À l'occasion de l'événement Surface Event, Microsoft a dévoilé ses nouveaux ordinateurs portables hybrides ainsi que son nouveau smartphone à double écran. Au programme : Surface Pro 8, Surface Go 3, Surface Duo 2, et un tout nouveau produit avec la Surface Laptop Studio.
Surface Pro 8
Commençons par le produit historique de la gamme Surface : la Surface Pro. Pour cette 8ème génération, Microsoft a apporté quelques évolutions très intéressantes. Alors bien sûr, la Surface Pro 8 aura le droit à un processeur Intel de 11ème génération.
Voici les autres nouveautés principales :
Deux ports Thunderbolt 4
Une batterie avec 16 heures d'autonomie
Support de l'audio Dolby Atmos
Caméra frontale de 5 mpx
Un nouveau stylet Surface Slim Pen, plus fin et qui se range sur le clavier
Quant à l'écran tactile PixelSense Flow de 13 pouces, il bénéficie d'un taux de rafraichissement à 120 Hz et il est compatible Dolby Vision et Dolby Vision IQ.
La Surface Pro 8 sera disponible à partir du 28 Octobre 2021 avec un prix de départ fixé à 1 179 euros. À ce prix, vous avez le droit à un processeur Intel Core i5, 8 Go de RAM et 128 Go de SSD.
La petite sœur de la Surface Pro a le droit à sa mise à niveau. La Surface Go 2 laisse la place à la Surface Go 3, une nouvelle génération qui serait 60% plus rapide grâce aux processeurs Intel, notamment l'Intel Core i3, mais en 10ème génération. Microsoft va sortir un modèle équipé d'une puce 4G+, ce qui est nouveau sur ce produit.
Par ailleurs, la Surface Go 3 sera équipée d'un écran tactile PixelSense de 10,5 pouces, accompagné par une caméra frontale 1080p avec des micros Studio Mics. Sans surprise, la Surface Go 3 sera compatible Windows 11 et le nouveau système de Microsoft sera préinstallé.
La Surface Go 3 sera disponible à partir du 5 octobre 2021 avec un prix de départ fixé à 439 euros. À ce prix, le processeur est un Intel Pentium 6500Y accompagné par 4 Go de RAM et 64 Go de SSD.
Le nouvel ordinateur hybride Surface Laptop Studio est un mix entre une Surface Book et une Surface Studio. Ce modèle s'adresse aux créateurs, aux designers, aux graphistes... La plus puissante des Surface, basée sur des processeurs Intel Core Séries H de 11ème génération.
La Surface Laptop Studio bénéficie d'un écran tactile PixelSense Flow de 14 pouces (120 Hz), qui peut s'incliner de manière très surprenante comme la Surface Studio version desktop, afin de basculer en mode Studio ! Pour la partie audio, vous pouvez compter sur les 4 haut-parleurs compatibles Dolby Atmos. Sachez qu'il y aura deux ports Thunderbolt 4.
Au niveau de la carte graphique, Microsoft a choisi d'intégrer une carte NVIDIA GeForce RTX 3050 Ti. Microsoft proposera un modèle avec 32 Go de RAM et 2 To de SSD pour le stockage.
La Surface Laptop Studio sera disponible début 2022 et son prix de départ devrait être de 1 600 dollars.
Le Surface Duo 2 était attendu au tournant afin de relever le niveau vis-à-vis de la première version et de sa configuration décevante. Même si le Surface Duo 2 reprend la même base, Microsoft a clairement mis à niveau la fiche technique ! Voici les caractéristiques principales du Surface Duo 2, le smartphone à double écran de Microsoft :
Écrans AMOLED PixelSense 8,3 pouces en mode ouvert / 5,8 pouces en mode fermé
Processeur Snapdragon 888 (5G)
RAM : 8 Go
Stockage : de 128 Go à 512 Go
Module photo arrière avec trois capteurs (12 mpx grand-angle + 12 mpx téléobjectif + 16 mpx ultra grand-angle)
Module photo avant avec un capteur (12 mpx)
Paiement sans contact via NFC
Wi-Fi 6
Double batterie 4 340 mAh
Capteurs : accéléromètre, gyroscope, magnétomètre, capteur de luminosité, capteur de proximité, capteur à effet Hall, lecteur d'empreintes digitales
Le Surface Duo 2 sera disponible à partir du 21 octobre 2021 avec un prix de départ fixé à 1 599 euros.
VMware a publié un bulletin de sécurité pour informer ses clients de la présence d'une faille de sécurité critique au sein de toutes les installations de vCenter Server en version 6.7 et 7.0.
Pour rappel, le vCenter est un serveur de gestion pour faciliter l'administration et la configuration d'un ensemble de serveurs VMware et des machines virtuelles associées.
Au moment d'évoquer cette vulnérabilité, Bob Plankers, Technical Marketing Architect chez VMware, précise qu'elle peut être exploitée par quelqu'un qui est capable de contacter le serveur vCenter sur le réseau (port 443), peu importe la configuration, qui est en place sur le serveur vCenter. Pour se convaincre que cette faille est réellement critique, il suffit de regarder son score CVSS 3.1 : 9.8 / 10.
Cette faille de sécurité se situe au sein du service Analytics et elle permet à un pirate d'exécuter des commandes ou un programme sur l'hôte vCenter grâce au chargement d'un fichier malveillant. L'attaquant n'a pas besoin d'être authentifié sur le serveur pour exploiter la faille et il n'y a aucune interaction requise de la part des utilisateurs, contrairement à certains cas. Cela rend la vulnérabilité facilement exploitable.
Par conséquent, il est fortement recommandé d'installer le correctif dès que possible afin de se protéger contre cette vulnérabilité référencée avec le nom CVE-2021-22005. Un serveur VMware vCenter 7.0 doit être mis à jour vers la version 7.0 U2c pour être protégé, tandis que pour un serveur vCenter 6.7, il faut viser la version 6.7 U3o.
Il est à noter que certaines versions ne sont pas affectées par cette vulnérabilité, notamment la version vCenter Server 6.5.
Pour ceux qui ne sont pas en mesure d'appliquer le correctif dès maintenant, VMware a publié une procédure pour atténuer la vulnérabilité. Cela consiste à modifier un fichier de configuration et à redémarrer les services. Tout cela est expliqué sur cette page.
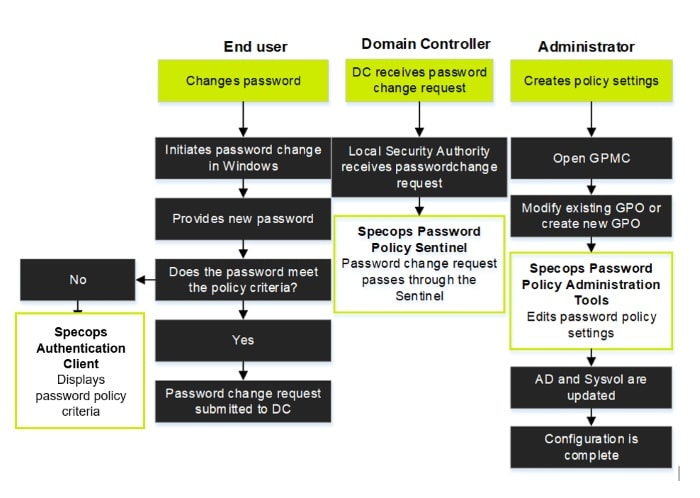
Dans ce tutoriel, nous allons découvrir le logiciel Specops Password Policy. Il va permettre de mettre en place des politiques de mots de passe très flexibles au niveau de l'Active Directory et d'accompagner les utilisateurs pour le renouvellement de leur mot de passe.
La mise en place d'une politique de mots de passe n'est jamais une tâche facile en entreprise. Bien souvent, les utilisateurs sont réticents à la mise en place de contraintes concernant les mots de passe. Pourtant, c'est indispensable, car les mots de passe sont continuellement pris pour cible lorsqu'il s'agit d'attaquer une entreprise. Ce fameux sésame est la clé qui ouvre la porte à une partie du système d'information. Pour lutter contre les attaques de type brute force et password spraying, il n'y a pas de secrets : il faut mettre des mesures de protection en place.
Nativement, l'Active Directory intègre la possibilité de mettre en place une politique de mots de passe pour les comptes des utilisateurs. Même si l'on peut mettre en place les stratégies de mots de passe affinées, cette solution native ne va pas assez loin en matière de sécurité des mots de passe et dans la gestion du renouvellement de ces mêmes mots de passe.
Quand je dis "cette solution native ne va pas assez loin en matière de sécurité des mots de passe", j'entends par là qu'il n'est pas possible d'interdire les mots de passe trop proches, et qu'il n'est pas possible de vérifier si le mot de passe saisi par l'utilisateur fait déjà l'objet d'une fuite de données (et que, potentiellement, il est déjà présent dans un dictionnaire).
