Je tiens à remercier mon employeur pour me permettre de vivre cette expérience ainsi que les organisatrices et organisateurs pour leur confiance et leur accueil (vous vous reconnaitrez).
Merci également à toutes celles et ceux qui m’ont aidé également à monter en compétence en tant que speaker.
Et maintenant?
Grâce à l’initiative 1Tech-Rel de Worldline, j’ai pu faire des super rencontres et progresser techniquement dans certains domaines : Préparer et proposer un s ujet technique vous impose de le creuser à fond et de le maîtriser.
Pour l’année prochaine, on a quelques idées. J’espère pouvoir communiquer là-dessus rapidement.
Je vous souhaite en attendant un bon réveillon et si vous découvrez mon article en 2023 une bonne année.
2022 in few words
2023 is coming.
It is time to review 2022 in a professional point of view.
After moving on to another project early 2022, I had the opportunity on behalf of my company Worldline, to participate as a speaker to:
Thank you to my employer for giving me this opportunity and the organisers for their trust and their hospitality. I’m pretty sure you will recognise yourselves.
Thanks then to who helped me in my speaker journey.
And now, something completely different?
On behalf of the 2Worldline tech rel initiative, I had the chance to meet great people and move forward in some technical domains. Drawing up and submitting a talk about a technical topic requires you to dig into it and be proficient on it.
I already have ideas for the next year. I hope communicating about it shortly.
Best wishes for the new year eve and if you come across this article in 2023: Happy new year!!
c’est comme des dev rel mais on essaye d’inclure au delà des devs (ex. les OPS, SRE). ↩
It is just like dev rel, but we would like to include all the tech crew (e.g., OPS & SRE) ↩
Petit rappel, cet article est le second de notre série introductive sur la lecture d’empreinte digitale et fait suite à notre premier article intitulé un lecteur d’empreintes digitales, comment ça marche ?. Nous vous invitons à le lire avant celui-ci pour une compréhension optimale.
Un troisième article, cette fois-ci sous la forme d’un tutoriel plus technique, portera quand à lui sur l’utilisation du lecteur d’empreintes R307 avec le Raspberry Pi. Cette introduction faite, passons à l’article !
Maintenant que nous avons fait le tour des différentes technologies pour l’acquisition des empreintes, il nous reste à comprendre comment il est possible d’analyser et de reconnaître deux empreintes similaires.
À priori, on pourrait imaginer que la comparaison de deux empreintes est une tâche très simple. Après tout, ne suffit-il pas de superposer les deux images pour voir si elles correspondent ? Et bien en fait non, dans un monde parfait dans lequel chaque capture d’image serait parfaite et ou chaque empreinte resterait toujours la même, cela fonctionnerait effectivement, mais ce n’est hélas pas comme ça que les choses se passent !
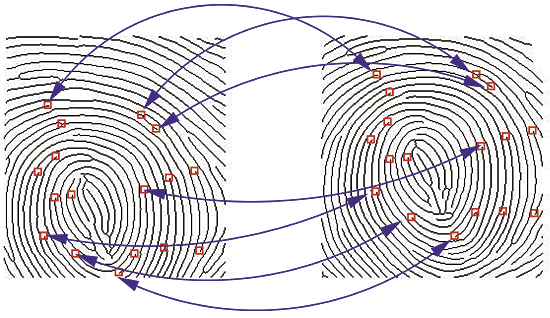
L’analyse d’une empreinte digitale, ne consiste pas simplement à superposer deux images. En effet, il s’agit ici de la même empreinte, et pourtant même si elles se ressemblent les deux images sont en fait complètement différentes. Source : Le Hong, Hai & Nguyễn, Hoá & Nguyen, Tri-Thanh. (2016). A Complete Fingerprint Matching Algorithm on GPU for a Large Scale Identification System.
Lors de la capture d’une empreinte, celle-ci n’est jamais parfaite, l’empreinte n’est jamais capturée dans son intégralité, la capture peut avoir quelques défauts, le capteur (ou même l’empreinte elle-même) peut être sale. L’empreinte peut aussi avoir un peu changé (une coupure, des travaux manuels qui ont abîmé quelques sillons, etc.). Sans compter que pour que l’image soit toujours la même, il faudrait que la pression appliquée par l’utilisateur lors de la lecture de l’empreinte soit, elle aussi, toujours exactement la même.
