Dans le petit monde des DevOps, la solution de virtualisation Docker a le vent en poupe. Nous allons dans ce billet essayer de décrypter ce qui ce cache derrière ce nouvel outil et proposer un tutoriel sur l'installation et les premiers pas pour une utilisation souple et efficace.
C'est quoi donc ?
Docker est un logiciel open-source (sous licence Apache 2.0) et un service en ligne optionnel (Docker.io) permettant de gérer des conteneurs ("dockers").
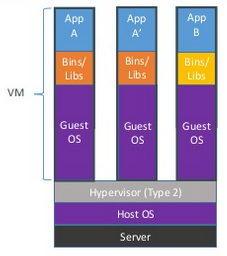
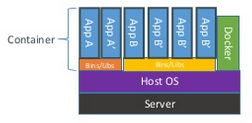
Contrairement aux machines virtuelles classiques qui comprennent un système hôte ("guest OS") et les librairies/applications, les conteneurs ne contiennent, au maximum, que les applications/librairies.
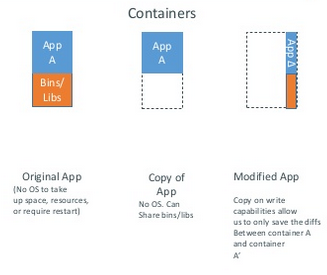
Quand je dis au maximum c'est qu'une copie d'un conteneur qui ne change que la partie application ne contiendra que les différences par rapport au conteneur initial.
Le système hôte est ainsi géré directement par le Docker Engine (en vert dans le premier schéma). On a ainsi une mutualisation qui permet de lancer les conteneurs de manière très rapide: le temps de lancement d'un conteneur est presque le même que le temps de lancement des applications qu'il contient. En effet, le système d'exploitation est déjà lancé. Donc pas de phase de démarrage ni d'initialisation de cette couche. Il faut quand même avoir à l'esprit que même si l'on est pas dans une machine virtuelle, on dispose tout de même d'un environnement isolé (processus, système de fichier, ports réseau). L'utilisateur n'a qu'à se préoccuper que de ce qu'il veut virtualiser (les applications/services) et ne s'occupe pas du reste.
L'autre gros avantage de cette technologie est la portabilité. En effet, il est tout à fait possible de concevoir un conteneur sur son PC portable puis ensuite de le déployer sur son infrastructure de production physique ou virtuelle. La taille des conteneurs étant relativement réduite, on peut donc imaginer un workflow de déploiement basée sur un repo central (type Git) et des Docker Engine installés sur les machines qui font elle même tourner des conteneurs. Il n'y a pas vraiment de limite au nombre de conteneurs qu'une machine puisse faire tourner. La limite vient de l'occupation mémoire/CPU/réseau de vos applications.
Si vous avez encore des questions sur la différence entre Docker et VM, je vous conseille la lecture de cette question sur StackOverflow: "How is Docker.io different from a normal virtual-machine ?".
Installation de Docker
Note (merci à @jb_barth pour le commentaire): jusqu'à la version 0.9, Docker se basait sur la technologie LXC ("Linux Containers") du noyau Linux et ne fonctionnait donc que sur des distributions GNU/Linux avec un noyau >= 2.6.24. La dépendance stricte à LXC a sauté depuis la v0.9.0, le driver par défaut est maintenant libcontainer, une lib pur go produite par le projet pour accéder de façon propre aux APIs dispos dans le kernel. C'est ce qui a permis de supporter des noyaux aussi vieux d'ailleurs, au début c'était >= 3.8
Voici les étapes à suivre pour installer Docker sur une distribution Ubuntu 14.04 LTS. A noter, pour les miséreux développeurs sous Windows ou Mac OS, il est est toujours possible de faire tourner une VM Ubuntu (par exemple avec VirtualBox) et de suivre cette installation.