Le logiciel payant Specops Password Policy va apporter des fonctionnalités que l'on peut résumer en trois points :
Définir une politique de mots de passe sur mesure pour les utilisateurs (en s'appuyant sur un groupe de sécurité ou en ciblant une unité d'organisation) en appliquant de nombreuses règles
Vérifier si le mot de passe est compromis : le mot de passe définit par l'utilisateur est un mot de passe qui est présent dans une fuite de données ou utilisé par des hackers et repéré par Specops grâce à des honeypots
Notifier les utilisateurs par e-mail et/ou SMS : le mot de passe expire dans X jours ou le mot de passe a été trouvé dans une fuite de données
Avant de commencer, vous deveztélécharger Specops Password Policy. En utilisant mon lien, vous pouvez obtenir une version d'essai de 45 jours (contre 30 jours en temps normal) : de quoi prendre le temps de découvrir le logiciel et d'avoir de premiers retours.
II. Installation de Specops Password Policy
L'installation de Specops Password Policy (SPP) s'effectue en plusieurs étapes. Pour cette démonstration, je vais utiliser 3 machines virtuelles pour reproduire l'installation selon les bonnes pratiques de l'éditeur :
1 serveur contrôleur de domaine Active Directory - SRV-ADDS-01
1 serveur membre Windows Server - SRV-APPLIS
1 poste de travail sous Windows 11
En résumé, je vais installer sur le contrôleur de domaine : les outils d'administration de SPP et le composant Sentinel qui doit être installé sur l'ensemble des contrôleurs de domaine. Sur le serveur membre, je vais installer également les outils d'administration de SPP ainsi que le composant Arbiter. Enfin, le poste de travail sous Windows est là pour tester le logiciel en se mettant dans la peau d'un utilisateur.
A. A quoi correspondent les rôles Sentinel et Arbiter ?
Les rôles Sentinel et Arbiter sont propres à Specops Password Policy, donc je vais vous expliquer l'utilité de ces deux composants.
Le rôle Sentinel s'installe sur tous les contrôleurs de domaine et il est là pour s'assurer que les politiques de mots de passe définies dans SPP sont bien respectées. En fait, lorsqu'un utilisateur va modifier son mot de passe il va l'analyser pour vérifier qu'il respecte bien la politique qui s'applique sur cet utilisateur.
Le rôle Arbiter sert de proxy (ou de passerelle si vous préférez) entre le contrôleur de domaine et les services Cloud de Specops. Il s'installe sur un serveur différent, car on considère que le contrôleur de domaine n'a pas d'accès à Internet. Grâce à une clé d'API, il va communiquer avec le service "Breached Password Protection API" de Specops pour vérifier si le nouveau mot de passe de l'utilisateur est présent dans une fuite de données, auquel cas il sera refusé.
Note : la vérification du mot de passe au travers de "Breached Password Protection API" s'effectue de façon sécurisée. Le mot de passe n'est pas envoyé entièrement pour requêter l'API puisque la requête est effectuée avec les quatre premiers caractères du mot de passe. Ensuite, l'API retourne les mots de passe correspondants s'il y en a, et c'est au niveau local que la vérification est effectuée.
B. Préparation du contrôleur de domaine
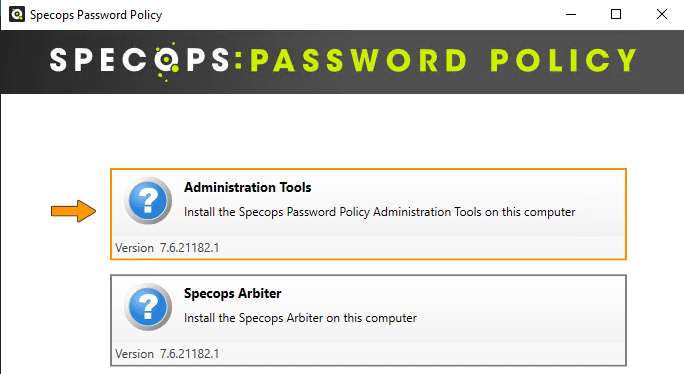
Au premier lancement, l'exécutable décompresse ses données dans le dossier "C:\Temp\SpecopsPasswordPolicy_Setup_7.6.21182.1", ce qui sera utile pour la suite, vous verrez. Il faut commencer par installer la console de gestion du logiciel, par l'intermédiaire du bouton "Administration Tools".
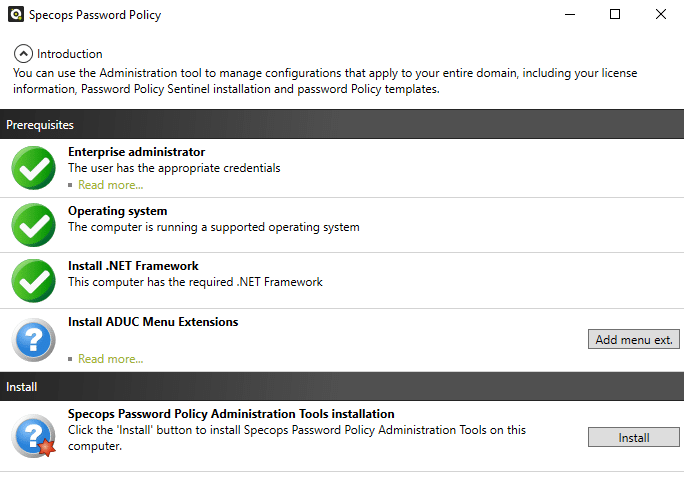
Ensuite, il faut cliquer sur le bouton "Add menu ext." puis sur le bouton "Install" pour installer les différents composants liés à la gestion du logiciel.
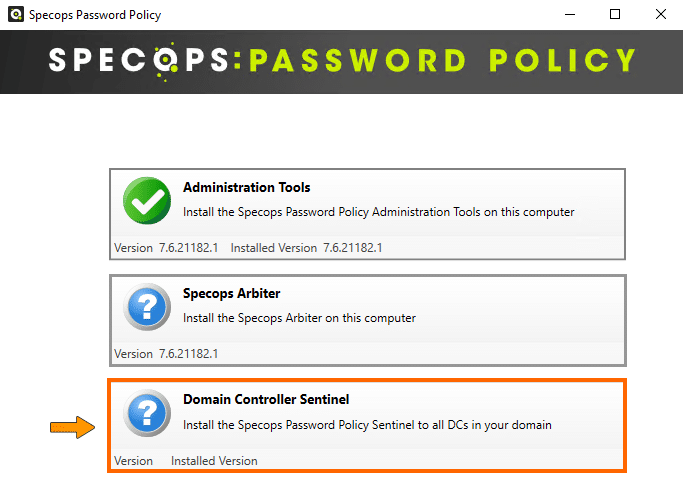
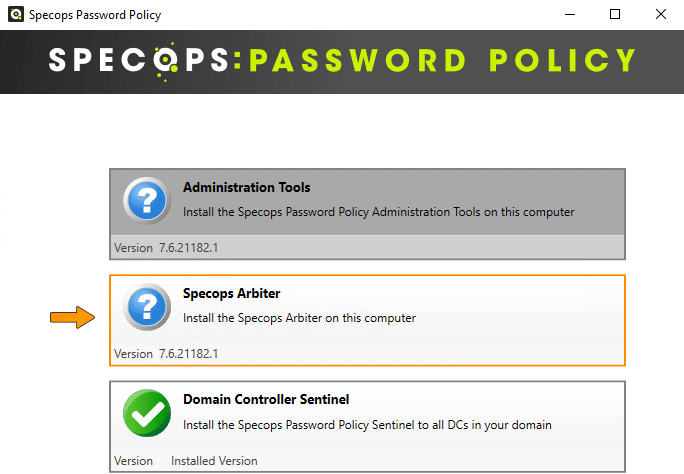
Ensuite, revenez au menu principal de l'installeur. Cliquez sur "Domain Controller Sentinel".
Sélectionnez tous les contrôleurs de domaine de votre infrastructure pour déployer l'agent partout. Pour ma part, il n'y en a qu'un seul. Une fois la sélection effectuée, il faut cliquer sur "Install".
Voilà, nous en avons fini avec le contrôleur de domaine pour le moment.
C. Préparation du serveur membre
À partir du serveur membre, qui s'appelle dans mon cas "SRV-APPLIS", je vais accéder aux sources d'installation située sur mon serveur SRV-ADDS-01.
\\SRV-ADDS-01\c$\Temp\
Ensuite, j'exécute l'assistant d'installation.