Vous l’aurez compris, la tâche est plus complexe que prévue, et comparer deux empreintes, ne revient en fait pas à comparer deux images telles quelles. En fait, la reconnaissance d’empreinte n’est absolument pas comme un mot de passe pour lequel on cherche une correspondance exacte. Dans le cas de la reconnaissance d’empreinte, tout est une question de taux de ressemblance, de probabilité, de motifs et de points de repères.
Le premier niveau de reconnaissance, le motif des empreintes.
Dans la reconnaissance d’empreinte, comme dans beaucoup de domaines liés à l’informatique d’ailleurs, on parle en fait de plusieurs niveaux de reconnaissance, chaque niveau supplémentaire permettant une correspondance plus précise, mais généralement aussi plus complexe.
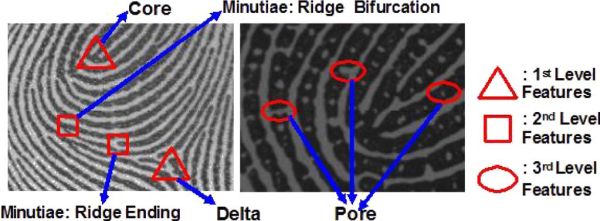
Au début de cet article nous avons expliqué qu’une empreinte était en fait un ensemble de sillons arrangés généralement selon l’un de ces trois motifs, arche, spirale ou boucle, vous vous souvenez ? Et bien ce type de motif, c’est déjà un premier niveau de reconnaissance d’une empreinte digitale !
Le niveau le plus simple de reconnaissance consiste à extraire le point central autour duquel se construit l’empreinte, puis à en extraire le motif.
Alors évidement, à première vue ce niveau 1 ne parait pas bien précis. Avec un simple calcul on en déduit que chaque empreinte à au minimum 1 chance sur 20 (5%, le pourcentage de motif « arche ») de correspondre à n’importe quelle autre empreinte. Et c’est absolument vrai, mais n’allez pas pensez pour autant que ce niveau 1 de la reconnaissance est inutile, loin de là !
Bien sûr, si vous avez déjà deux empreintes connues et que vous souhaitez simplement les comparer, cela n’a pas beaucoup d’intérêt, le taux d’erreur serait beaucoup trop important. Mais maintenant, imaginez la situation suivante, vous avez d’un côté une empreinte appartenant à une personne inconnue, par exemple une empreinte retrouvée sur une scène de crime, et de l’autre une base de données de plusieurs centaines de milliers d’empreintes, par exemple un registre de police. Votre objectif, retrouver dans cette base de données la personne à laquelle appartient cette empreinte.
Et bien, d’un seul coup, ce niveau 1 devient très intéressant ! En effet, déterminer le type d’empreinte est un travail simple, très rapide, et dont le résultat peut sans problème être calculé dès l’enregistrement de l’empreinte puis stocké directement à côté de l’empreinte de base sans devoir être recalculée à chaque fois. Il s’agit donc d’un critère sur lequel le travail de tri prendra moins d’une seconde pour le dernier des ordinateurs du dernier des commissariats du dernier village du bout du monde. À une époque, il s’agit même d’un travail de tri qui aurait été possible manuellement par une petite équipe de moustachus armés d’une machine à café en ordre de marche !
Hors, ce premier tri vous permet déjà d’éliminer de 40% à 95% des suspects, vous libérant le temps nécessaire à la réalisation des vérifications plus poussées du niveau suivant !
Par ailleurs, ce niveau 1 ne se résume pas seulement au motif, mais également à son orientation, au doigt ciblé, etc ! Oui, 5% des empreintes ont un motif d’arche, mais combien d’empreintes ont un motif arche, penché de 12° dans le sens horaire, sur le pouce gauche ? Et si vous possédez plusieurs empreintes à chercher en même temps, la liste se réduit encore !
