I. Présentation
Dans ce tutoriel, nous allons voir comment fusionner un compte utilisateur de l'Active Directory local avec un compte utilisateur d'Office 365, en s'appuyant sur Azure AD Connect.
Prenons un cas classique : un tenant Office 365 d'un côté, avec des utilisateurs existants et actifs, créés directement dans le Cloud. Un annuaire Active Directory de l'autre, sur les serveurs de l'entreprise, avec des comptes pour les utilisateurs.
Et là, vous souhaitez mettre en place l'outil Azure AD Connect pour synchroniser les comptes de l'annuaire Active Directory on-premise avec Office 365. Une bonne idée puisque cela permet de synchroniser de nombreux attributs, dont le nom, le prénom, l'identifiant, l'e-mail, les alias ainsi que le mot de passe. Oui, mais comment procéder lorsque l'on a déjà les utilisateurs dans les deux annuaires et que l'on souhaite fusionner les comptes plutôt que de sacrifier les comptes de l'un des deux annuaires ? C'est ce que nous allons voir dans cet article.
II. Environnement et prérequis
Pour commencer, je vais décrire mon environnement et le point de départ de ce tutoriel pour éviter les ambiguïtés. Il peut y avoir plusieurs scénarios, d'où l'intérêt de préciser.
Je dispose de :
- Un tenant Office 365 pour le domaine it-connect.fr
- Un domaine Active Directory pour le domaine it-connect.local
L'outil Azure AD Connect est déjà installé et il est configuré de manière à synchroniser seulement certaines OUs de mon annuaire Active Directory local vers Office 365.
Pour le moment, les unités d'organisation à synchroniser sont vides ! Autrement dit, les utilisateurs à fusionner ne doivent pas être dans le périmètre des OUs synchronisées via Azure AD Connect (sauf si vous avez un filtre supplémentaire avec un groupe de sécurité).
Si vous avez besoin d'aide pour installer Azure AD Connect, suivez ce tutoriel : Installation d'Azure AD Connect.
L'objectif est de fusionner le compte Office 365 qui se nomme "florian.o365@it-connect.fr" avec le compte Active Directory de "florian.o365@it-connect.local". Remarquez la subtilité entre le ".fr" et le ".local", c'est important.
Avant de pouvoir synchroniser ce compte dans le but de le fusionner, il va falloir effectuer quelques vérifications, voire modifications !
III. Fusion des comptes AD / Office 365 : les étapes
Pour que l'outil Azure AD Connect soit en mesure de faire la correspondance entre les deux comptes existants, et donc faire une fusion, il va comparer les attributs des objets. Comme l'explique Microsoft dans sa documentation, il y a trois attributs utilisés pour faire la correspondance entre des comptes existants : userPrincipalName, proxyAddresses et sourceAnchor/immutableID.
Il y a deux types de correspondances :
- Soft-match : correspondance basée sur les attributs userPrincipalName et proxyAddresses
- Hard-match : correspondance basée sur l'attribut sourceAnchor
Dans notre cas, nous allons miser sur le soft-match puisque la synchronisation sera nouvelle pour ces comptes : nous allons devoir traiter avec une grande attention les attributs userPrincipalName et proxyAddresses de notre utilisateur.
A. Mise à jour de l'attribut userPrincipalName
Nous devons avoir la même valeur pour l'attribut userPrincipalName (appelé UPN) aussi bien dans l'Active Directory que dans Office 365. Pour rappel, cet attribut correspond au nom d'utilisateur dans Office 365 (utilisé pour se connecter) et au "Nom d'ouverture de session de l'utilisateur" dans l'AD.
Pour récupérer la valeur userPrincipalName dans Office 365, on peut regarder dans les "Utilisateurs actifs", à partir du portail Web. Comme ceci :
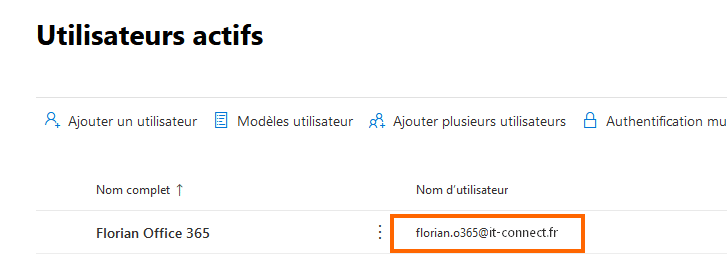
Note : sur le portail Web, tout à droite de la ligne vous pouvez constater que l'utilisateur est bien de type "Dans le cloud" en regardant la valeur de la colonne "Etat de synchronisation".
On peut aussi procéder avec PowerShell via le module MSOnline (ou un autre module qui permet d'interroger la base de compte Azure AD).
On se connecte à son tenant :
Connect-MsolService
On recherche l'utilisateur, en précisant son nom pour le paramètre -SearchString, par exemple.