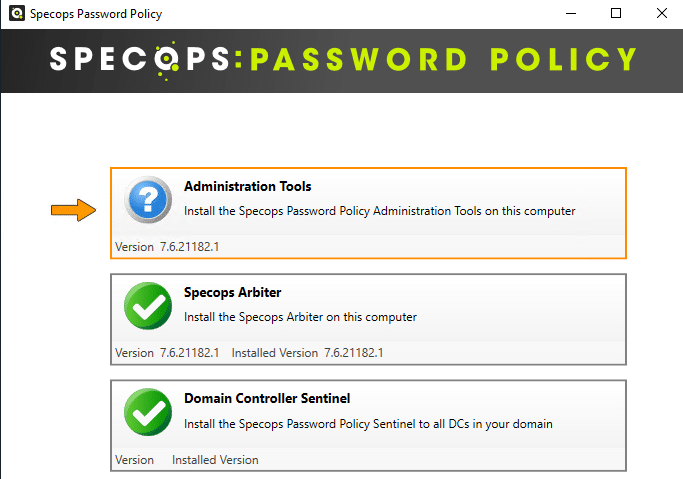
Cette fois-ci, je sélectionne le rôle "Specops Arbiter". Il est à noter que l'éditeur recommande d'installer au minimum deux serveurs avec le rôle Arbiter pour assurer la redondance. Que vous installiez un seul ou plusieurs serveurs Arbiter, le coût reste le même.
Cliquez sur le bouton "Install" et suivez l'assistant.
Comme sur l'autre serveur, installez la console en cliquant sur "Administration Tools", puis cliquez directement sur "Install".
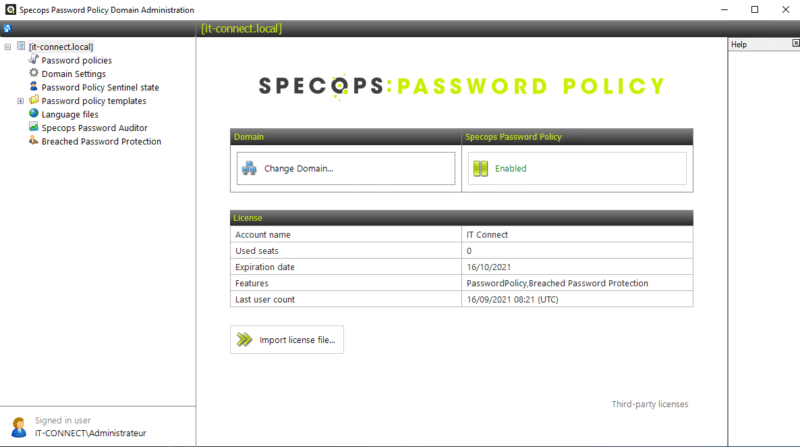
Vous pouvez fermer l'assistant d'installation. Sur votre serveur, vous pouvez ouvrir la console "Specops Password Policy Domain Administration" pour commencer à configurer le logiciel.
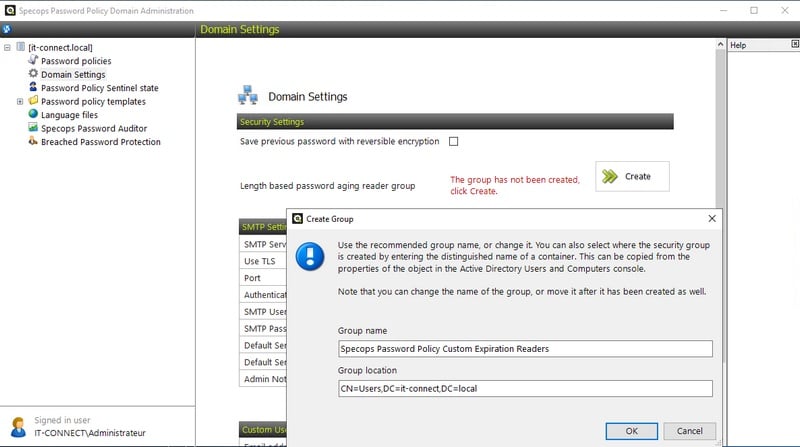
Accédez à l'onglet "Domain Settings" : le message "The group has not been created, click Create" apparaît. Cliquez sur le bouton "Create" puis sur "OK". Cela va permettre de créer un groupe nommé "Specops Password Policy Custom Expiration Readers" dans l'Active Directory.
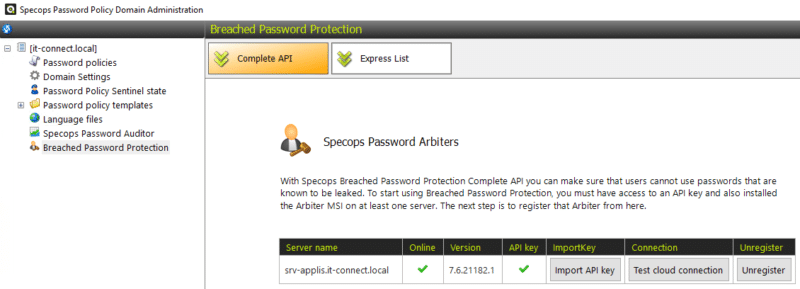
Ensuite, accédez à l'onglet "Breached Password Protection" afin d'enregistrer notre serveur Arbiter ("Register new Arbiter") auprès de l'API Breached Password Protection. Ce qui est indispensable pour utiliser cette fonctionnalité (que nous découvrirons par la suite).
Voilà, laissez la console de côté un instant, nous allons préparer le poste client. Ce sera fait et nous aurons plus à nous occuper de la partie installation.
D. Préparation du poste client
Sur les postes clients, il est recommandé de déployer un agent Specops. Pourquoi ? Cet agent est utile lors de la réinitialisation d'un mot de passe depuis le poste client. Il va permettre d'afficher à l'utilisateur les conditions à respecter pour définir son nouveau mot de passe. Sachez malgré tout que l'installation du logiciel sur les postes clients est facultatif (vous verrez par la suite l'intérêt de ce client).
Cet agent est disponible au format MSI, ce qui va permettre de le déployer facilement par GPO ou avec un logiciel de déploiement. Il est disponible en version 32 bits et 64 bits. La bonne nouvelle, c'est qu'il s'installe très facilement, sans configuration particulière.
Pour ma part, j'ai procédé à l'installation du package "Specops.Authentication.Client-x64.msi" sur une machine Windows 11.
Nous verrons dans la suite de ce tutoriel à quoi ressemble l'intégration au sein du poste client.
III. Création de sa première politique de mots de passe renforcée
Il est temps de créer notre première politique de mots de passe renforcée et surtout une politique sur mesure, que l'on va configurer aux petits oignons, comme on dit.
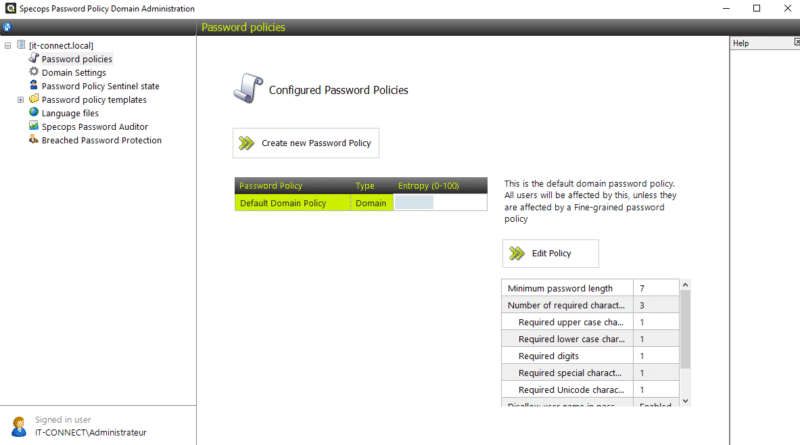
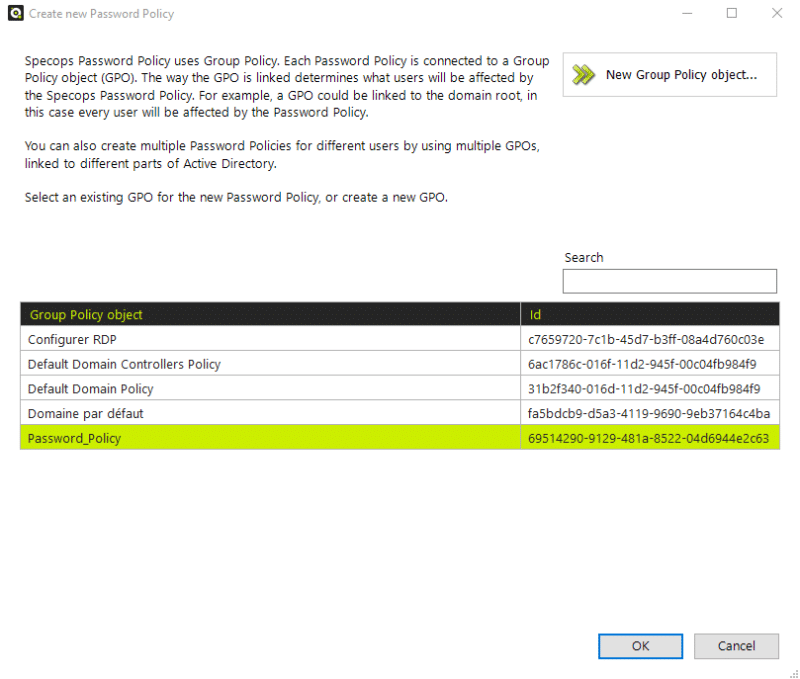
En haut à gauche, cliquez sur "Password policies". Ensuite, le logiciel va lister les politiques de mots de passe actuelles, y compris celle native de l'Active Directory. Pour notre part, nous allons créer une nouvelle politique : cliquez sur "Create new Password Policy".
