Les entreprises sont de plus en plus nombreuses à refuser de payer la rançon demandée par les cybercriminels lorsque les données sont chiffrées par un ransomware, et c'est tant mieux ! Le nombre de victimes qui paient la rançon est passé sous la barre des 30% !
Plus de 7 victimes sur 10 refusent de payer la rançon
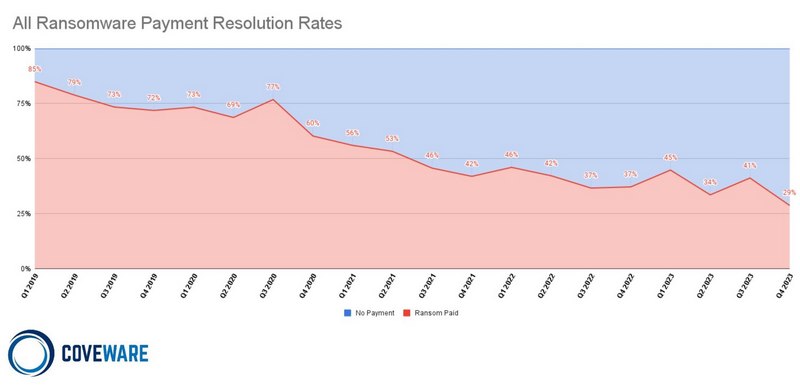
Au début de l'année 2019, on estime que 85% des entreprises payaient la rançon lorsqu'elle subissait une attaque par ransomware. À partir de fin 2020, ce taux de paiement a commencé à baisser... Pour atteindre 46% à la fin du premier semestre 2021.
Le rapport mis en ligne par les chercheurs en sécurité de chez Coveware confirme la tendance : dans plus de 7 cas sur 10, l'entreprise refuse de payer la rançon réclamée par les pirates informatiques. En effet, à la fin du troisième trimestre 2023, le taux de paiement était de 29% : c'est la première fois qu'il passe sous la barre des 30%. Nous pouvons même parler de "record".
Par ailleurs, Coveware affirme que le montant des rançons diminue également. En moyenne, au dernier trimestre 2023, le montant d'une rançon s'élevait à 568 705 dollars, soit une baisse de 33% en comparaison du trimestre précédent. Ceci s'explique par le fait que les cybercriminels ciblent davantage les PME (231 employés, en moyenne), souvent moins bien protégées, et donc la rançon demandée est moins élevée.
À l'heure actuelle, les cybercriminels peuvent toujours mettre à la pression aux victimes grâce à la double extorsion, puisque si la rançon n'est pas payée, ils peuvent diffuser des données, potentiellement sensibles, sur le Dark Web.
Par ailleurs, ce rapport nous apprend qu'au dernier trimestre 2023, les gangs de ransomware les plus actifs étaient Akira (17%), BlackCat (10%) et LockBit 3.0 (8%).
Malgré tout, c'est une bonne nouvelle, car cela fait des mois que la communauté cyber et les autorités demandent aux victimes de ransomware de ne pas payer la rançon ! Le message semble être - enfin - entendu.
Comment expliquer ce changement de comportement ?
D'après Coveware, les entreprises ont perdu confiance envers les cybercriminels, car même lorsque la rançon est payée, il arrive que les données soient divulguées, ce qui ne fait qu'augmenter la valeur du préjudice.
Surtout, les organisations semblent mieux préparées et sensibilisées aux risques que représentent les cyberattaques. Ceci veut dire que même s'il y a une intrusion et que les données sont chiffrées, les entreprises sont de plus en plus nombreuses à être en mesure de restaurer leur infrastructure et de récupérer tout ou partie de leurs données sans avoir besoin de la clé de déchiffrement. Cela change la donne, car sinon le fait de payer la rançon pouvait être une question "de vie ou de mort" pour l'entreprise et cela pouvait être son seul espoir de récupérer ses données.
Même s'il y a encore une marge de progrès importante pour de nombreuses organisations (dans plus de 25% des cas, le vecteur d'attaque initial, c'est la compromission d'un accès RDP !), et que la cybersécurité est un combat de tous les jours, la situation évolue dans le bon sens.
L'automatisation est aujourd'hui devenue incontournable dans les systèmes d'information. La mouvance DevOps n'y ai pas étrangère bien entendu, et bon nombre d'éditeurs se sont mis sur ce créneau, avec pour objectif d'améliorer nos flux de travail ou nos processus.
Donc, est-ce réservé aux seuls ingénieurs DevOps ou Cloud? Que nenni! L'automatisation peut aussi faciliter la vie de l'administrateur système/réseau en facilitant les tâches courantes ou en préparant les tâches de déploiement.
Rundeck répond parfaitement à cette problématique et du haut de ses 12 ans d’existence, le projet est bien mûr et prêt à vous rendre service. Existant en version communautaire et open source ou en version pro, il s'adapte à tous les besoins et n'est pas très gourmand, il trouvera donc forcément une place dans votre infra !
Ce logiciel est capable d'exécuter plusieurs tâches sur plusieurs serveurs, comme des commandes, des scripts, des copies de fichiers, etc... Le tout à la volée ou de manière programmée.
Dans ce tutoriel, nous allons déployer un serveur Rundeck et voir comment s'en servir pour administrer des serveurs Linux. Dans un prochain article, nous verrons comment gérer des serveurs Windows avec Rundeck.
Déjà un bon point : Rundeck s'installe de bien des façons. Tout le monde y trouvera son compte, car il peut tout autant se déployer via un conteneur Docker que s'installer sur Ubuntu, CentOS ou même Windows!
Je ne vais détailler ici que l'installation sous Debian. Les Linuxiens adapteront à leur distribution et les Windowsiens ne seront pas perdus par l'installation somme toute classique. Pour ceux qui le souhaitent, le déploiement est également possible depuis un JAR.
Au niveau des prérequis, il vous faudra à minima une machine avec 2 CPUs, 4 Go de RAM et 20 Go de disque.
Tout d'abord, sur notre Debian tout frais, comme d'habitude, on prépare l'installation :
apt-get update && apt-get upgrade -y
Si vous êtes sur Windows, il faut récupérer le package d'installation. Il est disponible ici : www.rundeck.com/downloads . Attention, il faudra fournir à minima un mail. Les paquets Deb et RPM sont également disponibles sur cette même page pour ceux qui préfèrent.
Je vais détailler l'installation via les dépôts, qui vous permettront des mises à jour facilitées.
Avant de faire l'installation à proprement parler, et Rundeck tournant sous Java, installez la version 11 d'OpenJDK :
apt-get install openjdk-11-jdk-headless -y
Si vous êtes sous Debian avec un user et un root, installez également le paquet sudo .
apt-get install sudo -y
Maintenant que tout est OK, passons à l'installation des dépôts de Rundeck, un script est fourni, pour ceux qui sont sous d'autres distributions, vous trouverez toute la doc ici :
Note : sur la documentation, faites attention à bien sélectionner l'onglet "Community" car par défaut les commandes et guides sont donnés pour la version pro
Une fois ceci fait, l'installation peut se faire comme n'importe quelle application :
apt-get install rundeck
L'installation n'est pas très longue. Une petite subtilité toutefois pour les utilisateurs de Debian (et sûrement Ubuntu), contrairement à ce qu'indique la doc, le premier démarrage doit impérativement se faire via Initd, sinon, vous aurez un message d'erreur :
/etc/init.d/rundeckd start
Une fois démarré, ajoutez-le aux services qui démarrent avec le système !
systemctl enable rundeckd
Voilà, votre serveur Rundeck est installé !
