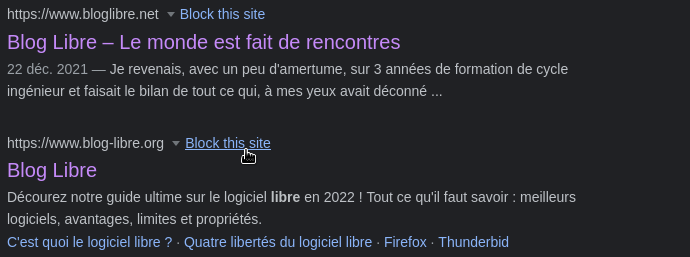
Vous considérez les clones pourris de StackOverflow/GitHub (die qastack die !) comme un cancer du web et n’en pouvez plus de les voir parasiter vos recherches ? Vous en avez marre des résultats Instagram/Pinterest lors d’une recherche d’images ? Vous ne voulez plus d’infos provenant de 20minutes.fr ?
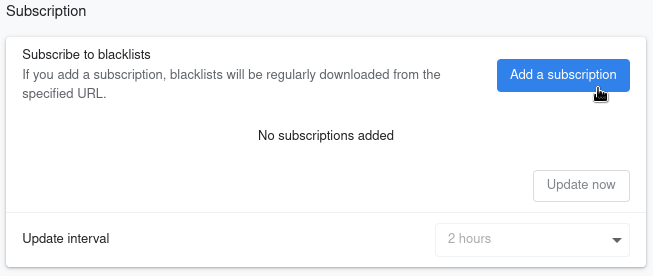
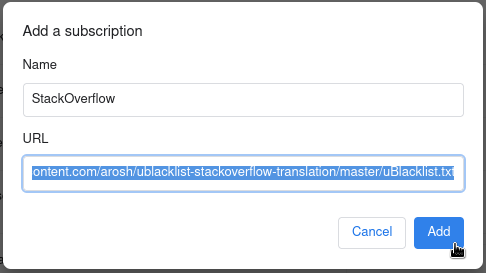
Concrètement vous lancez une recherche dans votre moteur de recherche préféré et les domaines bloqués avec uBlacklist n’apparaîtront plus dans les résultats.
Points forts
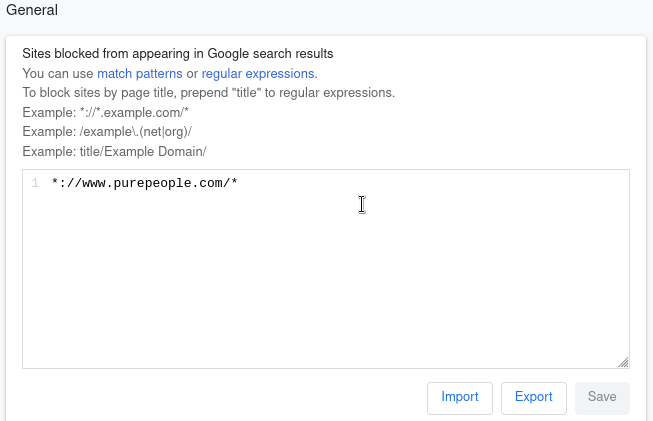
Bloquer manuellement et simplement un domaine en cliquant sur Block this site.
C’est bien connu, les souris sont des animaux avec des vies courtes ! La mienne, une Corsair Dark Core RGB SE est morte cet été, et a durée presque 3 ans. Sniff, j’adorais mon petit mulot. Juste pour la petite histoire, il est possible de la changer la batterie (vraiment attention le modèle doit être à trois fils). Bien que j’ai trouvé de la documentation sur la batterie et pour changer celle-ci, j’ai préféré d’abord passé par une solution beaucoup plus simple: changer celle-ci. Après, c’est compliqué mais pas impossible. On verra cela….quand je serais très motivé. Mais pour en revenir à l’objet de cet article, elle me provoquait quelques problèmes au démarrage. Bien que téméraire, pour cette fois-ci, je n’ai pas voulu m’embêter. Pour être en raccord avec mes articles précédents, j’ai choisi la marque la mieux reconnue sous Linux : Razer. Pour ce faire, il a fallut quelle soit aussi sans fils, c’est tellement ennuyant les fils. Après avoir hésiter avec RazeGenie (C++/Qt5), j’ai choisi Polychromatic (PyQt5) car il est plus activement développé que le premier. Et maintenant, rentrons dans le vif du sujet. Et c’est parti !
Et on commence par le …..commencement
La première chose à faire est d’installer Polychromatic et toutes ses dépendances. Sur Manjaro, cela donne la ligne de commande suivante (si vous préférez utiliser une GUI comme Pamac ou Octopi, ne vous privez pas)
Ensuite, on vérifie par la commande lsusb si la souris est bien connectée et reconnue par le système. Celle-ci communique par le biais d’une clé USB soit sans fils soit en Bluetooth. Un peu plus sur cette souris à cet endroit. En promo, elle se trouve moins chère.
$ lsusb
Bus 003 Device 002: ID 0b05:190e ASUSTek Computer, Inc. ASUS USB-BT500
Bus 001 Device 004: ID 1b1c:0c18 Corsair H100i Platinum
Bus 001 Device 003: ID 04f3:152e Elan Microelectronics Corp. Gaming KB
Bus 001 Device 005: ID 1b1c:1c0a Corsair
Bus 001 Device 002: ID 1532:0083 Razer USA, Ltd RC30-0315, Gaming Mouse [Basilisk X HyperSpeed]
Bingo. On voit, outre le fait que mon système la reconnaît, qu’elle se trouve sur le Bus 001 en tant que Device (=Périphérique) 002 et que le vendorId de razer est bien le 1532 et que le productid de la souris est le 0083.
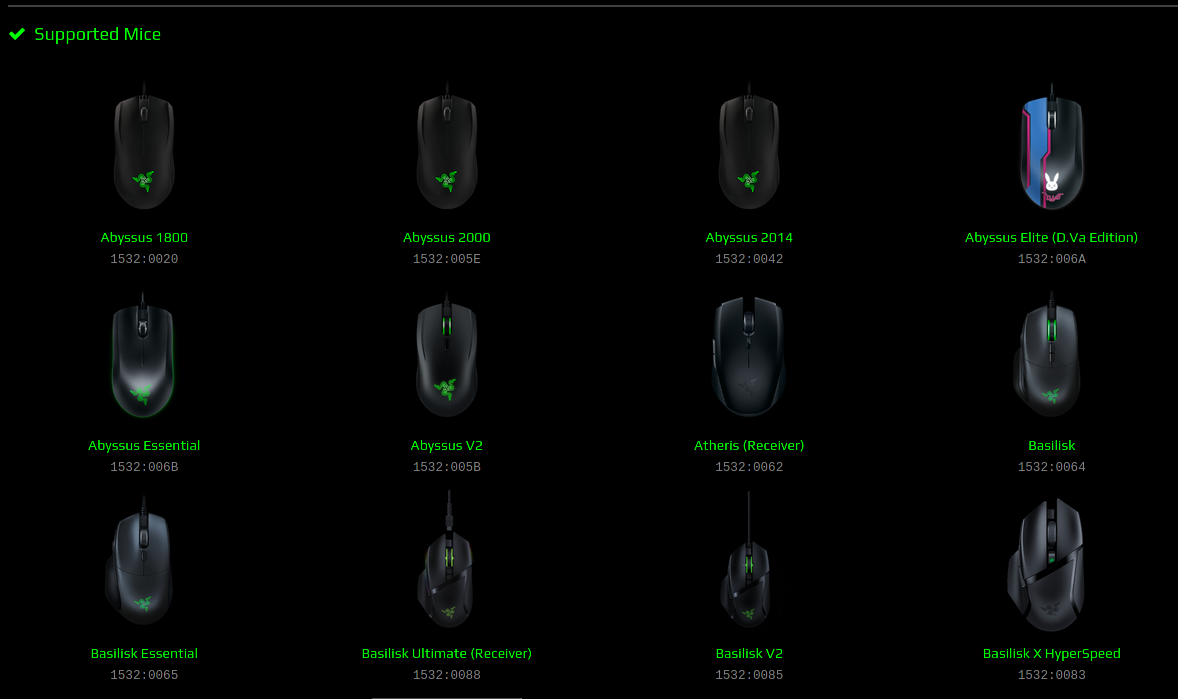
Un rapide petit tour soit sur le site de Poychromatic soit sur le site des drivers Razer open-source : OpenRazer nous permet de vérifier toutes ces informations et bien que la liste est très longue, de voir que notre souris est belle et bien supporté. C’est une excellente nouvelle, du out-of-box sous Linux, cela change.
notre modéle est le 5 ème Basilik confirmé par son productid ici 0083
Et maintenant que tout est bon et installé, il est temps de paramétrer cette souris.
