Ces dernières semaines, j'ai réalisé plusieurs Pull Requests sur des projets écrits en Go. J'ai travaillé sur une fonctionnalité qui permet d'ajouter des informations dans le registre de paquet de Gitea, j'ai corrigé un bug sur l'outil d'intégration continue Woodpecker et j'ai proposé une fonctionnalité pour Codeberg/pages-server que j'utilise pour héberger des pages statiques. Ces contributions étaient mes premiers pas avec Go et j'ai vraiment apprécié ce langage.
Pour en apprendre un peu plus, j'ai décidé de réécrire un projet initialement en PHP. Le use case est très personnel, mais il peut sans doute plaire à d'autres personnes. Il s'agit d'un outil client/server en ligne de commande pour servir des fichiers vidéos distants.
Le projet s'appelle Mugo et les sources sont libres ! Je fourni un unique binaire qui permet de lancer le serveur et le client.
Côté serveur, il suffit de définir quel est le répertoire où se trouvent les vidéos, sur quel port écouter et l'adresse publique du serveur web qui sera démarré (API). Coté client, on définit l'adresse du serveur web (API) et éventuellement les filtres à appliquer.
Une fois le serveur démarré, le client peut s'y connecter et afficher les vidéos disponibles. Les vidéos pourront être sélectionnées interactivement avec leur numéro ou en spécifiant une plage.
Pour démarrer le serveur, la commande est simple : mugo serve. Le répertoire courant sera servi par défaut et il écoutera sur le port 4000. Il est possible de spécifier l'adresse publique du serveur avec l'argument --api-url (si reverse proxy par exemple).
Dans mon cas, l'API exposée par le serveur est accessible via un frontend Apache2. L'adresse du proxy est sous la forme https://videos.example.com. Mes fichiers sont stockés dans le répertoire /srv/videos (sous répertoires inclus). Voilà comment je lance le serveur :
Je peux maintenant accéder à l'API via https://videos.example.com/api/list.
Côté client, je peux afficher la liste des vidéos comme suit. Le résultat de chacunes de ces commandes sera une liste de vidéo avec un prompt interactif.
# Lire les fichiers (mpv)
$ mugo play -u https://videos.example.com
# Télécharger les fichiers (wget)
$ mugo download -u https://videos.example.com
$ mugo download -d "$HOME/Videos" -u https://videos.example.com
# Afficher que les fichiers qui contiennent "batman"
$ mugo play -u https://videos.example.com -n batman
# …et les ordonner par nom
$ mugo play -u https://videos.example.com -n batman -o name
Toutes les infos sur le projet son dispos sur Gitnet 🙂
Dans mon dernier article, j’ai tenté de faire un état des lieux des solutions possibles pour implémenter des batchs cloud natifs.
J’ai par la suite testé plus en détails les jobs et cron jobs Kubernetes en essayant d’avoir une vue OPS sur ce sujet.
Le principal inconvénient (qui ne l’est pas dans certains cas) des jobs est qu’on ne peut pas les rejouer.
Si ces derniers sont terminés avec succès - Vous allez me dire, il faut bien les coder - mais qu’on souhaite les rejouer pour diverses raisons, on doit les supprimer et relancer.
J’ai vu plusieurs posts sur StackOverflow à ce sujet, je n’ai pas trouvé de solutions satisfaisantes relatifs à ce sujet.
Attention, je ne dis pas que les jobs et cron jobs ne doivent pas être utilisés.
Loin de là.
Je pense que si vous avez besoin d’un traitement sans chaînage d’actions, sans rejeu, les jobs et cron jobs sont de bonnes options.
Le monitoring et reporting des actions réalisées peut se faire par l’observabilité mise en place dans votre cluster K8S.
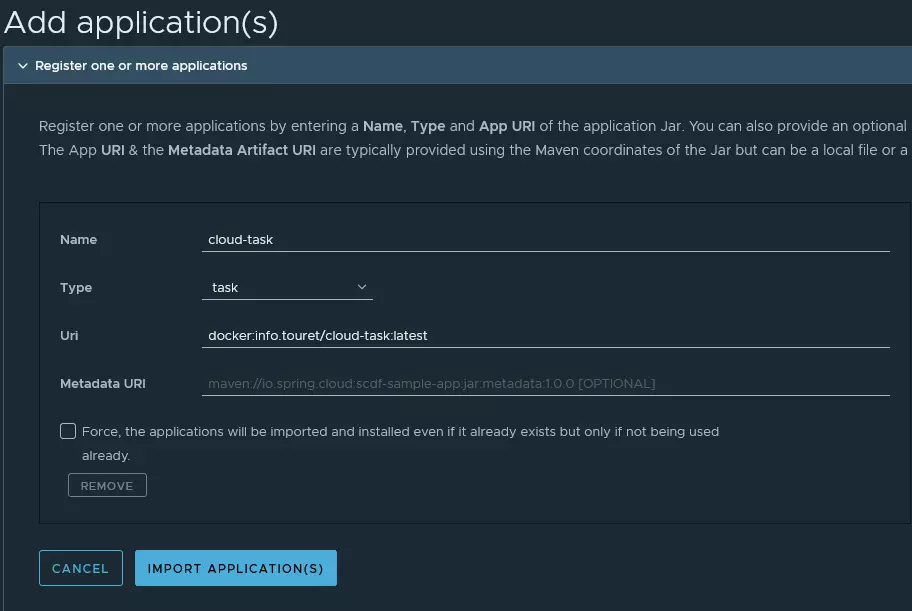
Après plusieurs recherches, je suis tombé sur Spring Data Flow.