Note : pour modifier une politique existante et créée avec Specops, il suffit de la sélectionner et de cliquer sur le bouton "Edit Policy".
Ensuite, la liste de vos GPOs s'affiche. Cliquez sur "New Group Policy object" pour créer une nouvelle GPO qui va utiliser l'extension Specops. Pour ma part, je nomme cette GPO "Password_Policy".
Pendant le processus de création de la GPO, il est nécessaire de sélectionner l'OU sur laquelle appliquer la GPO (et donc la politique de mots de passe). Tout en sachant que la politique s'applique sur les utilisateurs. Une alternative consiste à s'appuyer sur un groupe de sécurité pour appliquer les politiques du logiciel Specops, c'est au choix.
Note : la liaison de la GPO liée à Specops sur les OUs peut être effectuée à partir de la console standard de gestion des GPOs.
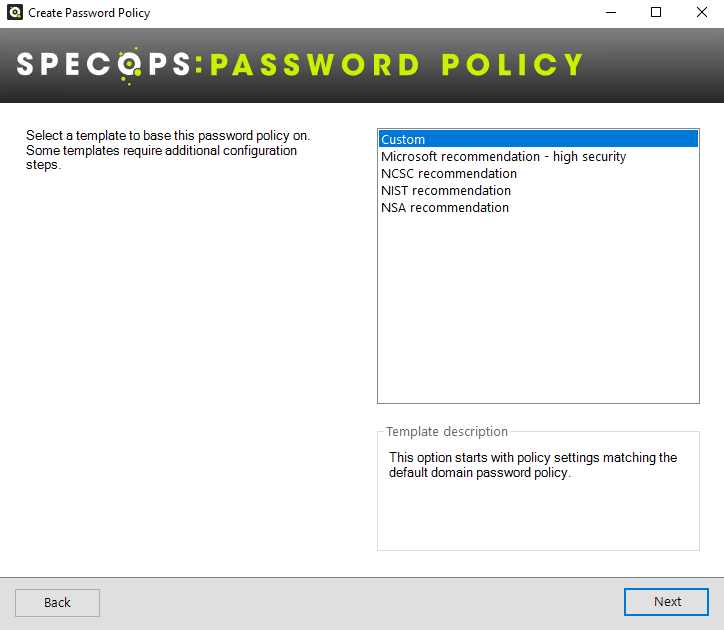
Ensuite, vous avez plusieurs choix pour créer votre politique :
Custom : une politique sur mesure que vous personnalisez entièrement
Microsoft recommendation : politique de mots de passe basée sur les recommandations de Microsoft
NCSC recommendation : politique de mots de passe basée sur les recommandations du NCSC (National Cyber Security Centre, équivalent de l'ANSSI au Royaume-Uni
NIST recommendation : politique de mots de passe basée sur les recommandations du NIST (National Institute of Standards and Technology, États unis)
NSA recommendation : politique de mots de passe basée sur les recommandations de la NSA (National Security Agency, Etats-Unis)
Ce serait intéressant que l'ANSSI entre en contact avec Specops (ou l'inverse) pour intégrer les recommandations de l'ANSSI au logiciel. Ce serait une bonne évolution pour aiguiller les entreprises lors de la création d'une politique.
Pour notre part, nous allons choisir "Custom" pour voir les différentes options proposées par ce logiciel. Le fait d'utiliser une politique qui suit les recommandations permet de partir d'une base, mais vous pouvez ajuster la politique malgré tout.
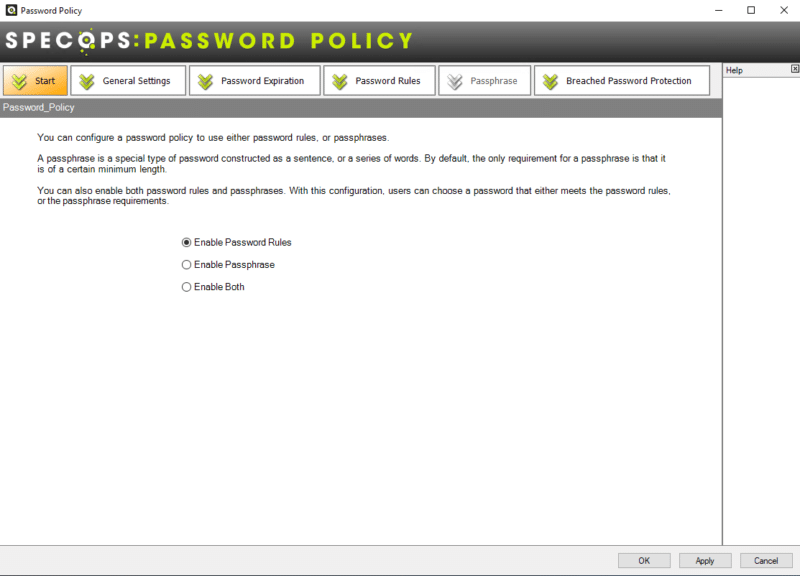
Nous pouvons définir une politique de mots de passe et une politique de passphrase ("phrase secrète"), que l'on peut considérer comme des mots de passe constitués d'une suite de mots et avec une longueur plus importante que les mots de passe standards. Nous pouvons faire choisir les deux, c'est ce que nous allons faire : choisissez "Enable Both".
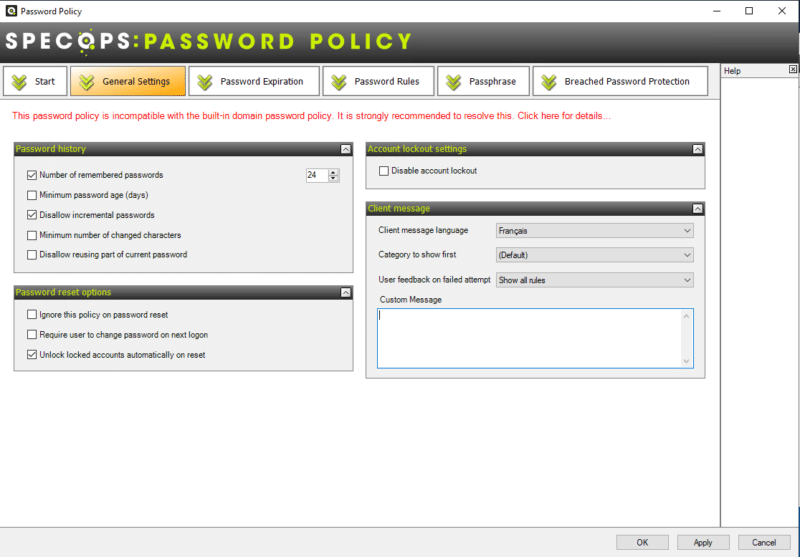
Commençons par le premier onglet "General Settings". Au sein de cet onglet, nous allons retrouver les paramètres globaux, notamment au sujet de l'historique des mots de passe.
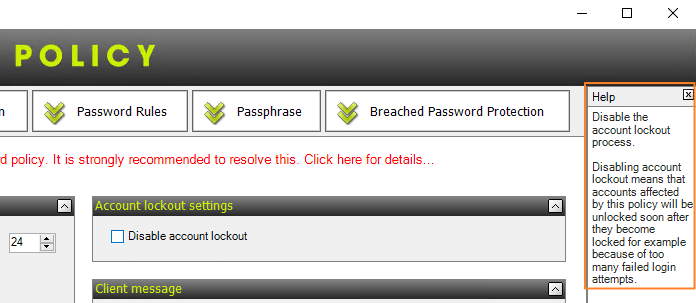
Note : le message "The password policy is incompatible with the built-in domain password policy...." s'affiche si la politique que vous êtes en train de créer "est plus faible" que la politique de mots de passe intégrée à l'Active Directory. Dans ce cas, il faut ajuster la politique existante pour faire disparaître le message.
Pour être plus précis sur la partie historique des mots de passe :
L'option "Disallow incremental passwords" permet de désactiver l'incrémentation des mots de passe. Je m'explique : un utilisateur avec le mot de passe "Bonjour1" ne pourra pas définir "Bonjour2" ni "Bonjour5" comme mot de passe. Quant à l'option "Number of remembered passwords", elle permet d'indiquer le nombre de mots de passe mémorisés et sur lequel se base l'historique de mots de passe de l'utilisateur.