On lance Polychromatic de la manière qui vous va le mieux (menu, dock, lanceur d’application) et là, …rien. Cela commence bien pour une appli parfaitement reconnu. Personnellement, je préférerai avoir ceci.
Okay cest un clavier mais cela en jette.
Premier reflex, on ouvre un terminal et on lance l’application. On obtiens le résultat suivant:
polychromatic &&
Bon il semblerait qu’il y ait un soucis, on a rien.
Deuxième réflexe : un petit tour sur Polychromatic qui ne nous apprend pas grand chose puis sur le wiki OpenRazer sur Github et là, on obtient des informations sur les problèmes les plus courants que l’on peut rencontrer en consultant cette page.
Après avoir vérifié que ma souris est bien prise en charge par OpenRazer grâce à la commande lsusb , on va se baser sur la documentation pour trouver ce qui cloche. Et on commence par les logs (=journaux) pour le kernel, les drivers et le daemon razer que nous avons installé en même temps que Polychromatic et OpenRazer. Ce qui nous donne les commandes suivantes:
$ sudo dmesg
....
[ 4.291675] NET: Registered PF_ALG protocol family
[ 4.782425] input: Razer Razer Basilisk X HyperSpeed as /devices/pci0000:00/0000:00:01.3/0000:02:00.0/usb1/1-1/1-1:1.0/0003:1532:0083.0001/input/input17
[ 4.782484] hid-generic 0003:1532:0083.0001: input,hidraw0: USB HID v1.11 Mouse [Razer Razer Basilisk X HyperSpeed] on usb-0000:02:00.0-1/input0
[ 4.789517] input: Razer Razer Basilisk X HyperSpeed Keyboard as /devices/pci0000:00/0000:00:01.3/0000:02:00.0/usb1/1-1/1-1:1.1/0003:1532:0083.0002/input/input18
[ 4.843559] input: Razer Razer Basilisk X HyperSpeed as /devices/pci0000:00/0000:00:01.3/0000:02:00.0/usb1/1-1/1-1:1.1/0003:1532:0083.0002/input/input19
[ 4.843647] hid-generic 0003:1532:0083.0002: input,hidraw1: USB HID v1.11 Keyboard [Razer Razer Basilisk X HyperSpeed] on usb-0000:02:00.0-1/input1
[ 4.847700] input: Razer Razer Basilisk X HyperSpeed as /devices/pci0000:00/0000:00:01.3/0000:02:00.0/usb1/1-1/1-1:1.2/0003:1532:0083.0003/input/input20
[ 4.903547] hid-generic 0003:1532:0083.0003: input,hidraw2: USB HID v1.11 Keyboard [Razer Razer Basilisk X HyperSpeed] on usb-0000:02:00.0-1/input2
...
$ cat ~/.local/share/openrazer/logs/razer.log
2021-10-23 19:20:11 | razer | CRITICAL | User is not a member of the plugdev group
2021-10-23 19:20:11 | razer | CRITICAL | Please run the command 'sudo gpasswd -a $USER plugdev' and then reboot!
2021-10-24 13:27:59 | razer | CRITICAL | User is not a member of the plugdev group
2021-10-24 13:27:59 | razer | CRITICAL | Please run the command 'sudo gpasswd -a $USER plugdev' and then reboot!
2021-10-25 17:58:45 | razer | CRITICAL | User is not a member of the plugdev group
2021-10-25 17:58:45 | razer | CRITICAL | Please run the command 'sudo gpasswd -a $USER plugdev' and then reboot!
2021-10-25 21:10:30 | razer | CRITICAL | User is not a member of the plugdev group
2021-10-25 21:10:30 | razer | CRITICAL | Please run the command 'sudo gpasswd -a $USER plugdev' and then reboot!
2021-10-25 21:12:42 | razer | CRITICAL | User is not a member of the plugdev group
2021-10-25 21:12:42 | razer | CRITICAL | Please run the command 'sudo gpasswd -a $USER plugdev' and then reboot!
On commence par en apprendre un peu plus dont le fait est que la souris est parfaitement reconnu par le système, et qu’il faudrait ajouter l’utilisateur au groupe plugdev et ensuite rebooter. Mais continuons notre exploration avec les commandes suivantes:
$ pacman -Q openrazer
erreur : le paquet « openrazer » n’a pas été trouvé
Cela commence à devenir intéressant car on apprend que la version de OpenRazer est la 3.1.0-1. Poursuivons.
$ sudo dkms install openrazer-driver/3.1.0-1
On vérifie que l’on a bien installé la bonne version des modules OpenRazer pour notre kernel. C’est le cas.
$ sudo dkms status
Comme on n’a aucune erreur, on peut dire que cela ne vient pas du kernel.
$ sudo modprobe razerkbd
On essaie de charger le module du kernel utilisant dkms. Aucune réponse en sortie, donc c’est bon. Continuons donc.
$ openrazer-daemon -Fv
Unable to lock on the pidfile
On vérifie si le daemon d’OpenRazer est démarré. Aie. C’est le cas grâce au message que nous avons en retour. Cela signifie qu’il faut ajouter l’utilisateur courant au groupe plugdev. D’ailleurs, si vous avez noté la commande cat ~/.local/share/openrazer/logs/razer.log passée au début, nous avions la même consigne. Maintenant que nous sommes sûr de ce qu’il faut faire, ….faisons-le. On passe donc la commande suivante.
$ sudo gpasswd -a $USER plugdev
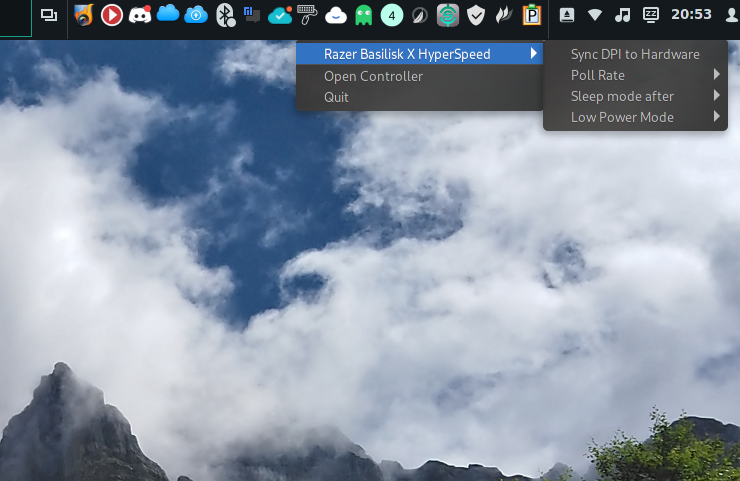
On démarre l’application et Bingo, elle se lance. C’est pas magique ?
