Après avoir pas mal touché à Apache Lucene il y a quelques années ce ça ( je vous par le d'un temps que les moins de vingt ans ne peuvent pas connaître...), j'ai décidé de me pencher sur les moteurs de recherche opensource.
J'ai donc décidé de me pencher sur SOLR et ElasticSearch. Ces deux projets sont basés sur lucene.
Après avoir pas mal touché à Apache Lucene il y a quelques années ce ça ( je vous par le d'un temps que les moins de vingt ans ne peuvent pas connaître...), j'ai décidé de me pencher sur les moteurs de recherche opensource.
J'ai donc décidé de me pencher sur SOLR et ElasticSearch. Ces deux projets sont basés sur lucene.
Le cas d'utilisation que je souhaite mettre en œuvre est assez simple pour l'instant : indexer le résultat d'une requête faite dans un SGBD. Celle ci prend énormément de temps ( environ 30 secondes ) et je souhaite avoir un résultat immédiat le tout en REST.
Le cas elasticsearch
J'ai tout d'abord essayé elasticsearch. Ce dernier est le projet qui a le vent en poupe et présente de nombreux sous-projets très intéressants ( logstash, kibana). Le seul moyen d'extraire les données d'un SGBD est le jdbc-river. Ce moyen ne m'a pas trop séduit , il y a pas mal de problèmes liés à la saisie d'une requête complexe. Aussi j'en ai discuté brièvement avec David Pilato ( qui a fait une super présentation sur Kibana) lors du JugSummerCamp . Il m'a confirmé l'extension du scope du projet logstash aux autres sources de données (ex. JDBC). Cette mutation devrait être effective mi 2014. Bref, en attendant j'ai exploré SOLR.
Présentation de SOLR
SOLR est donc un moteur de recherche ( ça vous l'aviez deviné) qui s'appuie sur Apache Lucene ( ça aussi ...) . Il présente des fonctionnalités semblables à ElasticSearch. A ce que j'ai pu lire sur le net ici ou là, ce dernier est supérieur sur la gestion des recherches distribuées. Je n'aurais pas besoin de cette fonctionnalité dans un premier temps. Les fonctionnalités qui m'intéressent sont les suivantes :
- Les API JAVA et REST
- Le facets
- La mise en avant de certaines recherches
- Les requêtes geo spatiales
- La réplication des données
Configuration
Pour mon projet, je me suis basé sur un archetype maven disponible sur le net. Ce dernier crée un exemple de projet qui lance un jetty avec le war de solr
Vous devez également disposer de la distribution de SOLR pour que le livrable soit déployé. C'est la seule solution que j'ai trouvé pour l'instant. Ce n'est pas très élégant, car je préférerai avoir le tout embarqué dans la webapp.
Mon projet s'appelle customer-indexer . Il indexe les données d'une base de clients. Dans le répertoire src/main/resources, j'ai crée un répertoire customers. J'ai copié le contenu du répertoire collection1 présent dans les exemples de la distribution.
J'exposerai ici la configuration indispensable pour mon cas d'étude
le fichier solr.xml
version="1.0" encoding="UTF-8" ?>
persistent="true">
adminPath="/admin/cores" defaultCoreName="refper" host="${host:}" hostPort="${jetty.port:}" hostContext="${hostContext:}" zkClientTimeout="${zkClientTimeout:15000}">
name="customers" instanceDir="." />
>
>
Dans le répertoire src/main/resources/customers/conf, il faut ajouter a minima les fichiers solrconfig.xml schema.xml et data-config.xml.
