L'autre jour je vous présentait l'installation de
Transmission, un client de torrent basique, mais stable, et très facile à installer. Pour ceux d'entre vous qui sont prêts à passer un peu plus de temps pour avoir un client plus performant et plus design, voici
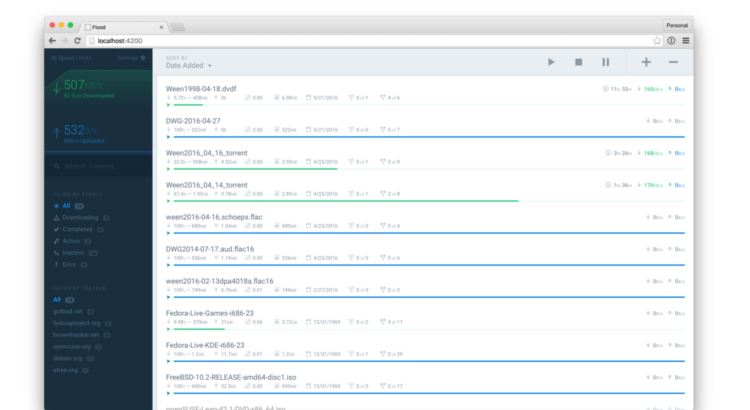
Flood !
C'est une interface web en nodejs ( :-? ) pour
rTorrent, un client en lignes de commandes qui est stable et léger, et qui est souvent utilisé avec
Rutorrent, une interface web qui elle est en PHP (mais moins jolie !).
Pour ceux qui veulent voire à ça ressemble, j'ai mis une petite galerie à la fin de l'article. :)
Une Seedbox ?
Une seedbox est un serveur dédié au téléchargement et au partage de fichiers torrents. Flood est une interface web qui nous permet de télécharger ces fichiers.
Pourquoi avoir une seedbox ? Le fait que ce soit un serveur signifie que :
• vous avez beaucoup de stockage
• vous avez beaucoup de bande passante, donc des téléchargements rapides
• vous n’êtes pas surveillés par HADOPI
• vous pouvez regarder vos films ou séries en streaming depuis votre serveur.
Installation de rTorrent et libTorrent
Flood n'étant qu'une interface web pour rTorrent, nous allons d'abord devoir l'installer.
Depuis les dépôts
rTorrent est disponible dans
les dépôts de Debian en version 0.9.2 et libTorrent en version 0.13.2, sachant que les dernières versions disponibles, même si elles ont plus d'un an, sont respectivement la 0.9.6 et 0.13.6, qui elles sont disponibles sous Debian Sid et Stretch.
Si vous avez la flemme de compiler vous pouvez tout de même les installer :
apt install rtorrent
Depuis les sources
Ainsi pour avoir les dernières versions, on peut compiler
rTorrent et
libTorrent directement depuis les sources.
On installe les dépendances :
apt install build-essential subversion autoconf g++ gcc ntp curl comerr-dev pkg-config cfv libtool libssl-dev libncurses5-dev ncurses-term libsigc++-2.0-dev libcppunit-dev libcurl3 libcurl4-openssl-dev
XML-RPC permet rTorrent de communiquer avec Flood.
On le télécharge :
svn co -q https://svn.code.sf.net/p/xmlrpc-c/code/stable /tmp/xmlrpc-c
On le compile :
cd /tmp/xmlrpc-c
./configure
make -j $(nproc)
On l'installe :
make install
On télécharge libTorrent :
cd /tmp
curl http://rtorrent.net/downloads/libtorrent-0.13.6.tar.gz | tar xz
On le compile :
cd libtorrent-0.13.6
./autogen.sh
./configure
make -j $(nproc)
Et on l'installe :
make install
On télécharge rTorrent :
cd /tmp
curl http://rtorrent.net/downloads/rtorrent-0.9.6.tar.gz | tar xz
On le compile :
cd rtorrent-0.9.6
./autogen.sh
./configure --with-xmlrpc-c
make -j $(nproc)
Et on l'installe :
make install
ldconfig
Vous êtes toujours là ? :lol:
Configuration de rTorrent
On ajoute un utilisateur pour éviter de lancer rTorrent en root :
adduser --disable-password rtorrent
On édite la configuration de rTorrent :
nano /home/rtorrent/.rtorrent.rc
Et on ajoute ceci :