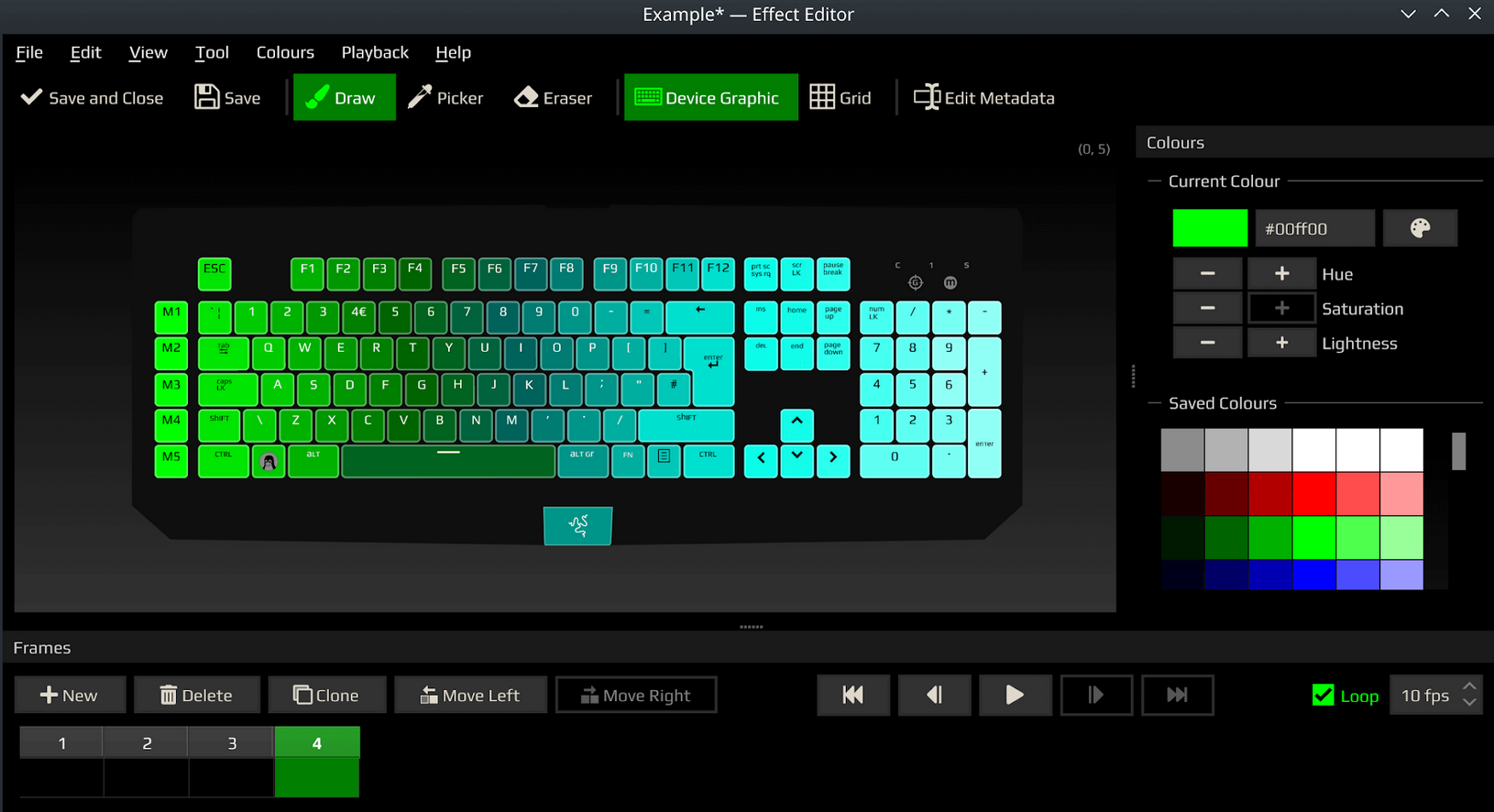
A la découverte de Polychromatic sauce Basilisk x Hyperspeed
Whaoouh. c’est top et c’est beau
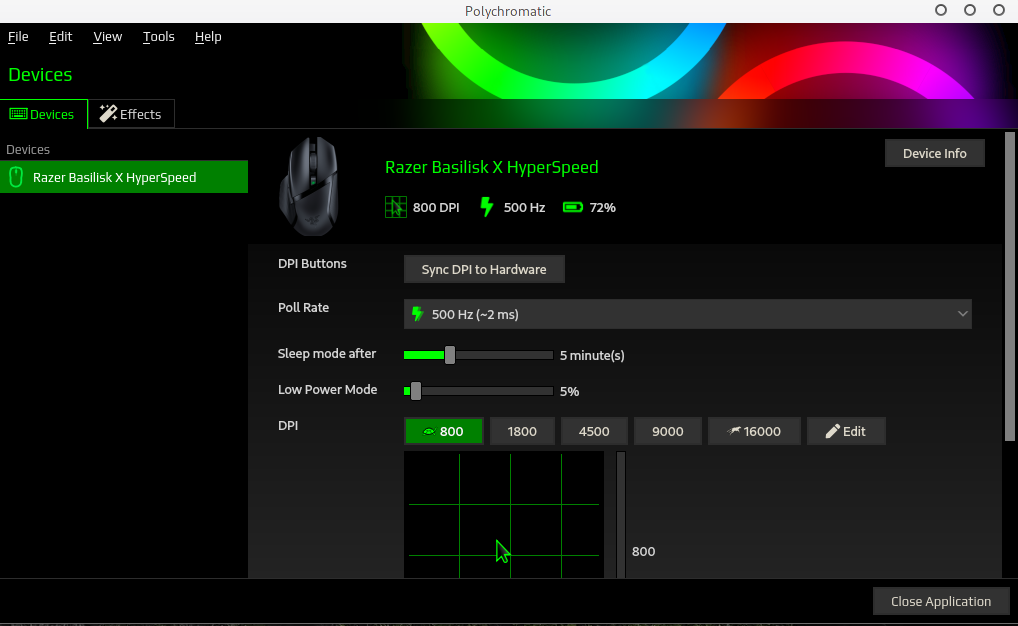
Polychromatic s’ouvre par défaut sur l’onglet Device. Ici, il n’y en a qu’un mais dans le cas où vous auriez plusieurs périphériques de la marque, ils seraient dans la partie gauche, listés en dessous de la Razer Basilisk X Hyperspeed. Pour ce périphérique, nous avons en un coup d’œil, toutes les caractéristiques de notre souris. A savoir déjà, une image puis son nom et modèle, enfin le nombre de DPI, le Pool Rate et le pourcentage de la batterie. Ensuite vient chaque caractéristique détaillée et modifiable. Celles-ci sont, pour cette souris, les suivantes:
la synchronisation des DPI avec la souris
le Polling Rate
l’activation de l’hibernation après tant de minutes
un mode d’économie d’énergie
la sélection des DPI
Il n’y a aucun effet car ce modèle de souris n’en a pas. C’est manqué.
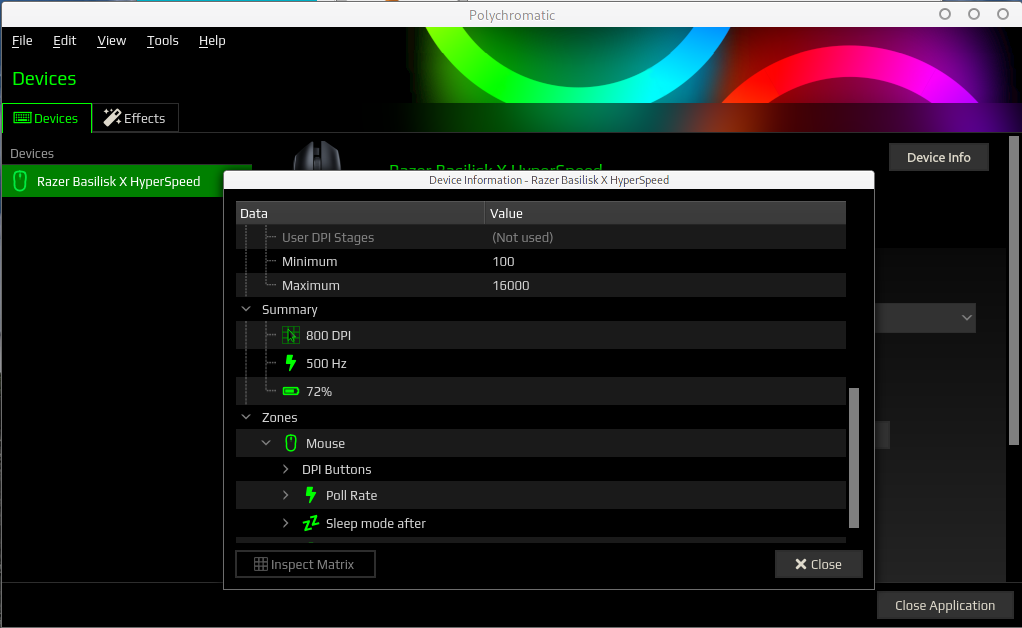
En haut, à droite dans l’interface principale, nous avons un bouton nommé Device Info (Info sur le Périphérique en français) qui est une synthèse de tout ce que Polychromatic (grâce aux drivers opensource Razer) sait sur notre souris.