Docker est directement disponible dans les repositories d'Ubuntu, donc un simple
sudo apt-get install docker.io
suffit pour effectuer l'installation complète de Docker sur notre machine comprenant:
- le Docker Engine (ou service Docker)
- le Docker Client (permettant de discuter avec le Docker Engine)
Comme les conteneurs vont utiliser les serveurs DNS de la machine hôte, il est nécessaire de configurer les adresses des serveurs DNS dans le fichier /etc/default/docker.io (par exemple avec les serveurs OpenDNS):
$ vi /etc/default/docker.io
# Use DOCKER_OPTS to modify the daemon startup options.
DOCKER_OPTS="-dns 208.67.220.220 -dns 208.67.220.222"
Pour que la configuration soit prise en compte, il faut relancer le service Docker avec la commande:
sudo service docker.io restart
Un petit ps permet de voir que le service est bien lancé:
0.0 0.1 563M 9.65M 733 root 0 S 0:00.46 0 0 /usr/bin/docker.io -d -dns 208.67.220.220 -dns 208.67.220.222
Récupération des images système
Nous allons commencer par récupérer des images qui vont servir de de bases à notre conteneur. Une liste assez conséquente d'images sont disponibles sur le site officiel du projet. Vous pouvez ainsi récupérer celle qui est le plus proche de l'environnement que vous recherché. Un moteur de recherche est disponible à l'adresse https://index.docker.io/ pour trouver des images conçues par les développeurs du projet et par des contributeurs.
On retrouve ainsi des distributions GNU/Linux minimales comme Ubuntu, CentOS, BusyBox pour ne siter que les images officiellement supportées par le projet Docker.io (il existe également des repos non officiels avec Fedora, RH, Arch...).
Petit mention spéciale pour les images BusyBox qui sont vraiment très légère (moins de 10 Mo) pour un système fonctionnel !
Même si il est possible de directement télécharger l'image au lancement du conteneur, je préfère avoir sur ma machine les images des différentes versions de l'OS que j'utilise le plus: Ubuntu.
Pour récupérer l'ensemble des images du repo Ubuntu qui contient les versio minimale d'Ubuntu de la version 10.04 à 14.04), il faut saisir la commande suivante:
$ sudo docker.io pull ubuntu
74fe38d11401: Pulling dependent layers
316b678ddf48: Pulling dependent layers
3db9c44f4520: Pulling dependent layers
5e019ab7bf6d: Pulling dependent layers
99ec81b80c55: Pulling dependent layers
a7cf8ae4e998: Pulling dependent layers
511136ea3c5a: Download complete
e2aa6665d371: Downloading [==> ] 2.027 MB/40.16 MB 6m14s
Note: le téléchargement initial des images peut prendre un peu de temps selon la vitesse de votre liaison Internet.
Il est également possible de faire de même avec les autres distributions citées ci-dessus:
$ sudo docker.io pull centos
$ sudo docker.io pull busybox
Une fois le téléchargement terminé, on peut demandé à Docker un status de son état actuel:
$ sudo docker.io info
Containers: 64
Images: 46
Storage Driver: aufs
Root Dir: /var/lib/docker/aufs
Dirs: 174
Execution Driver: native-0.1
Kernel Version: 3.13.0-24-generic
WARNING: No swap limit support
ainsi que la liste des images disponibles:
$ sudo docker.io images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
busybox buildroot-2013.08.1 352f47ad2ecf 17 hours ago 2.489 MB
busybox ubuntu-14.04 6a95c08a9391 17 hours ago 5.609 MB
busybox ubuntu-12.04 1720a1681f1c 17 hours ago 5.455 MB
busybox buildroot-2014.02 f66342b343ae 17 hours ago 2.433 MB
busybox latest f66342b343ae 17 hours ago 2.433 MB
ubuntu glances_develop a483f92d9ab3 24 hours ago 556.8 MB
ubuntu 14.04_nicolargo 8574cc29575e 28 hours ago 440.8 MB
ubuntu 13.10 5e019ab7bf6d 4 weeks ago 180 MB
ubuntu saucy 5e019ab7bf6d 4 weeks ago 180 MB
ubuntu 12.04 74fe38d11401 4 weeks ago 209.6 MB
ubuntu precise 74fe38d11401 4 weeks ago 209.6 MB
ubuntu 12.10 a7cf8ae4e998 4 weeks ago 171.3 MB
ubuntu quantal a7cf8ae4e998 4 weeks ago 171.3 MB
ubuntu 14.04 99ec81b80c55 4 weeks ago 266 MB
ubuntu latest 99ec81b80c55 4 weeks ago 266 MB
ubuntu trusty 99ec81b80c55 4 weeks ago 266 MB
ubuntu 13.04 316b678ddf48 4 weeks ago 169.4 MB
ubuntu raring 316b678ddf48 4 weeks ago 169.4 MB
ubuntu lucid 3db9c44f4520 5 weeks ago 183 MB
ubuntu 10.04 3db9c44f4520 5 weeks ago 183 MB
centos centos6 0b443ba03958 6 weeks ago 297.6 MB
centos 6.4 539c0211cd76 14 months ago 300.6 MB
centos latest 539c0211cd76 14 months ago 300.6 MB
Comme alternative du moteur de recherche https://index.docker.io/, il est bien sûr possible d'utiliser la ligne de commande. Par exemple pour trouver toutes les images Ubuntu disponibles sur le repo central:
sudo docker.io search ubuntu | less
A noter qu'il est tout à fait possible, si vous ne trouvez pas votre bonheur de concevoir "from scratch" votre propre image système en suivant cette documentation sur le site officiel (la procédure se base sur DebootStrap).