III. Configuration de Rundeck
À partir de là, votre serveur devrait répondre sur le port 4440 à son adresse IP.
En fonction de la méthode d'installation, il est possible que ce ne soit pas le cas.
Si vous êtes dans cette situation, pas de panique, il existe une solution. Pour les autres, si vous comptez accéder à votre serveur depuis une autre machine, il peut être également intéressant de faire les modifications.
Tout d'abord, le premier fichier à configurer est "framework.properties" qui se situe dans le répertoire "/etc/rundeck". L'élément qui nous intéresse est tout au début de ce fichier :
Changez "localhost" par le nom de votre serveur, au besoin, vous pouvez également changer le numéro de port. Enfin, et c'est le plus important, changez l'URL en inscrivant ici votre adresse IP (ou nom d'hôte si vous avez une résolution DNS ou Netbios au sein de votre réseau) à la place de localhost dans la ligne "framework.server.url".
Ensuite, le second fichier à modifier est celui nommé "rundeck-config.properties" qui se situe dans le même répertoire.
La ligne qui nous intéresse ici est celle nommée "grails.serverURL", modifiez encore une fois "localhost" par votre adresse IP ou nom d'hôte.
Enregistrez et redémarrez Rundeck, vous devriez accéder à la page web.
Le petit défaut de Rundeck est qu'il est long à démarrer. Donc si vous n'accédez pas immédiatement à la page après le redémarrage cela ne veut pas forcément dire qu'il ne fonctionne pas. Pour en avoir le cœur net, vous pouvez afficher le contenu de /var/log/rundeck/service.log. Tant que ce fichier n'affichera pas "Grail application running at http://.......", c'est que votre serveur n'est pas prêt!
Viens maintenant le temps de se connecter! Les logins par défaut sont admin/admin, bien entendu je vous conseille vivement de les changer si vous êtes en production...
IV. Création du premier projet
Rundeck fonctionne sous forme de projet. Chacun des projets peut avoir sa propre liste de nœuds, ses propres utilisateurs, se propres jobs, etc. L'avantage ici est donc de pouvoir scinder la gestion auprès de plusieurs équipes, ou pour des suivis ou projets clients différents par exemple.
Autre avantage, les projets sont archivables, et peuvent être importés sur un autre serveur. Cela facilite grandement les migrations ou les reprises après sinistre.
La première étape est donc de créer un projet, au sein duquel nous importerons nos serveurs. Cliquez sur le bouton "Create New Project" :
Note : si vous souhaitez accéder à la doc officielle, vous pouvez le faire d'ici depuis le bouton "Docs". Tout à droite, vous avez même accès à une sorte de tuto expliqué (en anglais) pour vous familiariser avec l'outil.
La création du projet va demander quelques informations. Tout d'abord bien entendu le nom et la description du projet, un label peut éventuellement être ajouté :
Vous l'aurez compris, je vais prendre pour exemple un déploiement de stack LAMP pour Linux.
Viens ensuite des options. Ces options sont définies au niveau projet. Cela veut dire qu'il est possible ensuite d'aller contre, disons que ce sont les options par défaut de votre projet.
L'onglet "Execution History Clean" permet de mettre en place une politique de rétention d’historique d'exécution. Par défaut, toutes les tâches exécutées sont inscrites dans l'historique pour 60 jours, avec un nombre de 50 maximum. La tâche par défaut s'exécute tous les jours à midi. Si ces valeurs ne vous conviennent pas, il suffit de cocher la case et de choisir les vôtres.
L'onglet "Executionmode" va vous permettre de choisir d'activer ou de désactiver l'exécution des tâches, et cela pour deux méthodes : programmées ou manuelles. Vous allez pouvoir entre autres ne permettre que l'exécution des tâches manuelles qu'à partir de 24 heures après la création du projet, ou au contraire la désactiver.
L'onglet "User interface" vous permet de paramétrer certains aspects de l'interface utilisateur comme afficher ou non le readme du projet, dérouler automatiquement les groupes de travaux, etc.
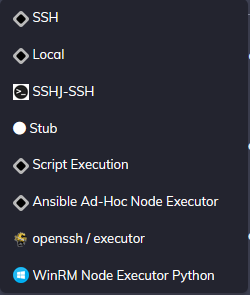
L'onglet "Default Node Executor" est relativement important. Le Node Executor est responsable de l'exécution des commandes et des scripts sur les nœuds distants. Vous devrez donc choisir quel "exécuteur" de commandes utiliser. Au choix, vous pourrez utiliser SSH, WinRM via python, SSHJ (pour Java) ou même Ansible ! Il est aussi possible d'utiliser son propre exécutable (Script Execution).
Pour ma part, je laisse SSH, car c'est ce qui me convient le mieux. Je n'ai pas encore testé à ce jour l'utilisation conjointe d'Ansible et Rundeck, pour les nœuds Windows, je préfère l'administration via SSH depuis que cela est rendu possible justement pour avoir les mêmes méthodes d'accès. Si vous êtes en full Linux ou hybride Linux/Windows, je vous conseille SSH, si vous êtes en full Windows, WinRM peut peut-être mieux convenir.
A noter que l'édition Entreprise de Rundeck permet l'utilisation de plus de méthodes, comme par exemple PowerShell.
Vous pourrez indiquer à Rundeck l'endroit où vous souhaitez que les fichiers de clés SSH ou de mot de passe soient stockés. Par défaut, ils le sont dans /var/lib/rundeck/project/nomduprojet/keys.
Idem pour le "Default File Copier", vous aurez le choix entre plusieurs "moteurs" pour envoyer des fichiers sur les hôtes distants. Par défaut, SCP est choisi, celui-ci étant basé sur SSH, les mêmes options que précédemment vous sont proposées.
Une fois vos choix faits, il ne reste qu'à cliquer sur "Create" !
V. Ajout de la première machine
D'office après la création de votre projet, Rundeck vous affiche la page "Edit Nodes" pour ajouter vos nœuds.
Cet ajout se fait par lecture d'un ficher en XML, JSON ou en YAML, disponible en local ou via une URL, ou encore sur un stockage S3 et même importées depuis Ansible. Cette source se déclare via le bouton "Add a new node source".
Je choisis un fichier local, je clique donc sur "File" et choisis le format YAML dans la liste déroulante (vous n'êtes pas obligé bien entendu).
Au niveau de la ligne "File Path", j'indique le chemin où je souhaite "ranger" mon fichier. Ce fichier doit pouvoir être lu et écrit par l'utilisateur rundeck, créé au moment de l'installation. À noter qu'aucun dossier home n'est créé pour ce dernier, je vais donc le créer, mais vous pouvez bien sûr le mettre où vous voulez.
