Je partage complétement ce qui est expliqué dans cette article. Naviguer sur des
pages web, c'est passer plus de temps à arrêter des vidéos en lecture automatique
ou fermer des pop-in que de lire son contenu…
Tout le monde est maintenant conscient de l’importance de délivrer ou utiliser un service web fortement sécurisé. Il est indispensable de protéger les données stockées dans les bases de données, valeurs inestimables, et assurer la confidentialité des échanges.
L’utilisation d’un framework comme Django permet de partir sur des bonnes bases. Mais nous allons voir qu’il est nécessaire de paramétrer finalement celui-ci.
Comment sécuriser Django ?
Je vais me servir d’un exemple concret, l’application PyFreeBilling dont je suis le créateur. PyFreeBilling est une application complète de VoIP (fonctionnalités de class 4 pour les connaisseurs) permettant à un opérateur télécom ou à une entreprise de services de connecter des clients et des fournisseurs, de router les appels, d’appliquer un tarif selon le type d’appel ainsi que l’ensemble des tâches nécessaires à cette activité.
L’exemple est intéressant du point de vue de la criticité de l’application. Une solution de communications de VoIP doit-être fortement sécurisée. Les risques de fraudes, de divulgation d’informations ou de perte de services sont importants. Un serveur à peine déployée subit ses premières attaques au bout de quelques minutes ceci étant aidé par des frameworks permettant d’automatiser les attaques.
L’interface de gestion de PyFreeBilling est développée avec le framework Django.
Pourquoi sécuriser Django ?
La sécurisation de l’interface d’administration est essentielle. Elle permet de gérer a création et la suppression de comptes SIP, la modification de mots de passe, l’augmentation des limites comme le nombre d’appels simultanés ou le volume d’appels journaliers. Un système d’anti-fraude peut ainsi être facilement détourné, un compte utilisateur pirate créé et des routes créées. Un assaillant peut aussi récupérer les données des accès opérateurs ou la base clients.
Les risques
Je vais maintenant présenter les types d’attaque les plus courantes et puis montrer comment avec Django mettre en oeuvre des solutions afin de limiter le risque.
L’OWASP est une communauté spécialisée dans la sécurité des applications web. Ils proposent notamment des outils afin de tester la sécurité des applications web. Un projet va particulièrement nous intéresser : OWASP Application Security Verification Standard (ASVS) . Je vous engage notamment à lire les cheatsheets mises à disposition.
Voici le top ten des risques définis par l’OWASP (les liens conduisent à la page détaillant chaque item) :
Maintenant que nous avons identifié les risques et nous avons une base documentaire solide sur laquelle nous appuyer, nous allons voir les contre-mesures pour sécuriser Django.
Les injections
Tout d’abord, nous allons voir les injections SQL. Django fournit un ORM qui permet de se protéger de ce risque en échappant les variables avant de soumettre la requête à la base de données. A la condition, de ne pas utiliser la fonction RawSQL permettant d’utiliser du code SQL natif. Dans ce cas, c’est au développeur de valider les variables utilisées dans la requête !
Attention : l’ORM ne dispense pas de valider les variables, c’est une bonne pratique !
L’authentification
Nous allons retrouver plusieurs sous parties.
Tout d’abord, nous allons voir comment se protéger des attaques par brute force.
Pour se protéger des attaques que subissent constamment les pages de login, les attaques par brute force, j’utilise le package django-axes . Il permet de bloquer une adresse IP après un nombre prédéfini de tentatives infructueuses. La configuration par défaut est très satisfaisante, mais je vous invite à lire la documentation de django-axes afin de tuner votre configuration selon vos souhaits, notamment si vous avez besoin de whitelister quelques adresses IP.
Toutes les tentatives sont accessibles via l’interface d’administration incluant les adresses IP, les navigateurs, les noms d’utilisateurs utilisés …
En complément, un honeypot est intégré afin de détecter les robots malveillants testant la page /admin, page identique à la vraie page de connexion ! Toute tentative est ainsi bloquée en amont. Pour cela, j’utilise le package django-admin-honeypot.
Le second point, concerne la robustesse des mots de passe. Très souvent les utilisateurs utilisent des mots de passe trop simples. Afin, de renforcer la complexité des mots de passe, Django intègre des validateurs de mots de passe, dont voici un exemple de configuration :
Nous allons tout d’abord vérifier que le mot de passe n’est pas trop similaire avec un attribut de l’utilisateur, puis que la longueur minimum est de 9 (je suggère d’augmenter cette valeur), ensuite nous allons vérifier s’il ne fait pas partie d’une liste de mots de passe couramment utilisés et que le mot de passe n’est pas entièrement composé de chiffres. Par ailleurs, il est aussi possible d’intégrer son propre validateur en plus de ceux prédéfinis par Django.
Le stockage du mot de passe en base de données doit aussi être particulièrement surveillé.
Django ne stocke heureusement pas les mots de passe en clair dans la base de données, mais un hash de celui-ci. Nous avons la flexibilité d’utiliser les méthodes de hachage de notre choix, mais dans une liste réputée sécurisée. Par défaut, c’est l’algorithme PBKDF2 avec un hash SHA265.
PyFreeBilling utilise l’algorithme Argon2 étant réputé plus sécurisé.
Il est possible et souhaitable d’activer une double authentification (two-factor authentication). Dans PyFreeBilling, cette fonctionnalité est optionnelle, car selon le type de déploiement, la mise en oeuvre sera plus ou moins complexe. Mais je recommande très fortement la prise en considération de cette fonctionnalité qui va renforcer sensiblement l’application. Pour cela, l’application django que je recommande est django-two-factor-auth qui intègre de nombreux services. Je ne vais pas détailler ici la mise en oeuvre, un article entier serait nécessaire. Je vous encourage à lire la documentation qui est bien faite.
Exposition de données sensibles
Il est essentiel de s’assurer qu’aucune donnée sensible ne puisse être interceptée.
Tout d’abord la mise en oeuvre du protocole HTTPS afin de garder confidentielles les données échangées est indispensable.
Par défaut, Django autorise les échanges via le protocole HTTP, mais pour des raisons évidentes, l’accès à l’interface d’administration de PyFreeBilling est forcée en HTTPS.
Pour cela nous allons forcer le navigateur l’utilisation du protocole HTTPS en activant l’entête HTTP Strict Transport Security ou HSTS.