Je ne crois pas que les lecteurs d’empreinte numérique aient jamais utilisé le niveau 1 de la reconnaissance comme un critère de reconnaissance suffisant, et si cela a jamais été le cas, ça ne l’est plus depuis longtemps. Mais le niveau 1 reste employé, non pas comme un moyen de reconnaissance formel, mais bien comme un système de tri ultra rapide !
Le deuxième niveau de reconnaissance, les minuties.
Quand on parle de reconnaissance d’empreinte, on parle en fait généralement de ce niveau 2, lequel se base sur l’analyse de ce que l’on appelle des « minuties ».
Nous l’avons dit, une empreinte c’est un ensemble de sillons arrangés selon un schéma. En théorie, une empreinte digitale, ça devrait donc ressembler à l’image ci-dessous à gauche, un ensemble de lignes bien parallèles suivant un schéma parfait. Dans les faits, une empreinte digitale, ça ressemble plutôt à l’image de droite.
À gauche une empreinte théorique, sans défaut, à droite une vraie empreinte.
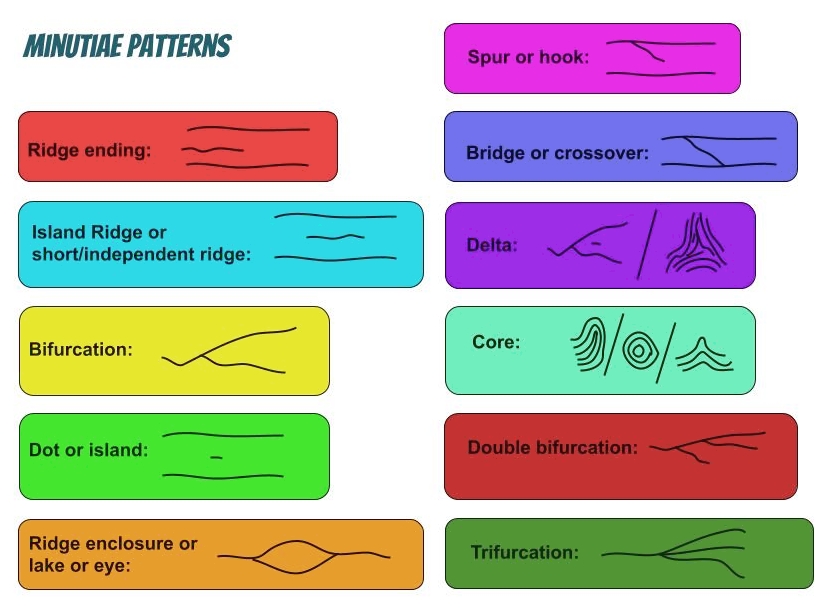
Certains sillons se rejoignent, d’autres se créent au milieu de nul part, certains s’arrêtent, il y a des coupures, des sillons qui bifurquent, etc. Au final on compte au moins 11 types de « défauts » différents et notables, parmi lesquels les plus remarquables sont les bifurcations (et leurs variantes), les fins et débuts de crêtes, les îlots, et les coupures de crêtes.
Représentation (un peu discutable, je l’admet) des différents types de minuties.
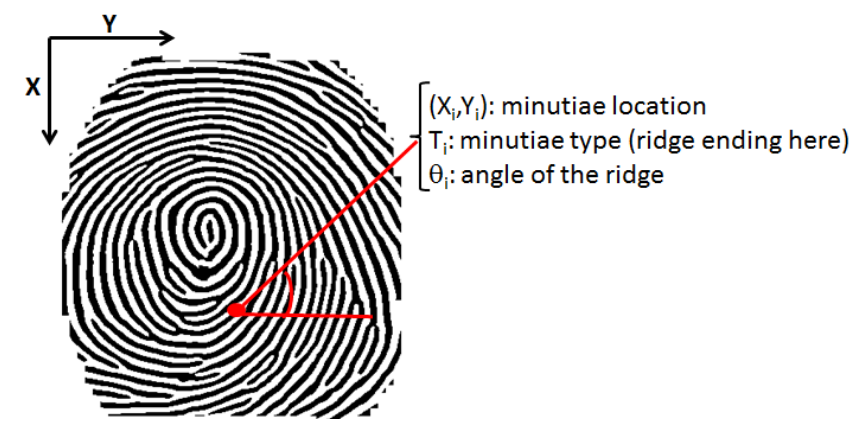
Tous ces défauts sont appelés des « minuties », et ce sont ces minuties qui vont nous servir à identifier une empreinte. Pour cela, on va noter l’emplacement de toutes les minuties visibles dans notre empreinte, leur type, leur orientation, et on va dresser une sorte de carte de leur positionnement relatif les unes par rapport aux autres.