Il est déconseillé d'utiliser les options "Minimum number of changed characters" (Minimum de caractères différents entre l'ancien et le nouveau mot de passe) et "Disallow reusing part of current password" (Désactiver la réutilisation d'une partie du mot de passe actuel), car, bien qu'elle puisse sembler pertinente, elles nécessitent d'activer le chiffrement réversible au sein de l'Active Directory. Pour des raisons évidentes de sécurité, on évitera et on se contentera des comparaisons basées sur les hash.
Ce que j'aime bien au sein de l'interface de SPP, c'est le panneau d'aide sur la droite. En fait, lorsque l'on positionne la souris sur une option, il y a l'aide concernant cette option qui s'affiche sur la droite. C'est très pratique.
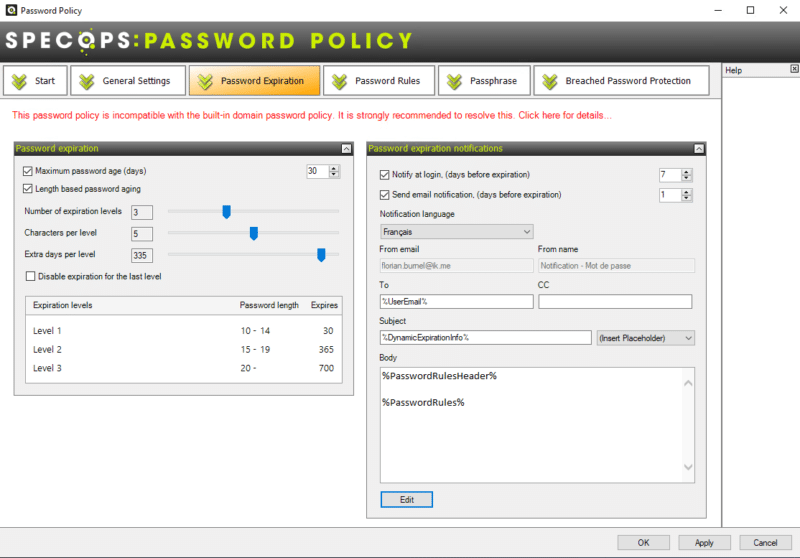
Passons à l'étape suivante : "Password Expiration". Elle va permettre de configurer la politique d'expiration des mots de passe et de paramétrer les notifications associées.
Password expiration
En configurant la politique, on peut adopter la logique suivante : plus le mot de passe est long, plus l'utilisateur peut le conserver longtemps. Tout cela est ajustable et on crée des "niveaux d'expiration". Une bonne manière de motiver les utilisateurs pour qu'ils définissent un mot de passe plus long car en général ils n'aiment pas changer leur mot de passe.
Dans l'exemple ci-dessous, il y a trois niveaux d'expiration, mais on peut en créer plus que cela. Un utilisateur qui définit un mot de passe compris entre 10 et 14 caractères devra le changer au bout de 30 jours maximum, tandis qu'un utilisateur avec un mot de passe compris entre 15 et 19 caractères devra le changer au bout de 365 jours maximum.
Password expiration notifications
Il est possible de notifier l'utilisateur que son mot de passe arrive à expiration. Cette notification s'effectue par e-mail et vous pouvez choisir combien de jours avant l'expiration du mot de passe vous souhaitez notifier l'utilisateur.
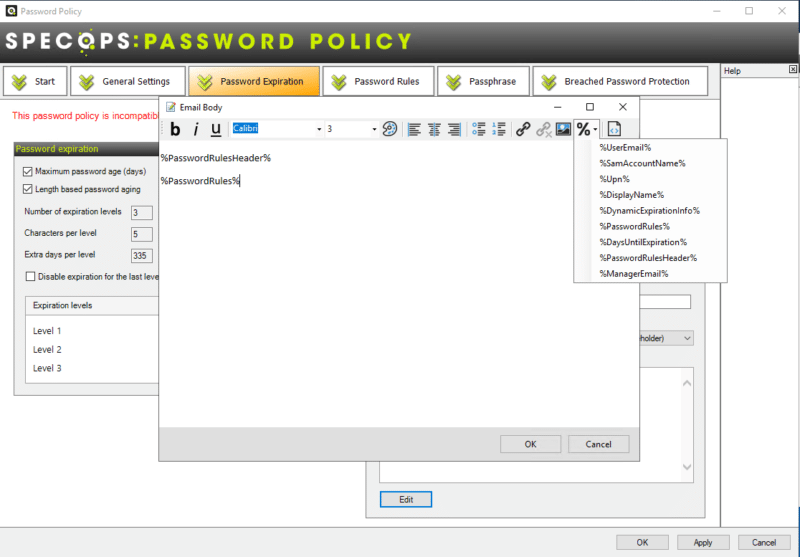
Pour les notifications, l'e-mail est entièrement personnalisable et vous pouvez inclure certaines variables. Ces valeurs dynamiques vont permettre d'intégrer le nom d'utilisateur, le nom d'affichage, l'adresse e-mail ou encore l'adresse e-mail du responsable (si c'est renseigné dans l'AD).
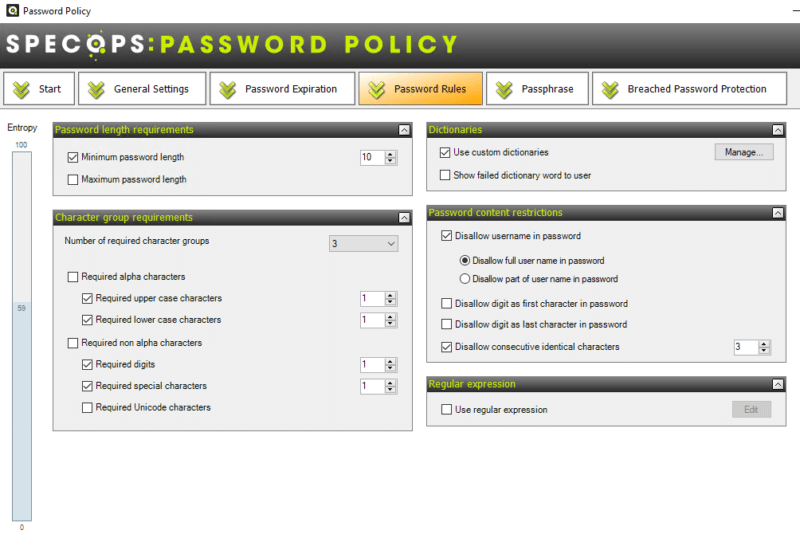
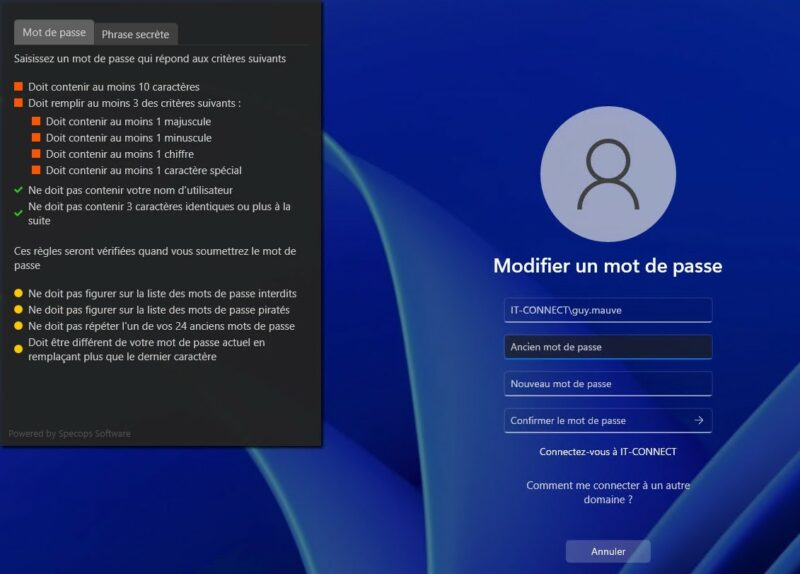
Passons à l'étape "Password Rules". Comme son nom l'indique, cette section va permettre de définir les règles pour les mots de passe, notamment la longueur, les types de caractères, etc.
L'option "Number of required character groups" sert à définir le nombre de types de caractères différents requis pour le mot de passe. Par exemple, si vous définissez "3", vous devez sélectionner au minimum trois types de caractères (la sélection s'effectue en dessous) et pour chaque type, vous pouvez indiquer le nombre minimal. Cela permet d'affiner très précisément.
Vous pouvez appliquer des restrictions au niveau du mot de passe : l'option "Disallow consecutive identical characters" égale à "3" empêche l'utilisation de 3 caractères identiques à la suite. Dans le même esprit, si l'on coche "Disallow full user name in password", l'utilisateur ne pourra pas utiliser son nom d'utilisateur dans le mot de passe.