L’offre de ce module de Spring Cloud va au delà des batchs.
Il permet notamment de gérer le streaming via une interface graphique ou via son API.
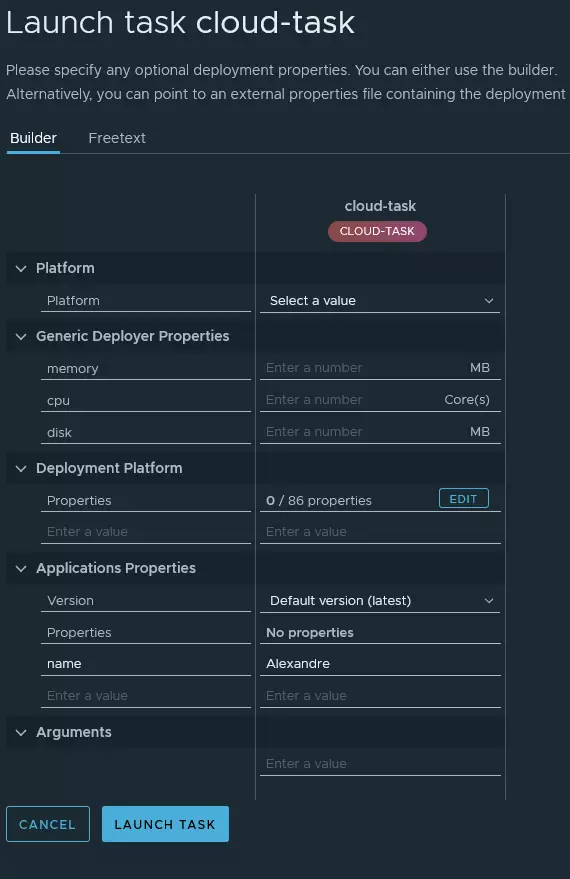
Dans cet article, je vais implémenter un exemple et le déployer dans Minikube.
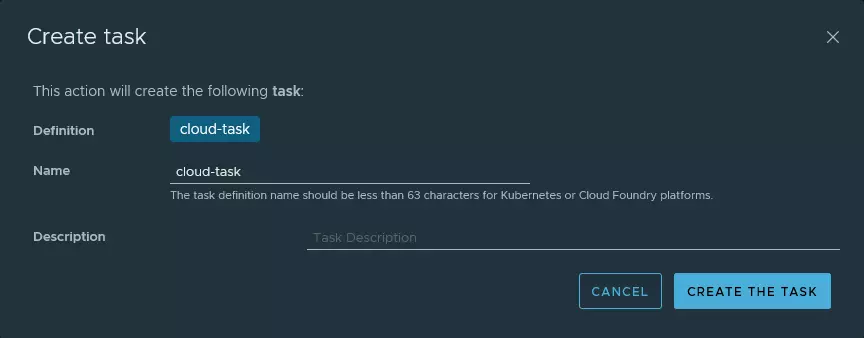
Maintenant, il nous est possible de lancer notre tâche.
