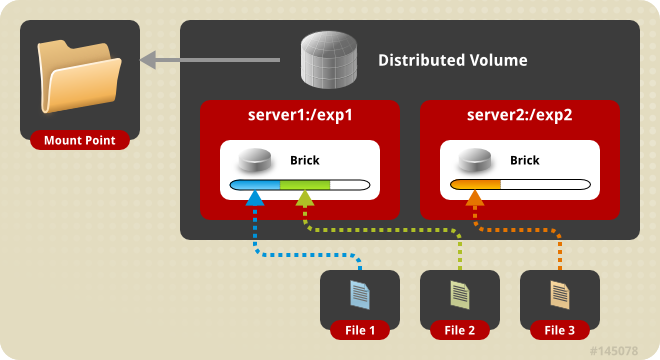
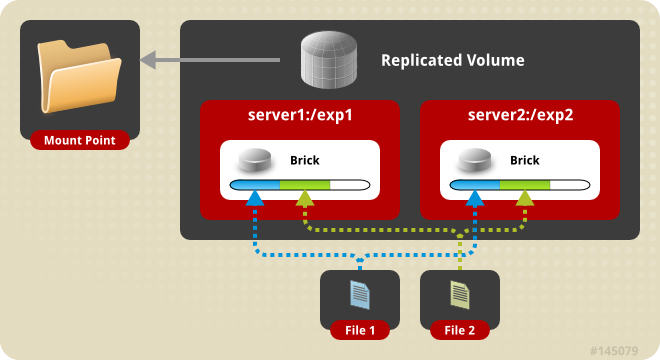
J’ai depuis plusieurs années un NAS sous OpenMediaVault. Bien que je fasse les mises à jour au grès de leurs sorties et alors que j’utilise la dernière version stable d’OMV, force est de constater que celle-ci est encore basée sur Debian 9. Du coup, qui dit Debian 9, dit PHP 7.0. Or cette version n’est […]
Pour la 13ème semaine de l'année 2020, voici 10 liens intéressants que vous avez peut-être ratés, relayés par le Journal du hacker, votre source d’informations pour le Logiciel Libre francophone !
De plus le site web du Journal du hacker est « adaptatif (responsive) ». N’hésitez pas à le consulter depuis votre smartphone ou votre tablette !
Le Journal du hacker fonctionne de manière collaborative, grâce à la participation de ses membres. Rejoignez-nous pour proposer vos contenus à partager avec la communauté du Logiciel Libre francophone et faire connaître vos projets !
Et vous ? Qu’avez-vous pensé de ces articles ? N’hésitez pas à réagir directement dans les commentaires de l’article sur le Journal du hacker :)
Aujourd’hui on va parler de micromanagement et surout du manager qui pratique le micromanagement. On va l’appeler le micromanager. Tu l’as sûrement déjà croisé dans ta vie professionnelle, celui qui passe ses journées sur ton dos et ceux de tes collègues, à dire comment chacun doit faire son boulot – alors que t’as 10 ans d’ancienneté dans ta spécialité – et qui s’étonne au final que les projets avancent pas et que les gens ne prennent pas d’initiative.
Je préfère qu’on fasse comme ça
Dans une approche top-bottom classique, le micromanager a raison. Il a la vision. Ok, pourquoi pas ? Chaque boîte a ses spécificités, il faut avant tout répondre aux besoins de la boîte. Fair enough, je pense que n’importe quel informaticien avec quelques expériences en a conscience.
L’expérience de chacun
Maintenant, on est des professionnels. On a déjà mené à bien des tonnes de projets. Donc à priori on va faire en gros comme d’habitude et mener à bien le projet, en autonomie sur les points qu’on gère et en équipe pour se synchroniser et construire un système qui marche. On a de la bouteille, on en a vu passer des projets.
Oui mais non. Pas avec le micromanager. Parce que là, tu devrais pas faire ça comme ça, en fait. Parce que ça n’est pas le résultat qui compte, c’est le chemin vers le résultat, même si à la fin ça fait la même chose. Même si ça coûte 1 ou 2 jours en plus de reprendre tout comme il veut à chaque fois, pour quasiment le même résultat. D’ailleurs, tant qu’il n’aura pas relu personnellement ton travail, il ne sera pas validé. L’intégration continue, c’est lui.
Et les ennuis commencent
Le micromanager a toujours raison. D’ailleurs la preuve, en réunion, personne ne le contredit (ou si peu). Il parle souvent des heures, quasiment tout seul.