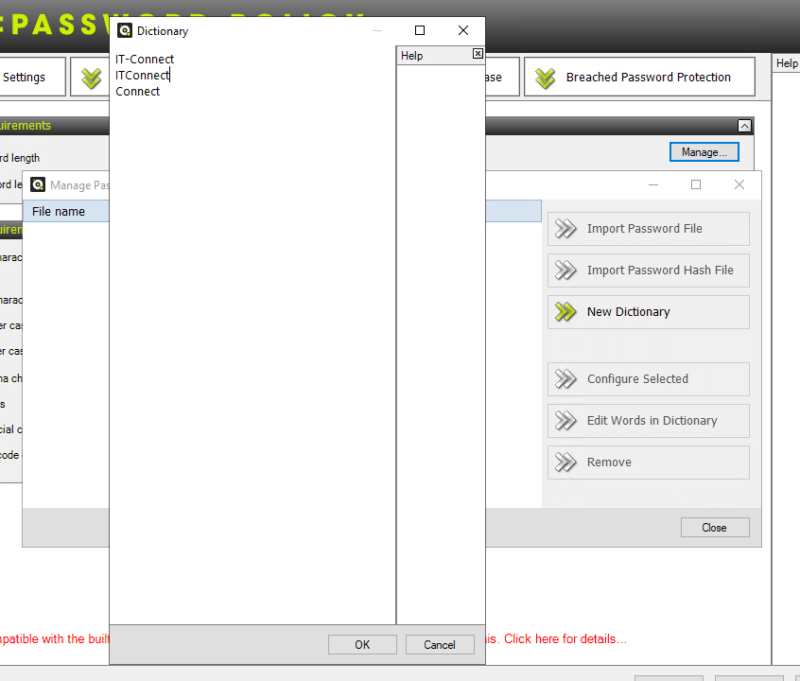
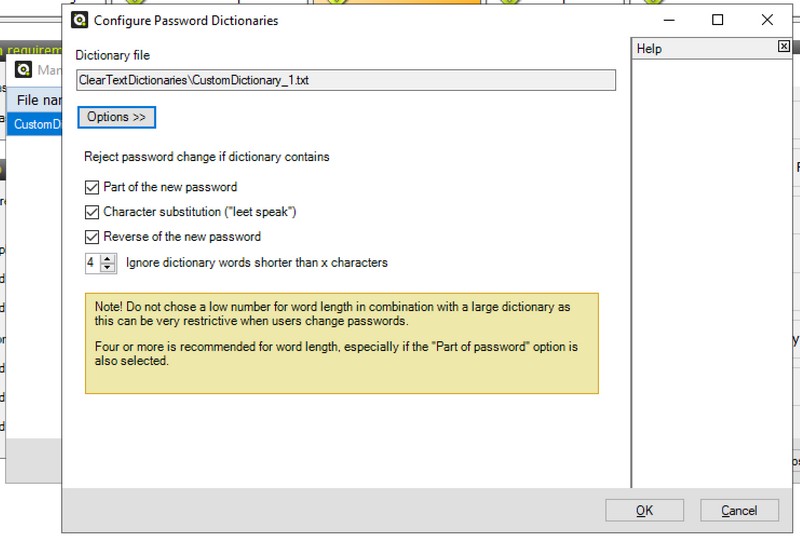
Il est à noter la présence de la section "Use custom dictionaries". En cliquant sur le bouton "Manage", on a la possibilité de créer un nouveau dictionnaire ou d'en importer un existant.
Par exemple, si l'on crée un nouveau dictionnaire soi-même, il faudra saisir les mots à interdire. La chose que l'on peut faire, c'est indiquer le nom de son entreprise pour empêcher que le nom soit utilisé dans les mots de passe. Indispensable selon moi, car c'est très très courant !
En spécifiant "Connect" en référence à "IT-Connect", cela va bloquer "Connect", "CONNECT", mais aussi "connect" et même "C0nnect" (un zéro à la place du "o"). Le logiciel va prendre en charge les variantes pour renforcer l'interdiction.
Si votre entreprise dispose déjà d'un dictionnaire de mots à bloquer, il est possible de l'importer très facilement grâce à l'option "Import Password File".
Chaque dictionnaire est configurable, notamment pour bloquer les caractères de substitution lors de l'utilisation d'un mot du dictionnaire. Cela correspond à l'option "Character substitution (leet speak)".
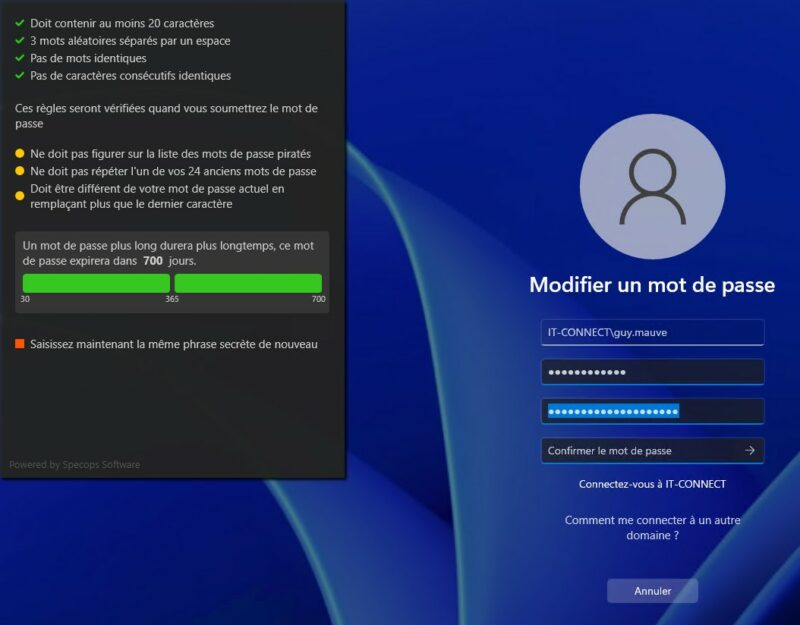
Poursuivons la configuration sur notre lancée : rendez-vous dans l'onglet "Passphrase". Dans le cas où l'utilisateur souhaite définir un mot de passe très long, on parlera plus de passphrase. Dans ce cas, une stratégie différente peut s'appliquer afin de choisir la longueur, les types de caractères que vous souhaitez, etc.
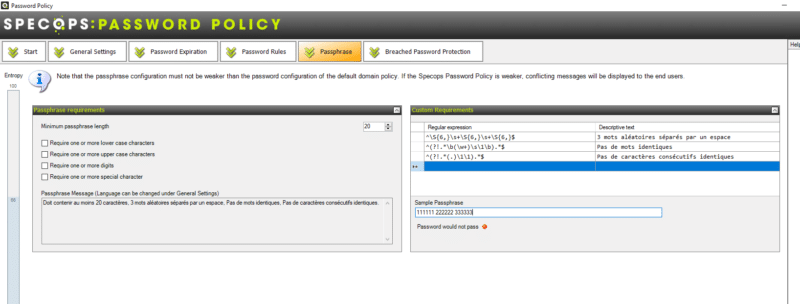
Le logiciel va très loin puisque l'on peut créer ses propres règles pour les prérequis, en s'appuyant sur des expressions régulières (RegEx).
Par exemple, si l'on veut imposer une passphrase composée de 3 mots de 6 caractères séparés par un espace, on utilisera cette RegEx :
^\S{6,}\s+\S{6,}\s+\S{6,}$
De la même façon, on peut bloquer les mots identiques :
^(?!.*\b(\w+)\s\1\b).*$
Ainsi que l'utilisation de caractères consécutifs identiques :
^(?!.*(.)\1\1).*$
Ensuite, on peut tester ses règles, au fur et à mesure de préférence, via la zone de saisie "Sample Passphrase". Grâce à nos règles, un utilisateur ne pourra pas utiliser "111111 222222 333333" ni "111111 111111 22222" comme passphrase.
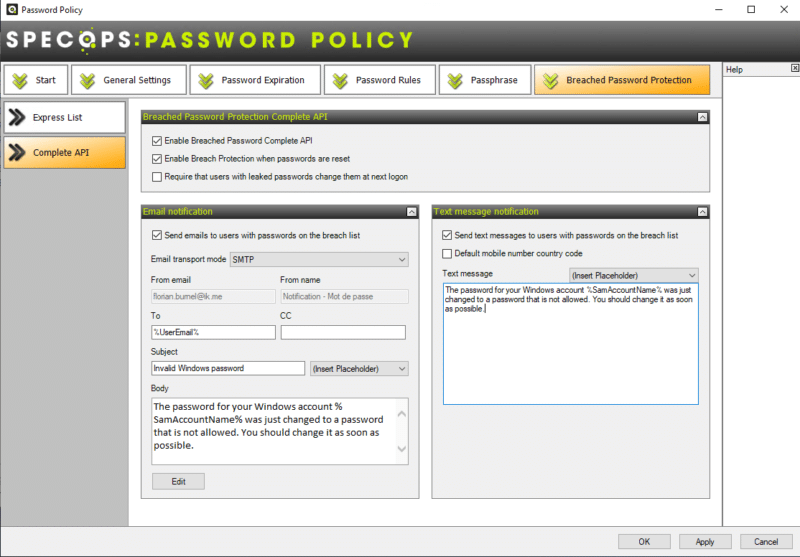
Terminons par la configuration de l'onglet "Breached Password Protection". Grâce à cette fonctionnalité (vendue en complément sous le nom de "Breached Password Protection"), le logiciel SPP va comparer les mots de passe définis par les utilisateurs avec les mots de passe contenus dans les fuites de données connues ou collectés par Specops. On parlera de "leaked password", sans oublier les mots de passe collectés par Specops via les serveurs honeypots. Pour effectuer cette comparaison, le logiciel s'appuie sur le hash des mots de passe, car il ne connaît pas le mot de passe des utilisateurs.