# Vitesse de téléchargement max up/down, en KiB. "0" équivaut à aucune limite.
download_rate = 0
upload_rate = 10000
# Nombre maximal de téléchargements simultanés
max_downloads_global = 10
# Nombre maximal de peers par torrent
max_peers = 100
# Nombre maximal de peers à upload par torrent
max_uploads = 20
# Répertoire qui contient les fichiers téléchargés.
directory = /srv/seedbox/downloads
# Répertoire où rtorrent stocke l'état de téléchargement des torrents.
session = /srv/seedbox/.session
# Ports utilisables par rTorrent. 2x la même valeur = 1 port
port_range = 49999-49999
port_random = no
# Vérification des données à la fin du téléchargement
check_hash = yes
# Activation de DHT pour les torrents sans trackers.
# À désactiver si vous utilisez des trackers privés
dht = auto
dht_port = 6881
peer_exchange = yes
# On préfère les échanges avec chiffrement
encryption = allow_incoming,try_outgoing,enable_retry
# On autorise les trackers UDP
use_udp_trackers = yes
# Port SCGI, on en a besoin pour communiquer avec Flood
scgi_port = 127.0.0.1:5000
On n’oublie pas de créer les dossiers qui vont bien :
mkdir /srv/seedbox
mkdir /srv/seedbox/downloads
mkdir /srv/seedbox/.session
Et on applique les bonnes permissions à tout ça :
chmod 775 -R /srv/seedbox
chown rtorrent:rtorrent /srv/seedbox
Il faudra démarrer rTorrent à la main. J'aurai préféré le faire avec des services, mais ceux que j'ai trouvé ne marchent pas du tout, ou à moitié, et j'ai pas les connaissances nécessaires pour les débugger. De toute façon ils utilisaient screen ou dtach. Si quelqu'un passe par là et a un script d'init qui fonctionne, je suis preneur. :)
On va utiliser screen :
apt install screen
screen nous permet de créer des terminaux virtuels, de les laisser tourner en arrière plan, et d'y revenir quand on veut. Personnellement je m'en sert très souvent pour des processus un peu longs. :)
On crée le terminal du nom de "rtorrent" comme ceci :
screen -S rtorrent
On y entre automatiquement. Ensuite on change d'utilisateur :
su - rtorrent
Et on lance rTorrent :
rtorrent
Pour arrêter rTorrent, il faut faire
ctrl + q.
Pour quitter screen sans cloturer le terminal, il faut faire
ctrl + a puis
d. Pour clôturer le terminal, il faut fermer rTorrent puis écrire
exit et le screen se fermera tout seul.
Vous reviendrez ensuite dans votre "ancien terminal" qui n'a pas bougé non plus.
Pour retourner dans le screen de rTorrent :
screen -r rtorrent
Et même manip' pour le quitter ou le fermer.
Installation de Flood
On passe au morceau qui nous intéresse : l'interface web. C'est du nodejs, donc il va falloir installer ce dernier :
curl -sL https://deb.nodesource.com/setup_4.x | sudo -E bash -
sudo apt-get install -y nodejs
Ensuite, on installe git :
apt install git
Puis on va récupérer le code source de flood :
mkdir /srv/seedbox
cd /srv/seedbox
git clone https://github.com/jfurrow/flood.git
On ajoute la conf de flood :
cd flood
cp config.template.js config.js
On l'installe :
npm install --production
Là non plus, pas de script d'init, j'ai essayé avec
forever pour les connaisseurs mais ça ne marche pas. Je n'ai pas réussi à faire de script d'init, d'autant plus que le dev lui même conseille d'utiliser screen... donc maintenant que l'on connait, autant en profiter. J'ai quand même ouvert une
issue à ce sujet.