Viennent ensuite les options, comme la possibilité de générer directement le fichier en question s'il n'existe pas (ce qui est mon cas) et la possibilité d'intégrer le serveur Rundeck lui-même à la liste des nœuds. Dans mon cas, cela n'as pas vraiment de sens; si je crée un autre projet pour gérer la conformité et la mise à jour de tous mes serveurs, j'aurais pu en avoir besoin par exemple. Je le laisse ici pour avoir un exemple d'entrée dans ce fichier, si vous débutez, je vous conseille de faire de même pour avoir une idée de la syntaxe et des champs attendus.
Je ne coche pas "Require File Exists" vu que je vais le générer, mais je coche la case "Writable" pour pouvoir ajouter les nœuds depuis Rundeck directement. Si cette cas n'est pas cochée, l'ajout des nœuds devra se faire via SSH ou en console directement sur le fichier, si vous préférez séparer les permissions.
Une fois les infos remplies, je sauvegarde sur cet écran ET sur l'écran suivant pour que les changements soient pris en compte. Vous remarquerez que, par défaut, une source locale est présente, elle représente le serveur Rundeck lui-même. Comme annoncé plus tôt, cette source ne m'est pas nécessaire pour ce projet, je la supprime donc.
Nous nous retrouvons avec notre fichier YAML (ou le format choisi) somme seule source. Sur ce même écran, il est possible de cliquer sur l'onglet "Edit" pour ajouter directement mes nœuds (seulement si vous avez rendu le fichier inscriptible!). Une fois dans l'onglet, un clic sur "Modify" vous permettra de découvrir le fichier tel qu'il existe au départ :
Si comme moi vous avez choisi le YAML, rappelez-vous bien que ce langage est très strict sur l'indentation! Si on décortique :
nodename : nom du nœud tel que vous souhaitez qu'il apparaisse dans Rundeck
hostname : nom de l'hôte ou IP
osVersion : Version du système
osFamily : type de système
osArch : architecture
description : comme son nom l'indique
osName : nom de l'OS
username : nom de l'utilisateur sous lequel seront effectuées les actions, très important
tags : suite de mots clés qui vous permettront de classifier vos nœuds afin de les retrouver plus facilement lors d'une recherche
Basé sur ce modèle, je vais donc insérer mon nouveau nœud, qui est un serveur Debian :
srv-dev: nodename: srv-dev hostname: 192.168.1.44 osVersion: 5.10.0-27-amd64 osFamily: unix osArch: amd64 description: Serveur de developpement osName: Debian username: rundeck tags: dev linux
J'enregistre et voilà mon nœud ajouté. Mais comment fait Rundeck pour s'y connecter?
VI. Ajout de la clé SSH
Comme je me connecte en SSH, le plus simple et le plus secure est d'ajouter une clé pour l'utilisateur root que Rundeck pourra utiliser. Pour cela, il faut en premier lieu générer la clé, puis ajouter la clé publique sur mon Debian dans les clés autorisées. Pour faire tout cela, plusieurs choix : PuTTYGen à partir d'un hôte tiers ou OpenSSH/OpenSSL depuis l'hôte Rundeck (via le terminal).
Le résultat est le même. Personnellement, je passe par PUTTYGen et un hôte tiers, car je supprime les fichiers de clé après l'opération, de sorte que la clé pour Rundeck ne se balade pas partout. C'est juste un point de vue personnel, pas une consigne.
Donc, sur mon PC Windows, je lance PUTTYGen et je génère une paire de clés. Pour ceux qui ne l'ont jamais utilisé, il suffit de bouger la souris dans le cadre supérieur jusqu’à ce que la barre de progression soit complète.
Une fois la clé générée, son empreinte sera affichée en haut, c'est cette empreinte qu'il faudra copier :
Comme indiqué au-dessus de la clé, il faut ajouter cette ligne (car oui, c'est en une seule ligne, et faites attention à l'ascenseur à droite!) dans le fichier "authorized_keys" dans le dossier ".ssh" de l'utilisateur concerné sur le serveur cible, ici root sur mon srv-dev.
Donc, connexion en SSH sur ce serveur, puis on bascule en root et on vérifie le dossier de l'utilisateur :
Pas de dossier ssh ici, on va donc le créer, n'oubliez pas le point devant car il s'agit d'un dossier caché :
mkdir .ssh
Et, à l'intérieur de ce dossier, on va créer le fichier authorized_keys et coller le texte issu de PUTTYgen :
nano .ssh/authorized_keys
Je ne vous mets pas la ligne ici, car cela n'a pas d’intérêt et qu'elle est très longue. En revanche, elle se termine par rsa-key-20240123. Cette chaine à la fin est une remarque qui peut être modifiée, je vous conseille de mettre quelque chose qui vous rappelle que cette clé est utilisée pour Rundeck, cela facilitera les choses lors du changement, surtout si vous utilisez vous-même une clé pour vous connecter.
Note : je part du principe que vous utilisez une clé par usage, c'est à dire une clé pour vos connexions en tant qu'admin et une différente pour Rundeck (et éventuellement une autre pour votre collègue). Il est fortement déconseillé d'utiliser la même clé!
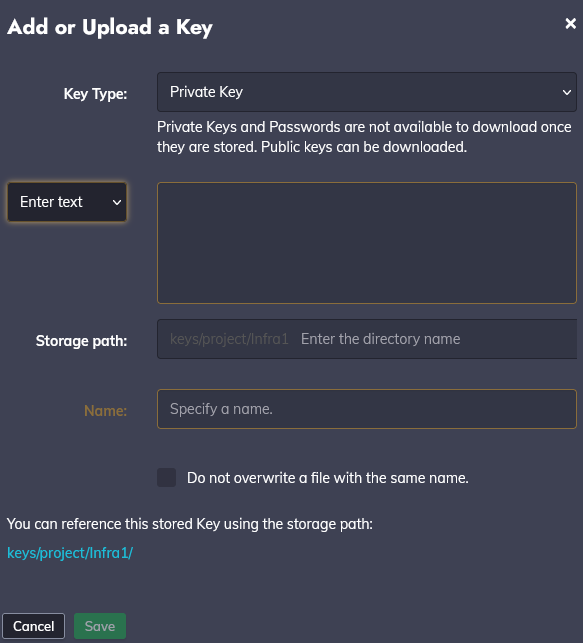
Enregistrez le fichier et fermez. Il faut maintenant donner la clé privée à Rundeck. Pour cela, sur l'interface d'administration, cliquez tout en bas à gauche sur "Project Settings" puis sur "Key Storage".
Cliquez sur "Add or Upload a Key" pour ajouter votre clé, ce qui vous amène à l'écran suivant :
Il est possible ici de copier/coller le texte de la clé privée ou uploader le fichier directement. Je vais choisir la deuxième solution. De retour sur PUTTYgen, cliquez sur "Conversions" puis sur "Export OpenSSH key". PUTTYgen va vous avertir et vous demander de confirmer la création de la clé sans passphrase. Si vous souhaitez en ajouter une, sachez que sshpass sera nécessaire sur le serveur Rundeck. Enregistrez votre clé privée et, sur l'écran ci-dessus, déroulez la liste sur "Upload File" et allez chercher votre clé privée.