Création de son premier conteneur
Bon assez de préliminaires, nous allons maintenant pourvoir créer notre premier conteneur qui va se limiter à exécuter la commande 'ls' (si c'est pas du conteneur de compétition):
$ sudo docker.io run ubuntu:latest /bin/ls -alF
total 8280
drwxr-xr-x 46 root root 4096 May 28 06:50 ./
drwxr-xr-x 46 root root 4096 May 28 06:50 ../
-rw-r--r-- 1 root root 102 May 28 06:50 .dockerenv
-rwx------ 1 root root 8394118 May 27 15:37 .dockerinit*
drwxr-xr-x 2 root root 4096 Apr 16 20:36 bin/
drwxr-xr-x 2 root root 4096 Apr 10 22:12 boot/
drwxr-xr-x 4 root root 4096 May 28 06:50 dev/
drwxr-xr-x 64 root root 4096 May 28 06:50 etc/
drwxr-xr-x 2 root root 4096 Apr 10 22:12 home/
drwxr-xr-x 12 root root 4096 Apr 16 20:36 lib/
drwxr-xr-x 2 root root 4096 Apr 16 20:35 lib64/
drwxr-xr-x 2 root root 4096 Apr 16 20:35 media/
drwxr-xr-x 2 root root 4096 Apr 10 22:12 mnt/
drwxr-xr-x 2 root root 4096 Apr 16 20:35 opt/
dr-xr-xr-x 236 root root 0 May 28 06:50 proc/
drwx------ 2 root root 4096 Apr 16 20:36 root/
drwxr-xr-x 7 root root 4096 Apr 16 20:36 run/
drwxr-xr-x 2 root root 4096 Apr 24 16:17 sbin/
drwxr-xr-x 2 root root 4096 Apr 16 20:35 srv/
dr-xr-xr-x 13 root root 0 May 28 06:50 sys/
drwxrwxrwt 2 root root 4096 Apr 24 16:17 tmp/
drwxr-xr-x 11 root root 4096 Apr 16 20:35 usr/
drwxr-xr-x 14 root root 4096 Apr 16 20:36 var/
Arrêtons-nous un peu sur la commande: sudo docker.io run ubuntu:latest /bin/ls -alF
On demande donc le lancement (run) d'un conteneur basée sur la dernière version d'Ubuntu (ubuntu:latest qui est un lien vers l'image minimale de la version 14.04) qui va exécuter la commande ls (/bin/ls -alF). Comme vous pouvez le voir dans le résultat de la commande, on est dans un environnement isolé avec son propre système de fichier.
Première constatation, la vitesse d’exécution de notre environnement virtuel est vraiment impressionnante. Sur une petit commande,on peut voir que l'overhead de lancement du conteneur est négligeable:
$ time sudo docker.io run ubuntu:latest ls -alF /
...
real 0m0.331s
user 0m0.014s
sys 0m0.012s
$ time ls -alF /
...
real 0m0.007s
user 0m0.003s
sys 0m0.004s
Puis un conteneur persistant
Passons maintenant à la création d'un conteneur persistant, c'est à dire un conteneur qui va faire tourner une tache pendant un temps indéterminé (je prends par exemple un pin infini vers le site Google).