Django définit cet en-tête pour vous sur toutes les réponses HTTPS si vous définissez le réglage SECURE_HSTS_SECONDS à une valeur entière différente de zéro.
Définissez aussi le paramètre SECURE_SSL_REDIRECT sur True, ainsi toutes les demandes non SSL seront redirigées de manière permanente vers SSL.
Ensuite, nous allons intégrer des entêtes HTTP afin d’activer des paramètres de sécurité embarqués dans les navigateurs modernes (et oui, il faudrait bloquer les vieux navigateurs troués comme de vieux torchons).
Anti-click jacking :
Le principe est d’interdire l’affichage d’une page de notre interface d’administration dans une frame. Django possède nativement les protections, mais qu’il faut activer correctement via les variables suivantes :
Tout d’abord il faut activer le middleware « django.middleware.clickjacking.XFrameOptionsMiddleware » afin d’ajouter l’entête X-FRAME-OPTIONS à toutes les réponses.
Par défaut, la valeur de l’entête X-Frame-Options est à SAMEORIGIN, mais il est possible de forcer à DENY ce qui est fait pour l’administration de PyFreeBilling. Ainsi, on interdit au navigateur d’intégrer nos pages dans une iFrame.
Les entêtes Content Security Policy ou CSP permet de contrôler la manière dont les ressources sont inclues dans la page.
Afin de gérer ces entêtes, le package django-csp est utilisé (https://github.com/mozilla/django-csp). Il permet de paramétrer très finement nos ressources.
Tout d’abord nos devons activer le middleware « csp.middleware.CSPMiddleware » et ensuite définir les valeurs souhaitées pour les paramètres.
Le choix fait pour PyFreeBilling est de n’utiliser aucune ressources externes pour des raisons de sécurité, mais aussi afin de pouvoir fonctionner sans accès internet (c’est le cas de certains clients). Le paramétrage des entêtes CSP est ainsi simplifié. Pour comprendre en détail les différentes valeurs, je vous engage à lire les spécifications CSP puis la documentation de django-csp.
Protection XSS :
Définissez le paramètre SECURE_BROWSER_XSS_FILTER sur True afin d’activer les protections de filtrage XSS du navigateur.
Entête X-Content-Type-Options :
Enfin, il est avisé d’empêcher le navigateur de déterminer le type de fichier en ajoutant un entête X-Content-Type-Options. Pour cela Django dispose d’une variable (à False par défaut) qu’il faut passer à True : SECURE_CONTENT_TYPE_NOSNIFF (https://docs.djangoproject.com/en/2.1/ref/settings/#secure-content-type-nosniff)
XML entités externes
Je ne vais pas traiter de cette partie, n’utilisant pas ce type de fonctions dans PyFreeBilling. Si vous souhaitez l’utiliser, vous devez soit écrire le code ou utiliser une librairie. Je vous invite à lire la documentation associée et utiliser les éléments de filtrage proposés nativement par Django.
Vous pouvez apporter des éléments en commentaire du présent article pour les futurs lecteurs (je compléterais à l’occasion cette partie)
Broken accès control
Django propose de base une gestion des utilisateurs et des groupes d’utilisateurs. Des décorateurs permettent de définir l’accès à une ressource donnée avec des droits différents : lecture, modification, création … .
Il est aussi possible de définir plus finement l’accès. Un package très utilisé est django-braces.
D’autres plugins permettent de gérer plus finement par objet ou par certains attributs. Dans tous les cas, c’est de la responsabilité du développeur d’utiliser correctement ces outils et de tester les accès suivant les différents typologies d’utilisateurs.
Mauvaises configuration de sécurité
C’est l’objet de l’article de pointer sur les points d’attention lors du paramétrage d’un projet Django. Il existe des outils afin de valider que rien n’a été oublié.
Je vous en propose 2 :
FreesScan de Qualys qui va permettre de tester en profondeur votre site avec un rapport précis. Il va tester les certificats et la configuration du serveur web. Voici la note obtenue par un déploiement de PyFreeBilling de base sous docker :
Tous les éléments ne sont pas testés, mais ça permet de valider rapidement notre déploiement.
Et l’Observatory, outil de Mozilla permettant de vérifier de nombreux points de sécurité : il valide la sécurité des en-têtes OWASP, les meilleures pratiques TLS et effectue des tests tiers à partir de SSL Labs, High-Tech Bridge, des en-têtes de sécurité, du préchargement HSTS, etc. Il est particulièrement complet et aussi très instructif.
Cross-Site Scripting (XSS)
C’est une des failles visant le navigateur des utilisateurs. Nous allons voir comment des paramètres Django vont pouvoir nous prémunir contre elles, sachant que les outils automatisées savent les détecter et les exploiter !
Nous avons déjà vu dans la section « exposition de données sensibles » en ajoutant des entêtes HTTP en ajoutant des paramètres nous protégeant de failles XSS. Nous allons voir comment nous protéger du vol de sessions.
Il s’agit de bloquer l’accès à un code javascript exécuté dans le navigateur par un assaillant au cookie de session . Pour cela, nous allons forcer l’envoi de l’entête httpOnly transmise avec le cookie.
Explication de la team django : ‘It’s recommended to leave the SESSION_COOKIE_HTTPONLY setting on True to prevent access to the stored data from JavaScript.’
Afin de renforcer la sécurité des cookies, nous allons modifier 2 paramètres :
Enfin, nous allons forcer l’échange de cookies uniquement via une connexion HTTPS : la configuration par défaut est à False. Pour forcer l’échange via HTTPS, il faut mettre SESSION_COOKIE_SECURE à True.
Je vais faire la même remarque que pour le traitement de document XML.
Utiliser des composants incluant des vulnérabilités connues
Django étant un framework python, vous avez plusieurs outils vous permettant d’être notifié quand une dépendance est mise à jour. Mais surtout, certains outils peuvent envoyer une notification quand une dépendance utilisée contient une faille de sécurité. J’utilise PyUp pour cela. Ils annoncent surveiller 173 000 dépendances python !
Si votre projet utilise aussi du code qui n’est pas écrit en python, ce qui est souvent le cas comme du javascript, d’autres outils existent. Pour ce javascript, npmjs ou Retire.js pourront vous être très utiles. Retire.js propose même des extensions pour Chrome et Firefox !