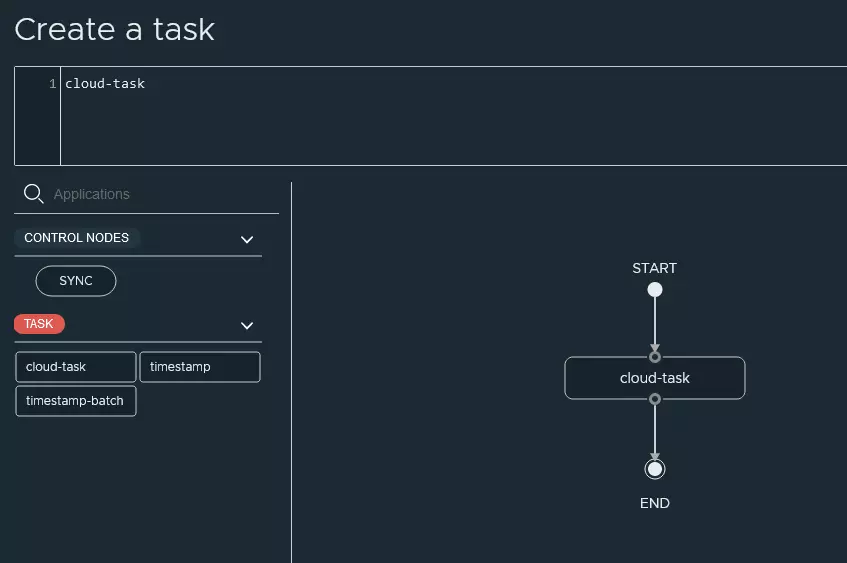
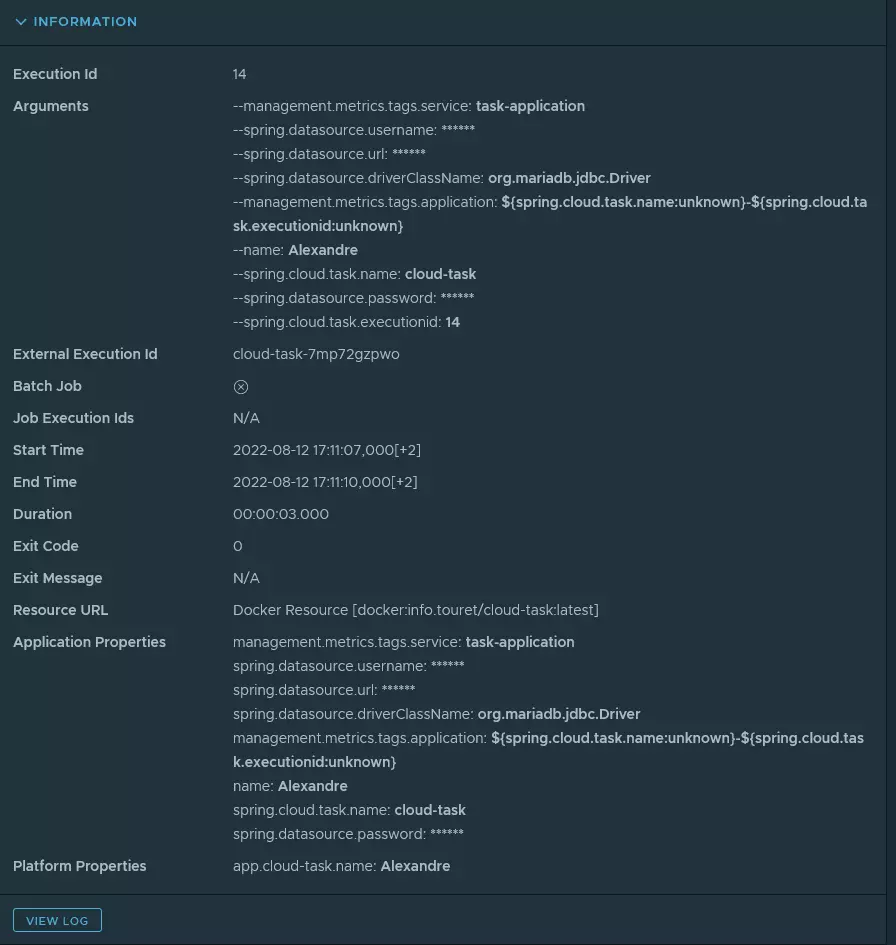
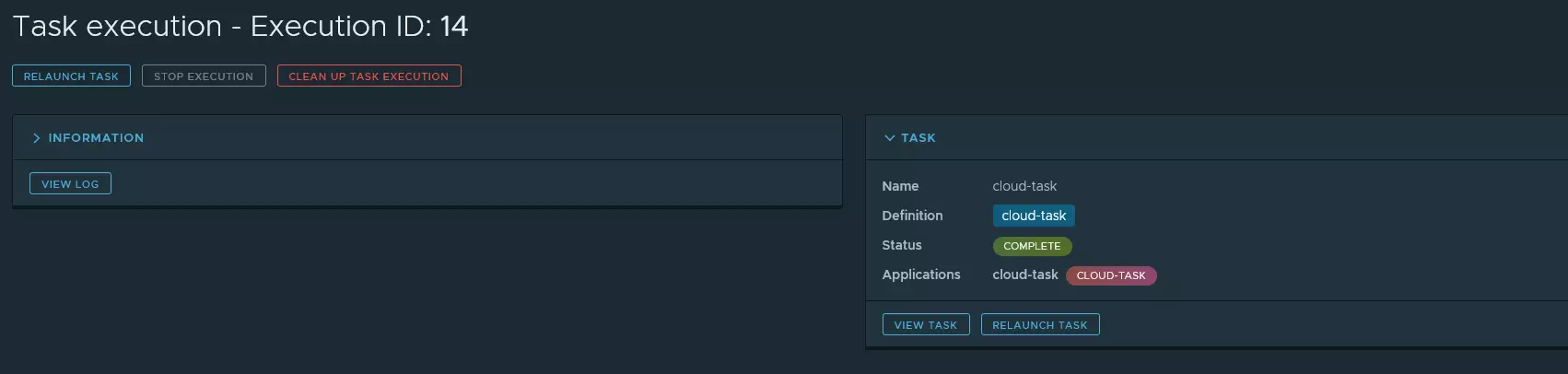
Vous trouverez dans les copies d’écran ci-dessous les différentes actions que j’ai réalisé pour exécuter ma toute nouvelle tâche.