Par exemple, on pourrait dire que la minutie A, est une interruption de crête, à un angle de 12°, et que la minutie B est un îlot de 5 pixels, à un angle de 17°, et que la minutie B est située à 25 pixels sur une ligne à 32° au dessus de la minutie A. Il s’agit ici d’une méthode de représentation relativement simple, mais des méthodes beaucoup plus poussées sont utilisées et font intervenir des notions de mathématiques et de géométrie que je ne maîtrise absolument pas, si le sujet vous intéresse, voici un exemple de papier scientifique sur le sujet.
De gauche à droite, l’image de base, l’image avec l’extraction des sillons, l’image avec uniquement les crêtes, et enfin l’emplacement de différentes minuties.
Source : Minutiae-based Fingerprint Extraction and Recognition, Naser Zaeri, 2010.
Au moment de comparer une empreinte, ce sont donc ces minuties qui vont êtres extraites et analysées. Comme nous l’avons dit plus tôt, l’image d’une empreinte n’est jamais une copie parfaite de celle-ci, et de nombreux défauts peuvent perturber l’image. C’est pour cette raison que les minuties sont stockées comme des références les unes par rapport aux autres, avec un niveau élevé de redondance. De façon à pouvoir être reconnues, non pas dans un cadre toujours identique, mais bien les unes par rapport aux autres, peu importe le cadre.
Par ailleurs, l’algorithme de correspondance ne va pas chercher une correspondance de toutes les minuties, ni une correspondance totale, car l’image d’une empreinte digitale étant toujours incomplète et de qualité variable, certaines minuties seront toujours manquantes. L’algorithme va donc plutôt chercher une correspondance suffisamment bonne et sur un nombre suffisamment élevé de minuties pour calculer un score de fiabilité quand à la correspondance des deux empreintes.
Un troisième niveau, plus rarement utilisé.
En plus du deuxième niveau, un troisième niveau de reconnaissance est possible. Celui-ci se base majoritairement sur la détection des pores de la peau, ainsi que les formes individuelles des crêtes, leur taille, leur orientation.
Différents types de minuties, avec à droite des pores, minuties de niveau 3. Source : Zhang et al., 2011
Ce niveau de détection reste aujourd’hui relativement rare, notamment car il demande des capteurs de très haute qualité, des empreintes très propres, etc., parce-que que le niveau 2 reste suffisant pour la vaste majorité des usages, et parce qu’ajouter davantage de minuties augmente de façon finalement peu utile l’espace nécessaire au stockage des données.
Un dernier défi, le stockage et la recherche des empreintes.
Si nous savons maintenant comment une empreinte est analysée afin de pouvoir être comparée, il reste un défi de taille, le stockage de ces empreintes. Là encore, on pourrait se dire que la solution est simple, il nous suffit de stocker les photos originales des empreintes.
Effectivement, la chose est faisable, après tout, stocker les empreintes de 10 millions de personnes, à raison de 10 empreintes par personnes, et pour des fichiers de 256*256 pixels, cela représente, environ 3 Ko par empreinte, sans aucune compression, c’est-à-dire 30 Ko par personne, soit 300 Go, un petit disque dur. Il serait donc tout à fait possible sur le plan technique de stocker toutes ces images, et c’est d’ailleurs à priori ce que fait la justice.