OWASP dispose aussi d’un outil pouvant être intégré dans votre Jenkins préféré appelé OWASP Dependency Check. Il supporte actuellement les langages Java, .NET, Ruby, Node.js, Python et partiellement C++.
Nous avons vu au cours de cette article que la sécurisation d’une application web est une tâche complexe nécessitant de bien connaître les risques. Un framework puissant comme Django, à condition de bien le maîtriser, nous facilite la tâche.
Et pour finir, je vais vous partager un dernier truc afin d’améliorer la sécurité de notre projet Django : restreindre l’accès à toutes ou certaines URL à une ou plusieurs adresses IP.
Pour cela, le package django-iprestrict est l’outil adéquate. Afin de bloquer/autoriser l’accès à partir de région ou pays, geoip2 sera utilisé. Tout d’abord, il faut activer le middleware « iprestrict.middleware.IPRestrictMiddleware ». Le paramétrage se fait ensuite dans l’interface d’administration.
Et surtout pour sortir sécuriser Django correctement, sinon tous vos efforts auront été vains, assurez-vous d’utiliser un SECRET_KEY long, aléatoire et unique !
Si vous avez des remarques ou des packages intéressants à partager afin d’améliorer la sécurité d’un projet Django, les commentaires sont à votre disposition.
J'ai eu le message suivant qui est apparu sur mon Ubuntu 18.04
Je me suis donc posé la question de ce à quoi il correspondait et j'ai rapidement trouvé la réponse en ligne.
Livepatch allows you to install some critical kernel security updates without rebooting your system, by directly patching the running kernel. It does not affect regular (not security-critical) kernel updates, you still have to install those the regular way and reboot. It does not affect updates to other non-kernel packages either, which don't require a reboot anyway. On a regular home or office computer, which does get rebooted daily (or every few days to weeks at least, your mileage may vary), Livepatch probably doesn't give you many benefits. It's mainly intended for servers which are supposed to have months and years of continuous uptime without reboots.Ask Ubuntu.com - Do I need to use canonical Livepatch ?
Ce que l'on peut traduire par :
Livepatch vous permet d'installer certaines mises à jour de sécurité du noyau critiques sans redémarrer le système, en appliquant directement un correctif au noyau en cours d'exécution. Cela n'affecte pas les mises à jour régulières du noyau (non critiques pour la sécurité), que vous devrez toujours installer de la manière habituelle et nécessitant un redémarrage. Cela n'affecte pas non plus les mises à jour des autres packages (non-noyau), qui ne nécessitent de toute façon pas de redémarrage. Livepatch ne vous apportera probablement pas beaucoup d'avantages sur un ordinateur ordinaire à la maison ou au bureau qui est redémarré tous les jours. Il est principalement destiné aux serveurs censés avoir des mois et des années de disponibilité continue sans redémarrage.
Livepatch est donc essentiellement utile sur les serveurs tournant sous Ubuntu pour lesquels un redémarrage complet du système est critique et ne peut pas de faire du tout ou seulement à des moments bien définis. Pour en savoir plus, il y a la page officielle https://www.ubuntu.com/livepatch
Pour ce qui concerne la nécessité de redémarrer les autres services et applications pour la prise en compte des mises à jour et patchs de sécurité, je rappelle l'existence de checkrestart que j'évoquais dans mon billet Astuces Debian ou encore needrestart qui est une surcouche à Checkrestart.
En tant que membre de l’équipe Image du laboratoire GREYC (CRNS, ENSICAEN, Université de Caen), j’ai implémenté un algorithme de “remplissage de dessin au trait” dans GIMP, aussi appelé “colorisation intelligente“. Vous avez peut-être entendu parler du même algorithme dans G’Mic (développé par la même équipe), donc quand on m’a proposé l’emploi, cet algorithme m’a rapidement intéressé. Ce devint ma première mission!
Le problème
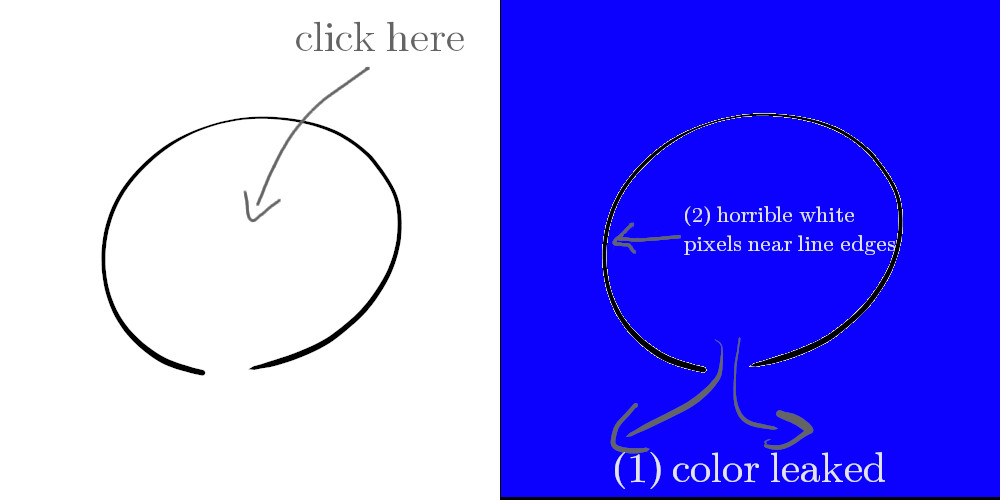
Conceptuellement le remplissage de dessin au trait est simple: vous dessinez une forme au stylo noir, disons un cercle approximé, et vous souhaitez le remplir d’une couleur de votre choix. Vous pouviez déjà le faire, plus ou moins, avec l’outil de remplissage, en remplissant les couleurs similaires… à 2 problèmes près:
Si le trait n’est pas bien fermé (il y a des “trous”), la couleur fuite. Les trous peuvent être le fait d’erreur de dessin, cependant on ne les trouve pas forcément aisément (cela peut être un trou d’un pixel au pire des cas), et perdre du temps à les trouver n’est pas très marrant. En outre, cela peut être un choix conscient voire artistique.
Le remplissage laisse en général des pixels non coloriés proche des bordures du traits, à cause de l’interpolation, l’anti-aliasing ou pour d’autres raisons (à moins de ne dessiner qu’avec des pixels pleins, style “pixel art”), ce qui n’est pas un résultat acceptable.