Exécution de la tâche
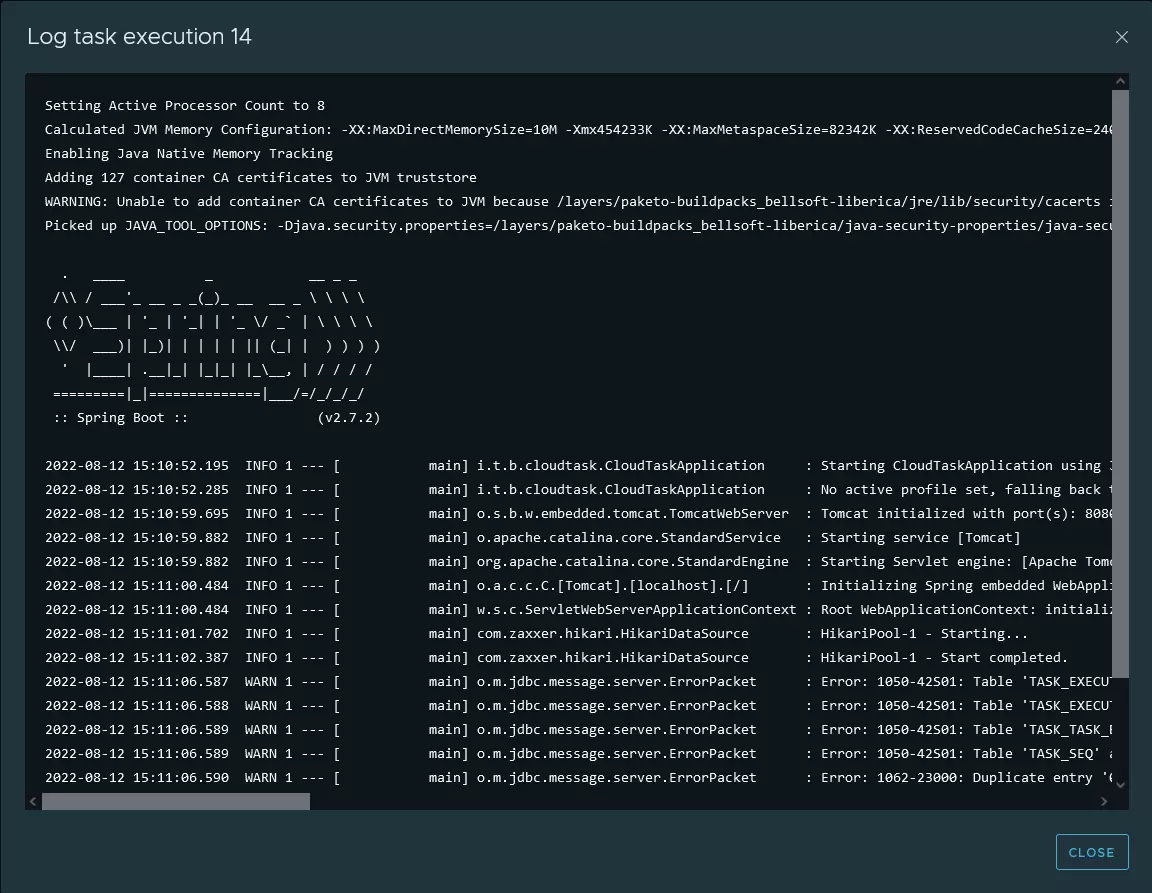
J’ai pu également accéder aux logs.
Il est également important de noter qu’ après l’exécution d’une tâche, le POD est toujours au statut RUNNING afin que Kubernetes ne redémarre pas automatiquement le traitement.
Bien évidemment, cette notation est purement personnelle.
Vous noterez que selon où on positionne le curseur, l’une des deux solutions peut s’avérer meilleure (ou pas).
Bref, tout dépend de vos contraintes et de ce que vous souhaitez en faire.
A mon avis, une solution telle que Spring Cloud Dataflow s’inscrit parfaitement pour des traitements mixtes (streaming, batch) et pour des traitements Big Data.
... voici le numéro 183, celui de juillet 2022, traduit en français par nos soins. Vous pouvez le télécharger ou le visionner sur notre page NUMÉROS ou le récupérer directement en cliquant sur la photo de couverture ci-dessous.