Cette section se découpe en deux zones :
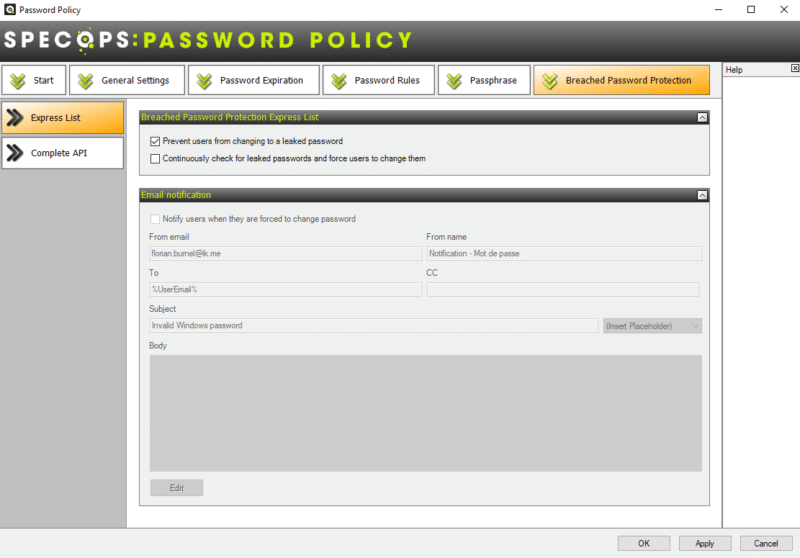
Express List : l'analyse est effectuée à partir de la base de mots de passe téléchargée en local (environ 5 Go) sur le serveur et qui contient environ 750 millions de mots de passe (mise à jour tous les deux mois).
Complete API : l'analyse est effectuée via API sur la base de mots de passe hébergée en ligne et qui contient 2,5 milliards de mots de passe (mise à jour quotidienne). Par exemple, la base intègre les mots de passe présent dans la fuite de données qui a touchée Fortinet récemment.
Dans le cas où un mot de passe est trouvé dans une fuite de données, l'utilisateur sera averti afin qu'il puisse changer son mot de passe. Cette notification sera envoyée par e-mail, ou par SMS (gratuit/inclus). Le texte de la notification sera en français puisque c'est le message configuré dans Specops qui est repris.
Il y a une option qui permet de forcer la réinitialisation du mot de passe s'il est trouvé dans une fuite ("Continuously check for leaked passwords and force users to change them"). C'est intéressant, mais cela peut poser des problèmes de connexion aux utilisateurs en télétravail (notamment à cause du cache local des identifiants).
Comme je le disais, les notifications sont personnalisables au niveau du texte. Pour envoyer la notification par e-mail, le logiciel reprend l'adresse e-mail de l'utilisateur au niveau de l'Active Directory. Idem pour le numéro de téléphone afin d'envoyer le SMS (ce qui nécessite d'avoir un annuaire bien renseigné).
Nous sommes à la fin de l'assistant de création d'une nouvelle stratégie ! Cliquez sur "OK" pour sauvegarder et nous allons tester le bon fonctionnement de notre politique.
Comme vous avez pu le constater, l'interface de ce logiciel de chez Specops est en anglais, mais la bonne nouvelle c'est que les notifications sont en français. Pour la partie configuration en anglais, cela ne devrait pas vous effrayer en tant que sysadmin.
IV. Tester la politique Specops Password Policy
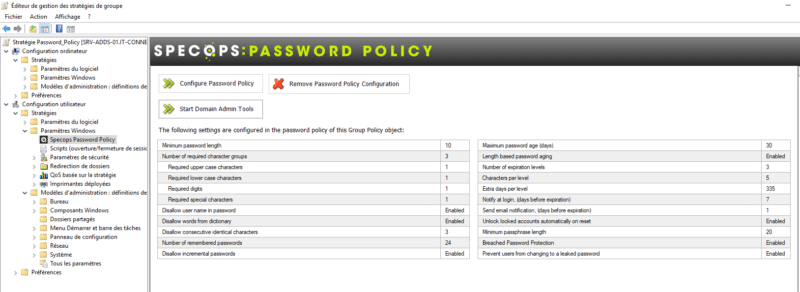
Avant de passer aux tests, je tenais à vous préciser que le contenu de la stratégie SPP est visible également à partir de l'Editeur de gestion des stratégies de groupe. Il suffit de modifier la GPO et d'accéder à l'emplacement suivant : Configuration utilisateur > Stratégies > Paramètres Windows > Specops Password Policy.
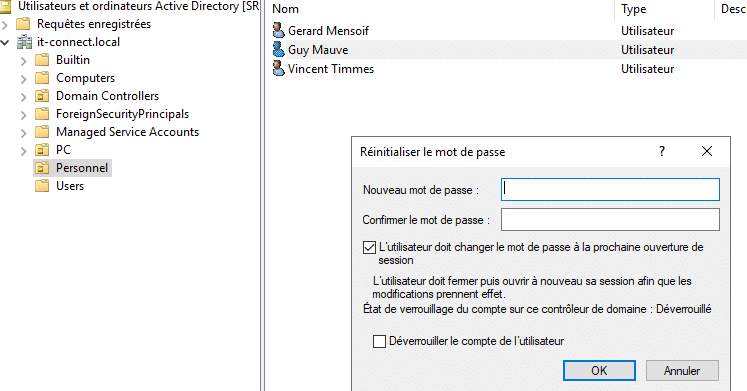
Faisons un test. On va réinitialiser le mot de passe de l'utilisateur "Guy Mauve" à partir du contrôleur de domaine. Bien sûr, la politique Specops que j'ai créée précédemment s'applique sur cet utilisateur. Il suffit de faire un clic droit sur le compte puis de cliquer sur "Réinitialiser le mot de passe". On saisit un mot de passe, par exemple "Connect123!".
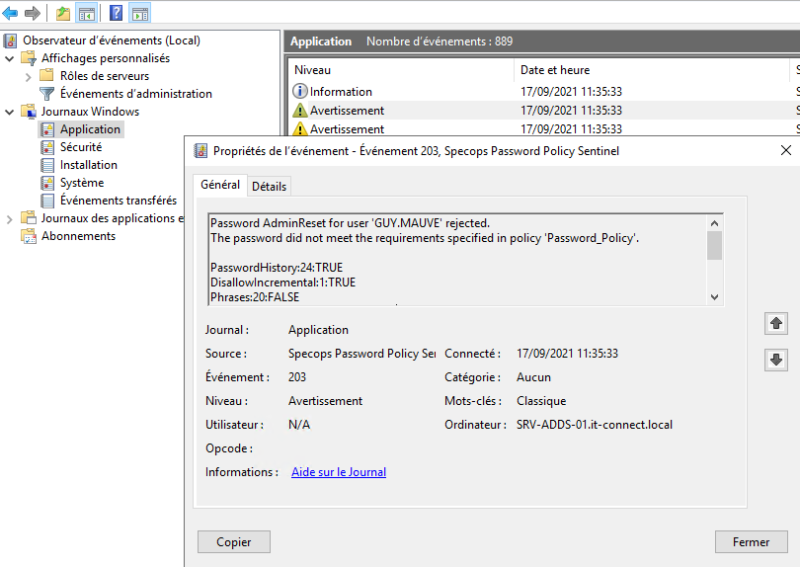
On obtient alors une erreur, car le mot de passe ne respecte la politique. Si l'on regarde l'observateur d'événements du serveur (Journaux Windows > Application), on peut voir qu'il y a des événements générés par Specops Password Policy.
Cet échec de réinitialisation de mot de passe a créé un événement : "Password AdminReset for user 'GUY.MAUVE' rejected". Ensuite, on sait que notre mot de passe ne respecte pas les prérequis de la politique "Password_Policy" et en regardant le détail, on peut savoir quels sont les prérequis non respectés.
Si je recommence avec un mot de passe qui respecte tous les prérequis, cela va fonctionner bien entendu.
Maintenant, je vais basculer sur mon poste client où j'ai déployé le client Specops Password Policy... Je me connecte avec l'utilisateur "guy.mauve" et je décide de changer le mot de passe de ce compte (CTRL+ALT+SUPPR > Modifier un mot de passe).
