de déterminer l’usabilité d’un produit ou d’un service. Ceci peut être fait avec une version en direct d’un site ou d’une application, un prototype ou un WIP (Work-In-Progress), ou même avec des maquettes clicable ou du papier et un crayon.
Il existe de nombreuses variations et styles de tests utilisateur, mais trois sont souvent utilisés: Controlés, Non Contrôlés, et en Guerilla
Les tests controlés sont les plus fréquents. Ils peuvent être fait en face-à-face, en vidéo ou par partage d’écran. Les laboratoires de tests utilisateurs sont équipés de miroirs semi-réfléchissant, pour que les collaborateurs puissent observer, pour conduire ces tests. Dans ces tests un facilitateur non biaisé s’asseoit et parle avec l’utilisateur, lisant à voix haute les tâches et demandant à l’utilisateur de dire ce qu’il pense lorsqu’il accomplit ces tâches. Le rôle du facilitateur est d’agir comme un pont entre les collaborateurs et l’utilisateur, posant des questions pour évaluer la pertinence d’un design et tester les hypothèses tout en aidant l’utilisateur à se sentir confortable dans le processus.
Les tests non controlés, connu aussi sous le terme de Recherche Asynchrone, sont fait en ligne à la convenance de l’utilisateur. Les tâches et les instructions sont fournies par vidéo ou enregistrement audio, et l’utilisateur clique sur un bouton pour commencer le test et enregistrer son écran et/ou l’audio. Comme lors des tests contrôlés, l’utilisateur est invité à penser à voix haute, bien qu’il n’y ai pas de facilitateur pour poser des questions. Ces tests sont disponibles à travers de nombreux sites web, et peuvent être bien moins cher que les tests contrôlés.
Un test Guerilla est une version plus traditionnelle, légère et moderne de tests. Au lieu de se passer dans un laboratoire, la recherche guerilla se passe souvent en lieu public: les utilisateurs sont pris dans des cafés, des stations de métro ou autre, et on leur demande d’accomplir quelques tâches avec un site web ou un service, en échange de quelques dollars, un café, ou simplement par bonté de coeur. Même si les tests guerilla sont très bien, surtout financièrement, ils sont plus adaptés aux produits avec une large base d’utilisateurs. Les produits de niche auront du mal à trouver des informations utiles à partir de la sélection aléatoire d’utilisateur de cette recherche.
Tests en arbre (Tree tests)
AU même titre que le tri de cartes est un bon moyen d’avoir des informations sur l’architecture d’un site web avant sa création, les tests en arbre sont un bon moyen de valider cette architecture. Dans ce test, l’utilisateur doit accomplir une tâche, avec comme outil le Sitemap d’un produit, en commencant par le niveau le plus haut. Ensuite, comme dans les Usability Tests, l’utilisateur est invité à penser à voix haute en remplissant la tâches. Mais au lieu d’avoir un écran pour naviguer, ils voient le prochain niveau d’architecture avec le Sitemap. L’objectif est de déterminer si l’information est catégorisée correctement, et si la nomenclature est appropriée.
Tests A/B
Les tests A/B sont un autre moyen d’apprendre quelles actions l’utilisateur entreprend. Un test A/B est souvent utilisé comme outil de recherche lorsque les designers n’arrivent pas à choisir entre deux versions. Que ce soit deux styles de contenu, un bouton VS un lien, ou deux approches pour une page d’accueil, un test A/B nécessite de montrer aléatoirement chaque version à un nombre égal d’utilisateur, et regarder ensuite les statistiques de l’application ou du site pour voir quelle version permet le mieux d’accomplir une tâche. Les tests A/B sont particulièrement utiles pour comparer une nouvelle version d’une page face à l’ancienne version, ou lors de collecte de données pour vérifier une hypothèse.
Des liens sur UxBooth
Si cette traduction vous a plu, n’hésitez pas à me le faire savoir, par mail ou par commentaire (je lis aussi de temps en temps les commentaire sur le journal du hacker). Je vous renvoie vers l’article d’origin sur UXBooth pour pleins de liens vers des personnalités à suivre sur les réseaux, des idées de livre sur le sujet, et plein d’autres choses.
Original post of Ilphrin.Votez pour ce billet sur Planet Libre.

Articles similaires
- Ilphrin : Traduction: Guide du débutant en recherche UX (05/02/2017)