Comme vous pouvez le constater, la critique d'une distribution ni Debian, ni Ubuntu, concerne quelque chose avec un nom bizarre, SliTaz 5.0, qui, comme dit Adam Hunt, est beaucoup plus intéressant qu'il semble à premier abord. Tout un système d'exploitation en moins de
60 Mo (ce n'est pas une faute de frappe) ? C'est possible !
Les autres critiques ont pour sujet Lubuntu 22.04 LTS, un livre sur la Récursion dans Python ET JavaScript et un jeu. En fait, ce n'en est pas exactement un. Il s'agit de Pico-8 avec lequel vous pouvez créer des jeux, du pixel art, de la musique ; le tout dans un petit espace, 128 x 128 pixels, qui mime l'écran d'une très vieille machine. Après, vous pouvez partager vos créations avec des copains et voir celles d'autres « joueurs » aussi.
C'est l'été et il y a des rubriques manquantes : Ubuntu au quotidien, Micro-ci micro-là, Blender, mais il y a C & C, Python, LaTeX et Inkscape, ainsi qu'une longue Mon Histoire, les trois pages de Q. ET R., et....... les ACTUS qui, de façon assez désespérant pour l'équipe française, font le tiers de la revue ce mois-ci.
Nous vous en souhaitons bonne lecture et un excellent mois d'août,
Bab, scribeur et relecteur, d52fr, traducteur et relecteur, et moi, AE, traductrice et relectrice
En avril 2022 la fondation Raspberry Pi a annoncé que pour des raisons de sécurité, le compte utilisateur pi et le mot de passe raspberry qui étaient jusqu’à présent définis par défaut lors de l’installation d’un Raspberry Pi avec Raspberry Pi OS seraient désormais désactivés.
Si la présence d’un compte par défaut était effectivement discutable du point de vue de la sécurité, car ouvrant la voie à des attaques automatisées visant les équipements mal configurés, cela était en revanche bien pratique pour les utilisateurs. Dans ce tutoriel nous allons donc voir comment définir un utilisateur et un mot de passe pour le Raspberry Pi, d’abord lors de l’installation de Raspberry Pi OS sur la carte SD, puis après l’installation de Raspberry Pi OS, si vous avez oublié de définir le mot de passe lors de la création de la carte SD.
Définir le mot de passe utilisateur au moment d’installer Raspberry Pi OS
Dans un premier temps, nous allons voir comment définir le mot de passe de l’utilisateur lors de l’installation de Raspberry Pi OS (anciennement Raspbian) sur la carte SD.
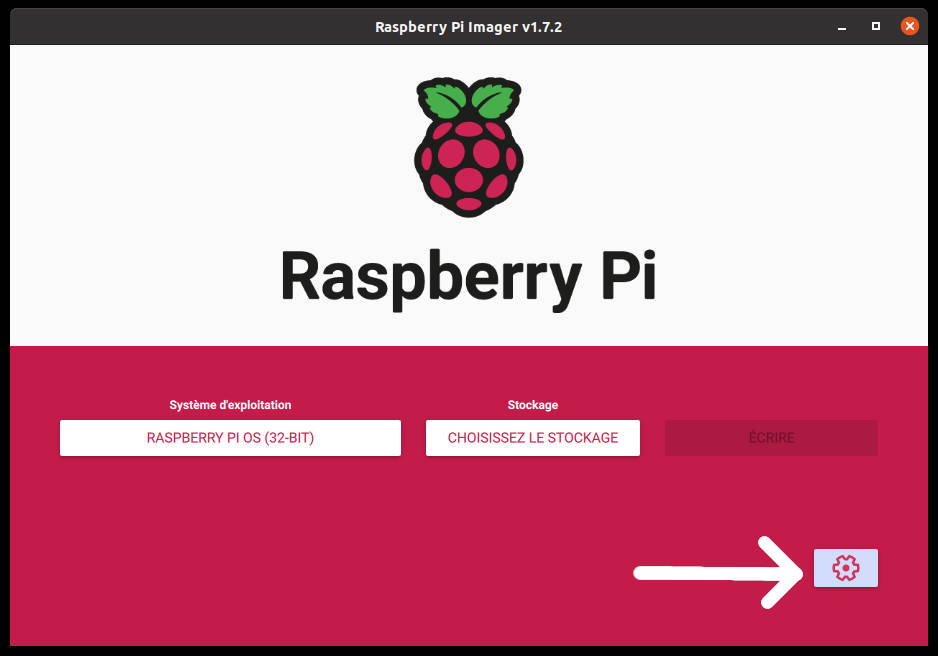
Vous pouvez donc insérer votre carte SD dans votre ordinateur, lancer le logiciel Raspberry Pi Imager, et cliquer le bouton pour choisir l’OS de votre choix, dans le cas présent Raspberry Pi OS. Une fois que vous avez choisi l’OS, vous pouvez voir qu’un bouton avec une icône d’engrenage apparaît en bas à droite du logiciel.
Après le choix de l’OS un engrenage apparaît.
En cliquant sur cette icône vous pourrez alors accéder à la fenêtre des options avancées, laquelle vous permettra de choisir d’activer ou non un serveur SSH, de configurer un réseau Wi-Fi, mais surtout, et c’est ce qui nous intéresse, de créer un compte utilisateur et un mot de passe par défaut.
