Haute Disponibilité et répartition de charge avec KeepAlived !
Keepalived c’est un peu comme le miel, au début ça colle aux doigts et après on s’aperçoit que son parfum sucré est drôlement agréable. Je vais donc aborder les fondements de la haute disponibilité de services réseaux au niveau kernel pour arriver à une solution entièrement pilotée.
De quoi s’agit-il ?
Une architecture informatique est dite hautement disponible lorsque sa conception est pensée d’une part pour répondre à la panne d’un ou plusieurs équipements et d’autre part lorsqu’elle est capable d’encaisser un pic de charge sans sourciller. La solution présentée dans ces pages se focalise sur la notion de services réseaux. Bien entendu, la notion de haute disponibilité doit être prise en compte à tous les niveaux d’un système, donc aussi bien au niveau matériel (RAID, liens réseaux redondés…) qu’au niveau applicatif (clusters MySQL, LDAP multi-master, etc…) qu’humain (hé oui si l’unique sysadmin qui connait une technologie est en vacances lors d’une panne…). La répartition de charge consiste à pouvoir distribuer les requêtes de manière efficace sur un pool de serveurs afin de pouvoir gérer un nombre importants de clients.
Un mode de fonctionnement très simple pour faire de la haute disponibilité consiste à mettre en place ce que l’on appelle du Round Robin DNS, en faisant pointer plusieurs enregistrements DNS identiques, par exemple :
www IN A 192.168.1.61
www IN A 192.168.1.62
Cependant, cette solution ne tient pas compte de la disponibilité réelle des services et peut connaître des problèmes de cache DNS. Il convient donc pour réaliser un fonctionnement propre d’utiliser un load balancer en frontal. Dans cette topologie, l’ensemble des flux entrants passent par le répartiteur qui achemine aux nœuds le trafic selon un algorithme (round robin, round robin pondéré, hash IP source, moins de connexions, etc…).
2. Comment ça fonctionne sous Linux ?
2.1 La couche IPVS
IPVS pour IP Virtual Server est une interface qui se greffe au niveau de la couche Netfilter. Pour rappel, Netfiler et la couche du noyau en charge de la manipulation des paquets réseaux. C’est cette couche que vous manipulez lorsque vous utilisez la commande iptables afin de mettre en place des règles de firewall. C’est cette même couche qui sera manipulée par la commande ipvsadm présente suite à l’installation du package éponyme.
L’opération consiste donc à présenter aux clients une adresse IP dite virtuelle (VIP) indépendante de celle utilisée pour l’administration des machines qui redirigera les flux vers les serveurs réels.
IPVS est capable d’opérer selon trois modes :
– IPVS-TUN, c’est à dire derrière un tunnel de type encapsulation IP. Je n’en parlerai pas car à ma connaissance ce mode est extrêmement peu utilisé
– IPVS-NAT
– IPVS-DR
2.2 IPVS-NAT
Le mode IPVS-NAT est le plus simple à mettre en œuvre techniquement mais implique une plus grande maîtrise du réseau. Il permet également d’utiliser un adressage IPV4 privé pour les serveurs réels lorsque l’on ne dispose pas de suffisamment d’adresses IP publiques.
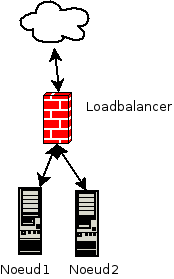
Dans ce mode, lorsqu’un paquet arrive sur le load balancer et qu’il correspond à un service fourni par IPVS, un serveur réel est choisi dans le pool selon l’algorithme sélectionné. Un enregistrement dans la table des connexions est effectué pour préserver la destination du paquet. L’adresse IP est réécrite pour correspondre à celle du serveur réel puis le paquet est routé vers celui-ci. Lorsque le serveur réel répond, le load balancer masque son IP en réécrivant le paquet puis l’achemine au client. Ainsi, tous les flux entrants et sortants passent par le load balancer.