$ sudo docker.io run -d ubuntu:latest ping www.google.fr
7404bfa4beca4ba97459c96f8d93242c4fba6ecf2c5b11d18c09acd2fce9991e
Noter le -d dans la ligne de commande pour détacher le conteneur et ainsi lui permettre de tourner en tache de fond.
En retour on obtient le numéro d'identifiant unique du conteneur qui va nous permettre de le contrôler.
On commence donc par vérifier qu'il tourne bien:
$ sudo docker.io ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7404bfa4beca ubuntu:14.04 ping www.google.fr 3 minutes ago Up 3 minutes mad_lumiere
On peut ainsi, l'arrêter:
sudo docker.io stop 7404bfa4beca
Le démarrer:
sudo docker.io start 7404bfa4beca
Le redémarrer (l'équivalent d'un stop/start):
sudo docker.io restart 7404bfa4beca
Lui envoyer des signaux:
sudo docker.io kill 7404bfa4beca
Ensute on supprime le conteneur avec la séquence stop/rm:
sudo docker.io stop 7404bfa4beca
sudo docker.io rm 7404bfa4beca
Un Shell dans un conteneur
Pour accéder à un shell dans le conteneur, il faut utiliser les options suivantes dans la ligne de commande:
- -t: Allocate a pseudo-tty
- -i: Keep STDIN open even if not attached
$ sudo docker.io run -i -t ubuntu:latest bash
root@bb89ed6cdd3c:/#
Structurer la création des conteneurs avec les Dockerfiles
Les Dockerfiles sont des fichiers textes décrivant les différentes étapes pour la création d'un conteneur. Idéalement, ce sont ces fichiers que vous aller gérer en configuration et que vous aller partager avec les différentes personnes utilisatrices de votre projet. Pour illustrer mes dires, je vais prendre l'exemple d'un dockerfile qui va permettre aux contributeurs du projet Glances de tester simplement la branche de développement du logiciel.
En gros, le dockfile doit:
- utiliser un OS de base (Ubuntu 14.04 LTS)
- installer les pré-requis système
- télécharger la dernière version de Glances sous Github
Le dockfile glances_develop_install correspondant est alors le suivant:
# Install Glances Development branch
#
# $ sudo docker.io build -t ubuntu:glances_develop - < glances_develop_install
#
# VERSION 1.0
# Use the ubuntu base image provided by dotCloud
FROM ubuntu
MAINTAINER Nicolargo, nicolas@nicolargo.com
# Make sure the package repository is up to date
RUN apt-get -y update
# Install prerequirement
RUN apt-get install -y python-dev python-pip git lm-sensors
RUN pip install psutil bottle batinfo https://bitbucket.org/gleb_zhulik/py3sensors/get/tip.tar.gz
# Patch for current Docker version
RUN ln -s /proc/mounts /etc/mtab
# Install Glances from the Pipy repository
RUN git clone -b develop https://github.com/nicolargo/glances.git
Voyons un peu en détail le contenu du fichier. On commence donc par définir l'OS de base:
FROM ubuntu
On peut bien sûr utiliser l'image/tag que l'on souhaite.
Ensuite on passe aux commandes que l'on souhaite exécuter:
RUN apt-get -y update
RUN apt-get install -y python-dev python-pip git lm-sensors
RUN pip install psutil bottle batinfo https://bitbucket.org/gleb_zhulik/py3sensors/get/tip.tar.gz
RUN ln -s /proc/mounts /etc/mtab
RUN git clone -b develop https://github.com/nicolargo/glances.git
Rien de bien compliqué, il suffit de faire précéder la commande Unix par le mot clé RUN...