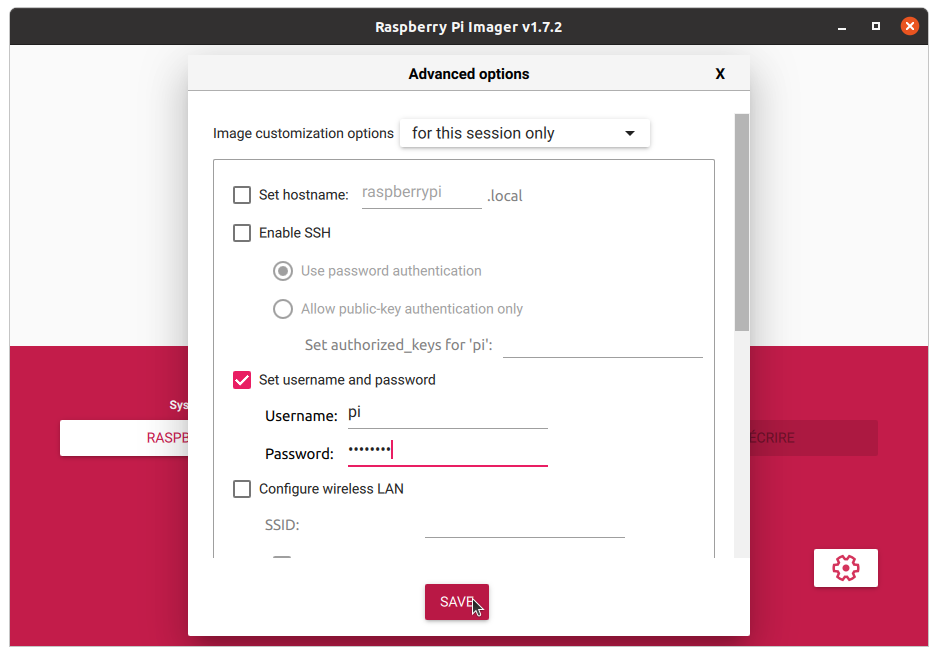
Cochez donc la case « Set username and password », et rentrez le nom utilisateur et le mot de passe de votre choix dans les champs « Username » et « Password ». Dans mon cas j’utilise généralement le compte pi et le mot de passe raspberry, par habitude, mais vous pouvez tout à fait utiliser le mot de passe de votre choix.
Petit point à considérer tout de même, si vous n’utilisez pas un clavier QWERTY, n’oubliez pas qu’il est possible lors de votre première connexion que le clavier du Pi ne soit pas dans votre langue habituelle, essayez donc, au moins pour la première installation, d’éviter les accents et autres caractères spéciaux ou régionaux…
Cochez la case « Set username and password » et renseignez le nom d’utilisateur et le mot de passe de votre choix.
Après cela, il ne vous reste plus qu’à cliquer sur le bouton de sauvegarde en bas des paramètres avancés, choisir la carte SD sur laquelle installer l’OS, et lancer l’écriture sur la carte.
Une fois l’écriture terminée, retirez la carte, insérez la dans le Raspberry Pi, branchez-le, et attendez jusqu’à la fin de l’installation, et voilà, votre compte utilisateur est prêt !
Comment créer un compte utilisateur après la création de la carte SD et sans interface graphique !
Il arrive souvent que l’on oublie de créer le compte utilisateur lors de la création de la carte SD, que ce soit par méconnaissance ou par simple distraction. Heureusement, il est toujours possible de définir un compte utilisateur et un mot de passe par défaut après la création de la carte SD, et ce sans avoir besoin d’interface graphique ou de clavier à connecter au Raspberry Pi.
Attention néanmoins, la création d’un utilisateur via cette méthode n’est possible que jusqu’à ce que le compte par défaut ait été créé. Une fois le compte par défaut créé vous devrez impérativement passer par celui-ci et utiliser la commande rename-user.
Pour définir le compte utilisateur par défaut, il vous suffit, en fait, de créer un fichier qui contiendra le nom de l’utilisateur à créer, ainsi que le hash de son mot de passe, séparés par deux point.
