Déjà six moix après la version LTS, voici que la nouvelle version d'Ubuntu est de sortie : la 16.10 Yakketi Yak. Contrairement à la version précédente, celle-ci n'est pas une version LTS, c'est à dire qu'elle n'est pas supportée sur le long terme (2 ans), mais seulement 6 mois, donc jusqu'en juillet 2017.
Voici les nouveautés de cette version :
- Noyau Linux 4.8 avec une meilleure prise en charge de la partie graphique
- Plus de fluidité pour Compiz, le gestionnaire de fenêtres
- Une ergonomie améliorée pour Nautilus, le gestionnaire de fichiers
- L'environnement de bureau a été mis à jour vers Unity 7.5. La version 8 tant attendue est disponible en beta et sera présente dans Ubuntu 17.04.
- Les logiciels GNOME en version 3.20 ou 3.22
- Firefox 48
- LibreOffice 5.2
- Thunderbird 38
- Et... Les nouveaux fonds d'écran !
Bien entendu les différentes variantes d'Ubuntu ont aussi été mises à jour.
Voici une petite vidéo qui résumé les changements :
https://www.youtube.com/watch?v=WHeGDDnL56U
Rien de fou, donc. C'est une évolution en douceur de la dernière LTS.
Je vous conseille comme d'habitude de faire des sauvegardes de vos données avant de passer à l'acte. Si vous êtes sous Ubuntu 16.04 LTS et qu'il vous convient, pas la peine de vous risquer à faire cette mise à jour !
Sachez que vous pouvez mettre à jour depuis l'interface graphique de Ubuntu, mais le faire via le terminal est plus clair, et c'est quand même plus sympa !
Mettre à jour depuis une version LTS
Si vous êtes sous Ubuntu 12.04 LTS ou 16.04 LTS, il faut que vous changiez de canal de mise à jour.
Il suffit d'aller dans le gestionnaire de mise à jour et de sélectionner :
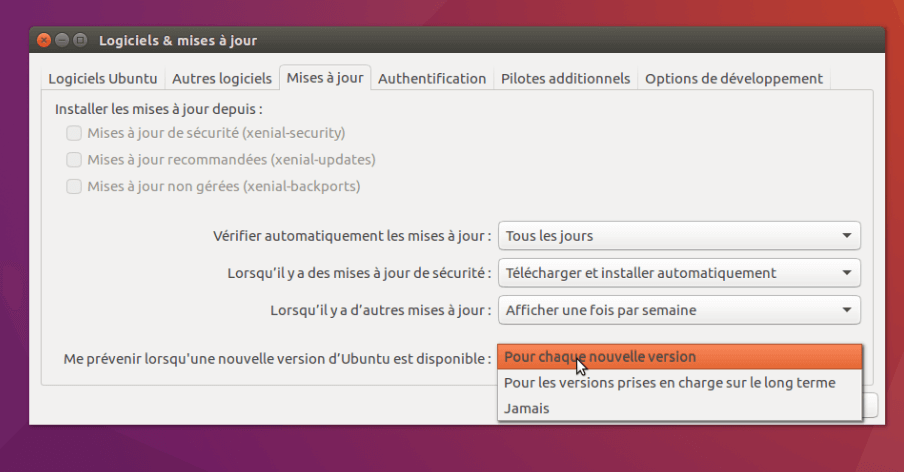
(Si vous n'êtes pas sous une version LTS, il n'y a rien à changer.)
Vous pouvez ensuite suivre les étapes ci-dessous.
Comment mettre à jour ?
Tout d'abord, on vérifie que notre système est à jour pour la version installée :
sudo apt update
sudo apt full-upgrade
Puis il suffit d'entrer cette commande dans votre terminal, elle va mettre à jour la liste des paquets, les dépôts et tous les paquets, tout se fait tout seul !
sudo do-release-upgrade
Note : Si cette commande ne trouve aucune mise à jour à faire, essayez avec ceci :
sudo do-release-upgrade -d
Attendez un peu, et il vous fera un résumé de paquets qui seront mis à jour. Généralement c'est plusieurs centaines de paquets à mettre à jour, alors soyez patients !