Il ne reste plus qu'à lancer la construction du conteneur et son exportation vers une nouvelle image (nommé ubuntu:glances_develop) à partir de la ligne de commande:
sudo docker.io build -t ubuntu:glances_develop - < glances_develop_install
ou alors directement depuis un repos (par exemple GitHub) ou vos Dockers files sont gérés en configuration:
sudo docker.io build -t ubuntu:glances_develop https://raw.githubusercontent.com/nicolargo/dockersfiles/master/glances_develop_install
On vérifie ensuite que l'image a bien été créée:
$ sudo docker.io images | grep glances
ubuntu glances_develop a483f92d9ab3 31 hours ago 556.8 MB
Puis on lance Glances depuis ce conteneur (en le metant à jour par un pull avant le lancement):
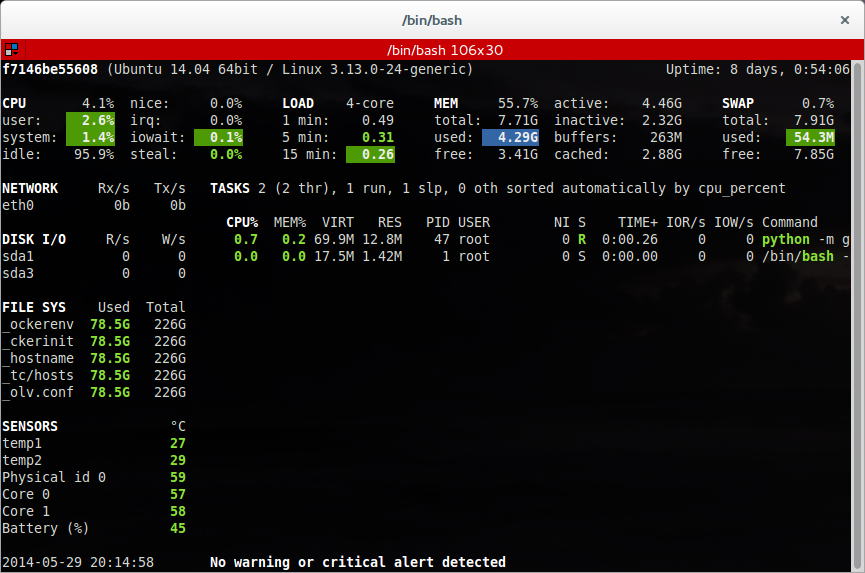
sudo docker.io run -i -t --entrypoint /bin/bash ubuntu:glances_develop -c "cd glances ; git pull origin develop ; python -m glances"
Et hop c'est magique:
Un des trucs fun avec Docker c'est que si l'on souhaite modifier un conteneur en ajoutant par exemple l'installation d'un nouveau logiciel, il suffit de modifier le Docker file puis de refaire la commande de build. L'installation ne se fera que par delta par rapport au premier conteneur.
Controler la CPU et la mémoire de ses conteneurs
Une fonction intéressante de Docker est sa capacité de contraindre un conteneur en terme de CPU et de MEM. Par exemple on peut limiter le conteneur à 512 Mo de RAM et donner un priorité moins forte en terme de CPU à ce conteneur par rapport aux autres. Il faut cependant que le hôte qu héberge Docker soit compatible avec ces options ce qui n'est pas mon cas:
$ sudo docker.io run -m 512m -i -t --entrypoint /bin/bash ubuntu:glances_develop -c "cd glances ; git pull origin develop ; python -m glances"
WARNING: Your kernel does not support swap limit capabilities. Limitation discarded.
Pour activer ces options sous Ubuntu, il faut modifier la configuration du Kernel via GRUB. Pour cela, il est nécessaire de suivre cette procédure.
Conclusion
L'approche est vraiment différente des solutions de virtualisation classiques mais si vous cherchez un outil simple pour valider vos applications Linux dans un environnement controlé alors Docker est définitivement une solution à envisager. Sa souplesse et sa légéreté en font une solution idéale à embarquer sur son PC portable ou à mettre en production sur son infrastructure.
Je vous conseille de vous plonger dans la documentation officielle qui est vraiment complète et très bien faite.
Des expériences à nous faire partager sur l'utilisation de Docker ?
Quelques références:
Cet article Virtualisation légère avec Docker est apparu en premier sur Le blog de NicoLargo.

Original post of Nicolargo.Votez pour ce billet sur Planet Libre.