Faites très attention au chemin en bleu sur cette fenêtre et copiez-le. En effet, c'est ce chemin qu'il faudra déclarer dans le fichier des nœuds pour que Rundeck sache quelle clé utiliser. Pour moi, c'est ce chemin :
keys/project/Infra1/key_dev
Enregistrez, votre clé a été ajoutée. Retournez dans "Project Settings" puis cliquez sur "Edit Nodes". Vous retrouvez le fichier YAML crée précédemment, cliquez sur "Modify" pour ajouter l'entrée suivante à la fin du bloc concernant votre nœud (attention à l'indentation !):
ssh-key-storage-path: keys/project/Infra1/key_dev
Sauvegardez le fichier. Pour tester le bon fonctionnement, nous allons utiliser la fonction commande, qui permet d'exécuter une commande sur un ou plusieurs nœuds du projet. Pour cela, cliquez sur "Commands" dans le menu de gauche, ce qui vous amènera à cette fenêtre :
La première chose à renseigner, c'est le nœud (ou le groupe de nœuds). Ici, soit vous rentrez directement le nom du nœud en question, soit vous entrez "tag:" suivi du tag pour sélectionner les nœuds, soit vous utilisez une regex pour choisir plusieurs nœuds selon leur nom (par exemple name: srv.* sélectionnera tous les nœuds dont le nom commence par srv). Plus d'information sur les filtres sur la documentation officielle.
Ici, je n'ai qu'un seul nœud, donc je vais taper directement son nom, puis à la ligne de commande, je vais simplement faire un hostname :
L'hôte m'a bien répondu, il est temps de passer à la suite.
VII. Création du job
Dans un projet Rundeck, il est question de Job pour les actions faites sur les nœuds, nous pourrions appeler cela des playbooks. Ces jobs vont inclure une suite d'actions qui seront effectuées de manière séquentielle sur un ou plusieurs nœuds, en fonction de ce que vous choisissez.
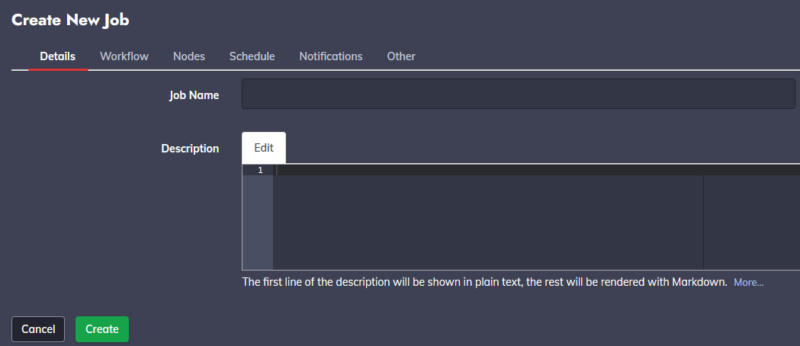
Pour créer un job, cliquez sur "Jobs" dans le menu de gauche, puis sur "Create a New Job", ce qui vous amènera à la fenêtre suivante, sur l'onglet "Details" :
Ici vous l'aurez compris, il s'agit de donner un nom au job et une description, ces deux éléments s'afficheront sur la page des jobs. Remplissez les champs et rendez-vous dans l'onglet "Workflow".
C'est ici que tout se joue. Je ne pourrais pas en un article vous montrer toute l'étendue de l'outil tellement il existe de possibilités différentes! La partie "Options" par exemple vous permettra de définir des options qui pourront être réutilisées dans les différentes étapes de votre job, comme par exemple la date du jour, ou un mot de passe afin qu'il ne soit pas stocké en dur, mais passé à chaque exécution, etc. Vous trouverez l'ensemble de ces possibilités sur la documentation. Pour notre exemple, je ne vais pas en utiliser.
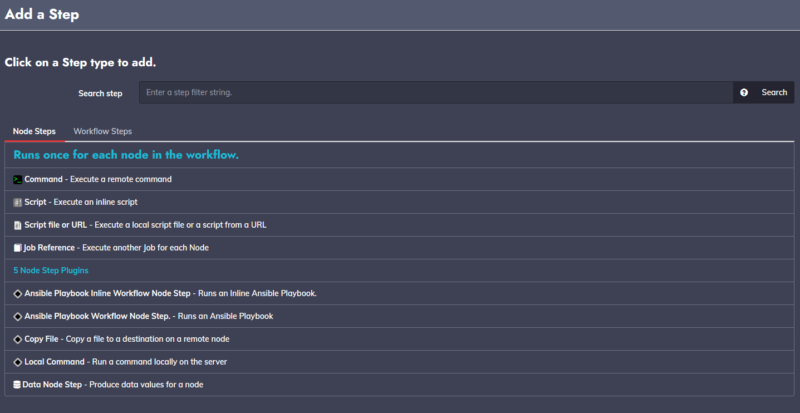
Chaque action d'un job est nommé "Step" (étape), et comme vous pouvez le constater, les différentes possibilités permettent déjà de faire pas mal de choses :
Command permet de passer une commande, comme nous l'avons fait tout à l'heure avec hostname
Script vous permet d'écrire directement dans Rundeck un script qui sera exécuté sur la machine distante
Script file or URL vous permet d'utiliser un fichier de script préalablement écris ou récupérer un script depuis une page web (sur un gist par exemple)
Job reference vous permet d'inclure un job dans un job (l'inception de l'administration de système quoi...)
Mais là où ça devient très intéressant, c'est les plugins, de base, la version communautaire de Rundeck est fournie avec 5 plugins :
Ansible Playbook Inline vous permettra d'écrire un playbook directement dans Rundeck depuis la page web
Andible Playbook vous permettra d'utiliser un playbook préexistant
Copy file vous donnera la possibilité de copier des fichiers depuis le serveur Rundeck vers le serveur cible. Pratique si vous installez également un Git pour la mise à jour de scripts par exemple.
Local command va exécuter une commande sur le serveur Rundeck
Data Node Step permet quant à lui de déclarer des données à la volée pour ce job (je ne l'ai jamais utilisé cela dit donc pas certain de ce qu'il fait réellement)
Pas mal, non? Mais ce qui est top, c'est que vous pouvez ajouter des plugins! Vous en trouverez pour Git, Docker, Azure, etc. Bref, tout (ou presque) est possible. À noter que les plugins officiels ne sont disponibles que sur la version Entreprise. Pour le reste, vous pouvez commencer sur leur GitHub.