Seulement, tout l’intérêt d’une base d’empreintes ce n’est pas simplement de stocker les empreintes, mais bien de pouvoir rechercher des empreintes à l’intérieur de cette base ! Si nous stockons uniquement nos empreintes sous forme de photos, nous sommes obligés de refaire le processus de calcul pour chaque image de la base à chaque recherche d’empreinte. Autant vous le dire tout de suite, ce serait très long et très cher.
Par ailleurs, si on peut espérer (on a le droit de rêver) qu’un état est capable, dans un cadre centralisé, de stocker de façon sécurisée ce type de données hautement sensibles sur le plan de la vie privée, qu’en est-il pour des entreprises privées, toujours prêtes à vendre nos données personnelles, et pour des objets hautement décentralisés et par nature dérobables physiquement, comme les téléphones ?
Personnellement, je ne ferais pas non plus tellement confiance à l’état pour utiliser et stocker correctement nos données…
Pour ces différentes raisons, la plupart du temps les empreintes ne sont en fait pas (ou pas uniquement) stockées sous forme d’images, mais sous forme de signature, généralement désignée comme un « template ». Cette signature contient habituellement un certain nombre de minuties (souvent uniquement les X plus importantes, ceci pour réduire le poids de la signature), lesquelles sont représentées selon leurs différentes propriétés selon un encodage adapté. Il peut exister différents formats de template, avec certains formats propriétaires, mais globalement et malgré quelques critiques, la norme ISO/IEC 19794-2 semble être ce que nous avons de plus proche d’un standard reconnu en la matière.
Grâce à cette représentation simplifiée, l’ensemble du traitement relatif à l’extraction des données est effectué une seule fois puis stocké, ne laissant plus à faire que le travail de comparaison et de calcul du taux de correspondance. Ainsi, en combinant des techniques de recherche rapide de niveau 1 et en stockant une partie du travail de niveau 2, il devient possible de faire des recherches dans de grands volumes de données dans des temps qui restent raisonnables.
Par ailleurs, cette forme de stockage permet de limiter les risques en cas de vol des données, car même s’il est théoriquement possible de recréer une empreinte qui produira une signature valide à partir d’une signature donnée, il semble pour l’heure impossible de reconstruire une empreinte parfaitement similaire à l’originale à partir de cette signature par essence incomplète.
Extraction des données d’une minutie.
De nombreux lecteurs d’empreintes sont capables d’effectuer directement ces traitements pour ne transmettre à l’ordinateur connecté que le template final, voir de sauvegarder en interne les templates et d’effectuer la recherche de correspondances directement en interne.
Mais au final, les empreintes digitales sont-elles vraiment fiables ?
Comme nous l’avons vu, contrairement à une vérification par mot de passe pour laquelle on obtient une réponse booléenne, avec une comparaison qui sera soit vraie, soit fausse, une empreinte retournera plutôt une probabilité, un taux de confiance quand à la correspondance de deux empreintes.
En matière d’empreinte et de traitement numérique, il n’existe jamais de certitude absolue, il nous appartient de fixer un seuil que nous considérerons comme adapté selon nos besoins. Ce seuil sera nécessairement un compromis entre le niveau de certitude, le temps de traitement et le taux de faux négatifs, c’est à dire d’empreintes qui auraient du correspondre, mais sont considérées comme différentes par le lecteur, par exemple en raisons de défauts dans l’image capturée.
Ce seuil peut et dois donc varier selon les besoins, il est la plupart du temps adaptable soit par l’utilisateur soit par le constructeur de l’appareil.
Déverrouiller son téléphone sous la pluie, une de ces choses si simples qui vous donnent envie de voir le monde brûler dans des hurlements…
Pour déverrouiller votre téléphone ou votre porte de maison, certes, la sécurité est importante. Mais, si cela vous permet d’ouvrir sous la pluie avec le doigt un peu humide, il est préférable que votre empreinte soit considérée comme valide avec seulement 7 points correspondants et risques de faux positif de 0.00001%, plutôt que de passer la nuit dehors avec un taux d’erreur 10 fois plus faible.
Pour qu’une empreinte soit valide dans une affaire criminelle en revanche, on peut estimer qu’une fiabilité très forte est la règle primordiale, quitte à utiliser une fiabilité plus faible lors des phases de recherches pour limiter la puissance de calcul nécessaire, et donc le temps de recherche, et faire un second examen par la suite.