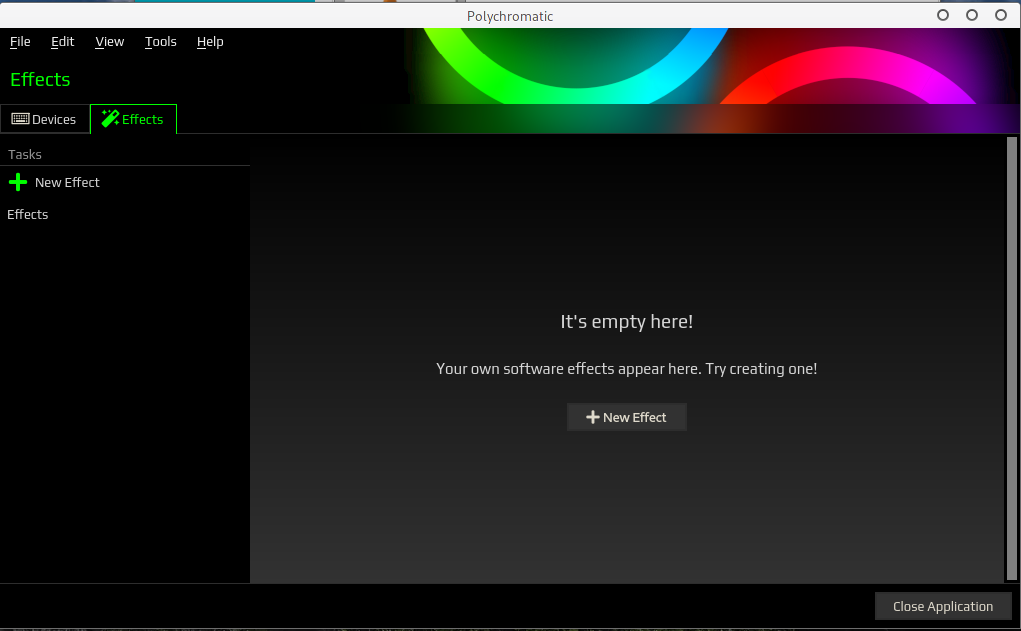
Je ne sais si par défaut l’onglet des Effets est vide ou bien lié à notre périphériques. On peut créer un nouvel effet sauf dans le cas où, ce périphérique n’en dispose pas, …..comme ici. Sniff. J’ai pas pris le bon modèle mais bon vu le prix, je vais pas me plaindre surtout qu’il s’agit d’une souris très agréable en main.
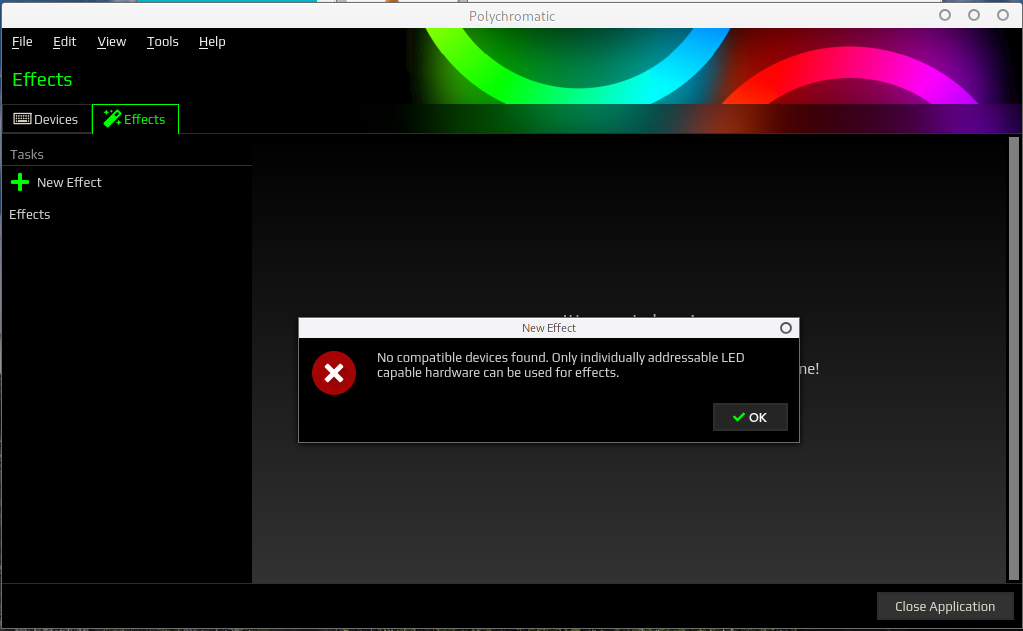
On peut toutefois en créer si c’est possible. Quand cela ne l’est pas, vous avez le message suivant:
souris non compatible avec des effets lumineux.