2 principaux problèmes du remplissage des couleurs similaires
En conséquence, probablement aucun coloriste numérique n’utilise l’outil de remplissage directement. Diverses autres méthodes nécessitent par exemple l’outil de sélection contiguë (ou d’autres outils de sélection), l’agrandissement ou réduction de la sélection, puis seulement à la fin le remplissage. Parfois peindre directement avec une brosse est la méthode la plus adaptée. Assister à un atelier d’Aryeom sur le sujet de la colorisation est d’ailleurs absolument fascinant. Elle peut enseigner une dizaine de méthodes différentes utilisées par les coloristes. Elle-même n’utilise pas toujours la même procédure (cela dépend de la situation). Pour le project ZeMarmot, j’ai aussi écrit des scripts Python d’aide à la colorisation, qu’Aryeom utilise maintenant depuis des années, et qui fait un boulot très raisonnable d’accélération de cette tâche ingrate (mais la tâche reste ingrate malgré tout).
Pour nos besoins, je me suis intéressé à ces deux étapes de l’algorithme:
La fermeture des traits, par la caractérisation de “points d’intérêt”, lesquels sont les bords de traits avec courbures extrêmes (on peut alors estimer que ce sont probablement des extrémités de lignes), puis en joignant ces points d’intérêts en définissant des facteurs de qualités à base des angles de normales, ou de distance maximum. Les lignes peuvent être fermées avec soit des splines (c’est à dire des courbes) soit des segments droits.
La colorisation proprement dite, en “mangeant” un peu sous les pixels de traits, ainsi de s’assurer de l’absence de pixels non-coloriés près des bords.
Comme on peut le voir, l’algorithme prend donc en compte les 2 problématiques (que j’ai numérotées dans le même ordre, comme par hasard )! Néanmoins je n’ai implémenté que la première étape de l’algorithme et ai adapté la seconde avec une solution propre (quoique basée sur des concepts similaires) à cause de problématiques d’utilisabilité.
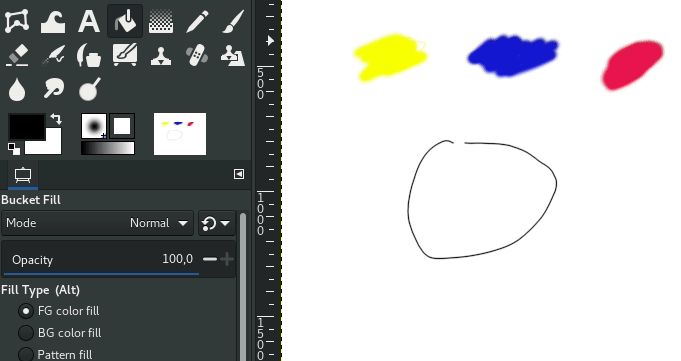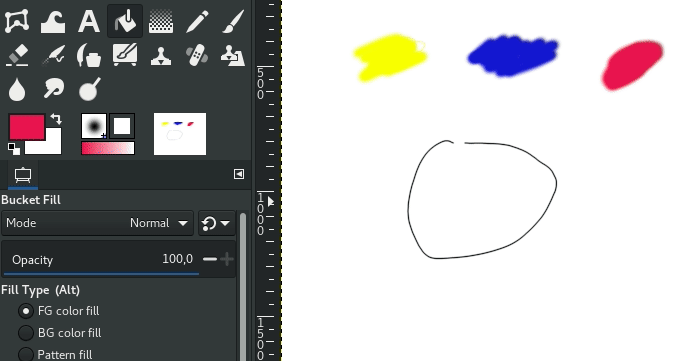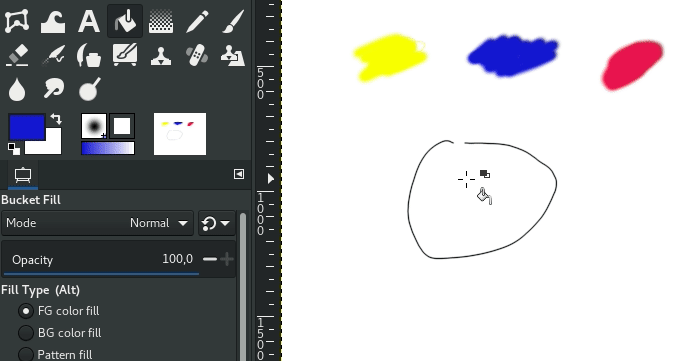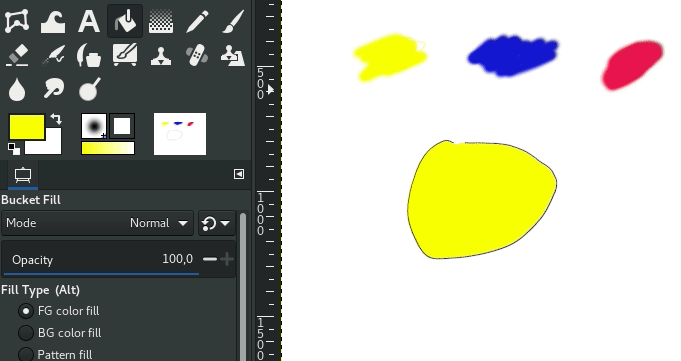
Et voici donc le remplissage par détection de traits dans GIMP:
Remplissage par détection de trait
Je ne vais pas réexpliquer l’algorithme en détail. Si c’est ce qui vous intéresse, je suggère plutôt de lire le papier de recherche (10 pages), lequel est très clair, et a même des images très explicites. Si vous préférez lire du code, comme moi, plutôt que des équations, vous pouvez aussi regarder directement l’implémentation dans GIMP, principalement contenue dans le fichier gimplineart.c, en commençant en particulier avec la fonction gimp_line_art_close().
Ci-dessous, je vais plutôt me focaliser sur les améliorations que j’ai faites à l’algorithme, et que vous ne trouverez pas dans les papiers de recherche. Je rappelle aussi que nous avons travaillé avec l’animatrice/peintre Aryeom Han (réalisatrice de ZeMarmot) comme artiste-conseil, pour rendre l’implémentation utile pour de vrai, non juste théoriquement.