solrconfig.xml
Les deux premiers sont déjà présents J'ai modifié le premier avec les informations suivantes :
j'ai mis le chemin en dur de la distribution et non le relatif
dir="c:/java/solr-4.5.0/contrib/extraction/lib" regex=".*\\.jar" />
dir="c:/java/solr-4.5.0/dist/" regex="solr-cell-\\d.*\\.jar" />
dir="c:/java/solr-4.5.0/contrib/clustering/lib/" regex=".*\\.jar" />
dir="c:/java/solr-4.5.0/dist/" regex="solr-clustering-\\d.*\\.jar" />
dir="c:/java/solr-4.5.0/dist/" regex="solr-dataimporthandler-\\d.*\\.jar" />
dir="c:/java/solr-4.5.0/contrib/langid/lib/" regex=".*\\.jar" />
dir="c:/java/solr-4.5.0/dist/" regex="solr-langid-\\d.*\\.jar" />
dir="c:/java/solr-4.5.0/contrib/velocity/lib" regex=".*\\.jar" />
dir="c:/java/solr-4.5.0/dist/" regex="solr-velocity-\\d.*\\.jar" />
La configuration de l'élément elevator semblait erronée
name="elevator" class="solr.QueryElevationComponent" >
name="queryFieldType">string>
name="config-file">elevate.xml>
>
J'ai rajouté également le module d'import des données
name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
name="defaults">
name="config">data-config.xml>
>
>
schema.xml
Ce fichier décrit la structure des documents présents dans l'index du moteur de recherche. On définit les données à indexer, les types de données et les filtres à appliquer (exemple: tout passer en minuscule)
name="customers" version="1.5">
>
name="idpp" type="string" indexed="true" stored="true" required="true" multiValued="false"/>
name="_root_" type="string" indexed="true" stored="false"/>
name="dtcrea" type="date" indexed="true" stored="true" omitNorms="true"/>
name="dtlastupd" type="date" indexed="true" stored="true"/>
name="title" type="lowercase" indexed="true" stored="true" omitNorms="true"/>
name="lastname" type="lowercase" indexed="true" stored="true" multiValued="true"/>
name="fstname" type="lowercase" indexed="true" stored="true" multiValued="true"/>
name="dtbirth" type="date" indexed="true" stored="true" termVectors="true" termPositions="true"
termOffsets="true"/>
name="status" type="float" indexed="true" stored="true"/>
name="content" type="text_general" indexed="false" stored="true" multiValued="true"/>
name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>
name="text_rev" type="text_general_rev" indexed="true" stored="false" multiValued="true"/>
name="_version_" type="long" indexed="true" stored="true"/>
>
>idpp>
source="title" dest="text"/>
source="lastname" dest="text"/>
source="firstname" dest="text"/>
source="birthday" dest="text"/>
>
data-config.xml
Dans ce fichier on spécifie les données récupérées de la base de données
>
driver="oracle.jdbc.OracleDriver" url="urljdbc" user="user" password="pwd"/>
name="customer">
name="customer" query="Marequete">
column="id" name="id" />
column="LASTNAME" name="lastname" />
column="FIRSTNAME" name="firstname" />
column="DTCREATION" name="dtcreation" />
column="DTLASTUPDATE" name="dtlastupdate" />
column="BIRTHDAY" name="birthday" />
column="STATUS" name="status" />
>
>
>
Configuration maven
voici le contenu du pom.xml
version="1.0" encoding="UTF-8"?>
xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
>4.0.0>
>customer-indexer>
>1.0-SNAPSHOT>
>1.7.5>
>1.2.17>
>4.5.0>
>customers>
>customers>
>c:/java/solr-4.5.0/>
>
>
>
>org.slf4j>
>${slf4j-api.version}>
>
>
>org.slf4j>
>${slf4j-api.version}>
>
>
>org.slf4j>
>${slf4j-api.version}>
>
>
>org.slf4j>
>${slf4j-api.version}>
>
>
>log4j>
>${log4j.version}>
>
>
>com.oracle.ojdbc>
>10.2.0.2.0>
>
>
>org.apache.solr>
>${solr.version}>
>war>
>
>
>
>customers>
>
>
>true>
>src/main/resources>
>
>
>1.7>
>
>
>copy-to-solr>
>
>run>
>
>
>
todir="${solr.solr.home}" includeemptydirs="true" overwrite="true">
dir="${project.build.outputDirectory}">
>
>
>
>
>
>
>
>org.eclipse.jetty>
>9.0.4.v20130625>
>
>9966>
>stop>
>
>/refper>
>
>
>
>
>
>
Démarrage
Dans mon cas il me suffit de lancer la commande
mvn clean install jetty:run
Import des données
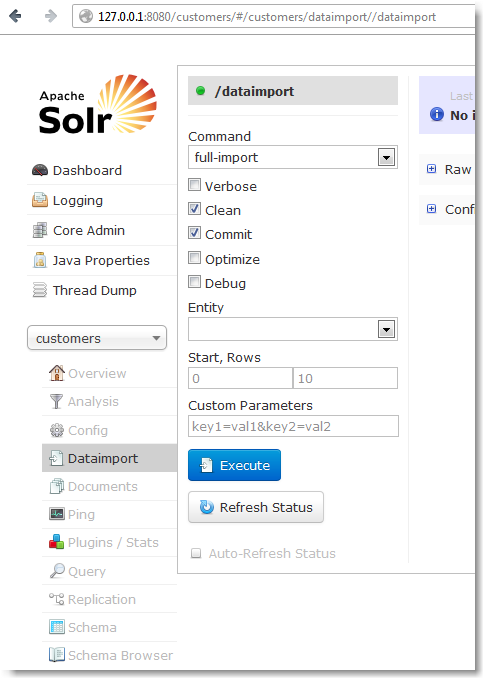
On peut le faire soit par un appel REST, soit par la console :
Sélectionner la collection puis cliquer sur Data Import
Conclusion
Pour l'instant j'ai rapidement fait une première indexation de mes données. je suis conscient qu'il y a pas mal d'améliorations à apporter, notamment sur la modélisation de mon index avec les bonnes entités (ex. une entité customer, une entité address,...)
Je verrai le requêtage dans un autre post.

Original post of Littlewing.Votez pour ce billet sur Planet Libre.