2.3 IPVS-DR
Dans ce mode de fonctionnement, le load balancer et les serveurs réels sont physiquement sur le même segment de réseau. La VIP est partagée entre le load balancer et les serveurs réels via une pseudo-interface. Lorsqu’une requête arrive sur la VIP, le load balancer la dispatche sur les serveurs réels en fonction de l’algorithme retenu.
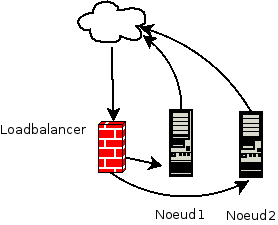
Sur le serveur de destination, la requête est traitée puis la réponse est directement effectuée par le serveur réel au client, sans passer cette fois par le load balancer. La décision de routage effectuée par le load balancer est conservée dans une table afin de conserver le routage jusqu’au timeout ou jusqu’à la terminaison de la connexion. Ce mode de fonctionnement a l’avantage d’être plus performant comme les réponses ne passent pas par le load balancer.
3. Mise en bouche avec IPVS
Commençons la pratique en se basant sur une architecture réseau simple. L’infrastructure de test est constituée de deux noeuds srv1 et srv2 d’adresses IP 192.168.1.61 et .192.168.1.62. Les deux nœuds hébergent chacun un serveur web Apache. En frontal, nous aurons un load balancer lb d’adresse IP 192.168.1.50. En ce qui concerne la distribution, elle a assez peu d’importance même si rien ne vaut une Debian !
Après avoir vidé les éventuels enregistrements ipvs déjà présents, on ajoute un service réseau sur le port 80 correspondant donc au HTTP, associé à un algorithme d’équilibrage. J’utilise ici les options longues afin de rendre les commandes plus explicites mais des options courtes existent bien entendu.
root@lb:~# ipvsadm --clear
root@lb:~# ipvsadm --add-service --tcp-service 192.168.1.50:80 --scheduler wrr
On peut vérifier que le service réseau est pris en compte en saisissant simplement le nom de la commande :
root@lb:~# ipvsadm
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.1.60:http rr
On ajoute ensuite les deux nœuds sur le load balancer :
root@lb:~# ipvsadm --add-server --tcp-service 192.168.1.50:80 --real-server 192.168.1.61:80 --gatewaying --weight 100
root@lb:~# ipvsadm --add-server --tcp-service 192.168.1.50:80 --real-server 192.168.1.62:80 --gatewaying --weight 100
Il est désormais possible de faire pointer un navigateur sur la VIP (donc http://192.168.1.50) et constater qu’il ne se passe… absolument rien !
Et pourtant, le load balancer retransmet bien des paquets :
root@lb:~# ipvsadm -L -n --stats
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Conns InPkts OutPkts InBytes OutBytes
-> RemoteAddress:Port
TCP 192.168.1.50:80 6 42 0 2520 0
-> 192.168.1.61:80 3 21 0 1260 0
Une inspection de paquets nous le confirme :
root@srv1:~# tcpdump port 80
20:23:56.204722 IP new-host-2.home.46973 > 192.168.1.50.http: Flags [S], seq 95994012, win 14600, options [mss 1460,sackOK,TS val 697670 ecr 0,nop,wscale 7], length 0
20:23:56.457979 IP new-host-2.home.46975 > 192.168.1.50.http: Flags [S], seq 3006976356, win 14600, options [mss 1460,sackOK,TS val 697746 ecr 0,nop,wscale 7], length 0
En effet, les nœuds du cluster reçoivent des paquets venant de l’adresse IP du load balancer sur l’adresse IP virtuelle qui ne correspond donc pas à une interface d’écoute. La solution consiste à faire de l’IP aliasing sur l’IP du load balancer. Cependant, le risque est que les nœuds parasitent les caches ARP en répondant aux requêtes. La solution consiste à ignorer les requêtes ARP. Comme je suis plutôt ceinture et bretelles, je préfère également bloquer les requêtes à coup d’arptables au montage de l’interface.