Note: cet article se concentre sur l’aspect technique de la fonctionnalité. Si vous souhaitez seulement savoir comment l’utiliser, je conseille d’attendre quelques jours ou semaines. Nous ferons une courte (néanmoins aussi exhaustive que possible) vidéo pour montrer comment l’utiliser ainsi que le sens de chaque option.
Étape 1: fermeture des traits
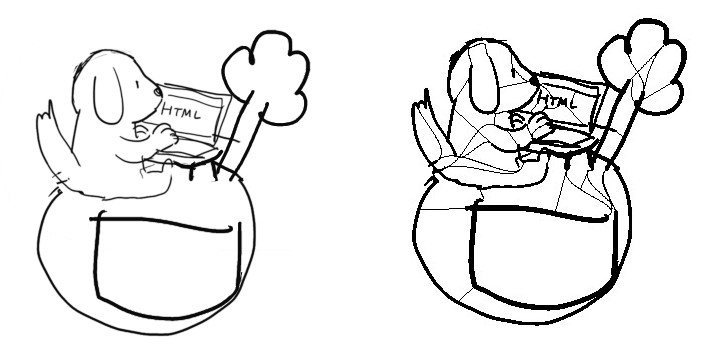
Pour donner un aperçu rapide de la logique algorithmique, voici un exemple simple à partir d’une ébauche de dessin par Aryeom (bon exemple puisqu’une telle esquisse est pleines de “trous”!). À gauche, vous pouvez voir l’esquisse, au milieu comment elle est traitée par l’algorithme (cette version de l’image n’est jamais visible par le peintre), et à droite mon essai de colorisation en aplats (avec l’outil de remplissage seulement, pas de brosse, rien!) en moins d’une minute (chronométrée)!
De lignes à colorisation, avec représentation interne au centre
Note: bien sûr, il ne faut pas voir cela comme un exemple de “travail final”. Le travail de colorisation est en général en plusieurs étapes, la première consistant en l’application d’aplats de couleur. Cet outil ne participe qu’à cette première étape et l’image peut nécessiter du travail supplémentaire (d’autant plus avec cet exemple qui se base sur une esquisse).
Estimer une épaisseur de trait globale locale (algo amélioré)
Un aspect de l’algorithme est rapidement apparu comme suboptimal. Comme dit plus haut, nous détectons les points clés grâce à la courbure des lignes. Cela pose problème avec les très grosses brosses (soit parce que vous peignez dans un style “lignes épaisses” ou bien juste parce que vous peignez en très haute résolution, donc avec des lignes “fines de dizaines de pixels”, etc.). L’extrémité de telles lignes peut alors présenter une courbure basse et donc ne pas être détectées. Dans le papier originel, la solution proposée au problème est:
Afin de rendre la méthode de fermeture indépendante de la résolution de l’image, une étape préliminaire permet de réduire si besoin l’épaisseur des tracés à quelques pixels, en utilisant une érosion morphologique. Le rayon utilisé pour cette érosion est déterminé automatiquement par estimation de la largeur des traits présents dans le dessin.
Section ‘2.1. Pré-traitement de l’image anti-aliasée’
Malheureusement calculer une estimation de largeur de traits unique pour un dessin entier présente des limites, puisque cela part du principe que le trait a une épaisseur constante. Demandez donc à un calligraphe ce qu’il en pense pour rigoler!
En outre bien que cela fonctionnait globalement, des effets secondaires pouvaient apparaître. Par exemple des trous inexistants au préalable pouvaient apparaître (en érodant une ligne plus fine que la moyenne). Le papier était conscient de ce problème mais l’écartait en supposant que ce trou serait de toutes façons refermé dans l’étape de fermeture qui suivait nécessairement:
Il est à noter que d’éventuelles déconnexions provoquées par l’érosion appliquée, qui restent rares, seront de toute façon compensées par l’étape suivante de fermeture des traits.
Section ‘2.1. Pré-traitement de l’image anti-aliasée’
Pourtant dès les tests initiaux qu’Aryeom a effectuées avec la première version implémentée de l’outil, elle a rencontré des cas similaires. Une fois même, nous avions une zone parfaitement fermée à la base qui laissait fuiter la couleur, une fois l’algorithme appliqué ⇒ nous obtenions donc l’effet inverse du but de l’algoritme! Paradoxal! Pire, alors que trouver des micros trous dans des traits pour les combler est compliqué, trouver des micros trous invisibles (car existants seulement dans une représentation interne du dessin) tient de la gageure.
Pour couronner le tout, cette érosion ne semblait même pas vraiment bien accomplir son but, puisqu’on arrivait aisément à créer des dessins avec de grosses brosses où aucun point clé n’était détecté malgré l’étape d’érosion. Au final donc, cette étape d’estimation d’épaisseur de trait globale+érosion apportait plus de problèmes qu’elle n’en réglait.
Conclusion: pas glop!
Après de longues discussions avec David Tschumperlé et Sébastien Fourey, nous en sommes arrivés à une évolution de l’algorithme, en calculant des épaisseurs de ligne locales pour chaque pixel de trait (plutôt qu’une unique épaisseur de trait pour le dessin entier), simplement basé sur une fonction distance du dessin. Nous pouvons alors décider si une courbure est symptomatique d’un point clé relativement à l’épaisseur locale (plutôt qu’un test absolu sur un dessin érodé par une épaisseur moyenne).
Non seulement cela fonctionnait mieux, cela ne créait pas de nouveaux trous invisibles dans des zones fermées, détectait des points clés sur de très gros traits en supposant la variabilité des traits (que ce soit un choix stylistique ou parce que la perfection n’est pas de ce monde!), mais en plus c’était même plus rapide!
En exemple, la version originelle de l’algorithme n’aurait pas réussi à détecter les points d’intérêt pour fermer cette zone avec de si gros traits. Le nouvel algorithme n’a aucun problème:
La fermeture de traits est clairement l’étape la plus longue du traitement. Bien que cela reste raisonnable sur des images FullHD voire même 4K, sur mon ordinateur, cela pouvait tout de même prendre une demi-seconde de traitement. Pour un outil intéractif, une demi seconde, c’est un siècle! Sans compter si on se met à traiter des images énormes (pas impossible de nos jours), cela peut alors prendre plusieurs secondes.
J’effectue donc ce calcul en parallèle afin qu’il soit exécuté au plus tôt (dès que l’outil de remplissage est sélectionné). Puisque les gens ne sont pas des robots, cela rend l’intéraction bien plus rapide en apparence, voire dans de nombreux cas, on peut ne même pas se rendre compte qu’il y a eu temps de traitement.