Nous allons rester simples, pour rappel, il s'agit de déployer la stack LAMP sur les serveurs cibles. Donc si on décompose, je dois :
Faire un mise à jour des dépôts et des paquets
Installer Apache, PHP (et les autres paquets utiles) et MariaDB
Vérifier que les services sont bien démarrés et les activer au démarrage
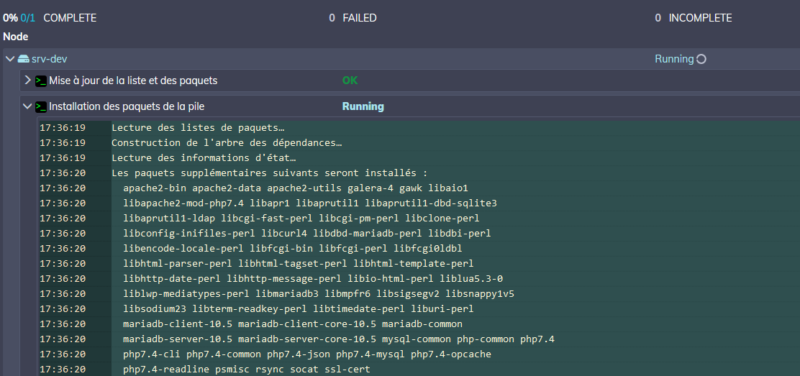
Dans mon Workflow, je vais donc découper tout cela en steps pour bien vérifier chaque étape. Je vais donc ajouter un Step pour la mise à jour, pour cela, pas besoin de script, je choisis une commande :
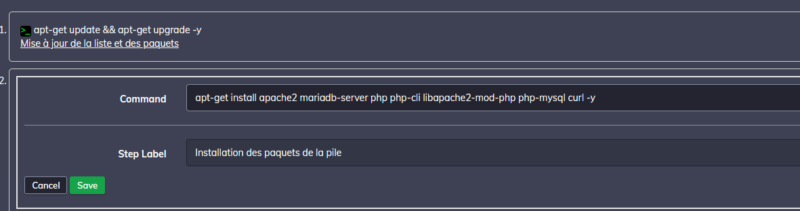
J'enregistre et ensuite, j'installe ce dont j'ai besoin, là encore, pas besoin de script, une commande suffit. Je l'ajoute en cliquant sur "Add A Step" :
Note : n'oubliez pas le "-y" à la fin! Vous ne pourrez pas interagir avec le job une fois celui-ci lancé...
Ensuite, il me faut recharger Apache car il va démarrer tout seul suite à l'installation, et je souhaite qu'il prenne en compte PHP, puis je l'ajoute au démarrage. Ici, je préfère utiliser un script :
Vous constaterez que je n'ai pas mis de shebang ! C'est normal, car c'est du bash et c'est mon terminal par défaut. Si jamais j'utilise un autre langage, il faudra impérativement que je l'indique. Vous remarquerez aussi que vous pouvez créer des arguments pour votre script.
Maintenant, lors d'une installation normale, j'exécuterais "mysql_secure_installation", mais là pas possible. Je vais devoir le faire manuellement (enfin, via un script bien sûr) et donner un mot de passe à root. Sauf que je ne veux pas que celui-ci soit clairement indiqué dans mon étape ! C'est ici que les options peuvent nous sauver, nous allons donc créer une option, qui sera le mot de passe de MariaDB qu'il faudra renseigné lors du déploiement. Celui-ci sera rappelé dans mon script à l'aide d'une variable.
Cliquez sur "Add an Option" en haut de la fenêtre (avant les étapes) et remplissez le formulaire. Je ne fais pas de capture d'écran ici car ce serait trop grand mais je vais détailler les différents champs :
Option type : j'ai le choix entre Text et File, ici je choisis Text
Option name : le nom que je donne à mon option. C'est important car c'est avec ce nom que je vais l'appeler ensuite. Je choisis de l'appler db-pass
Option label : si vous voulez donner une étiquette à l'option, je n'en mets pas
Eventuellement une description plus explicite, pas utile pour moi
Default Value pour insérer une valeur par défaut si rien n'est indiqué lors de l'exécution. Dans mon cas, ce serai contre productif!
Input Type vous permet de choisir quel type d'entrée. Je vais choisir Secure car il s'agit ici d'un mot de passe. Celui-ci ne sera donc pas enregistré par Rundeck
Sort Value me permet de trier, utile pour une liste mais pas dans mon cas
Required : si Yes est coché, le job ne pourra pas être exécuté sans avoir rempli l'option, c'est ce que je veux donc oui.
Le champ suivant vous permet de masquer l'option sur la page du job, moi je n'en ai pas besoin.
Une fois tout rempli, Rundeck me dis comment l'utiliser :
Comme je vais l'utiliser dans un script, je vais appeler mon mot de passe avec "@option.db-pass@" et Rundeck passera au script la valeur renseignée au moment où je lance le job. Sauvegardez l'option, et ajoutez une étape au job sous forme de script.
Voici ce que je vais renseigner :
mysql --user=root <<_EOF_
SET PASSWORD FOR 'root'@localhost = PASSWORD('@option.db-pass@');
DELETE FROM mysql.user WHERE User='';
DELETE FROM mysql.user WHERE User='root' AND Host NOT IN ('localhost', '127.0.0.1', '::1');
DROP DATABASE IF EXISTS test;
DELETE FROM mysql.db WHERE Db='test' OR Db='test\_%';
FLUSH PRIVILEGES;
_EOF_
Toutes les étapes du script "mysql_secure_installation" sont reprises ici, notez l'appel de mon option à la deuxième ligne.
Je rajoute une étape pour m'assurer que le service MariaDB démarre bien avec le système :
Je termine en ajoutant un script, qui va vérifier que tout est OK en allant charger une page en PHP via Curl. Si tout est bon il va me dire "TEST OK" sinon, il me dira "TEST NOK" :
echo "" > /var/www/html/test.php
test=$(curl http://127.0.0.1/test.php | grep "PHP Version")
if [$test != "" ]; then echo "TEST OK"; else echo "TEST NOK"; fi
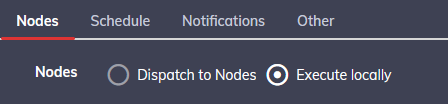
Nous voilà donc avec nos 6 étapes dans le job. Dernière étape obligatoire, dire où ce job s'exécute dans l'onglet "Nodes".
Rien de sorcier ici, soit on l'exécute localement, soit sur des nœuds. Cependant, lorsque vous allez cliquer sur "Dispatch to Nodes", plusieurs options vont s'afficher :
Node filter : permet de définir un filtre pour appliquer ce job à un ou plusieurs nœuds, dans mon exemple, ils seront appliqués aux serveurs Debian donc je mets osName: Debian et je clique sur "Search". Ce paramètre peut s'écraser pour ne le faire que sur un nœud au moment de l'exécution.
Exclude filter : si vous voulez exclure certains noeuds qui apparaissent quand même avec votre précédent filtre
Show Excluded Nodes : si vous souhaitez que les noeuds exclus s'affichent sur la page du job
Matched Nodes : les nœuds qui répondent au filtre mis au début. Normalement ici vous retrouvez votre serveur.
