Wooster by CheckmyWebsite : HHVM : Mode « turbo boost on » pour vos applications PHP ?
vendredi 10 octobre 2014 à 09:00Me faire une première opinion de la chose en quelque sorte !
HHVM, qu’est ce que c’est ?
D’après le site officel, HHVM se définit comme suit :
HHVM est une machine virtuelle Open Source créée pour exécuter des programmes écrits en Hack et PHP. HHVM utilise la compilation à la volée « Just In Time » pour obtenir des performances supérieures tout en maintenant la fexibilité de développement que procure PHP.
Ce projet développé par facebook pour ses besoins internes est comptatible avec la majorité des frameworks PHP qui comptent dans le monde libre.
Alléchant non ? Quel gain peut-on espérer au niveau performance ? L’installation de Wordpress va t’elle continuer à fonctionner correctement ? Pour cela, rien de tel qu’un petit banc de test.
Installation et test de HHVM
L’installation de Wordpress utilisée est la dernière version disponible à l’écriture de cet aricle ; soit la 4.0. Aucune manipulation n’est faite après installation, c’est donc une installation « out of the box ».
Installation de HHVM
L’installation sur Ubuntu 14.04 LTS 64 bits ne pose pas de problème particulier puisque des binaires existent pour la plateforme. Il suffit d’ajouter le bon dépôt et zou !
wget -O - http://dl.hhvm.com/conf/hhvm.gpg.key | sudo apt-key add -
echo deb http://dl.hhvm.com/ubuntu trusty main | sudo tee /etc/apt/sources.list.d/hhvm.list
sudo apt-get update
sudo apt-get install hhvmSi vous souhaitez que HHVM soit automatiquement démarré au boot de la machine :
sudo update-rc.d hhvm defaultsEt enfin, la génération de la configuration de HHVM pour Nginx
sudo /usr/share/hhvm/install_fastcgi.shCe script installe le fichier de configuration HHVM nécessaire à Nginx dans /etc/nginx/hhvm.conf. Il contient ceci :
location ~ \\.(hh|php)$ {
fastcgi_keep_conn on;
fastcgi_pass localhost:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}Il est maintenant possible de complètement désinstaller PHP et ses modules, en bref virer php5-fpm.
sudo apt-get remove php5-fpm php5-commonÇa fait bizarre quand même !
Configuration de Nginx pour HHVM
Dans le fichier de configuration du site, je remplace complètement la déclaration du traditionnel bloc location ~ \\.php$ par un include hhvm.conf; qui est le fichier généré automatiquement par la commande utilisée ci-dessus.
Les performances, ça donne quoi ?
Nous commençons par tester un blog Wordpress posé sur un setup classique; soit Nginx + MariaDB + php5-fpm et ensuite ce même blog avec un setup HHVM.
J’ai procédé au test avec Check my Website, ce qui me permet de voir si ce changement peut avoir un impact sur les métriques principales d’un site web.
Dès que HHVM est mis en œuvre, le site gagne quelques précieuses millisecondes sur le temps de réponse du serveur. Sur les tests effectués, j’ai gagné à chaque fois environ 20% de temps de réponse avec HHVM.
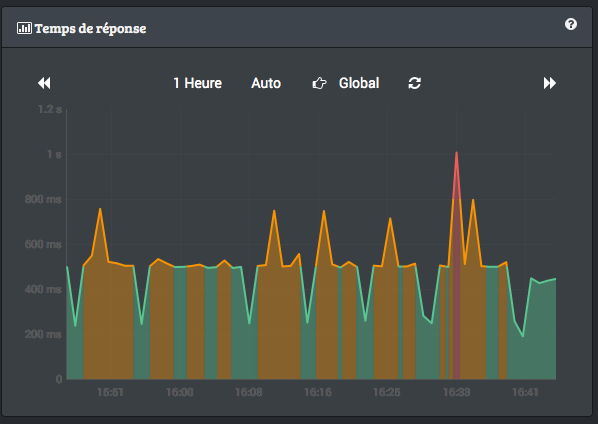
Cette tendance est confirmée par le même graphe mais sur une échelle de temps plus longue. On continue à bien voir la rupture qui correspond à la mise en route de HHVM?
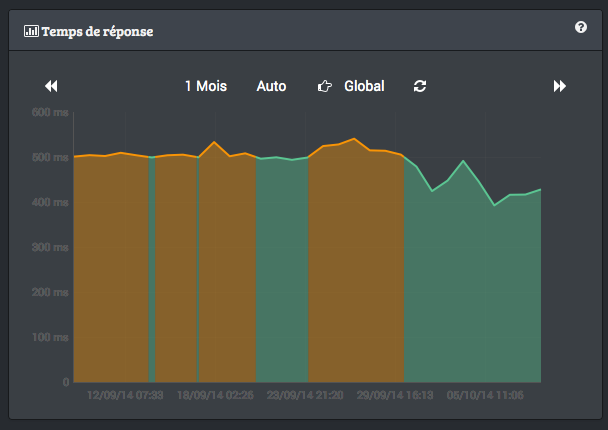
À l’inverse, dès que je stoppe HHVM et repasse sur un setup plus classique, le temps de réponse du serveur remonte inexorablement.
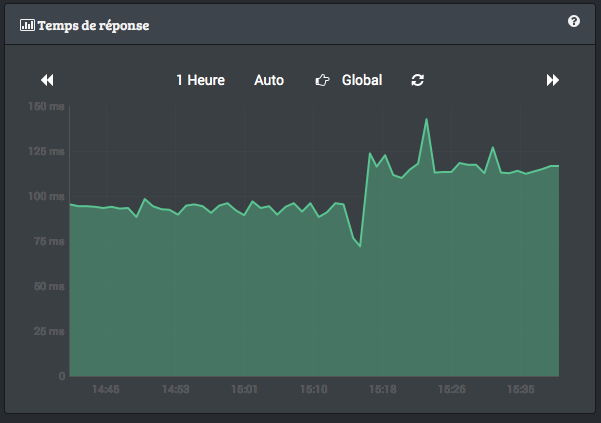
Par contre, le temps total de chargement de la page ne bouge pas ou peu. la conclusion semble donc être que HHVM joue beaucoup plus sur la capacité pour le serveur à répondre rapidement à la requête qu’à servir la page complète.
Ce test n’est qu’un test rapide du potentiel de HHVM et il conviendrait de le pousser plus loin pour affiner ces résultats. Ça donne envie d’aller plus loin par contre car le potentiel semble intéressant.
Ça sent la migration
Pour le moment, que du bon donc ! J’ai aussi testé HHVM avec Dokuwiki et n’ai pas rencontré de problème particulier après bascule vers celui-ci. Il me reste à voir comment on peut balancer la charge entre plusieurs instances HHVM comme on le fait depuis Nginx vers plusieurs php5-fpm et le compte sera bon.
Je pourrais alors gentiment entreprendre la migration des quelques sites Wordpress et consorts que j’opère pour le compte de tiers vers cette nouvelle architecture.
Original post of Wooster by CheckmyWebsite.Votez pour ce billet sur Planet Libre.