En France, le système judiciaire considère qu’il faut 12 minuties suffisamment proches de l’originale pour déclarer que deux empreintes correspondent. Ce chiffre représente globalement assez bien la moyenne en Europe. Aux USA en revanche, la barre est fixée à 8. Enfin, les français se souviendront du cas dit du « faux Xavier Dupont de Ligonnès », quand un homme avait été arrêté à tort à Glasgow, les enquêteurs ayant détecté une concordance partielle de ses empreintes avec celles de l’homme en fuite. Les enquêteurs n’avaient en fait que 5 points de correspondance…
Par ailleurs, il est à noté que des attaques sur les lecteurs d’empreintes ont non seulement été théorisées, mais également démontrées et exploitées. Les capteurs les plus performants peuvent être dotés de contre-mesures de sécurité plus ou moins efficaces, mais oui, dans une certaine mesure, le truc de la colle qu’on voit dans les films fonctionne vraiment. Pour plus d’infos sur le sujet, je vous conseille l’excellente vidéo de Scilabus sur le sujet.
La vidéo de Scilabus sur le sujet est vraiment intéressante, d’ailleurs toutes les vidéos de Scilabus sont intéressantes.
Enfin, l’empreinte digitale souffre, en comparaison à un mot de passe de bonne qualité, de certains défauts, parmi lesquels on peut citer : l’impossibilité de changer son empreinte digitale (par exemple en cas de vol du fichier contenant l’empreinte originale) ; l’impossibilité de transmettre son empreinte digitale à une autre personne en cas de besoin ; la possible altération de l’empreinte digitale (par exemple en cas de blessure grave) ; l’existence physique de l’empreinte digitale qui permet sont utilisation illégitime par la contrainte ou la ruse.
J’espère que cet article vous aura intéressé et permis de mieux comprendre le processus complexe derrière la reconnaissance d’empreinte. Je vous retrouve dans quelques semaines pour le dernier article de notre série, avec cette fois un article plus technique pour apprendre à utiliser un lecteur d’empreinte digitale avec le Raspberry Pi. D’ici là soyez sage, et ne jouez pas avec la colle !
Ces douze derniers mois ont été extrêmement riches avec une activité associative prenante, un projet de construction de maison qui démarre enfin, le démarrage d'une entreprise, un nouveau job et la maintenance de logiciels libres 🙂.
En début d’année, un véritable virage a été pris par l'association Tinternet & Cie. En effet, nous avons décidé de renforcer notre équipe d’intervenant⋅e⋅s et d’employer une coordinatrice et nous en sommes très fiers ! Le projet, mené en collaboration avec le département du Doubs, a permis de mettre en œuvre plus de 150 interventions durant le premier semestre dans de nombreux établissements scolaires, notamment des collèges et lycées 👩🏫. Par ailleurs, nous avons également mené de nombreuses permanences pendant lesquelles nous parlions de logiciels libres et de vie privée. Tout cela va continuer en 2023 !
Depuis fin 2021, ma moitié et moi avons démarré un des grands projets de notre vie, la construction d'une maison 🛖. Nous avons du passé de nombreux mois dans les papiers, stressé⋅e⋅s par une situation économique compliquée. Fort heureusement, nous avons eu un peu de chance et les travaux ont démarrés début décembre !
En milieu d'année, j'ai décidé de quitter le poste de responsable informatique dans lequel j'évoluais depuis quelques années. Je désirais me reconcentrer dans le développement web et l'administration système. J'ai donc rejoins Trinaps, un opérateur local avec de belles valeurs et une équipe ultra motivante ! Cela m'a permis d'apprendre Ruby, un langage que j'avais tendance à fuir jusqu'à présent 😌
À coté de ça, un ami me parlait de son projet d'entreprise intimement lié au RGPD, le Règlement Général sur la Protection des Données et pour un tas de bonnes raisons, j'ai décidé de l'accompagner.