Editable filter : si vous voulez toujours exécuter sur le ou les nœuds déclarés par le biais de votre filtre, vous pouvez laisse sur No. En revanche, si votre job est amené à être exécuté sur tantôt un nœud, tantôt plusieurs nœuds, je vous conseille de mettre Yes.
Thread Count : si plusieurs nœuds, le nombre de tâches parallèles
Rank Attribute : si plusieurs nœuds, l'ordre dans lequel sera exécuté le job. Par défaut, c'est le nom des nœuds par ordre alphabétique.
Rank Order : l'ordre du classement (A-Z ou Z-A par exemple)
If a node fails : décris comment doit se comporter le job si un nœud échoue. Soit le job se termine immédiatement même s'il reste des nœuds à traiter, soit il continue sur les autres nœuds. Je choisis de continuer.
If node set empty : que faire si la liste définie de noeuds est vide
Node selection : si les cibles doivent être définies manuellement ou si la sélection se fait par défaut
Orchestrator : permets d'ajouter plusieurs options sur la manière dont le job sera traité
Une fois les options souhaités remplies, il ne reste qu'a définir si le job peut être programmé, car oui, il est possible de programmer les jobs directement pour qu'il s'exécutent à une date et une heure donnée, et s'il peut être exécuté. Cette dernière option est pratique si vous êtes plusieurs et que votre job n'est pas complet. Car vous pourrez le sauvegarder sans craindre qu'un de vos collègue l'exécute.
A ce stade, vous pouvez cliquer sur "Create" pour créer votre job. L'onglet "Notification" permet d'être alerté par mail en cas d'échec par exemple et l'onglet "Other" contiens d'autres options, comme le niveau de log. Vous pouvez laisser les valeurs par défaut, mais je vous invite à regarder ce qu'il est possible de faire.
Voilà donc mon job prêt à être lancé. Il ne reste qu'à le tester! Lorsque vous terminez sa création, vous pouvez directement le lancer à partir de l'écran sur lequel vous êtes :
Ici, je dois indiquer le mot de passe de root pour MariaDB (mon option) et je peux, si je veux changer, le ou les nœuds de destination. Je vais entrer un mot de passe et lancer le job pour vérifier que tout va bien.
Lorsque celui-ci est lancé, vous pouvez le suivre en déroulant les différentes étapes. Vous pourrez même avoir le retour du terminal du serveur distant, pratique pour débugger !
Par exemple, j'ai une erreur :
En déroulant cette étape, voici ce que cela me renvoie :
/tmp/4-7-srv-dev-dispatch-script.tmp.sh: ligne 2: curl : commande introuvable
/tmp/4-7-srv-dev-dispatch-script.tmp.sh: ligne 4: erreur de syntaxe : fin de fichier prématurée
Failed: NonZeroResultCode: Remote command failed with exit status 2
Ben oui, j'aurais pu vérifier que cURL était bien installé avant de lancer le job! Heureusement, j'avais pris un snapshot pour la démo... (comme quoi ça vous prouve que cet article est sans filet !)
Donc, je clique sur le menu à côté du nom de mon job et sur "Edit this Job" :
Me revoilà dans l'interface d'édition du job, je me rends dans l'onglet "Workflow" et édite l'étape numéro 2 en ajoutant cURL :
Je sauvegarde et relance le job (an ayant au préalable restauré mon snapshot bien sûr...).
Ça va beaucoup mieux ! Mon serveur LAMP est déployé ! Il me suffit maintenant d'ajouter plusieurs nœuds et je pourrais le faire à la volée sur plusieurs serveurs !
VIII. Conclusion
Ce premier tutoriel sur l'installation et l'utilisation de Rundeck touche à sa fin ! N'hésitez pas à nous faire vos retours en commentaire ! Le prochain article sur Rundeck portera sur la gestion des serveurs Windows Server !
Une nouvelle faille de sécurité critique a été découverte dans une bibliothèque très populaire puisque présente dans de nombreuses distributions Linux : GNUC C (glibc). En l'exploitant, un attaquant peut obtenir un accès root sur la machine. Voici ce qu'il faut savoir.
Les chercheurs en sécurité de chez Qualys ont mis en ligne un nouveau rapport dans lequel ils évoquent la découverte de 4 vulnérabilités dans la bibliothèque GNU C.
Celle qui est particulièrement dangereuse, c'est la faille de sécurité associée à la référence CVE-2023-6246 est présente dans la fonction "__vsyslog_internal()" de la bibliothèque glibc. Cette fonction est très utilisée par les distributions Linux par l'intermédiaire de syslog et vsyslog afin d'écrire des messages dans les journaux.
Cette vulnérabilité de type "heap-based buffer overflow" permet une élévation de privilèges sur une machine locale sur laquelle un attaquant à déjà accès avec un compte utilisateur standard. Ainsi, il peut élever ses privilèges pour devenir root ("super administrateur") sur cette machine. De nombreuses distributions populaires sont vulnérables, comme le précise le rapport de Qualys : "Les principales distributions Linux telles que Debian (versions 12 et 13), Ubuntu (23.04 et 23.10) et Fedora (37 à 39) sont confirmées comme étant vulnérables." - Pour Debian, rendez-vous sur cette page pour obtenir la liste des versions où cette vulnérabilité a été corrigée.
Il est à noter que cette vulnérabilité a été introduite dans la bibliothèque GNU C en août 2022, au sein de glibc 2.37. Par ailleurs, elle a été accidentellement intégrée dans la version 2.36 de glibc lorsque les développeurs ont intégré un correctif pour une autre vulnérabilité : CVE-2022-39046. Par ailleurs, la fonction "qsort()" de glibc contient une vulnérabilité qui affecte toutes les versions de la 1.04 (septembre 1992) à la version 2.38, qui est la plus récente.
L'occasion pour Qualys de rappeler l'importance de la sécurité des bibliothèques populaires : "Ces failles soulignent le besoin critique de mesures de sécurité strictes dans le développement de logiciels, en particulier pour les bibliothèques de base largement utilisées dans de nombreux systèmes et applications."
Ces dernières années, Qualys a fait la découverte de plusieurs failles de sécurité importantes au sein de Linux, notamment Looney Tunables et PwnKit.
Voilà une erreur qui aurait pu coûter cher à Mercedes-Benz : un jeton d'authentification correspondant à un employé du fabricant automobile a été découvert dans un dépôt GitHub public ! Grâce à lui, n'importe qui aurait pu accéder au serveur GitHub Enterprise de Mercedes-Benz.
Au cours du mois de janvier 2024, les chercheurs en sécurité de RedHunt Labs ont découvert que Mercedes-Benz avait involontairement laissé un jeton d'authentification sur un dépôt GitHub public. Autrement dit, ce jeton était à la portée de tout le monde... Mercedes-Benz a été informé de cette découverte le 22 janvier 2024 par RedHunt Labs, avec l'aide du média TechCrunch. Il semblerait qu'il était accessible depuis septembre 2023.