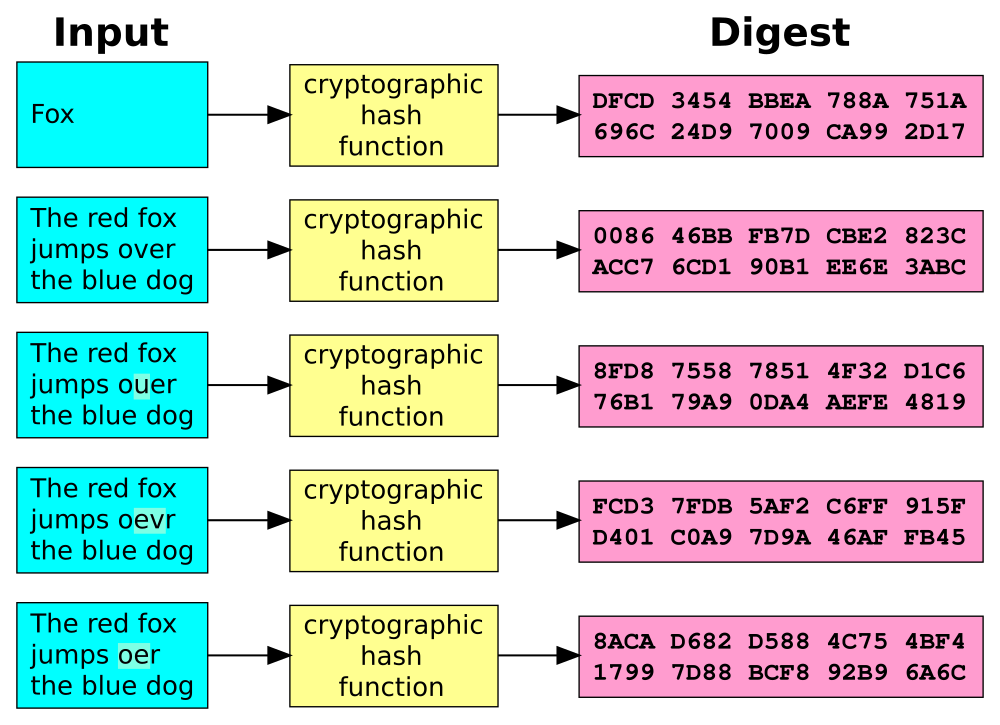
La notion de hash correspond à l’idée de prendre des données en entrée d’un algorithme, par exemple un mot de passe, et de générer en sortie une chaîne de caractères d’une longueur fixe, et qui, idéalement, aura les trois caractéristiques suivantes :
Être toujours la même pour deux entrées similaires
Être toujours différente pour deux entrées différentes
Ne pas permettre de retrouver les données d’entrée
Même une variation d’un seul bit en entrée change complètement la signature de sortie.
Grâce à ces caractéristiques, il est possible de stocker une forme dérivée d’un mot de passe, qui pourra par la suite être comparée à un mot de passe entré, mais qui ne permettra pas à un attaquant qui réussirait à accéder aux données stockées de retrouver le mot de passe original.
Si la notion de hash vous intéresse, vous trouverez plus d’informations sur la page wikipedia dédiée.
Il existe de très nombreuses fonctions de hachage, mais dans notre cas nous allons devoir hacher notre mot de passe dans un format qui corresponde à celui du fichier /etc/shadow, lequel contient la liste des mots de passe utilisateurs dans les systèmes Linux.
Pour cela, vous pouvez utiliser directement la ligne de commande mkpasswd sous Linux, mais le plus simple sera probablement d’utiliser un outil en ligne comme mkpasswd.net en choisissant comme type de hash crypt-sha512.
Il ne vous reste alors plus qu’à créer un fichier nommé userconf.txt dans la partition boot de la carte SD du Raspberry Pi, et d’y écrire :, ou sera le nom de l’utilisateur, et le hash de son mot de passe, tel que obtenu via mkpasswd.
À titre d’exemple, voilà ce que cela donne pour créer un utilisateur pi avec le mot de passe raspberry :
Il ne vous reste plus qu’à récupérer votre carte SD, l’insérer dans le Pi, attendre la fin du démarrage, et voilà, votre nouvel utilisateur est disponible !
Conclusion, fallait-il vraiment retirer le mot de passe par défaut ?
Nous espérons que cet article vous aura été utile, et qu’il sortira de l’embarras bien des débutants. À la rédaction de cet article et suite à notre utilisation du Pi depuis avril 2022, nous ne pouvons toutefois nous empêcher d’avoir quelques doutes quand au bien fondé de la suppression du mot de passe par défaut.
Ne pensez pas que nous ne soyons pas sensibles à la question de la sécurité informatique, bien au contraire. Et nous avons conscience que la présence d’un mot par défaut peut-être vu comme un risque de sécurité, spécialement dans le cadre d’attaques de masse automatisées. Mais nous pensons que la sécurité ne devrait pas être un frein à l’expérience utilisateur. Sans quoi elle ira de fait à l’encontre du but initial, nous en voulons pour preuve l’enfer des mots de passe nécessitant 8 lettres, 5 chiffres, 2 caractères spéciaux, 3 ornithorynque, 1 gnome enroulé dans du jambon, 2 boites de raviolis et une incantation à la lune chantée en mi-bémol, et grâce auxquels il suffit aujourd’hui de regarder sur les post-it accrochés aux écrans des secrétaires du monde en entier pour accéder à toutes les données d’une entreprise…
Hors, si la présence d’un mot de passe par défaut peut-être vu comme un risque de sécurité, ce risque restait faible dans le cadre d’une utilisation classique, c’est à dire sur un réseau privé, ceci d’autant plus que l’accès SSH à distance est désactivé par défaut.