Le problème, c’est qu’il n’y a que lui qui le sait. Vraiment. Il faudrait lui dire, mais ceux qui l’ont fait bizarrement ne sont pas restés longtemps. Non, il ne les a pas virés, ils sont partis d’eux-mêmes. Pas fous, ils savent que c’est mort pour ce projet.
Le mec en soirée qui a toujours raison
Parce que, habituellement, dans la vie, le mec qui a toujours raison en soirée, tu l’écoutes 2 minutes si t’es poli puis tu t’éloignes vers quelqu’un avec qui tu peux discuter. Et c’est pareil dans la tech, entre professionnels expérimentés. Sauf quand c’est ton boss. Là, c’est chiant.
Quand un mec te dit qu’il faut faire un projet de telle manière, et que toi t’as déjà fait 30 ou 40 projets et que tu sais très bien comment faire, tu piges très vite quelles sont ses priorités et tu vas les appliquer.
Mais avec le micromanager, tu vas jamais pouvoir les appliquer, parce qu’il n’y a que lui qui fait bien et qui sait comment bien faire. Et bien sûr c’est irréalisable. Et pas faire comme lui, c’est s’exposer à “un risque” ou “mal faire” ou c’est “moins performant”.
Perte d’autonomie
Avec le micromanager, ta belle expérience de 10 ans ne sert à rien en fait. Il suffit de penser comme lui. Et comme tu n’y arrives pas, évidemment tu n’as plus envie de rien faire.
Donc on fait le minimum et on se met à attendre le prochain retour du micromanager, et avancer jusqu’au prochain point où on devra de nouveau attendre le micromanager. De toute façon tu sais que tu vas devoir tout reprendre. Il n’y a pas de specs, pas de cahiers de recette. Tout est dans sa tête. Perte d’autonomie complète, perte d’initiative.
Ben alors ? Vous pourriez le faire vous-même !
Bien sûr de temps en temps le micromanager ne va pas comprendre pourquoi sa belle équipe remplie de seniors ne produit pas ce qu’il veut, même approximativement.
Il a déjà pourtant expliqué maintes et maintes fois ce qu’il faut faire. C’est fou que les gens ne comprennent pas ce qu’il veut alors qu’il suffit de l’écouter. Bon ok il n’y a pas de specs, pas de cahiers de recette, pas de documentation, il n’a pas eu le temps de l’écrire. Ça change tout le temps (au gré de ses idées en fait). Ou elle est illisible. Et de toute façon ils ne vont pas comprendre, donc ça sert à rien la doc (ou si peu).
Tous ces “ingénieurs” qui ne comprennent rien, franchement, il manque d’autonomie, de prise d’initiative.
Donc chaque jour le micromanager prend le clavier des mains de ses subordonnés si besoin (en fait à chaque fois). En leur ré-expliquant pour la énième fois que le formatage du code c’est super important (même si le projet a 6 mois de retard), que vraiment c’est mieux de faire ça pour des raisons de sécurité (même si l’infra n’existe pas encore), que c’est pas la bonne pratique de faire comme ça (alors que le programme fait ce qui est attendu).
Puis bon, quelque part pour lui, qu’ils ne comprennent rien, c’est flatteur. C’est lui le meilleur, le plus intelligent, le plus indispensable. On change les petits bras mais le micromanager demeure (enfin pour l’instant).
Bon il y a quand même quelque chose qui le stresse un peu, c’est la deadline qui s’approche et il a encore rien sorti. Ça l’embête un peu. Il sait qu’il est entouré de nuls, mais bon quand même, ils sont beaucoup (parce qu’évidemment il a besoin de plein de bras pour son projet vu que tu en as plein qui sautent du train).
La peur de délivrer
En fait, au fond, le micromanager, il aimerait sortir le projet tout seul, par lui-même. Le “hic” c’est que si on lui a confié une équipe, c’est qu’à priori il y a besoin d’être plusieurs pour aller au bout du projet dans les délais. Mais lui ça le stresse grave. Il supporte pas de sortir un produit qui n’est pas parfait. Ou plutôt il prend comme excuse que ça ne sera jamais parfait pour ne pas sortir son produit. Un cas classique en somme. Mais il le saurait s’il avait lu (et compris) un bouquin de gestion de projet.