Shubham Mittal, cofondateur de RedHunt Labs, a déclaré : "Le jeton GitHub donnait un accès "illimité" et "non surveillé" à l'ensemble du code source hébergé sur le serveur interne GitHub Enterprise Server". Il affirme également que les dépôts comprennent de nombreuses informations sensibles, notamment des clés d'accès Cloud, des clés d'API, des documents d'études, des codes sources, ou encore des identifiants.
Au passage, Shubham Mittal a pu prouver qu'il avait en sa possession des identifiants Microsoft Azure et AWS, ainsi qu'une base de données Postgres, appartenant à Mercedes-Benz. À ce jour, rien ne prouve que des données de clients ont été exposées dans le cadre de cet incident.
Heureusement que cela n'est pas tombé entre de mauvaises mains... Deux jours après avoir eu connaissance de ce problème de sécurité, Mercedes-Benz a révoqué le jeton d'authentification exposé et a procédé à la suppression du dépôt GitHub public.
Le constructeur automobile en a profité pour s'exprimer publiquement : "Nous pouvons confirmer qu'un code source interne a été publié sur un dépôt GitHub public par erreur humaine. Ce jeton donnait accès à un certain nombre de dépôts, mais pas à l'ensemble du code source hébergé sur le serveur interne GitHub Enterprise Server.".
Dans ce tutoriel, nous allons voir comment déployer un hôte ESXi 8.0 sur une machine virtuelle dans VMware Workstation Pro. Cette approche se nomme "virtualisation imbriquée" et vous permettra de créer un lab VMware sur votre poste de travail.
Vous pouvez suivre ce tutoriel au format vidéo, en complément de cet article :
Workstation Pro offre la possibilité d’installer ESXi pour faire l’essai et, éventuellement, d’installer vSphere, le produit phare de VMware.
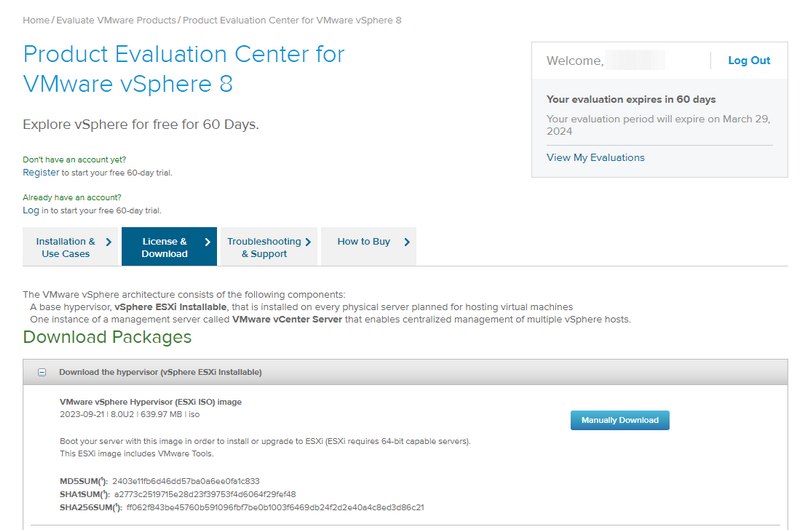
Pour compléter ce tutoriel, vous aurez besoin d’un compte VMware Customer Connect afin de télécharger une version d’évaluation de ESXi 8.0. Lorsque votre compte sera créé, vous pourrez naviguer dans la section vSphere et sélectionner l’ISO VMware vSphere Hypervisor(ESXi ISO) image à la version 8.0U2 au moment d’écrire ces lignes.
Si vous n’avez pas Workstation d’installé sur votre PC, vous pouvez consultez le tutoriel suivant :
Prenez note que le type d’installation proposé dans ce tutoriel n’est pas supporté par VMware et ne devrait pas être utilisé pour un environnement de production.
II. La virtualisation imbriquée
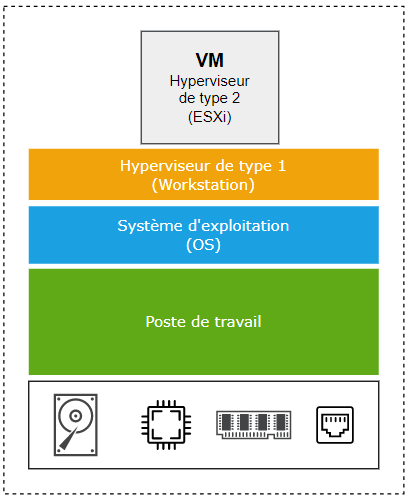
L’environnement que vous vous apprêtez à mettre en place consiste à créer un hyperviseur de type 1 (ESXi) sur une machine virtuelle qui va être exécutée sur un hyperviseur de type 2 (Workstation). Pour comprendre cette imbrication, voici un bref rappel des types d’hyperviseur :
Un hyperviseur de type 1 (dit aussi bare metal) s'installe directement sur le matériel. Il s’agit en général d’un logiciel de niveau entreprise installé sur des serveurs physiques très performants configurés en cluster pour offrir une solution de haute disponibilité. Dans cette catégorie, on retrouve bien sûr ESXi de VMware, mais aussi Hyper-V Server de Microsoft ou AHV de Nutanix.
Un hyperviseur de type 2 s'exécute sur un système d'exploitation et il est couramment utilisé sur des postes de travail pour créer des machines virtuelles de test ou de développement. Les principaux exemples de ce type de logiciel sont Oracle VM VirtualBox, VMware Workstation ou VMware Fusion pour macOS et Parallels Desktop.
Pour en savoir davantage sur les différents types d'hyperviseurs, voir l'article suivant :
La figure suivante représente l’environnement de virtualisation imbriquée que nous allons créer dans ce tutoriel :
III. Créer une VM pour installer ESXi sous Workstation
Lorsque votre installation de Workstation 17 est complétée, ouvrez la console pour créer une nouvelle machine virtuelle.
Dans le menu principal, appuyez sur « File », puis sur « New Virtual Machine ».
L’assistant de création d’une nouvelle VM s’ouvre, cochez « Custom » et appuyez sur « Next ».
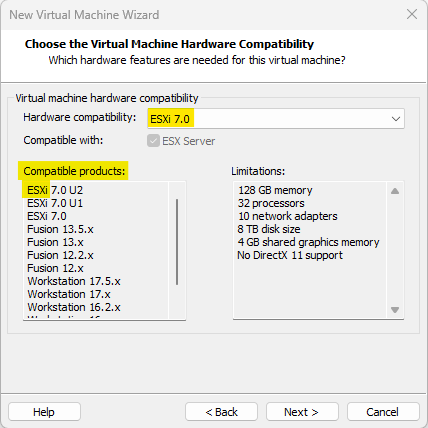
Sous « Hardware Compatibility », sélectionnez « ESXi 7.0 » qui fonctionne aussi pour ESXi 8.0 et appuyez sur « Next ». Ce choix vous permet de voir les produits compatibles et les limitations (largement suffisantes pour un lab VMware !).
Notons au passage que Hardware Compatibility (compatibilité matérielle) fait référence à la capacité de l’hyperviseur à prendre en charge et à utiliser les ressources matérielles de la machine hôte pour s’assurer d’avoir des performances optimales pour les machines virtuelles. Cette notion est spécifique aux produits VMware.