Available line art “Source” in the tool options
Partiellement pour la même raison, vous pourrez remarquer une option “Source” qui propose plus qu’à l’habitude dans d’autres outils (“Échantilloner sur tous les calques” ou sur le calque actif uniquement). Pour cet outil, vous pouvez aussi choisir le calque au dessus ou dessous du calque actif. C’est le résultat à la fois d’une décision logique (la couleur appliquée n’est pas du trait par définition) et pour des raisons de performance (il n’est pas nécessaire de recalculer la fermeture à chaque ajout de couleur).
Étape 2: remplissage
Rendre l’algorithme interactif et résistant aux erreurs
Le papier propose de remplir toutes les zones d’un coup à l’aide d’un algorithme de watershed.
J’ai fait le choix de ne pas honorer cette étape de l’algorithme, principalement pour raison d’utilisabilité. Lorsque j’ai vu les images de démonstration de cet algorithme sur G’Mic pour la première fois, le résultat semblait très prometteur; puis j’ai vu l’interface graphique, et cela semblait peu utilisable. Mais comme je ne suis pas le peintre de l’équipe, je l’ai montré à Aryeom. Ses premiers mots après la démo furent en substance: “je n’utiliserai pas“. Notez bien qu’on ne parle pas du résultat final (qui n’est pas mal du tout), mais bien de l’intéraction humain-machine. La colorisation est fastidieuse, mais si la colorisation intelligente l’est encore plus, pourquoi utiliser?
Qu’est-ce qui est donc fastidieux? G’Mic propose plusieurs variantes pour colorier une image: vous pouvez par exemple laisser l’algorithme colorier aléatoirement les zones, ce qui permet ensuite de sélectionner chaque aplat indépendamment pour recolorisation; vous pouvez aussi guider l’algorithme avec des touches de couleurs, en espérant qu’il fonctionnera suffisamment bien pour inonder les bonnes zones avec les bonnes couleurs. Je propose aussi de regarder cet article sympa de David Revoy, qui avait contribué à la version de base de l’algorithme.
La colorisation intelligente dans G’Mic est un peu complexe…
Ce sont des méthodes intéressantes et très sûrement utilisables, voire efficaces, dans certains cas, mais ce n’est pas une méthode générique que vous voudrez utiliser dans tous les cas.
Déjà cela implique beaucoup d’étapes pour colorier un seul dessin. Pour l’animation (par exemple le projet ZeMarmot), c’est encore pire, car nous devons coloriser des dizaines ou centaines de calques. En outre, cela implique que l’algorithme ne peut se tromper. Or nous savons bien qu’une telle hypothèse est absurde! Des résultats non voulus peuvent se produire, ce qui n’est pas obligatoirement un problème! Ce qu’on demande à un tel algorithme est de fonctionner la plupart du temps, du moment que l’on peut toujours revenir à des méthodes plus traditionnelles pour les rares cas où cela ne fonctionne pas. Si vous devez défaire la colorisation globale (car faite en étape unique), puis essayer de comprendre l’algorithme pour refaire vos touches de couleurs en espérant que la prochaine fois, cela marche mieux afin d’essayer encore, un peu à l’aveuglette, alors l’utilisation d’un algorithme “intelligent” ne peut être que perte de temps.
À la place, nous avions besoin d’un procédé de colorisation intéractif et progressif, de sorte que les erreurs de l’algorithme puissent être simplement contournées en revenant temporairement à des techniques traditionnelles (juste pour quelques zones). C’est pourquoi j’ai basé l’intéraction sur l’outil de remplissage qui existait déjà, de sorte que la colorisation (par détection de traits) fonctionne comme cela a toujours fonctionné: on clique et on voit la zone cliquée être remplie devant ses yeux… une zone à la fois!
C’est simple et surtout résistant aux erreur. En effet si l’algorithme ne détecte pas proprement la zone que vous espériez, vous pouvez simplement annuler pour corriger seulement cette zone. En outre je voulais éviter de créer un nouvel outil si possible (il y en a déjà tellement!). Après tout, il s’agit du même cas d’usage dont s’est toujours occupé l’outil de remplissage, n’est-ce pas? Il s’agit simplement d’un algorithme différent pour décider comment se fait le remplissage. Il est donc tout à fait logique que ce ne soit qu’une option dans le même outil.
En conclusion, je remplace le watershedding sur l’image totale en utilisant encore une carte de distance. Nous avions déjà vu que cela sert comme estimation décente d’épaisseur (ou de demi-épaisseur pour être précis) locale des lignes. Donc quand on remplit avec une couleur, on utilise cette information pour inonder sous les pixels de lignes (jusqu’au centre de la ligne approximativement). Cela permet ainsi de s’assurer qu’aucun espace non colorié ne soit visible entre le remplissage et les traits. Simple, rapide et efficace. C’est une sorte de watershedding local, en plus simple et rapide, et cela m’a aussi permis d’ajouter un paramètre “Max flooding” pour garder l’inondation de couleur sous contrôle.
Colorisation intelligente sans la partie “intelligente”!
Un usage possible, et bien cool, de ce nouvel algorithme est de se passer de la première étape, c’est-à-dire ne pas calculer la fermeture des traits! Cela peut être très utile si vous utilisez un style de trait sans rupture (design simple avec lignes solides par exemple) et n’avez donc pas besoin d’aide algorithmique de fermeture. Ainsi vous pouvez remplir des zones d’un seul clic, sans vous préoccuper des la sursegmentation ou de la durée du traitement.
Pour cela, mettez le paramère “Maximum gap length” à 0. Voici un exemple de design très simple (à gauche) rempli avec l’algorithme historique par couleurs similaires (au centre) et par détection de traits (à droite), en un clic:
Gauche: AstroGNU par Aryeom – Centre: remplissage par couleurs similaires – Droite: remplissage par détection de traits
Vous voyez le “halo blanc” entre la couleur rouge et les lignes noires sur l’image du milieu? La différence de qualité avec le résultat à droite est assez frappant et explique pourquoi l’algorithme de remplissage historique par “couleurs similaires” n’est pas utilisable (directement) pour du travail qualitatif de colorisation, alors que le nouvel algorithme par détection de traits l’est.