Et comme la deadline approche, qu’il l’a déjà reportée trois fois et qu’il ne veut pas se faire virer, il va devoir de toute façon baisser ses prétentions à la qualité au final. Le projet parfait, ça n’existe pas. Et s’il ne délivre pas quelque chose au final, c’est quelqu’un d’autre que lui qui prendra la direction du projet, pour le plus grand soulagement de ses subordonnés.
Sic transit gloria mundi.
Comment gérer le micromanager ?
Vous êtes au-dessus de lui hiérarchiquement ? Non ? Hé bien une seule solution.
Les carrières sont courtes, pas le temps de se faire infantiliser, d’autres missions vous offriront davantage d’autonomie et d’indépendance (en fait, presque toutes). Fuyez.
Me suivre sur les réseaux sociaux
N’hésitez pas à me suivre directement sur les différents sociaux pour
suivre au jour le jour mes différentes projets dans le Logiciel Libre
et/ou pour me contacter :
Recently, I had to build a geo-replicated GlusterFS setup and encountered a bunch of issues due to the not-so-up-to-date documentation and the unlucky thing. So much time spent reviewing things and discussing with the dev team over IRC. Here’s my (recent) life with a geo-replicated GlusterFS setup.
But why ?
Before we get started, it would be good if I gave you a little context. So, this is an assignment for a software company.
They provide their customers with large amounts of data (about 11 TB). The publisher being French, and for reasons of ease and competence - at the time of implementation - has created all its infrastructures in France.
Due to the fact that they have little control over their network (provided by another service provider from which they cannot leave for the moment) and a worldwide audience (with a strong increase on the North American continent), they were forced to deploy edge servers (HTTP services allowing the local distribution of its famous 11 TB).
This then irremediably leads to high latencies and low throughput for these North American users. Not a very pleasant user experience, you’ll tell me about it. If we talk about numbers:
Latency: 2 seconds compared to 0.3 seconds from France.
Throughput: 500 kB/s compared to 15 MB/s from France (and even 150 MB/s locally at storage)
So they decided to call on me to see how we could improve things with the following constraints:
rely on the existing provider (which has infrastructure in Europe and North America)
with the smoothest possible future migration to make it a quick-win
After an audit, we come to a decision for the next setup:
local cluster in France, based on a distributed GlusterFS setup
Local cluster in North America, also based on a distributed GlusterFS setup, geo-replicated on the first one in real time.
The interest here will also be to recycle technological bricks that the customer already knows, and to stay on something quite high level: GlusterFS is an overlay to the underlying file system (XFS was our choice here). The GlusterFS documentation (since version 3.5) also promises the correct operation of geo-replication on a distributed setup.
The setup
I enjoy working with Ansible to deploy my small clusters, like many DevOps. So I’m starting on it, writing my own playbooks. Be careful, the project presented on the previous link is the result of the work told here, after a little obvious cleaning, and potentially before a sequel …
The idea of this setup is to have the following elements:
Each country has its own cluster GlusterFS (the master being in France)
Each server has 10 disks of 4 TB available for this storage, built in software Raid type 10, formatted in XFS
Each node mounts the cluster locally with these parameters: 127.0.0.1:/storage-fr /opt/self glusterfs defaults,_netdev,noatime,log-level=ERROR,log-file=/var/log/gluster.log,direct-io-mode=no,fopen-keep-cache,negative-timeout=10,attribute-timeout=30,fetch-attempts=5,use-readdirp=no,backupvolfile-server=fs-fr-02 0 0
That’s the setup at the very beginning. Now let’s live it.
And then there’s the drama
Thanks to the Ansible playbook, the entire deployment goes smoothly and without errors. So I import my 11 TB and then I admit… but not for long. It’s perfect, but a SysOps rule scares me:
If everything goes well on the first try, you’ve forgotten something.