A noter aussi que lors de son lancement, un nouvel icône correspondant à Polychromatic se trouve dans le systray. Vous avez accès à 3 actions :
les caractéristiques de la souris elles-même découpées entre:
Synchronisation des DPI avec la souris
le polling rate
le temps d’hibernation
le mode d’économie d’énergie
l’ouverture de l’application
la fermeture de l’application
Polychromatic dans le systray avec toutes les actions possibles de ce modèle
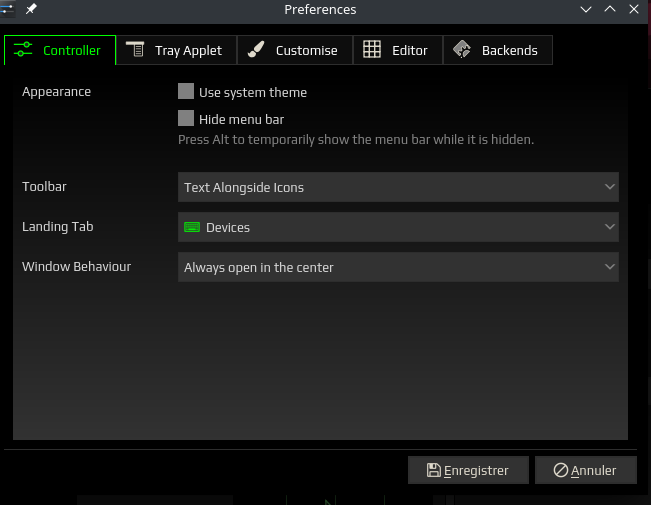
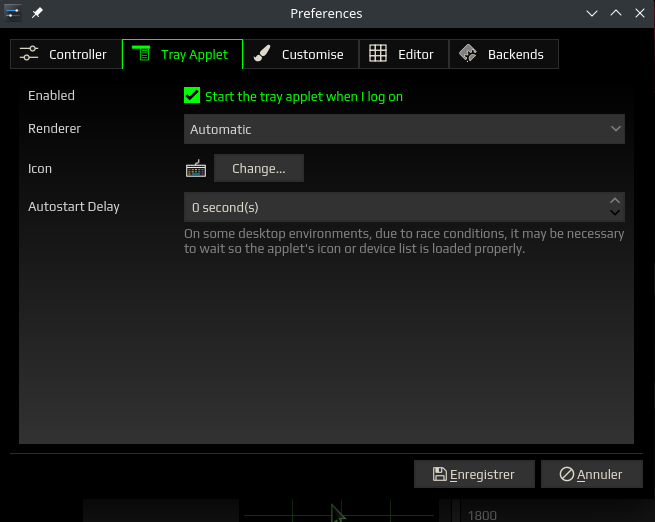
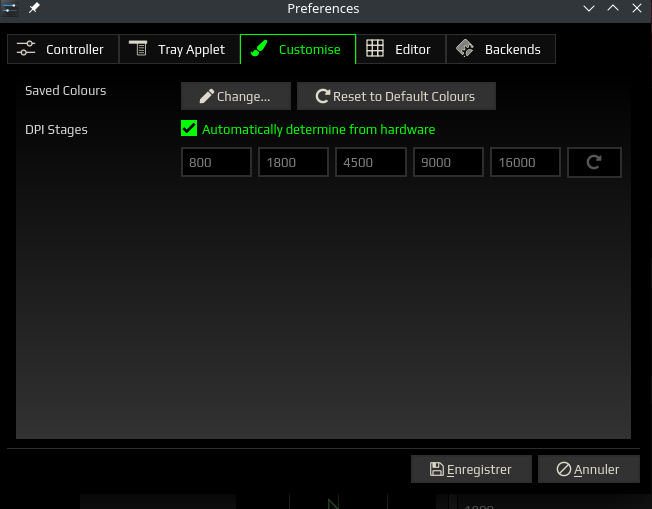
Le logiciel comporte aussi une section Préférences que l’on appelle dans le menu avec l’entrée View. Celle-ci dispose de 5 onglets qui sont:
Controller: tout ce concerne l’application elle-même (utilisation du thème dus système, positionnement de la fenêtre,…)
Tray Applet: tout pour l’applet dans le systray
Customize: tout pour les couleurs sauvegardées et les DPI « Stages »
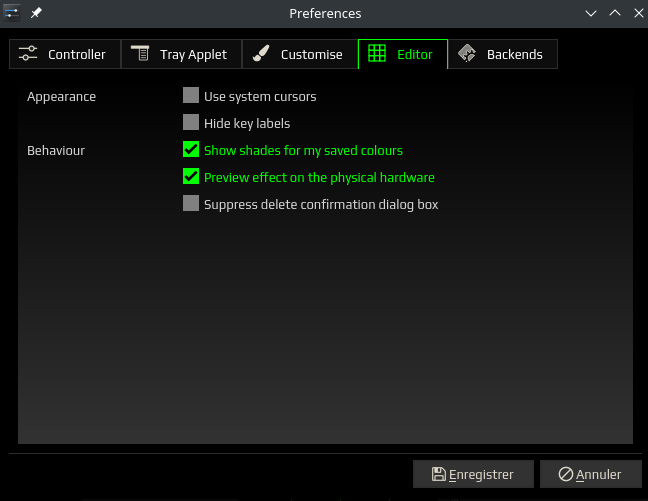
Editor: tout pour l’apparence et le comportement
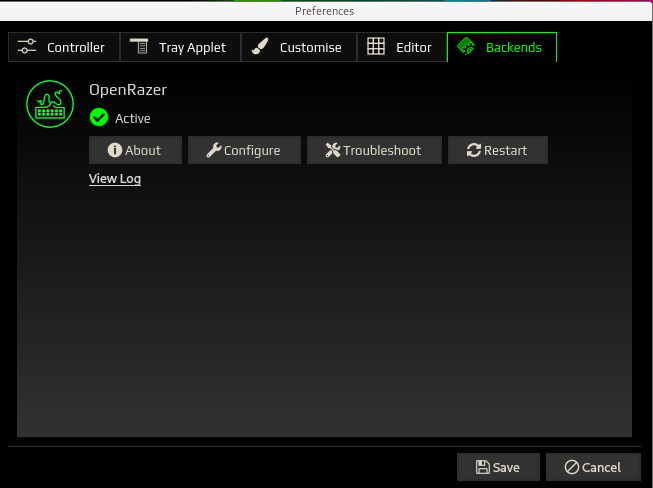
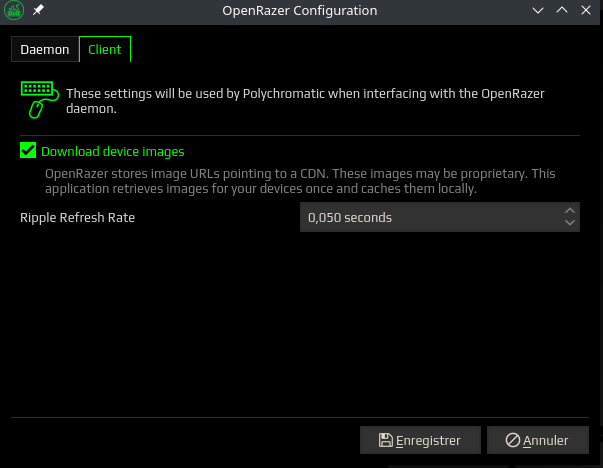
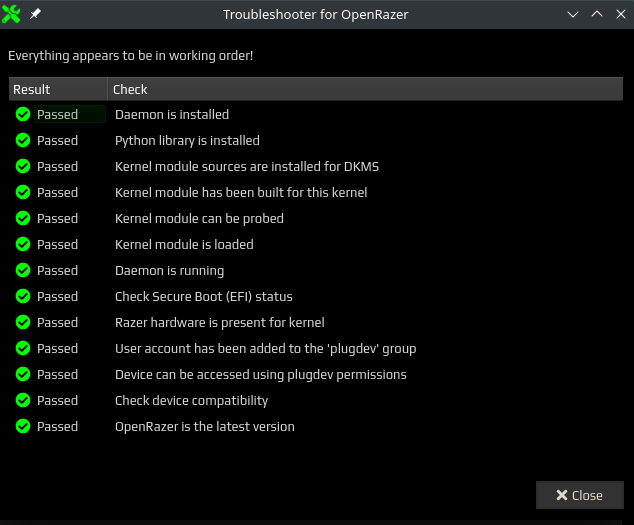
Backends: Celui est le plus intéressant de tous car il concerne les drivers opensources Razer. Nous avons à notre disposition tout un tas d’informations grâce à 4 onglets outre l’activation ou pas des dits drivers : About, Configure, Troubleshoot, Restart. Et en prime, nous avons aussi accès aux logs du daemon du driver. Une capture vaut mieux qu’un long discours.
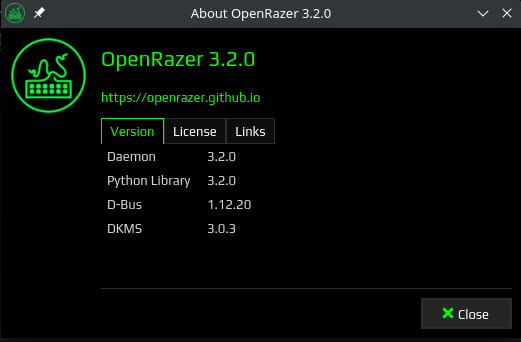
L’onglet About nous informe des librairies installés pour faire fonctionner OpenRazer ainsi que sa licence et les liens vers le projet.