Sur les deux nœuds de notre cluster on va donc ajouter ceci au fichier /etc/sysctl.conf :
net.ipv4.ip_forward=0
net.ipv4.conf.all.arp_ignore=1
net.ipv4.conf.all.arp_announce=2
net.ipv4.conf.default.arp_ignore=1
net.ipv4.conf.default.arp_announce=2
net.ipv4.conf.lo.arp_ignore=1
net.ipv4.conf.lo.arp_announce=2
Et paramétrer l’interface virtuelle comme ceci dans le fichier /etc/netwowk/interfaces (ou pour une Red Hat/CentOS, paramétrer un fichier /etc/sysconfig/network-scripts/ifcfg-lo.0 adapté) :
auto lo:0
iface lo:0 inet static
address 192.168.1.60
netmask 255.255.255.255
up arptables -A INPUT -d 192.168.1.60 -j DROP
On active le tout :
sysctl -p /etc/sysctl.conf && ifup lo:0
Si vous ouvrez voter navigateur sur l’URL que l’on a indiqué plus haut, ça doit fonctionner !
4. Et si on faisait de la vraie haute disponibilité cette fois ?
4.1 Les défauts de l’architecture précédente
Ce que l’on a mis en place est fonctionnel mais il faut reconnaître que c’est très loin d’être parfait. D’une part, on parle de haute disponibilité alors que l’on a introduit une machine : le load balancer qui n’est absolument pas redondé. D’autre part, notre configuration ne tient absolument pas compte de l’état réel des nœuds. Pour autant, les interruptions de service autant normales (maintenances programmées ou non…) qu’anormales (pannes…) font partie de la vie d’un serveur.
C’est à ce niveau que le logiciel Keepalived intervient. Il implémente le protocole VRRP (Virtual Router Redundancy Protocol). Avec ce protocole, les deux équipements participant à un groupe VRRP communiquent en multicast afin de définir un rôle maître-esclave dans le but de s’échanger une adresse IP virtuelle en cas de défaillance d’un des deux équipements. D’autre part, Keepalived possède la notion de « checks » afin de vérifier qu’un service réseau est accessible et ainsi dynamiser la configuration de la couche ipvsadm.
4.2 Mise en place
Pour cela, on va conserver nos nœuds existants, mais partir de deux nouveaux load balancer lb1 et lb2 d’adresses IP 192.168.1.51 et 192.168.1.52. Sur chaque nœud, on va installer le package keepalived et construire un fichier /etc/keepalived/keepalived.conf, qui sera à quelques détails près identique sur les deux nœuds du cluster.
La première section, global_defs, comporte principalement des informations concernant les notifications par mail. La notion de routeur_id a somme toute peu d’importance car elle constitue un label qui peut être défini sur le hostname du serveur :
global_defs {
# Configuration des notifications :
notification_email {
sysadmin@domain.local
root@domain.local
}
notification_email_from nagios@domain.local
smtp_server 192.168.1.16
smtp_connect_timeout 30
# ID du load balancer
router_id lb1
}
Ensuite, il faut configurer le groupe VRRP. Celui-ci se définit via un identifiant VRRP, le virtual_routeur_id qui est commun aux deux load balancer. Ensuite, on indique un état par défaut du load balancer, le paramètre state positionné à MASTER sur lb1 et BACKUP sur lb2. Cependant, c’est la priorité la plus haute qui a réellement le dernier mot. Enfin, on définit la VIP qui sera partagée entre les deux load balancer.