Enfin, j'ai continué de maintenir mes projets avec une attention particulière portée sur Murph, mon CMF qui repose sur Symfony, et Custom Menu, une application destinée à Nextcloud.
Tout cela m'amène à des semaines bien remplies mais j'ai bon espoir de bientôt pouvoir respirer et profiter !
J’ai démarré le développement avant l’annonce officielle de la version 3.0 de Spring Boot.
Ce n’était pas réellement obligatoire pour cet atelier, mais j’ai souhaité quand même migrer cette application dans la dernière version de Spring Boot/Framework.
Je vais décrire dans cet article comment j’ai réussi à migrer toute cette stack et les choix que j’ai fait pour que ça fonctionne.
Bien évidemment, cette application n’est pas une “vraie” application en production.
Par exemple, je n’ai qu’une seule entité JPA…
Cependant, je la trouve représentative et espère (très modestement) que mon retour d’expérience pourra servir.
Ensuite, j’ai utilisé les versions suivantes pour les différents composants spring:
Spring Boot : 3.0.0
Spring Cloud : 2022.0.0-RC2
Spring Dependency Management : 1.1.0
Dans mon application, j’utilisais certains plugins Gradle pour la génération du code notamment OpenAPIGenerator. Pour ce dernier, j’ai ajouté un paramètre pour le rendre compatible avec spring boot 3:
useSpringBoot3:"true"
Bref, il faut impérativement tous les mettre à jour et vérifier la compatibilité !
Ajout de nouvelles dépendances
Pour vérifier la pertinence de certaines propriétés dans la nouvelle version, Spring a mis à disposition ce plugin:
Il permet de notifier à l’exécution si un paramètre est déprécié ou totalement inutile.
Migration namespace javax vers jakartaee
Selon votre code, les dépendances que vous pouvez avoir, cette étape pourra aller du renommage des import javax vers jakarta à d’innombrables maux de tête.
Si vous utilisez Spring Boot au-dessus d’un Tomcat (c.-à-d. en mode old school), il vous faudra mettre à jour le conteneur de servlet à une version compatible.
Dans mon application, je n’ai eu qu’à modifier les imports dans les entités, filtres et méthodes annotées par l’annotation @PostConstruct().
J’ai suivi cet article paru sur le blog de Spring.
J’ai par conséquent basculé sur Zipkin (pour mon Workshop, l’utilisation du distributed tracing est un peu la cerise sur le gâteau).
Je pense que j’aurai pu faire fonctionner Jaeger.
Je n’ai pas voulu perdre de temps (SnowcampIO arrive bientôt…).
Securité
J’ai eu quelques soucis après avoir mis à jour Spring Authorization Server et Spring Security.
Je pense que la version précédente de Spring était plus permissive sur l’injection et le nom des beans chargés dans les classes Configuration.
Vous l’aurez compris, si vous faites l’effort de suivre régulièrement les versions de Spring, vous devriez venir à bout facilement de la migration vers la dernière version de Spring.
Néanmoins, sur des projets conséquents (et je ne parle pas de ceux où il n’y a de tests automatisés…) ça peut s’avérer coûteux.
Certaines actions et contournements peuvent prendre du temps (ex. javax –> jakarta).
Enfin, je vous conseille d’attendre la première version mineure et la version définitive de Spring Cloud avant de vous lancer pour “de vrai”.
Bien que Spring ait fait un effort de documentation pour la migration, il est plus sage d’attendre que les premiers correctifs soient publiés avant de vous lancer.
Le FabLab des fabriques de Besançon et l’association Tinternet & cie vous invitent pour une journée de découverte et de fabrication le samedi 21 janvier 2022 !
Programme de la journée
9h30 : Accueil des participants, présentation des intervenants et de la journée.
10h : Présentation et discussion sur l’IoT et la vie privée à travers deux cas d’usage
Les jouets et les accessoires connectés
La maison connectée
11h30 : Présentation de notre l’IoT à fabriquer
13h : Repas (offert par Tinternet), moment de convivialité
14h : Point et discussion sur les objets connectés dans le monde de la santé
15h : Fabrication et bricolage
16h30 : Présentation et discussion sur l’impact environnemental des objets connectés