Le moteur de blog statique propose nativement un plugin pour gérer les
commentaires avec disqus. Il permet de donner un peu de dynamisme au blog, qui
est entièrement statique… Sauf qu’il s’agit d’un service non libre, qui
enregistre les données des utilisateurs…
Le plugin disqus_static permet d’intégrer à la page html les commentaires
trouvés sur le service disqus. Cela permet de les inclure nativement dans
l’article, et évite au lecteur du blog d’informer disqus de sa navigation sur
le site. Voici la manière dont je l’utilise sur le blog.
Attention !
Cette configuration est moins pire que celle proposée par défaut par le
blog, mais elle continue d’enregistrer l’ensemble des commentaires auprès
d’une entreprise privée. Mieux vaut, si vous en avez la possibilité,
basculer sur une solution hébergée comme isso.
Création du compte
En suivant la documentation du plugin, on enregistre notre application sur le
site de l’api de disqus :
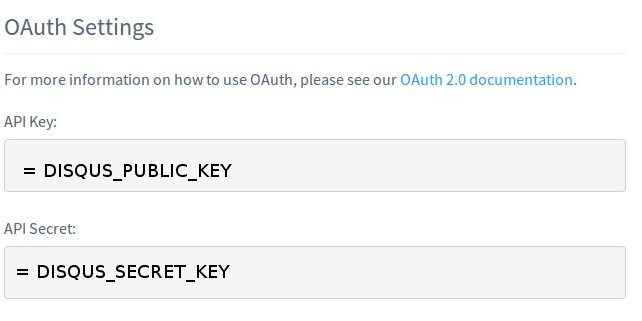
Le compte n’a besoin d’accéder aux commentaires qu’en mode lecture, penser
aussi à renseigner le nom de domaine utilisé par le blog dans les paramètres du compte.
Configuration du plugin
Le compte et la clef seront renseignés dans un fichier à part, que nous allons
nommer disqus.py. Normalement, il devrait juste contenir ces lignes :
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Configuration des commentaires
DISQUS_SITENAME='Votre compte disqus'
DISQUS_SECRET_KEY = u'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
DISQUS_PUBLIC_KEY = u'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
Pour éviter de diffuser ce fichier sur un serveur git public, ne pas oublier de
l’ajouter au fichier .gitignore ! Ainsi, nous serons sûr que notre clef privée
ne sera jamais transmise sur internet…
Dans le fichier publish.conf, nous allons ajouter le chargement du plugin :
import sys
import os.path
try:
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
from disqus import *
PLUGINS.append("disqus_static")
except:
pass
Cela permet de génerer le blog, même si la configuration pour les commentaires
n’est pas présente.
Utiliser le fichier publish.conf permet de générer le blog sans faire appel à
l’API pour éditer le blog, par contre, ceux-ci seront intégrés dès que l’on
lancera la commande make publish pour publier le blog.
Changement du template
Maintenant que tout est prêt, il ne reste plus qu’à modifier son template pour
éviter de charger disqus automatiquement. C’est dommage d’intégrer les
commentaires dans la page, si ceux chargés par disqus sont affichés automatiquement…
Sur mon blog, il faut cliquer sur le bouton pour recharger les commentaires (ou
pour en ajouter de nouveaux). C’est juste un peu de javascript, et vous pouvez
vous inspirer de ce bout de code :
{% if DISQUS_SITENAME %}
class="comments">
Commentaires :
id="disqus_thread">
{% if article.disqus_comments %}
class="post-list">
{% for comment in article.disqus_comments recursive %}
class="post">
class="post-content">
class="avatar hovercard">
alt="Avatar" src="{{ comment.author.avatar.small.cache }}">






{kind=link}