Outil de remplissage amélioré pour tous!
En bonus, j’ai dû améliorer l’intéraction de l’outil de remplissage de manière générique, pour tout algorithme. Cela reste similaire, mais avec ces détails qui font toute la différence:
Clic et glisse
J’ai mentionné plus haut un problème de “sursegmentation”. En effet on peut appeler un algorithme “intelligent” pour le rendre attrayant, cela ne le rend pas pour autant “humainement intelligent”. En particulier, nous créons des lignes de fermetures artificielles basées sur des règles géométriques, pas de reconnaissance réelle de forme ni en fonction du sens du dessin, et encore moins en lisant dans les pensées de l’artiste! Donc souvent, cela segmentera trop, en d’autres termes, l’algorithme créera plus de zones artificielles qu’idéalement souhaitées (si en plus, vous peignez avec une brosse un peu crénelée, cela peut être très mauvais). Regardons à nouveau l’image précédente:
L’image est “sur-segmentée”
Le problème est clair. on voudra sûrement coloriser le chien avec un aplat de couleur unique, par exemple. Pourtant il a été divisé en une vingtaine de zones! Avec l’ancienne intéraction de l’outil de Remplissage, vous devriez alors cliquer 20 fois (au lieu du clic idéal à 1), ce qui est contre-productif. J’ai donc mis-à-jour l’outil pour autoriser le clic glissé, tel un outil de peinture avec brosse: cliquez, ne relâchez pas et glissez sur les zones à colorier. Cela est désormais possible avec le remplissage par détection de traits ainsi que sur couleurs similaires (pour le remplissage sur sélection, c’est par contre non pertinent, bien sûr). Cela rend le remplissage de dessin sursegmenté bien moins problématique puisque cela peut être fait d’un seul tracé. Ce n’est pas aussi rapide que le clic unique idéal, néanmoins cela reste tolérable.
Prélèvement de couleurs
Une autre amélioration notable est le prélèvement aisé de couleurs avec ctrl-clic (sans avoir besoin de sélectionner la pipette à couleurs). Tous les outils de peinture avaient déjà cette fonctionnalité, mais pas encore l’outil de remplissage. Pourtant on travaille là aussi clairement avec la couleur. Par conséquent pouvoir très aisément changer de couleur par prélèvement sur les pixels alentour (ce qui est un usage très commun des peintres numériques) rend l’outil extrêmement productif.
Avec ces quelques changements, l’outil de remplissage est désormais un citoyen de première classe (même si vous n’avez pas besoin de la colorisation intelligente).
Limitations et travail futur possible
Un algorithme pour peintres numériques
La Colorisation intelligente est faite pour travailler sur des dessins au trait. Cela n’est pas fait pour fonctionner sur des images hors dessin, en particulier des photographies. Bien sûr, on découvre toujours des usages non prévus que des artistes aventureux inventent. Peut-être cela se produira ici aussi. Mais pour le moment, pour autant que je puisse voir, c’est vraiment réservé aux peintres numériques.
Traiter des cas autres que lignes noires sur fond blanc?
Les lignes sont détectés de la manière la plus basique possible, avec un seuil soit sur le canal Alpha (si vous travaillez sur des calques transparent) ou sur le niveau de gris (particulièrement utile si vous travaillez avec des scans de dessins).
Ainsi la version actuelle de l’algorithme peut avoir quelques difficultés pour détecter des traits, si par exemple vous scannez un dessin sur papier non blanc. Ou tout simplement, vous pourriez avoir envie de dessiner en blanc sur fond noir (chacun est libre!). Je ne suis cependant pas certain si ces cas d’usage sont suffisamment courants pour valoir d’ajouter toujours plus de paramètres à l’outil. On verra.
Plus d’optimisation
Je trouve que l’algorithme reste relativement rapide sur des images de taille raisonnable, mais je le trouve encore un peu lent sur de grosses images (ce qui n’est pas un cas rare non plus, notamment dans l’industrie de l’impression), malgré le code multi-thread. Je ne serais donc absolument pas surpris si dans certains cas, vous ne préfériez pas simplement revenir à vos anciennes techniques de colorisation.
J’espère pouvoir revenir tranquillement sur mon code bientôt pour l’optimiser davantage.
Des bordures de couleur peu esthétiques
Le bord du remplissage n’est clairement pas aussi “joli” qu’il pourrait l’être par exemple en coloriant avec une brosse (où le bord montrerait un peu de “texture”. Par exemple, jetons à nouveau un œil à notre exemple d’origine.
L’endroit où le bord du remplissage est visible aura probablement besoin d’une retouche. J’ai ajouté un paramère d'”antialiasing” mais clairement ce n’est pas une vraie solution dans la plupart des cas. Ça ne remplace pas une édition manuelle avec une brosse.
Le pire cas est lorsque vous planifiez de retirer les traits après colorisation. Aryeom fait parfois ce type de dessins où les lignes ne servent qu’en support de travail avant d’être retirées pour le rendu final (en fait une scène entière dans ZeMarmot, un peu “rêveuse”, est faite ainsi). Dans ce cas, vous avez besoin d’un contrôle parfait de la qualité des bords des zones de couleurs. Voici un exemple où le dessin final est fait uniquement de couleurs, sans traits externes:
Image de production du film ZeMarmot, par Aryeom
Pas encore d’interface (API) pour les plug-ins
Je n’ai pas encore ajouté de fonctions pour que les scripts et plug-ins puissent faire du remplissage par détection de trait. Cela est fait exprès car je préfère attendre un peu après la première sortie, notamment pour m’assurer que nous n’avons pas besoin de plus ou meilleurs paramètres, puisque une API se doit de rester stable et de ne plus changer une fois créée, au contraire d’une interface graphique qui peut se permettre plus facilement des changements.
En fait vous vous êtes peut-être rendus compte que toutes les options disponibles dans G’Mic ne sont pas disponibles dans les options d’outils de GIMP (même si elles sont toutes implémentées). C’est parce que j’essaie de rendre l’outil moins confus, étant donné que nombres de ces options nécessitent de comprendre la logique intime de l’algorithme. Plutôt que de passer son temps à trifouiller des curseurs au hasard, j’essaie de trouver une interface qui nécessite peu d’options.