Get-MsolUser -All -SearchString "Office"
La console va retourner :
UserPrincipalName DisplayName isLicensed
----------------- ----------- ----------
florian.o365@it-connect.fr Florian Office 365 True
Cela confirme qu'au niveau d'Office 365, le userPrincipalName est bien "florian.o365@it-connect.fr".
Pour rappel, pour récupérer la liste de tous vos utilisateurs Office 365, il suffit de faire :
Get-MsolUser -All
Maintenant, l'idée c'est de reporter la valeur "florian.o365@it-connect.fr" dans l'Active Directory pour l'utilisateur correspondant.
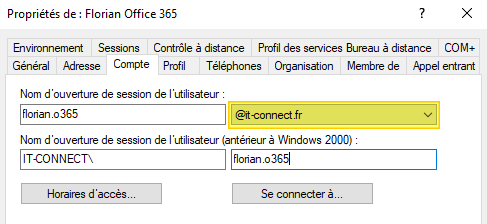
Rendez-vous dans l'Active Directory... Dans les propriétés de l'utilisateur. Voici ce que j'ai au sein de l'onglet "Compte".
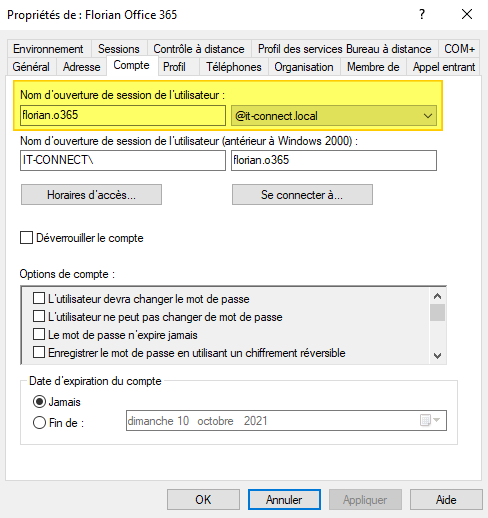
Mauvaise nouvelle : la valeur n'est pas bonne, car le domaine ne correspond pas. Il faut donc modifier le domaine @it-connect.local par @it-connect.fr. Si vous ne pouvez pas changer de domaine, vous devez déclarer un nouveau suffixe UPN correspondant à votre domaine de message.
Ensuite, il suffit de modifier le compte Active Directory avec le bon domaine puisque la première partie de l'identifiant est correcte. Voici le résultat.
Note : si vos utilisateurs se connectent sur les postes avec le nom court (sans @domaine.local), ce changement n'aura pas d'impact. Par contre, un utilisateur qui se connecte sur un PC avec son UPN sera perturbé et vous devez l'avertir de ce changement.
Pour finir avant de passer à l'attribut proxyAddresses, voici comment effectuer les vérifications de l'UPN avec PowerShell (et le module Active Directory).
Get-ADUser -Identity <login>
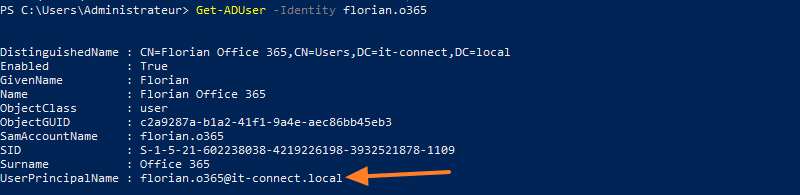
Get-ADUser -Identity florian.o365
Cette commande retourne bien la valeur de l'UPN :
Pour le modifier en PowerShell, il faudra faire :
Set-ADUser -Identity "florian.o365" -UserPrincipalName "florian.o365@it-connect.fr"
Voilà, le tour est joué !
B. Mise à jour de l'attribut proxyAddresses
Le champ proxyAddresses est caché dans l'onglet "Editeur d'attributs" de chaque compte utilisateur de l'Active Directory. Parfois méconnu, il est pourtant très important ! Il sert à définir l'adresse e-mail principale d'un utilisateur, mais aussi ses éventuels alias de messagerie.
Dans un scénario comme celui-ci, il est fort possible que cette valeur soit vide, car il n'y avait pas d'intérêt à compléter ce champ. En tout cas, ça c'était avant, car maintenant nous en avons besoin.