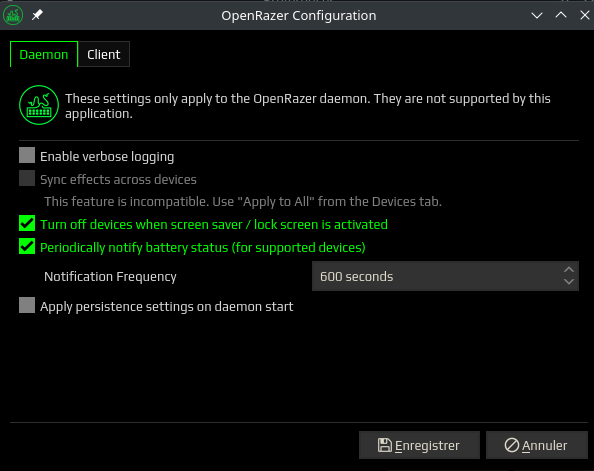
L’onglet Configure permet de configurer le daemon finement.
Dans le deuxième onglet nous pouvons nous occuper du client.
L’onglet TroubleShoot lance un test de tous les paramètres nécessaires au bon fonctionnement d’OpenRazer y compris du module dkms du kernel. Si vous avec une croix verte, c’est que c’est tout bon comme ci-dessous.
Restart n’est à utiliser que si vous avez une croix rouge, cela aura pour effet de relancer le daemon. Si vous n’avez pas de soucis comme moi au-dessus, il est inutile de le lancer. Ni de tenter le diable si cela fonctionne déjà.
Il est temps de nous quitter
Le remplacement forcé de mon petit mulot Corsair par un autre Razer piloté par Polychromatic est une très bonne surprise. Même si au début, tout ne s’est pas passé out-of-box, au final le résultat est au-delà de mes espérances: pratique, beau, complet, fonctionnel. J’espère que cela vous aura convaincu, à condition d’avoir un périphérique Razer, de tester les logiciels basés sur OpenRazer. Bien que mon choix s’est porté sur Polychromatic, il aurait été intéressant de tester Razergenie.
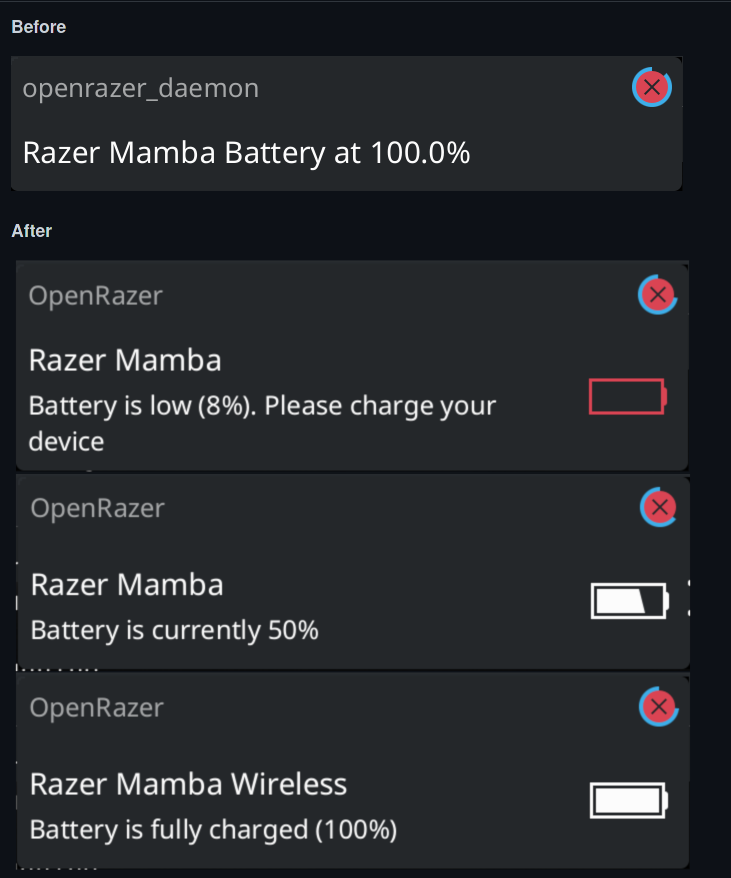
La critique que je ferais serait au niveau de la batterie. Je pense qu’il serait judicieux d’avoir aussi accès à une notification qui aurait juste pour but d’éviter de lancer l’application pour voir son niveau actuel. Et pourquoi pas programmer cette notification à intervalle réguliers. L’autre aspect qui peut rebuter certains est qu’il n’est pas (encore) traduit dans la langue de Molière. Étonnant d’ailleurs. Bonne découverte.
Petit complément suite à mes critiques au niveau de la batterie et de la langue de l’interface. En jetant un coup d’œil rapide dans les « issues » sur Github, je me suis rendu compte que la demande d’avoir la batterie dans le systray à déjà été demandé ici et ici et comme vous le voyez son développeur est assez intéressé par cette fonctionnalité. Et en jetant un autre coup d’œil pour la francisation de l’interface elle existe déjà. Par contre, aucune précision pour l’inclure. C’est à creuser. Peut-être l’objet d’un autre article, qui sait ?
NB: Je n’ai pas trouvé d’information pour avoir l’interface en Français, j’ai demandé à son auteur (aka Lah7) comment faire. Si vous voulez suivre la conversation c’est à cet endroit que cela se passe.
MAJ du 05 Février 2022
Une des chose que que j’aime dans le libre, c’est la rencontre avec les gens. Après avoir publié cet article, j’ai informé son auteur Lah7 sur le fait que l’on ne pouvait pas avoir le logiciel en Français, malgré une traduction Française existante et que j’avais fais un article sur Polychromatic. Pour ceux qui veulent voir les réponses de Lah7 sur cette situation peuvent se rendre ici. Il y avait un bogue et ceux qui installeront Polychromatic à la main auront automatiquement le logiciel en Français. Pour ceux qui comme moi l’installe avec leur outil préféré, il faudra attendre un peu plus longtemps. D’ailleurs, Lah7 aura besoin de traducteurs quand il aura fini le refactoring du projet. Et pas qu’en Français. Alors si vous parlez une autre langue,vous savez ce qui vous reste à faire.
L’autre point négatif que j’avais évoqué, est aussi en passe d’être résolu mais ce sera là du coté des drivers OpenRazer avec cet « issue » ouverte. Comme vous pouvez en jugé avec la capture d’écran ci-dessous c’est très bien. Le seul inconvénient est que si l’utilisateur n’a pas vu la notification, elle ne se répétera pas. Un autre point qui n’est pas encore corrigé. Mais cela viendra.