Fortunately for me, not everything is so beautiful: geo-replication doesn’t start. A glance at the geo-replication status does indeed bring me back to reality:
gluster volume geo-replication storage-fr fs-ca-01::storage-ca status
MASTER NODE MASTER VOL MASTER BRICK SLAVE USER SLAVE SLAVE NODE STATUS CRAWL STATUS LAST_SYNCED
------------------------------------------------------------------------------------------------------------------------------------------------------------------
fs-fr-01 storage-fr /opt/brick root fs-ca-01::storage-ca N/A Faulty N/A N/A
fs-fr-02 storage-fr /opt/brick root fs-ca-02::storage-ca N/A Faulty N/A N/A
In fact, the startup passes the replication to Active and then immediately to Faulty. For a successful setup, I would come back. So obviously, we always start by consulting the logs first:
less `gluster volume geo-replication storage-fr fs-ca-01::storage-ca config log-file`
And here we see a beautiful log entry, extremely explicit:
E [syncdutils(worker
/gfs1-data/brick):338:log_raise_exception] : FAIL:
Traceback (most recent call last):
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/gsyncd.py",
line 322, in main
func(args)
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/subcmds.py",
line 82, in subcmd_worker
local.service_loop(remote)
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/resource.py",
line 1277, in service_loop
g3.crawlwrap(oneshot=True)
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/master.py",
line 599, in crawlwrap
self.crawl()
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/master.py",
line 1555, in crawl
self.changelogs_batch_process(changes)
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/master.py",
line 1455, in changelogs_batch_process
self.process(batch)
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/master.py",
line 1290, in process
self.process_change(change, done, retry)
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/master.py",
line 1229, in process_change
st = lstat(go[0])
File
"/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/syncdutils.py", line
564, in lstat
return errno_wrap(os.lstat, [e], [ENOENT], [ESTALE, EBUSY])
File
"/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/syncdutils.py", line
546, in errno_wrap
return call(*arg)
OSError: [Errno 22] Invalid argument:
'.gfid/1ab24e67-1234-abcd-5f6g-1ab24e67'
First though is about a specific issue at some files. Checking the file matching the gfid, it occurs to seem valid. As an attempt to save the day, I get rid of it and restart the geo-replication. With no success at it fails the same way. Discussing with the Gluster dev team over IRC, they wonder if the amount of initial data might not be the issue. Fair enough, I get read of the data 1 TB per 1 TB, testing the geo-replication at each stage. Still no luck. As I end with a totally wiped folder, with no more data, I wondered if the changelog did not get corrupted or filled up during those test. I decide to wipe the complete cluster and attempt once again the deployment with Ansible, but without importing any data. To wipe the setup on the servers, I used the following commands:
And as you might have expected: it failed over once again!
E [syncdutils(worker
/gfs1-data/brick):338:log_raise_exception] : FAIL:
Traceback (most recent call last):
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/gsyncd.py",
line 322, in main
func(args)
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/subcmds.py",
line 82, in subcmd_worker
local.service_loop(remote)
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/resource.py",
line 1277, in service_loop
g3.crawlwrap(oneshot=True)
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/master.py",
line 599, in crawlwrap
self.crawl()
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/master.py",
line 1555, in crawl
self.changelogs_batch_process(changes)
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/master.py",
line 1455, in changelogs_batch_process
self.process(batch)
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/master.py",
line 1290, in process
self.process_change(change, done, retry)
File "/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/master.py",
line 1229, in process_change
st = lstat(go[0])
File
"/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/syncdutils.py", line
564, in lstat
return errno_wrap(os.lstat, [e], [ENOENT], [ESTALE, EBUSY])
File
"/usr/lib/x86_64-linux-gnu/glusterfs/python/syncdaemon/syncdutils.py", line
546, in errno_wrap
return call(*arg)
OSError: [Errno 22] Invalid argument:
'.gfid/00000000-0000-0000-0000-000000000001'
This time, the gfid matches the Gluster root: /opt/self. How may it fail over the empty root ? I review the complete setup with the dev guys and we could not find any issues with it: it correspond to the simpliest version of the documentation, without any potential permission issue as I built the setup as a root to begin with. One of them proposed to use a python script that can do it all “by magic”. The tool installation and usage is pretty straight forward … but yet: no luck.
After several days of digging, building and wiping things, using different hardware and VMs, I asked a simple question: is the distribued setup meant to be the source of the geo-replication? Colleagial positive answer as it’s available since version 3.5, as we are at version 7.3 and none of them touch this part of the code, it should work. Right. Should is the key to it all. None of them tested this setup since the branch 4.x of GlusterFS. Or fair enough, I can build a new setup quite quickly: let’s move to a replicated setup as a source to the geo-replication… And voilà! Now it works perfectly fine. There was some regression at least since the branch 5.x and no once noticed.