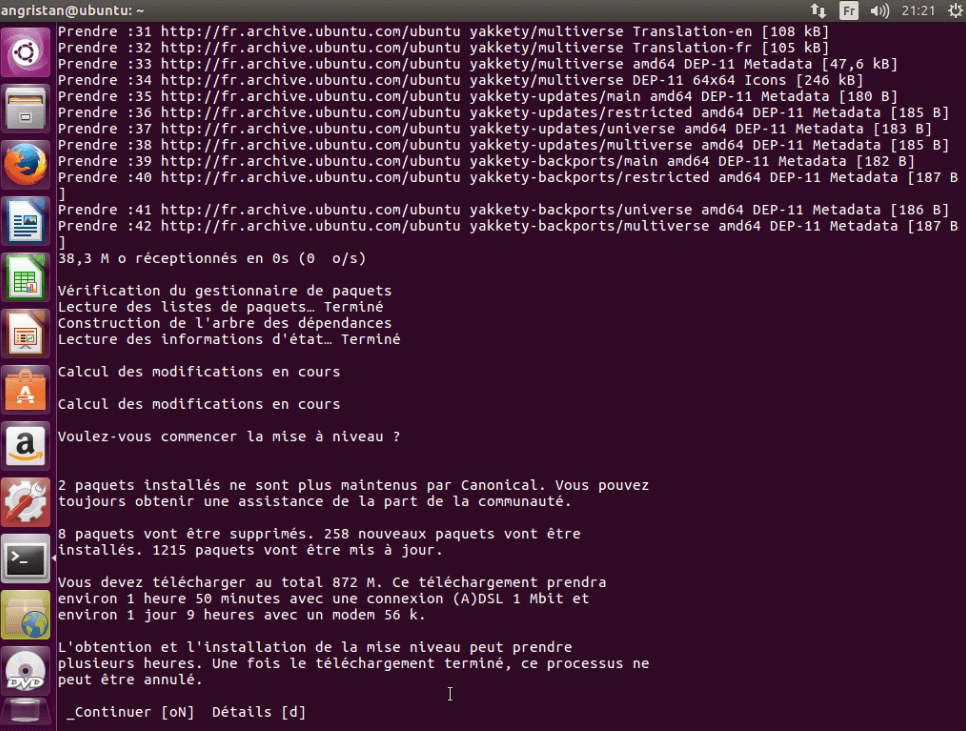
Une fois que la mise à jour vers Ubuntu 16.10 est terminée, vous pouvez redémarrer votre ordinateur. :)
On vérifie à nouveau que tout est bien à jour
sudo apt update
sudo apt full-upgrade
On nettoie le cache, là où se trouvent tous les paquets que l'on a téléchargé, ce qui doit représenter 1 ou 2Go :
sudo apt-get clean
sudo apt-get autoclean
sudo apt-get autoremove
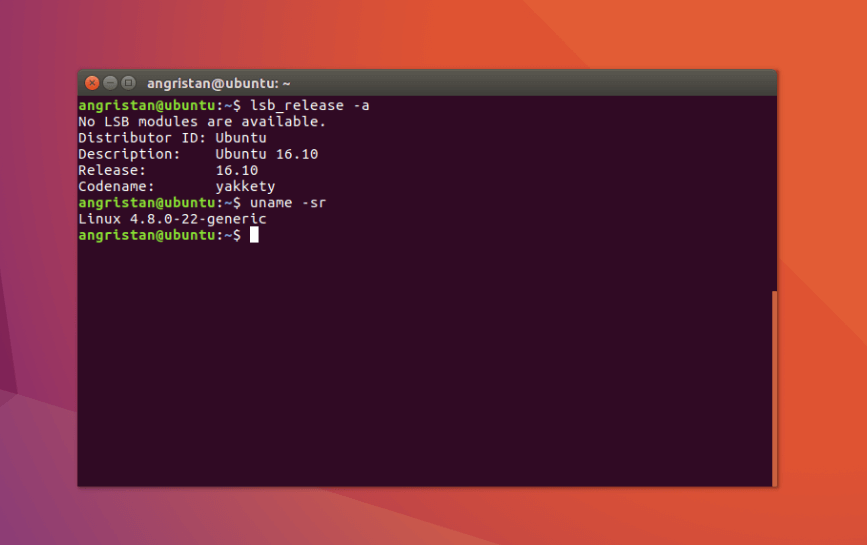
Et on vérifie qu'on est bien sous Ubuntu 16.10 Yakketi Yak !
lsb_release -a
uname -sr
Voici les versions d'Ubuntu supportées à ce jour (qui reçoivent des mises à jour) :
- 12.04 LTS jusqu'en avril 2017
- 14.04 LTS jusqu'en avril 2019
- 16.04 LTS jusqu'en avril 2021
- 16.10 jusqu'en juillet 2017
Vous pouvez télécharger Ubuntu 16.10 directement sur le site officiel.

Sources :
Je ne fais pas de support (surtout vu le nombre de demandes...) donc si vous rencontrez un problème je vous conseille de vous diriger vers une aide plus qualifiée comme le forum Ubuntu-fr.
L'article Mettre à jour Ubuntu vers la version 16.10 a été publié sur Angristan

Original post of Angristan.Votez pour ce billet sur Planet Libre.