vrrp_instance VI_1 {
virtual_router_id 100
state MASTER
priority 100
# Check inter-load balancer toutes les 1 secondes
advert_int 1
# Synchro de l'état des connexions entre les LB sur l'interface eth0
lvs_sync_daemon_interface eth0
interface eth0
# Authentification mutuelle entre les LB, identique sur les deux membres
authentication {
auth_type PASS
auth_pass secret
}
# Interface réseau commune aux deux LB
virtual_ipaddress {
192.168.1.50/32 brd 192.168.1.255 scope global
}
}
Enfin, la dernière partie intègre l’algorithme d’équilibrage de charge ainsi que les serveurs réels. On retrouve donc une configuration extrêmement proche de ce que nous avons vu en étudiant IPVS ce qui rend au final la lecture de la configuration relativement limpide.
virtual_server 192.168.1.50 80 {
# L'etat de santé des cibles est vérifié toutes les 5 secondes
delay_loop 5
lb_algo wrr
lb_kind DR
# Seul le protocole TCP est implémenté.
protocol TCP
# Si la VIP n'a pas pu être activée, le
# contrôle des serveurs réels est suspendu.
ha_suspend
# Vous pouvez définir l'adresse d'un serveur vers qui rediriger les
# requêtes si tous les serveurs réels sont injoignables.
#sorry_server 123.45.67.12 80
real_server 192.168.1.61 80 {
weight 1
HTTP_GET {
url {
path /
digest 21dde95d9d269cbb2fa6560309dca40c
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.1.62 80 {
weight 1
HTTP_GET {
url {
path /
digest 21dde95d9d269cbb2fa6560309dca40c
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
Un point particulier concerne cependant le digest. Il s’agit d’un hash de la page à vérifier. Bien entendu les données des serveurs doivent être identiques pour retourner le même hash. Celui-ci s’obtient avec une commande fournie par le paquet keepalived et s’exécute de cette façon en direction d’un des nœuds :
root@lb1:/etc/keepalived# genhash -s 192.168.1.62 -p 80 -u /
MD5SUM = 21dde95d9d269cbb2fa6560309dca40
Keepalived possède une sonde dédiée à la gestion du flux HTTP mais il aurait tout à fait été possible d’utiliser le check générique TCP_CHECK comme ci-après. Bien entendu, avec ce type de check, on ne vérifie que la disponibilité d’un port mais absolument pas la restitution correcte des informations.
real_server 192.168.1.61 80 {
weight 1
TCP_CHECK {
connect_timeout 3
connect_port 80
}
}
4.3 Ça marche vraiment ?
Maintenant que tout est en ordre et la configuration déployée sur les deux nœuds, il ne reste plus qu’à démarrer keepalived via le script d’init ou bien via la commade keepalived -f /etc/keepalived/keepalived.conf
Ceux qui auront saisi la commande ifconfig sur le master après ça auront peut-être eu une interrogation : comment mon load balancer peut rediriger les flux pour la VIP 192.168.1.60 alors qu’elle n’apparait pas dans la sortie d’ifconfig ? C’est simple, il faut passer par iproute2 qui prend réellement en charge toutes les fonctionnalités du noyau :
root@lb1:~# ip addr show dev eth0
2: eth0: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:42:b0:b3 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.51/24 brd 192.168.1.255 scope global eth0
inet 192.168.1.50/32 brd 192.168.1.255 scope global eth0
inet6 fe80::5054:ff:fe42:b0b3/64 scope link
valid_lft forever preferred_lft forever
Sur le master, les logs doivent indiquer que les checks sont activés et qu’il est bien passé en mode master :
May 25 23:29:57 lb1 Keepalived_healthcheckers: Activating healtchecker for service [192.168.1.61]:80
May 25 23:29:57 lb1 Keepalived_healthcheckers: Activating healtchecker for service [192.168.1.62]:80
May 25 23:29:57 lb1 kernel: [ 417.914963] IPVS: sync thread started: state = MASTER, mcast_ifn = eth0, syncid = 100
May 25 23:29:57 lb1 Keepalived_vrrp: VRRP_Instance(VI_1) Transition to MASTER STATE
May 25 23:29:58 lb1 Keepalived_vrrp: VRRP_Instance(VI_1) Entering MASTER STATE
Même chose sur le load balancer secondaire mais en indiquant cette fois le passage en mode secours :
May 25 23:30:45 lb2 Keepalived_vrrp: VRRP_Instance(VI_1) Entering BACKUP STATE
May 25 23:30:45 lb2 Keepalived_healthcheckers: Using LinkWatch kernel netlink reflector...