Not the most perfect solution but I can still achieve the same results my customer expect. Let’s move to a new setup:
Each country has its own cluster GlusterFS (the master being in France)
Each server has 10 disks of 4 TB available for this storage, built in software Raid type 0, formatted in XFS
Each node mounts the cluster locally with these parameters: `127.0.0.1:/storage-fr /opt/self glusterfs defaults,_netdev,noatime,log-level=ERROR,log-file=/var/log/gluster.log,direct-io-mode=no,fopen-keep-cache,negative-timeout=10,attribute-timeout=30,fetch-attempts=5,use-readdirp=no,backupvolfile-server=fs-fr-02 0 0
Ok we have a working setup, we can import the 11 TB. It will take quite some time. I run a simple rsync command in a screen without supervising it, and I’ll repeat the command over and over until the migration to be as up-to-date as possible prior to the M-Day:
So far so good, the M-Day is here and we decide to proceed with the migration. We update the mount points and benefit from the same options as previously. The customer is happy as the promised performance are reach in term of latency and throughput. Meaning, I’m happy and relieved.
Did you think it was over?
A couple hours later, his biggest customer in the US reach him out as they can’t access any files. Checking the logs, I can see a bunch of HTTP codes 200 and 304, so I wonder if the issue is a pebcak or an intermediate cache issue somewhere else: I request a couple of problematic URL to test.
Checking the provided URL on both FR and CA platforms, I succeed to reproduce the issue. Checking first the edge servers, they show that the files do not exists. As the platform data was up-to-date, it is pretty unclear. Comparing the same folder on both platforms, the CA instance appear … empty. But df reports the same volume usage. I decide to just add a simple -a param to my ls … and there they all are: the files exist, with the proper size, in the proper folder but instead of player.json (for instance), it’s named .player.json.AbvgGY. Weird ? Not so much as this is the format of the temp files from an rsync. But why do GlusterFS do not fix them on the CA platform as the data and naming are valid on the FR side ? Simply because it relies on a simple checksum of the content, ignoring the name of the files (it expects to track the rename() operation on the fly).
At this stage, my guess is that something happened during the data importation leading to the wrong file being copied. Checking each cluster logs, status and details (including the heal info), it appears that a split-brain occured on the FR platform. Pretty logicial with only two nodes in it. Digging a bit more on the timestamps, logs, states, … At the end, a pretty race condition of multiple things:
a pebcak (from me): I ran the rsync command with no specific param, leading to the creation of temp files ; I should have added --inplace argument to ensure using the proper name at once
network issues at the provider stage: kinda expected but it occured multiple times, and part during the rename() operations
GlusterFS georep being too simple: why the heck don’t they include the name in the validation of the content?
So, as long as it’s simple to heal the FR cluster (both split-brain and invalid data on one node), fixing the names on the CA cluster is not obvious. There is no GlusterFS mechanism to do so, and I can’t afford waiting for a week for the data to sync again if I decide to wipe the data. From here, I come with a new idea that is just an abuse of what GlusterFS is and how to fix a split-brain situation.
I know that I have no more customer connections to the CA cluster as I moved them all to the FR cluster while solving the issue. To summarize the idea:
GlusterFS considers that writing to a local brick (outside of GlusterFS) is an issue as it will lead to a split-brain
A split-brain can be resolve by reading locally the file via GlusterFS (mountpoint over 127.0.0.1) if there is no concurrent access to it
a rename() operation does not change the gfid, it just update the underlying link GlusterFS use
We know the data is valid, just the name is an issue
Thanks to this, I write a quick script and run it over my folders:
#!/bin/bash
find /opt/brick/ -name".*"-type f | while read f;do
rename -f-d-v's/\\.([^.]*)\\.([^.]*)\\..*/$1.$2/'$fbrick=`dirname $f`self=`echo$brick | sed 's/brick/self/g'`filename=`basename $f`echo$self | xargs ls-la &> /dev/null
dest=`dirname $brick`sudo rsync -a--inplace$brick root@fs-ca-02:$dest--delete-after> /dev/null
done
exit 0
Not the proper thing but efficient at least. It rename the file and ensure to solve the split-brain, before removing any invalid remaining dot file on the other node of the cluster. Neat.
One more thing…
We should be fine. “Should”. But we are not. New issue occurs on the edge servers as a full heal is running on the FR platform. Some of them expose corrupted files that are being healed, then cache those invalid files. As they are ok on both nodes of the cluster, the issue is clearly on the edge servers. To solve it, we just need to umount/mount the Gluster endpoint. Quick, efficient. We should re-do it once the full heal is achieved.