On ajoute un utilisateur pour éviter de lancer flood en root par la suite :
adduser --disable-password flood
On crée un screen :
screen -S flood
On change d'utilisateur :
su - flood
Puis on lance flood :
cd /srv/seedbox/flood
npm run start:production
(Vous pouvez sortir du screen avec
ctrl + a puis
d par la suite)
Flood est désormais accessible via
http://IP_DU_SERVEUR:3000
À votre première connexion il vous sera demandé de créer un compte, et puis après, vous êtes prêts à faire chauffer la connexion ! :-D
Mettre à jour Flood
Il suffit de récupérer le nouveau code et de relancer flood.
screen -r flood
ctrl + c pour l'arrêter puis
ctrl + a et
d pour sortir de flood
cd /srv/seedbox/flood
git pull
Vous devriez vérifier au cas où il y ait des changements dans config.sample.js.
On met à jour flood :
npm install --production
Et on le relance :
screen -r flood
npm run start:production
Docker
Si vous êtes un adepte de Docker, une image "officielle" est en cours de discussion
ici, et WonderFall en a fait une très bien
ici.
D'ailleurs, je me tâte à faire ma seedbox sous Docker moi. ^^
Reverse proxy Nginx avec HTTPS
Vous me connaissez, tant qu'on y est, autant faire les choses proprement : accéder à Flood via un domaine, le tout en HTTPS !
Pré-requis : avoir un domaine/sous domaine qui pointe l'IP du serveur.
Ici je prends comme exemple
seedbox.hadopi.fr. 8-)
Installation de Nginx
On suit mon
petit guide :
wget -O - https://nginx.org/keys/nginx_signing.key | apt-key add -
echo "deb http://nginx.org/packages/debian/ $(lsb_release -sc) nginx" > /etc/apt/sources.list.d/nginx.list
apt update
apt install nginx
Génération d'un certificat avec Let's Encrypt
On suit aussi mon petit gui... Oups, j'en ai pas encore fait :lol:
On installe l'outil depuis les backports de Debian :
echo "deb http://httpredir.debian.org/debian jessie-backports main" >> /etc/apt/sources.list
apt update
apt install -t jessie-backports letsencrypt
On arrête Nginx pour laisser le port 80 libre :
service nginx stop
On génère le certificat :
letsencrypt certonly -d seedbox.hadopi.fr --agree-tos -m contact@hadopi.fr --rsa-key-size 4096 --standalone
On configure nginx :
nano /etc/nginx/conf.d/seedbox.conf
Et hop (à adapter bien sûr) :
server {
listen 80;
server_name seedbox.hadopi.fr;
return 301 https://seedbox.hadopi.fr$request_uri;
access_log /dev/null;
error_log /dev/null;
}
server {
listen 443 ssl http2;
server_name seedbox.hadopi.fr;
access_log /var/log/nginx/seedbox-access.log;
error_log /var/log/nginx/seedbox-error.log;
location / {
proxy_pass http://127.0.0.1:3000/;
proxy_set_header Connection "";
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_pass_header X-Transmission-Session-Id;
}
ssl_certificate /etc/letsencrypt/live/seedbox.hadopi.fr/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/seedbox.hadopi.fr/privkey.pem;
ssl_trusted_certificate /etc/letsencrypt/live/seedbox.hadopi.fr/chain.pem;
ssl_protocols TLSv1.2;
ssl_ecdh_curve secp384r1;
ssl_ciphers EECDH+AESGCM:EECDH+AES;
ssl_prefer_server_ciphers on;
resolver 80.67.169.12 80.67.169.40 valid=300s;
resolver_timeout 5s;
ssl_stapling on;
ssl_stapling_verify on;
ssl_session_cache shared:SSL:10m;
ssl_session_timeout 5m;
ssl_session_tickets off;
}
Et peut démarrer Nginx :
service nginx start
Et voilà ! J'avoue, l'article est un peu long, mais ça vaut le coup non ? Pouvoir télécharger des ISO Linux avec style, c'est pas donné à tout le monde. 8-)
Je vous laisse avec quelques captures d'écran (ce client tellement bien fini, y'a même des petites animations) :
[gallery columns="4" link="file" ids="3657,3650,3652,3659,3651,3646,3654,3647,3653,3658,3648,3656,3655"]
J'adore !
Dans un prochain article, on verra comment streamer tout ça depuis sa seedbox. À suivre !
Sources :
L'article Seedbox : installer le client torrent Flood sous Debian 8 a été publié sur Angristan

Original post of Angristan.Votez pour ce billet sur Planet Libre.