La facilité d’utilisation apportée par la présence d’un compte par défaut sur un produit avec lequel il n’est pas rare de multiplier les installations et ré-installations était, elle, un vrai point positif à l’utilisation. D’autres solutions moins contraignantes et plus claires pour l’utilisateur débutant que la suppression pure et simple du compte par défaut nous semblaient plus adaptées.
Gitnet est la forge logicielle que je gère depuis quelques années et qui héberge la totalité de mes projets. Elle s'appuie sur l'excellentissime Gitea, un logiciel libre pour faire son propre Github/Gitlab sans dépenser des fortunes en ressources matérielles.
Gitea est un logiciel très complet mais une des fonctionnalités qui peut manquer à certain⋅e⋅s est la publication pages web statiques via la forge. Codeberg a développé Codeberg/pages-server, un projet écrit en GO qui permet de réaliser cette fonctionnalité. Il lance un serveur web et sert les fichiers qui sont récupérés via l'API. Après l'avoir forké pour le personnalisé, il est à présent déployé sur Gitnet Pages.
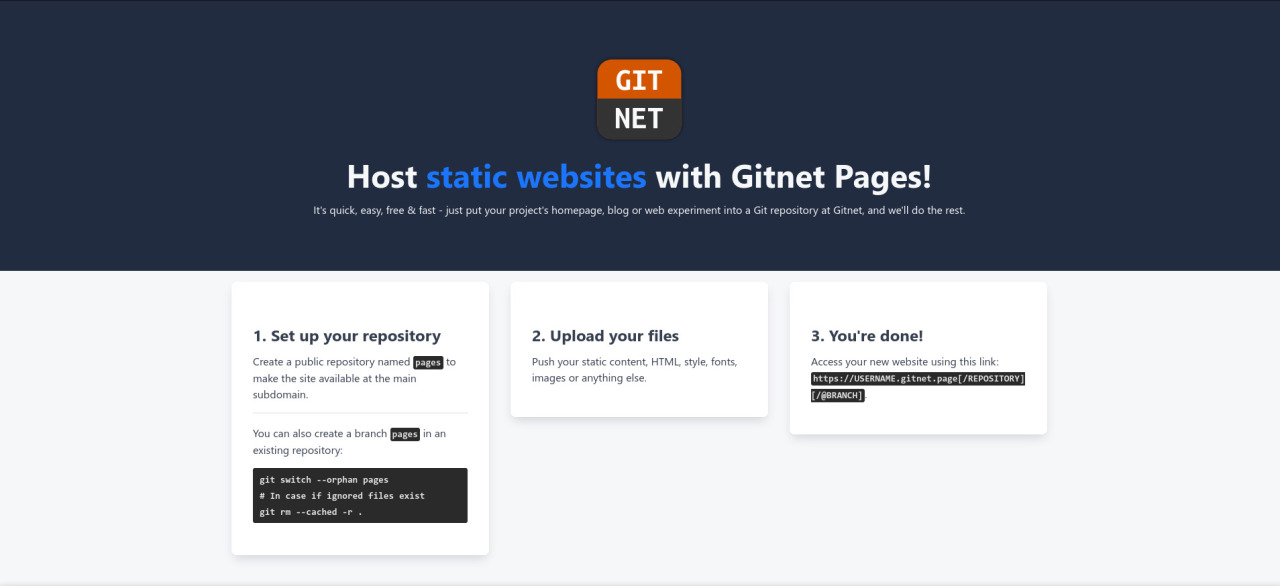
Pour commencer à publier, vous devez créer un dépot pages dans lequel vous déposerez y vos fichiers. Le contenu sera accessible via https://votre-login.gitnet.page/{fichier}.
Dans le cas où vous souhaitez intégrer des pages à un dépot existant, ajoutez une branche pages puis accédez à votre contenu via https://votre-login.gitnet.page/le-depot/{fichier} :
dev@project $ git switch --orphan pages
# Si vous avez des fichiers ignorés par git qui existent :
dev@project $ git rm --cached -r .
Et si vous désirez accéder à du contenu qui se trouve sur une autre branche, il faudra la spécifier de cette façon : https://votre-login.gitnet.page/le-depot/@la-branche/{fichier}.
Vous pouvez utiliser un générateur de site static mais il faudra ajouter un CI/CD. J'ai réalisé des tests avec Hugo + Woordpecker et ça marche bien ! On build la branche ou se trouve les sources, on copie le résultat dans la branche pages et on pousse le code sur Gitnet. Voici la configuration utilisée.
Si toutefois le service venait à être pas mal utilisé, alors j'intégrerai des fonctionnalités plus avancées comme le nom de domaine personnalité. Tel qu'il est déployé actuellement, ce n'est pas possible.