Voici l'écran qui s'affiche :
Un panneau latéral indique quels sont les prérequis à respecter que ce soit pour le mot de passe ou la passphrase (phrase secrète). Lorsque l'utilisateur saisit son mot de passe, les prérequis changent d'état dynamiquement pour que l'utilisateur sache d'où vient le problème si le mot de passe n'est pas accepté.
Note : dans le cas où le client Specops Password Policy n'est pas installé sur le poste client, cela va fonctionner malgré tout. Cependant, le panneau latéral avec les indications ne s'affichera pas.
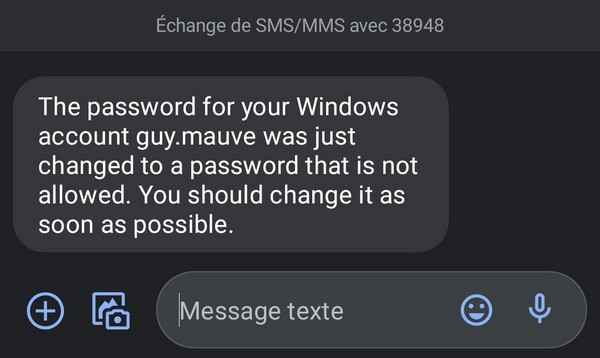
Dans le cas où l'utilisateur définit un mot de passe qui est repéré dans la base des mots de passe compromis, une notification est envoyée et un événement ajouté au journal (Observateur d'événements > Journaux des applications et des services > Specops).
Voici par exemple le SMS que j'ai reçu puisque c'est mon numéro qui est renseigné dans la fiche Active Directory de l'utilisateur "guy.mauve". Je vous rappelle que le message peut être défini en français, il suffit de modifier le texte de la notification au sein de la politique.
Quoi qu'il en soit, cette démonstration dans la peau d'un utilisateur permet de se rendre compte de l'utilité du client Specops Password Policy sur les postes et du système de notifications.
V. Analyse des résultats avec Specops Password Auditor
Après avoir mis en place Specops Password Policy, il est intéressant de relancer une nouvelle analyse avec Specops Password Auditor pour voir l'impact de cette nouvelle configuration. Si vous aviez de nombreux mots de passe vulnérables avant la mise en œuvre de SPP, les choses ont dû évoluer dans le bon sens désormais.
Si vous souhaitez découvrir Specops Password Auditor (logiciel gratuit), je vous invite à regarder ma vidéo à ce sujet.
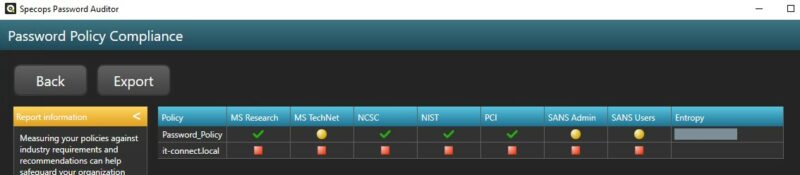
L'analyse effectuée par Specops Password Auditor suite à la mise en place de Specops Password Policy doit donner des résultats satisfaisants : pas d'utilisateurs sans mot de passe, pas de mots de passe compromis, etc.
Si l'on regarde la conformité de notre politique "Password_Policy" vis-à-vis des recommandations des différents organismes de sécurité, on peut voir qu'elle s'en sort bien également.
Avant de mettre en œuvre SPP, je vous recommande d'effectuer une analyse avec Specops Password Auditor afin de voir la valeur ajoutée de SPP après quelque temps d'utilisation.
Cette découverte de Specops Password Policy touche à sa fin ! N'hésitez pas à tester le logiciel de votre côté et à poster un commentaire si vous avez des questions.
Je vous laisse avec le lien de téléchargement qui vous permettra d'obtenir une version d'essai de 45 jours tout en sachant que le coût de la licence dépend du nombre d'utilisateurs à protéger avec Specops Password Policy :
Microsoft a remis en ligne son outil PC Health Check qui permet de vérifier si votre machine est compatible avec Windows 11. Cette fois-ci, il fournit des informations précises dans le cas où votre machine ne respecte pas un ou plusieurs prérequis.
Lorsque Microsoft a annoncé Windows 11, un outil avait été mis en ligne pour nous permettre de vérifier si notre machine était compatible avec son futur système d'exploitation. Le problème, c'est que si la machine était incompatible, le logiciel n'indiquait pas pourquoi. Autrement dit, il n'était pas très utile et heureusement que des développeurs indépendants ont publié un autre outil en seulement quelques heures : WhyNotWin11.
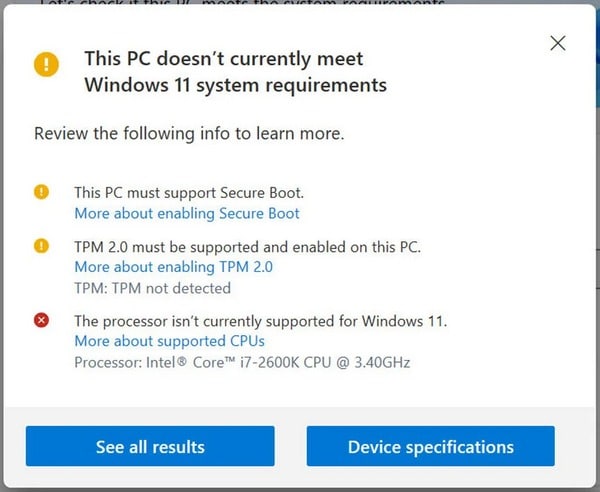
La communauté a très largement critiqué cet outil, à juste titre d'ailleurs, alors la firme de Redmond a pris le temps de développer une nouvelle mouture. Cette semaine, Microsoft a - discrètement - mis en ligne une nouvelle version de son outil PC Health Check. Cette fois-ci, l'outil explique pourquoi la machine n'est pas compatible avec Windows 11, si c'est le cas.
Par exemple, c'est précisé si le processeur n'est pas supporté par Windows 11, mais aussi s'il y a un problème au sujet de la puce TPM 2.0. Si l'outil détecte bien la puce TPM, il suffira simplement de l'activer dans le BIOS de votre machine. Pour chaque élément, un lien est intégré pour permettre à l'utilisateur d'obtenir des informations complémentaires.
C'est l'heure de faire une dernière vérification avant la sortie officielle de Windows 11, prévue le 5 octobre prochain. Vous pouvez télécharger l'outil en suivant ce lien (tout en bas de la page) : Télécharger PC Health Check
Alors qu'Apple vient tout juste de dévoiler iOS 15, la nouvelle version de son système d'exploitation pour mobile, un chercheur en sécurité est déjà parvenu à contourner l'écran de verrouillage !
Il s'appelle Jose Rodriguez et il est énervé contre Apple. Pour le faire savoir, il a publié une vidéo sur YouTube où il montre comment il est parvenu à contourner l'écran de verrouillage d'iOS 15. Pour cela, il a exploité Siri et la fonction VoiceOver afin d'accéder aux notes de l'appareil et de les envoyer par SMS : un enchaînement astucieux. Le jour de la sortie d'iOS 15, ce n'est pas une bonne publicité pour Apple !
Mais, pourquoi est-il énervé ? Selon lui, Apple lui doit de l'argent ou en tout cas, la firme à la pomme ne s'est pas montrée suffisamment généreuse. Il a remonté un bug de sécurité dans le cadre du programme Bug Bounty d'Apple et il a reçu une récompense de 5 000 dollars. Une récompense injuste, car pour des problèmes de sécurité moins graves, la prime serait de 25 000 dollars. Son travail n'aurait pas été récompensé à sa juste valeur.
D'après lui, Apple n'aurait pas corrigé entièrement le problème de sécurité et ne lui aurait pas demandé de vérifier si le correctif était efficace. Aucune référence CVE n'est communiquée à ce sujet.
Quelques nouveautés d'iOS 15...
Avec iOS 15, Apple a introduit de nouvelles fonctionnalités, notamment "LiveText" qui s'appuie sur l'OCR (reconnaissance de caractères) pour vous permettre de récupérer facilement le texte d'une carte de visite, d'un plan, d'une page de journal, etc.
Par ailleurs, l'application "Concentration" vous permettra de vous concentrer sans être perturbé par les notifications de votre iPhone. Lorsque ce mode est actif, seulement les contacts et les applications autorisées pourront émettre une notification sur votre appareil, tout en sachant que le mode peut être activé automatiquement à une heure précise.
Enfin, Apple a amélioré FaceTime en intégrant SharePlay, une fonctionnalité qui permet de partager son écran à des amis à distance dans le but de partager du contenu, comme une vidéo, par exemple. Mais ce n'est pas tout ! Désormais, FaceTime offre la possibilité de créer un lien pour inviter des contacts à rejoindre un appel vidéo, que ce soit des personnes avec un iPhone ou un iPad, et même des personnes avec un appareil sous Android (dans ce cas, la connexion s'effectue via un navigateur).