Si l'on reprend le compte "florian.o365@it-connect.fr", on sait que l'adresse de messagerie de cet utilisateur est "florian.o365@it-connect.fr" (identique à l'UPN, mais ce n'est pas une obligation). On peut récupérer cette information via le portail Web, mais aussi en PowerShell :
Get-MsolUser -UserPrincipalName "florian.o365@batimentcfanormandie.fr" | Ft userPrincipalName,proxyAddresses
ou
(Get-MsolUser -UserPrincipalName "florian.o365@batimentcfanormandie.fr").proxyAddresses
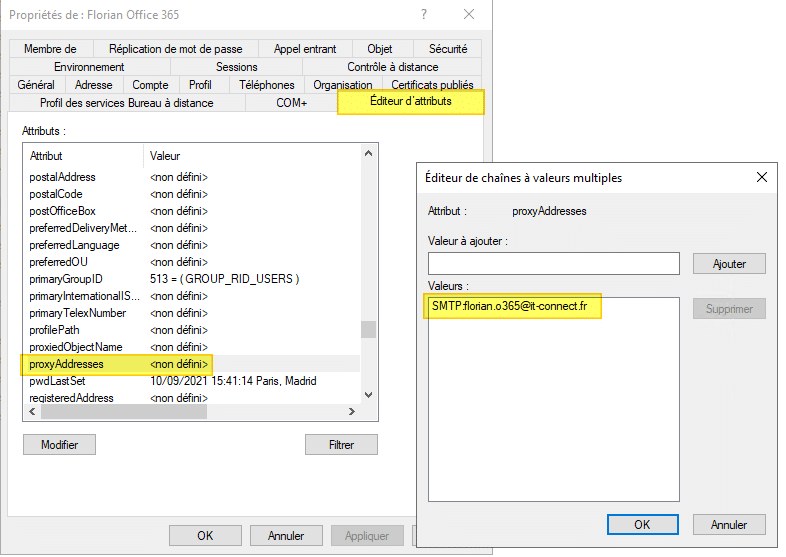
Il va falloir que l'on injecte cette valeur dans l'attribut proxyAddresses, au niveau de l'AD. Rendez-vous dans les propriétés du compte : Editeur d'attributs (nécessite d'activer : Affichage > Fonctionnalités avancées dans le menu de la console) > proxyAddresses > Modifier.
Pour déclarer l'adresse e-mail principale du compte, il faut utiliser cette syntaxe :
SMTP:florian.o365@it-connect.fr
C'est important d'écrire "SMTP" en majuscules pour dire qu'il s'agit de l'e-mail principale. Si l'on écrit "smtp" en minuscules, cela sert à déclarer un alias. Pour la fusion, c'est bien l'adresse e-mail principale qui est utile.
Voici un exemple :
Comme tout à l'heure, on peut le faire en PowerShell. Lire la valeur actuelle :
Get-ADUser -Identity "florian.o365" -Properties proxyAddresses | Format-Table userPrincipalName,proxyAddresses
Injecter la nouvelle valeur pour cet attribut en écrasant une éventuelle valeur existante :
Set-ADUser -Identity "florian.o365" -Replace @{proxyAddresses="SMTP:florian.o365@it-connect.fr"}
Je vous recommande aussi de mettre à jour l'attribut "mail" qui contient l'adresse e-mail. En fait, cela facilite la configuration d'Outlook pour remonter l'adresse e-mail directement, c'est plus agréable pour l'utilisateur final.
Voici la commande PowerShell :
Set-ADUser -Identity "florian.o365" -EmailAddress "florian.o365@it-connect.fr"
Voilà, le compte de notre utilisateur est prêt ! Nous allons pouvoir le synchroniser pour qu'il soit fusionné avec le compte Office 365 !
C. Déclencher la fusion du compte utilisateur
Dernière étape du processus : la synchronisation qui doit donner lieu à la fusion. Avant de poursuive, lisez ce qui suit : les informations du compte de l'Active Directory local vont venir écraser les informations du compte côté Office 365 au moment de la fusion. Cela signifie que le mot de passe du compte AD local va devenir le mot de passe de l'utilisateur côté Office 365 également.
Si c'est OK pour vous, prenez le compte utilisateur dans l'AD et déplacez-le dans une OU qui est synchronisée avec Azure AD Connect. Une fois que c'est fait, rendez-vous sur le serveur où est installé Azure AD Connect pour forcer une synchronisation, cela évitera d'attendre :
Start-ADSyncSyncCycle -PolicyType Delta
Vous n'avez plus qu'à regarder sur le portail Web d'Office 365 pour voir ce que ça donne. Quand le compte sera fusionné, l'icône va changer : le petit nuage va laisser place à l'icône de synchronisation. Et comme ça fonctionne, c'est vous qui êtes sur un petit nuage. 
Sans plus attendre, vérifiez les différentes valeurs pour voir si tout est bien conforme. Vérifiez également que la connexion au compte fonctionne : autant tout tester jusqu'au bout pour ce premier essai.
Si la correspondance n'est pas complète (UPN pas égaux, par exemple), la fusion pourra s'effectuer malgré tout, mais ce ne sera pas concluant. Par exemple, vous pouvez vous retrouver avec un nom d'utilisateur Office 365 qui prend le domaine "votre-domaine.onmicrosoft.com".
Avant d'effectuer la fusion sur un ou plusieurs comptes, je vous recommande fortement d'effectuer un essai avec un utilisateur de test pour valider le processus. Voilà, c'était le mot de la fin.
The post
Comment fusionner un utilisateur de l’AD local avec un compte Office 365 ? first appeared on
IT-Connect.