Besides all those issues with GlusterFS 7.3, I used to run a bunch of setup based on it … until the branch 4.x included. It used to be a bit more stable/reliable. I love the solution as it’s just a new layer, allowing you to build lots of things under it or around it. When it works, it just works. But when you have issues, the logs are not your best friend. I thing this is the main issue for a larger adoption of GlusterFS at this stage: the log entries and the documentation.
Do you use GlusterFS to build your reliable storage or geo-replication services ? Do you struggle with it ? Feel free to ping me to discuss more about it.
En 2012, j’écrivais un article « L’état du libre dans les téléphones » . On était encore à l’époque où Apple dominait le marché des smartphones et Mozilla présentait feu-Boot2Gecko. C’était un beau bordel avec une série d’acteurs qui essayaient de rattraper le train en marche après s’être rendu compte du potentiel des smartphones. Je concluais l’article par un triste :
Je pense qu’aujourd’hui, il n’y a pas d’alternative suffisamment mature à Android et il est donc toujours le meilleur calcul.
Mais 8 ans plus tard, la situation est sûrement meilleure non ? N’est-ce pas ? …
La quête d’un OS libre pour téléphone
De mon article de 2012, la plupart des projets expérimentaux sont morts ou en voie de garage. Plus de Firefox OS, plus de Meego, Tizen relégué aux montres de Samsung et WebOS sur les frigos de LG. Faisons un rapide tour du paysage des OS +/- libres pour téléphone en 2020.
Android
Android étant maintenant ultra-majoritaire avec 70-80% de part de marché, la bonne nouvelle est que Linux s’est enfin imposé comme noyau sur la majorité des appareils dans le monde ! Cependant, un noyau libre ne sert à rien si l’enrobage est rance. Android a également attrapé les travers d’Apple. Le Play Store est toujours plus cadenassé, plus aucune application préinstallée n’est open source, surveillance à gogo. Le Don’t Evil était encore un slogan en 2012 mais n’est aujourd’hui plus qu’un lointain souvenir.
Comme Framasoft le dit si bien, il est temps de se dégoogliser !
LineageOS
LineageOS est le fork de CyanogenMod, lui-même fork d’Android. Malgré une histoire un peu difficile suite à la fermeture de CyanogenMod par manque de rentabilité en 2016, LineageOS continue son bout de chemin. Il reste, aujourd’hui, la meilleure alternative si on veut un Android sans la dépendance à Google sur un téléphone grand public ou maintenir à jour un téléphone dont le constructeur aura lâchement abandonné le support après 4 mois.
Après 6 mois d’utilisation, en lançant 3 applications en parallèle
/e/ et Replicant
Choisir un nom impossible à chercher sur un moteur de recherche est sans doute une volonté pour un projet se voulant respectueux de la vie privée… /e/ est un dérivé d’Android (ou de LineageOS plus exactement) se focalisant sur la vie privée et l’open source. La plupart des services Made in Google ont été remplacés par des alternatives libres (CardDAV pour la synchronisation des contacts, etc.). Il est même possible d’acheter un téléphone reconditionné avec /e/ préinstallé.
Replicant se base également sur LineageOS pour offrir une version sans aucun composant propriétaire. Il est, entre autres, supporté par la Free Software Foundation qui les héberge. Alors que /e/ est encore en développement actif, je parlais déjà de Replicant il y a 8 ans. Si /e/ se veut une solution clef en main fonctionnant avec le plus d’appareils possibles, Replicant ne supporte aucun driver non-libre, ce qui rend la liste d’appareils supportés beaucoup plus restreinte.
Notez qu’il existe toujours une myriade d’autres projets +/- libres avec +/- d’appareils compatibles.