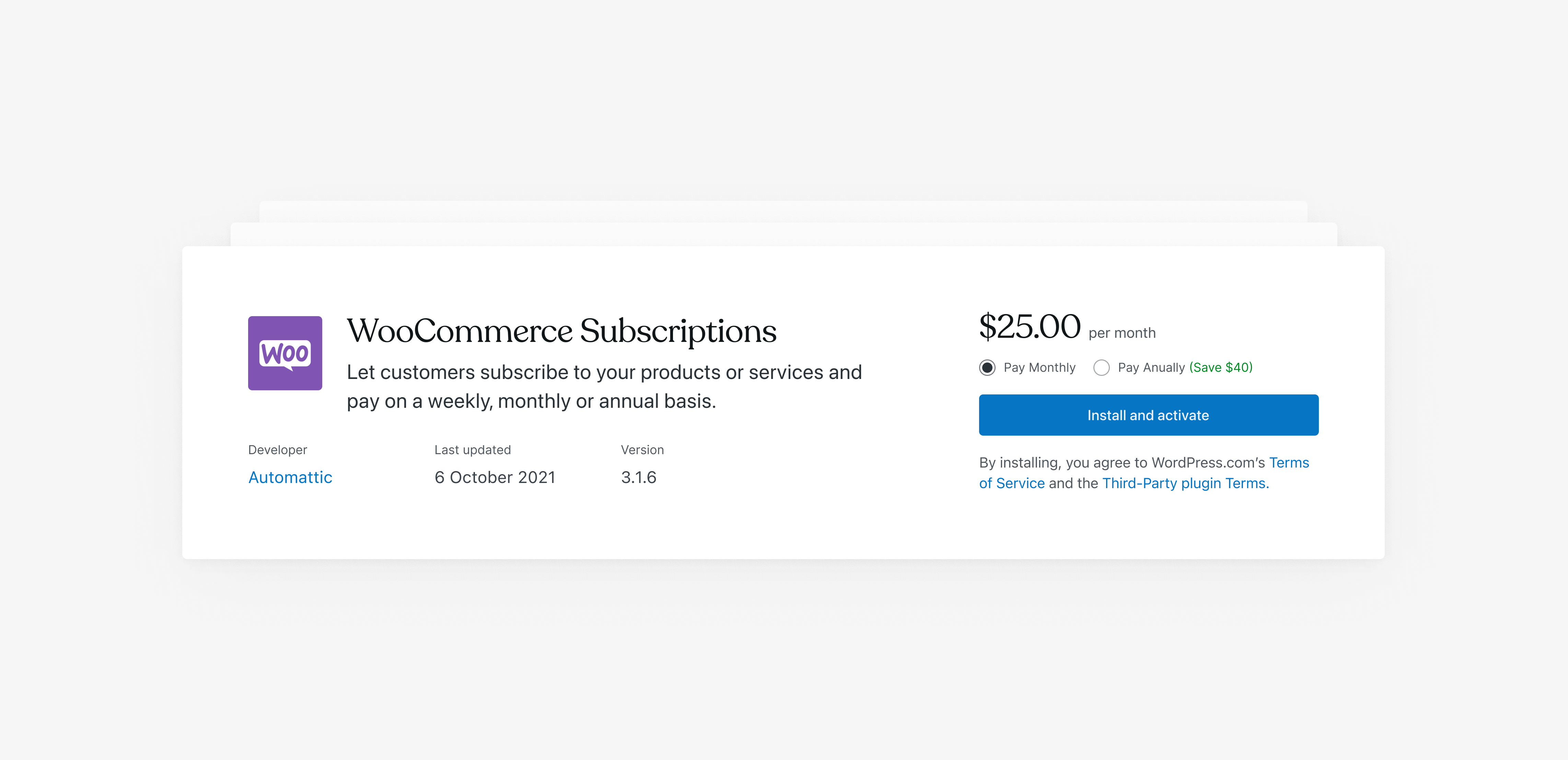
Pour les utilisateurs de nos offres Business et eCommerce, les extensions jouent un rôle essentiel dans l’expérience WordPress.com. Nous cherchons sans cesse à simplifier la découverte et l’installation d’extensions WordPress performantes.
À cet effet, il est désormais possible d’acheter certaines extensions directement sur la page des extensions de WordPress.com. En outre, WordPress.com proposera une tarification mensuelle et annuelle des extensions, ce qui garantira davantage de souplesse aux propriétaires de sites.
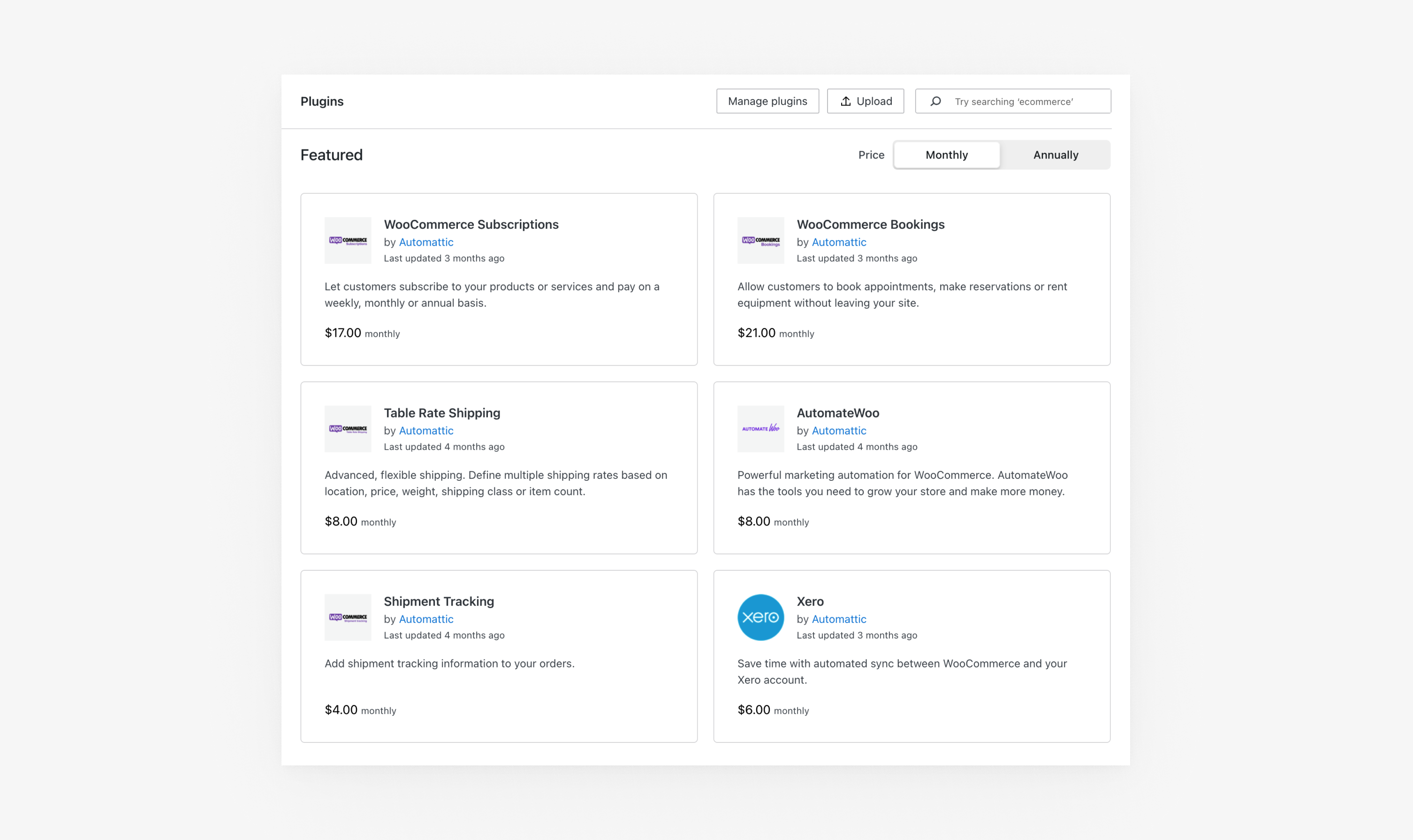
Pour le moment, vous pouvez acheter six de nos extensions WooCommerce les plus populaires sur la page des extensions de WordPress.com.
WooCommerce Subscriptions : permettez aux clients de s’abonner à vos produits ou services moyennant un paiement hebdomadaire, mensuel ou annuel.
WooCommerce Bookings : permettez aux clients de prendre rendez-vous, réserver ou louer des équipements sans quitter votre site
WooCommerce Table Rate Shipping : livraison personnalisée et flexible. Définissez plusieurs tarifs d’expédition en fonction du lieu, du prix, du poids, de la classe d’expédition ou du nombre d’articles.
WooCommerce AutomateWoo : automatisation puissante du marketing pour WooCommerce. AutomateWoo dispose des outils dont vous avez besoin pour développer votre boutique et gagner plus d’argent.
WooCommerce Xero : gagnez du temps avec la synchronisation automatique entre WooCommerce et votre compte Xero.
L’achat d’une extension via la nouvelle interface de WordPress.com est simple. Sur la page des extensions, cliquez sur l’une des fiches correspondant à une extension payante pour vous rediriger vers une page produit. Quand vous le souhaitez, cliquez sur le bouton d’achat en haut à droite de la page produit. Votre achat ne sera pas définitif tant que vous n’aurez pas confirmé votre mode de paiement et vos coordonnées sur la page suivante. L’extension sera installée automatiquement.