May 25 23:30:45 lb2 Keepalived_healthcheckers: Activating healtchecker for service [192.168.1.61]:80
May 25 23:30:45 lb2 Keepalived_healthcheckers: Activating healtchecker for service [192.168.1.62]:80
May 25 23:30:45 lb2 kernel: [ 476.743238] IPVS: sync thread started: state = BACKUP, mcast_ifn = eth0, syncid = 100
Simulons une panne ou une maintenance d'un des serveurs en arrêtant srv1.
May 25 23:32:57 lb2 Keepalived_healthcheckers: Timeout connect, timeout server [192.168.1.61]:80.
May 25 23:32:57 lb2 Keepalived_healthcheckers: Removing service [192.168.1.61]:80 from VS [192.168.1.50]:80
Puis son retour à la normale :
May 25 23:34:10 lb1 Keepalived_healthcheckers: MD5 digest success to [192.168.1.61]:80 url(1).
May 25 23:34:15 lb1 Keepalived_healthcheckers: Remote Web server [192.168.1.61]:80 succeed on service.
Même chose, en simulant une panne du load balancer maître, les logs du secondaire indique qu'il prend le relai. La commande ip addr doit confirmer la bascule de la VIP.
May 25 23:35:21 lb2 Keepalived_vrrp: VRRP_Instance(VI_1) Transition to MASTER STATE
May 25 23:35:22 lb2 Keepalived_vrrp: VRRP_Instance(VI_1) Entering MASTER STATE
May 25 23:35:22 lb2 kernel: [ 753.871114] IPVS: stopping backup sync thread 1959 ...
May 25 23:35:22 lb2 kernel: [ 753.873973] IPVS: sync thread started: state = MASTER, mcast_ifn = eth0, syncid = 100
A noter, la directive nopreempt permet d’empêcher la bascule vers le maître par défaut en cas de retour à la normale de celui-ci.
4.4 J’ai comme un doute sur ta manière de vérifier là…
Comme je le disais un peu plus haut, en dehors du check HTTP, les checks TCP sont extrêmement simples et ne vérifient que la possibilité de se connecter sur un port donné. Keepalived fournit un check générique, MISC_CHECK, permettant de déléguer à un script externe la vérification de l’état de santé. C’est le code de retour du script qui indique l’état de santé. Un code 0 renvoie un serveur disponible, 1 une erreur. D’autres valeurs sont possibles et sont documentées dans la page de man de keepalived.conf.
Un exemple pourrait donc être pour un serveur LDAP :
#!/bin/bash
HOST=$1
BASEDN="dc=domain,dc=local"
ldapsearch -x -h $HOST -b $BASEDN > /dev/null
Qui serait appelé dans keepalived comme suit :
real_server 192.168.1.61 389 {
weight 1
MISC_CHECK {
misc_path "/usr/local/bin/check_ldap.sh 192.168.1.61"
}
}
real_server 192.168.1.62 389 {
weight 1
MISC_CHECK {
misc_path "/usr/local/bin/check_ldap.sh 192.168.1.61"
}
}
Voila, je pense que l’on a fait un aperçu de ce qu’il est possible de faire grâce aux logiciels libres et de façon relativement simple sans devoir passer à la caisse pour acquérir une appliance « boite noire ». D’autres logiciels à la manière de keepalived sont capables de piloter la couche IPVS comme ldirectord, piranha qui offrent des fonctionnalités similaires et peuvent mériter votre attention mais ils se basent tous sur les mêmes principes !

Original post of Morot.Votez pour ce billet sur Planet Libre.



{kind=link}