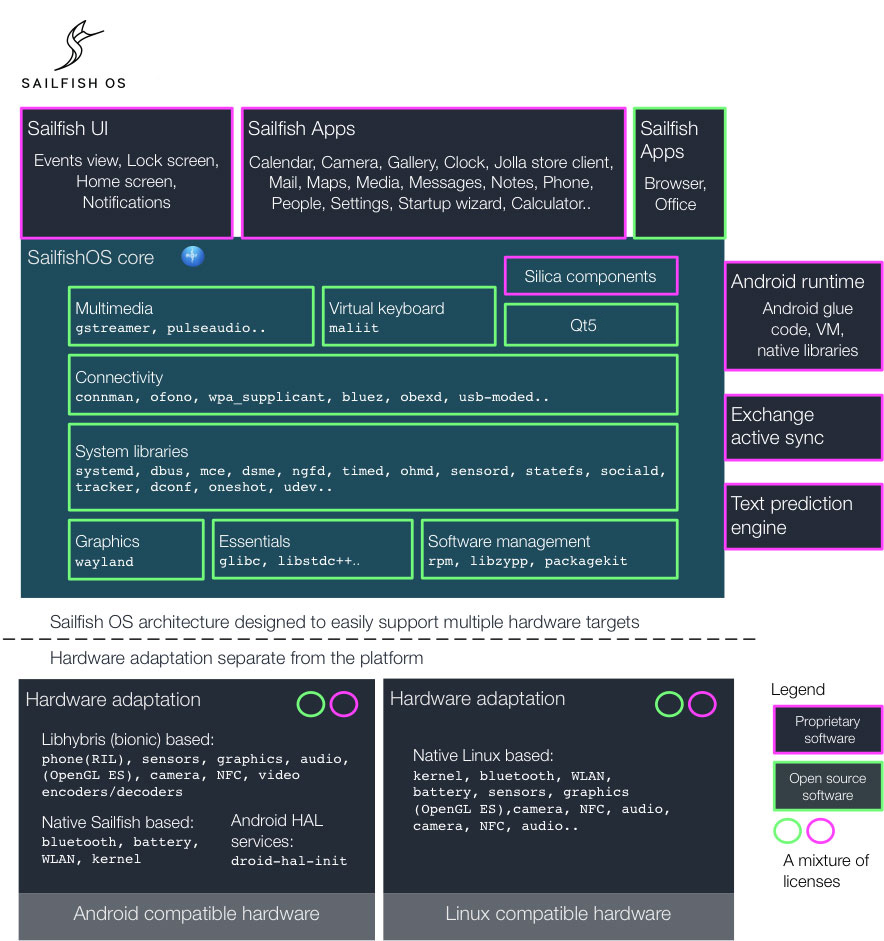
Sailfish OS
Sailfish OS est le système développé par la société finlandaise Jolla. Il utilise Mer Core comme base. C’est-à-dire que Mer sert de middleware entre le matériel et l’OS. Si votre appareil supporte Mer, vous pourrez faire tourner Sailfish OS. Je ne dis pas que ça sera facile mais vous ne devrez pas écrire de driver…
Si Sailfish OS met en avant son coté alternatif et son esprit open source, le complètement libre ne semble pas non plus au rendez-vous. Le modèle est assez similaire à celui d’Android : la société Jolla assemble les composants libres, y ajoute son interface et quelques composants propriétaires (comme par exemple une couche de compatibilité permettant de faire tourner les applications Android sur Sailfish OS). Si elle a produit des téléphones à une époque, Jolla essaye pour l’instant de vendre son OS pour les appareils compatibles (des Sony Xperia). Il existe une série d’appareils alternatifs avec des ports +/- fonctionnels.
En vert libre, en mauve propriétaire
Ubuntu Touch
Canonical a abandonné l’idée d’un Ubuntu sur smartphone en 2017. Heureusement, une communauté de motivés l’a repris via UBports. Il existe quelques appareils sur lesquels il est possible d’installer un Ubuntu 16.04 (oui ça date un peu) et de profiter d’un véritable Linux avec toute sa flexibilité.
postmakerOS
Lors de la rédaction de cet article, le certificat SSL du site de postmakerOS avait expiré, symptomatique du monde des projets expérimentaux de smartphone libre portés surtout par des volontaires avec peu de moyens. Pourtant, postmakerOS semble toujours bien actif. Avec plus d’une centaine d’appareils compatibles (c’est-à-dire pouvant démarrer l’OS, pour ce qui est du support du Wifi ou Bluetooth, c’est beaucoup plus aléatoire), il y a de quoi s’amuser.
Dans un esprit très Linux, ils proposent un micro-système (10MB) basé sur Alpine Linux sur lequel on installe les packages voulus. Libre à vous de faire tourner les programmes voulus. L’idée de cette approche modulaire est de facilement proposer une image pour de nouveaux appareils et de les maintenir à jour (un gros problème sur les appareils Android avec les téléphones ne recevant plus de mise à jour système après seulement quelques mois).
À la recherche d’un système réellement libre
PureOS/Librem
PureOS est le système développé par la société Purism et vise les appareils Librem, dont le récent téléphone (expérimental) Librem 5. Il se base sur Debian et est un système de type convergence (comme Ubuntu Touch, branchez un clavier et un écran pour transformer le téléphone en PC) avec une interface GNOME.