Cette annonce n’est qu’un début. D’autres extensions payantes et d’autres nouveautés passionnantes vous seront présentées au cours des prochains mois. Faites-nous savoir dans les commentaires ci-dessous quelles extensions vous aimeriez voir disponibles à l’achat directement sur WordPress.com.
Pour rappel, toutes les extensions (gratuites ou payantes) sont actuellement uniquement disponibles aux clients disposant d’un plan WordPress.com Business ou eCommerce. Si vous souhaitez mettre à niveau vers un plan Business annuel, cliquez ici pour bénéficier d’une réduction de 25 % sur votre première année.
Il y a quelques temps. j'expliquais que des applications métiers qui envoient du mail n'arrivaient plus à ouvrir de connexion vers les serveurs SMTP de Microsoft : Microsoft 365 - Problème de connexion aux serveurs SMTP.
La solution de contournement avait été de placer en liste verte la plage IP des serveurs qui hébergent ces applications.
Deux mois et demi sont passés et ça ne fonctionne plus. Évidemment, toujours pas d'explication du pourquoi du comment. Je travaille avec Microsoft depuis 5 ans et je ne m'y suis toujours pas habitué 🤬
Après quelques heures de tests et de bidouilles, j'ai décidé d'installer un proxy qui fera l'intermédiaire entre les applications bloquées et Microsoft. Pour ne pas avoir à gérer d'avantages d'accès, ce proxy sera totalement transparent.
Il n'existe (à priori) pas beaucoup de logiciels qui font ça et s'ils le font, ils ne sont plus maintenus. On retrouve beaucoup d'articles sur Nginx et Haproxy mais ils ne conviennent pas. Nginx n'est pas un proxy SMTP transparent et mes tests avec Haproxy ont échoués.
J'ai réussi à dénicher tuck1s/go-smtpproxy. Bien qu'il n'est pas reçu de mise à jour depuis 2 ans, il ne fait qu'utiliser une librairie qui elle a un développement actif : emersion/go-smtp.
Contexte / Prérequis :
Le serveur tourne avec Debian 11
Nom de domaine du proxy : relais-smtp.exemple.com
Il y a un certificat SSL généré par Let's Encrypt
Le serveur va écouter sur le port 587 avec la couche STARTTLS
Pour compiler le projet, il suffit d'installer Go, récupérer les sources et lancer le build. À l'issue du build, le binaire proxy sera généré dans le répertoire go/src/github.com/tuck1s/go-smtpproxy.
apt update
apt install golang
go get github.com/emersion/go-smtp-proxy
go get gopkg.in/natefinch/lumberjack.v2
go get github.com/tuck1s/go-smtpproxy
cd go/src/github.com/tuck1s/go-smtpproxy
./build.sh
Coté application, le serveur SMTP change de smtp.office365.com à relais-smtp.exemple.com. Si on envoie un mail, le proxy va afficher du log et on pourra s'assurer que ça fonctionne.
Il faut également améliorer tout ça avec un compte utilisateur dédié au proxy, gérer son démarrage avec un service Systemd/SysvInit/OpenRC/Whatever, etc.
Je reconnais que ce titre peut générer un gros mind fuck mais laissez moi vous expliquer !
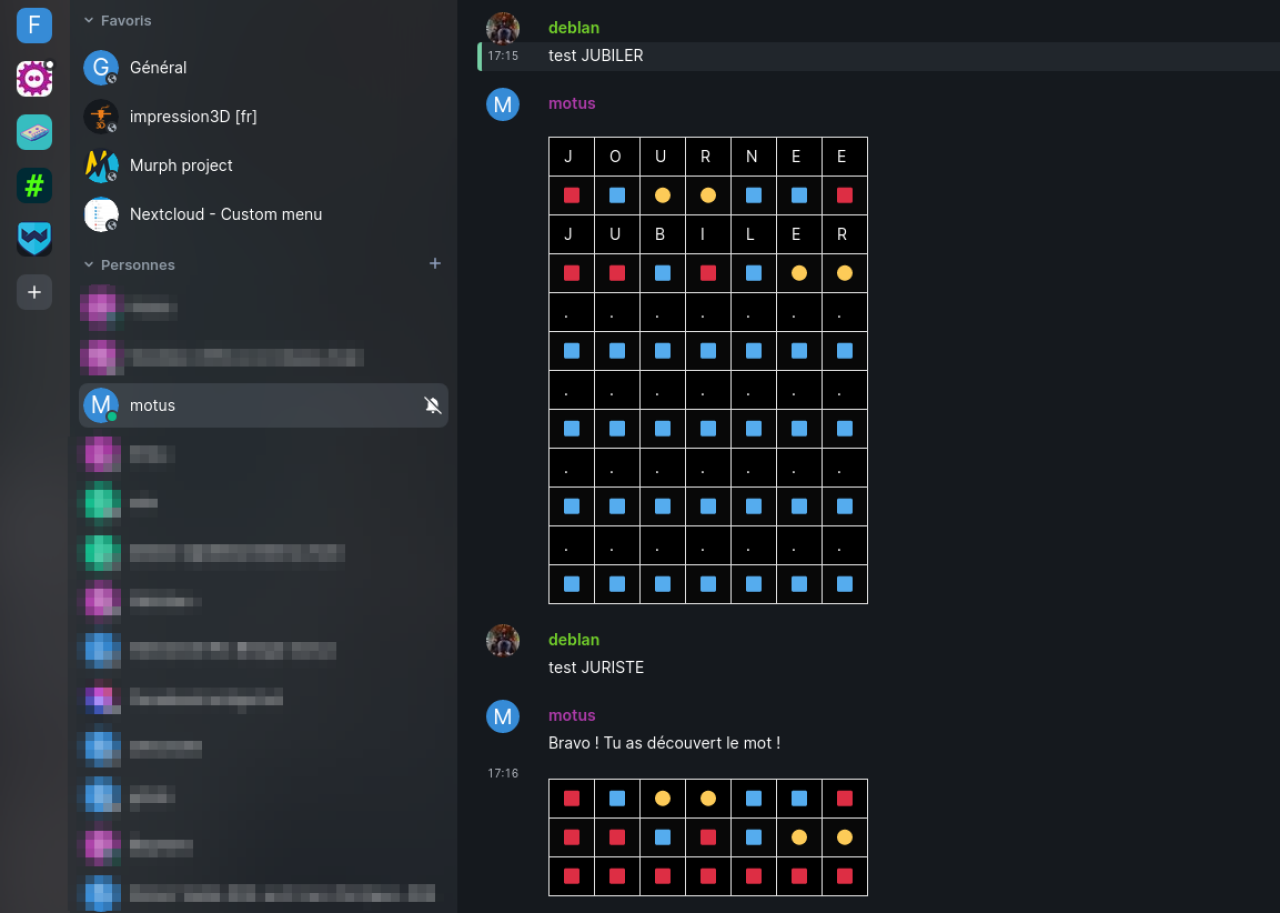
Depuis quelques temps, je joue quotidiennement à Sutom, une copie du jeu vieux jeu télévisé Motus. Le principe du jeu est simple : nous devons découvrir un mot avec comme indices sa taille et la première lettre qui le compose. On peut faire maximum 6 propositions qui permettent de découvrir les lettres. Une lettre découverte sera affichée dans un carré rouge, une lettre découverte mais mal placée sera dans un rond jaune. Les autres lettres resteront en bleu. Seuls des mots du dictionnaire peuvent être proposés.
Sutom est addictif...mais pas tant que ça car il n'y a qu'un seul mot à découvrir par jour !
Cela m'a donné un bon prétexte pour monter un nouveau projet : écrire un bot avec lequel je pourrai jouer via Matrix, ma messagerie instantanée. Le bot se connecte avec un compte utilisateur créé pour l'occasion puis accepte les invitations à rejoindre une conversation. Le bot va ensuite lire les messages qu'on envoit et va réagir quand c'est nécessaire. Ainsi on peut lancer ou relancer une partie et tester des mots. À chaque proposition, on retrouve un affichage comme dans Motus 🥸