Outil de sélection contiguë
La détection de traits n’est pour l’instant implémentée que pour l’outil de remplissage, mais cela serait aussi tout à fait adapté comme méthode de sélection alternative pour l’outil de sélection contiguë. À suivre…
Segmenter moins
Avec des lignes propres et nets, et des formes simples, l’algorithme marche vraiment bien. Dès que vous complexifiez votre dessin, et surtout utilisez des traits avec un peu de caractère (par exemple la série de brosses “Acrylic”, fournie dans GIMP par défaut), un peu trop de points clés faux-positifs sont détectés, et par conséquent le dessin sur-segmente. Nous sommes tombés sur de tels cas, donc j’ai essayé diverses choses, mais pour l’instant je ne trouve aucune solution miracle. Par exemple récemment j’ai essayé d’appliquer un flou médian sur le trait avant la détection de points clés. L’idée est de lisser les imperfections du trait crénelé. Sur mon exemple de base, cela a bien marché:
Centre: sur-segmentation avec l’algorithme actuel Droite: toujours trop segmenté, mais bien moins, après avoir appliqué d’abord un flou médian
Malheureusement cela a rendu le résultat sur d’autres images très mauvais, notamment en créant des trous (un problème dont nous nous étions débarrassé en ne faisant plus d’étape d’érosion!).
Centre: résultat très acceptable avec l’algorithme actuel Droite: mauvais résultat qui ferait fuiter la couleur et qui perd de nombreux détails
Donc je cherche toujours. Je ne sais pas si on trouvera une vraie solution. Ce n’est clairement pas un sujet facile. On verra!
En règle générale, la sursegmentation (faux positifs) est un problème, mais il reste moindre que ne pas réussir à fermer des trous (faux négatifs), notamment grâce à la nouvelle intéraction clic et glisse. J’ai déjà amélioré quelques problèmes à ce sujet, tels les micro-zones que le papier de recherche appelle des “régions non significatives” (or elles sont vraiment significatives pour les peintres numériques, car rien n’est plus embêtant à remplir que des petits trous de quelques pixels); et récemment j’ai aussi réglé des problèmes liés à l’approximation rapide de la surface des régions, laquelle peut être fausse dans le cas de régions ouvertes.
Conclusion
Ce projet fut vraiment intéressant car il a confronté des algorithmes de recherche à la réalité du travail de dessin au quotidien. C’était d’autant plus intéressant avec la rencontre de 3 mondes: la recherche (un algorithme vraiment cool pensé par des esprits brillants du CNRS/ENSICAEN), le développement (moi!) et l’artiste (Aryeom/ZeMarmot). Par ailleurs, pour bien donner le crédit à qui de droit, beaucoup des améliorations d’interface furent des idées et propositions d’Aryeom, laquelle a testé cet algorithme sur le terrain, c’est à dire sur de vrais projets. Cette coopération CNRS/ZeMarmot s’est même tellement bien passée qu’Aryeom a été invitée fin janvier pour présenter son travail et ses problématiques de dessin/animation lors d’un seminaire à l’université ENSICAEN.
Bien sûr, je considère encore ce projet comme un “travail en cours”. Comme noté plus haut, divers aspects doivent encore être améliorés. Ce n’est plus mon projet principal mais je reviendrai clairement régulièrement pour améliorer ce qui doit l’être. C’est néanmoins déjà dans un état tout à fait utilisable. J’espère donc que de nombreuses personnes l’utiliseront et apprécieront. Dites nous ce que vous en pensez!
Un dernier commentaire est que les idées derrière les meilleurs algorithmes ne semblent pas nécessairement les plus incroyables techniquement. Cet algorithme de colorisation intelligente est basé sur des transformations très simples. Cela ne l’empêche pas de fonctionner très bien et d’être relativement rapide (avec quelques limites bien sûr), de ne pas prendre toute votre mémoire vive en bloquant l’interface du logiciel pendant 10 minutes… Pour moi, cela est bien plus impressionnant que certains algorithmes certes brillant, et pourtant inutilisables sur les ordinateurs de bureau. C’est de ce type d’algorithme dont on a besoin pour les logiciels de graphisme pour le bureau. C’est donc très cool et je suis d’autant plus heureux de travailler avec cette équipe talentueuse de G’Mic/CNRS.





 )! Néanmoins je n’ai implémenté que la première étape de l’algorithme et ai adapté la seconde avec une solution propre (quoique basée sur des concepts similaires) à cause de problématiques d’utilisabilité.
)! Néanmoins je n’ai implémenté que la première étape de l’algorithme et ai adapté la seconde avec une solution propre (quoique basée sur des concepts similaires) à cause de problématiques d’utilisabilité.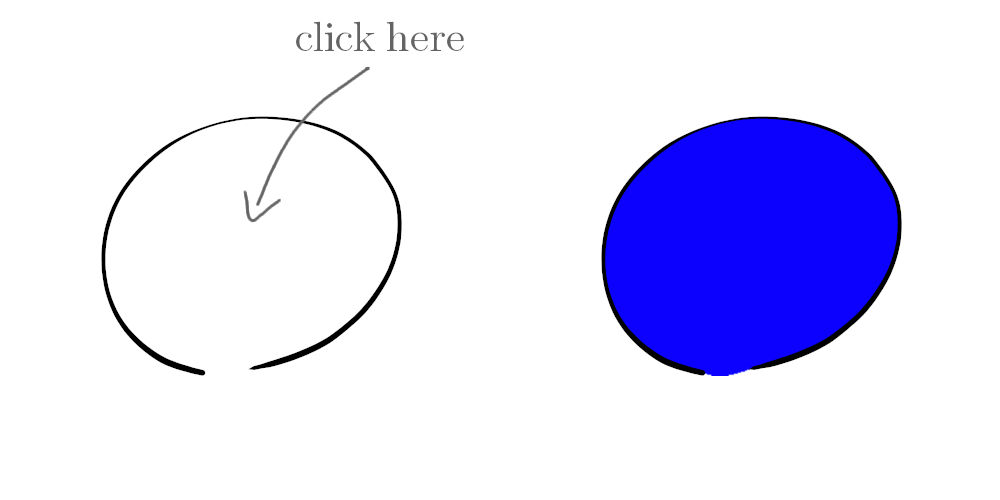



![filtre « Colorize lineart [smart coloring] »](./media/5e6af3b0.gmic_smart_coloring.jpg)