L’approche de Purisme vise l’open source et la sécurité à tous prix. Composants et logiciels ouverts avec kill switches matériels. ArsTechnica a écrit un article le mois passé à son sujet. C’est encore à l’état de prototype (pas moyen de passer un appel) mais cela vise les hackers voulant tester un appareil réellement libre. La liberté ayant un coût, comptez aujourd’hui 749$ pour un prototype et 1999$ pour le même appareil fabriqué entièrement aux États-Unis (plutôt qu’en Chine). Les livraisons se font par petits batchs tous les quelques mois, un batch étant une amélioration de l’appareil livré précédemment. On n’est pas encore à un appareil utilisable par le grand public mais on s’en approche.
Je peux compiler Gentoo là- dessus ?
PinePhone
Si Purism voulait tout maîtriser, du matériel au logiciel, Pine64 ne produit que le matériel. Après avoir produit le portable PineBook, la montre PineTime, la tablette PineTab et autres, ils s’attaquent au téléphone avec le PinePhone. Beaucoup plus abordable, pour 149$ vous pouvez obtenir la version BraveHeart qui est un smartphone… sans OS. A vous d’installer l’un des ports expérimentaux d’un des systèmes possibles (Ubuntu Touch, Sailfish OS,…). A réserver aux bidouilleurs avertis.
Est-ce que la situation est mieux qu’en 2012 ? Oui et non. L’écosystème est on ne peut plus occupé par le duopole Android et iOS qui totalisent 99% du marché. Autant dire qu’aucune alternative n’a percé et, aujourd’hui, je ne m’attends pas à ce qu’une arrive à court terme.
D’un autre coté, les projets de systèmes libres se démocratisent. En 2012, il fallait avoir un Samsung ou HP pour espérer créer un nouvel OS viable (et viable est un grand mot vu le résultat). Aujourd’hui, Purism arrive à lever plus de 2 millions de dollars en 60 jours pour produire un appareil ouvert de A-Z.
Si tous ces projets sont encore très expérimentaux (il suffit de regarder cette vidéo de comparaison de différents OS pour se rendre compte qu’il reste du boulot), ils ont le mérite d’exister. C’est beau de voir qu’il y a des gens qui se donnent du mal pour sortir du merdier dans lequel on se trouve.
En 2030, je prédis SteamOS majoritaire
Et j’utilise quoi alors ?
Une des problématiques que je n’aborde pas dans cet article (se focalisant sur les systèmes d’exploitation) mais essentielle est la couche applicative. A mon grand malheur, me priver aujourd’hui d’applications comme WhatsApp n’est quasi plus possible si je ne veux pas me couper de mon cercle social. Et convaincre mon entourage à passer sur Signal ne réglera pas le problème vu que toutes ces applications populaires ne fonctionnent que sur l’un des deux OS. Le système que l’on utilisera dépendra de ses habitudes et des concessions que l’on est prêt à faire. Dans mon cas, une compatibilité minimale avec les applications Android est encore nécessaire aujourd’hui.
Mais finalement, est-ce que le système d’exploitation est vraiment le seul problème ? A quoi bon avoir un téléphone 100% libre si l’on exploite des ouvriers chinois en épuisant les mines de cobalt pour produire un nouvel appareil tous les 18 mois ? Une société comme FairPhone proposant un téléphone produit de façon éthique et assurant une réparabilité de l’appareil est tout autant essentielle.
A quoi bon avoir un téléphone 100% libre si c’est pour passer son temps sur les applications voleuses d’attention comme savent si bien le faire les réseaux sociaux ? A une époque où l’on prône la déconnexion, pourquoi pas un téléphone avec des choix radicaux comme le Hisense A5 (testé par Ploum) avec son écran e-ink ?
Je n’ai pas de conseil sur ce que vous devriez utiliser si ce n’est de tirer un maximum du téléphone que vous possédez déjà (et de le faire réparer lorsque que l’écran cassera). Lorsque mon téléphone actuel, arrivant bravement sur ses 3 ans, décédera, je verrai quel appareil conviendra à mes besoins. Mes besoins à ce moment-là, en trouvant un équilibre entre liberté logicielle, respect de l’environnement et me permettant de maintenir les liens sociaux. Mais j’espère que ce choix ne se présentera pas trop vite…