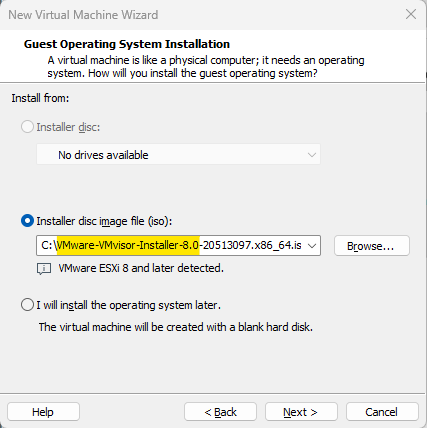
Sous « Installer disc image file (iso) », naviguez dans votre système de fichier pour sélectionner le média d’installation de ESXi 8.0 que vous avez téléchargé et appuyez sur « Next ».
Le nom du fichier devrait ressembler à ceci : VMware-VMvisor-Installer-8.0-20513097.x86_64.iso.
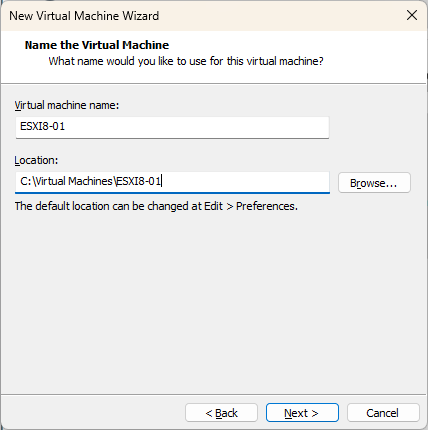
Nommez votre machine virtuelle et indiquez l’emplacement où vous souhaitez stocker les fichiers de celle-ci et appuyez sur « Next ».
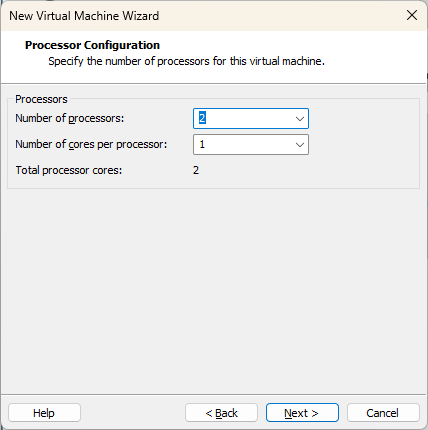
Laissez le nombre de processeurs (2) par défaut et appuyez sur « Next ».
Si votre poste de travail vous le permet, n’hésitez pas à assigner 4 CPUs à votre machine virtuelle, surtout si vous souhaitez mettre en place un lab vSphere.
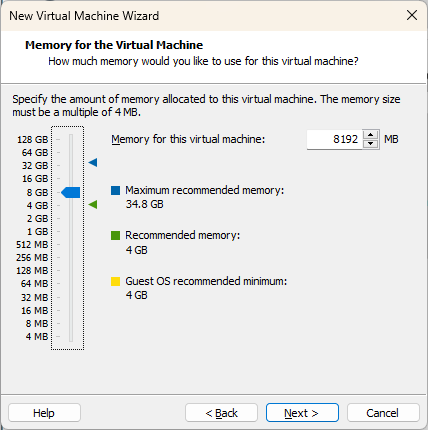
Par défaut, l’assistant recommande 4 Go de mémoire, mais, encore une fois, si vous pouvez vous rendre à 8 Go, ce sera mieux pour l’installation de l’hyperviseur et plus performant pour un lab VMware. Appuyez sur « Next ».
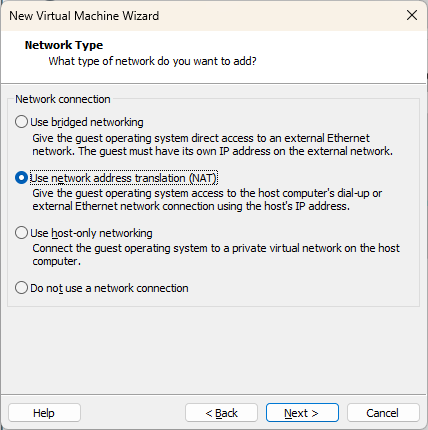
Le choix de la connexion réseau dépend de l’accès que vous souhaitez donner à votre machine virtuelle. Vous pouvez laisser l’option par défaut (Use network address translation, NAT) et vous pourrez la modifier plus tard. Appuyez sur « Next ».
Pour mieux comprendre les types de réseau, consultez le tutoriel suivant :
Laissez l’option « Disk Type » à « SCSI » et appuyez sur « Next ».
Laissez l’option « Create a new virtual disk » par défaut et appuyez sur « Next. »
À l’étape « Specify Disk Capacity », ne tenez pas compte de la taille de disque recommandée de 148 Go pour ESXi 8.0. En fait, VMware recommande un minimum de 32 Go pour son hyperviseur de type 1, mais vous pouvez très bien en allouer beaucoup moins.
En réalité, ESXi fait environ 150 Mo et peut être déployé sur une carte SD, mais cette installation ne serait pas supportée en production. Après avoir indiqué la taille du disque, sélectionnez la manière dont vous souhaitez stocker le disque virtuel et appuyez sur « Next ».
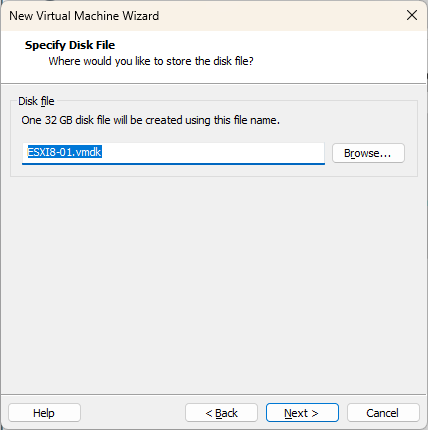
Indiquez l’emplacement désiré pour le nouveau disque (.vmdk) et appuyez sur « Next ».
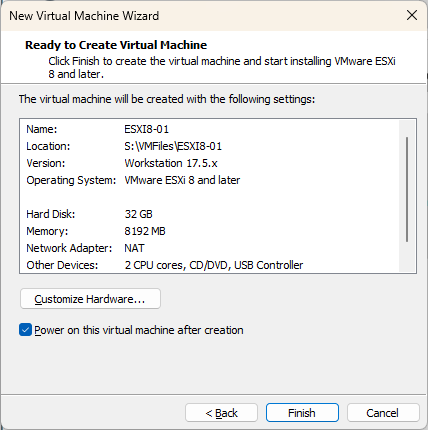
Vous êtes maintenant prêt à créer votre nouvelle machine virtuelle. Validez les paramètres et appuyez sur « Finish ».
Contrairement à Workstation qui utilise seulement une portion d'un disque local pour chaque disque virtuel qui est créé, VMware ESXi a besoin d'un espace logique nommé datastore (ou banque de données) pour stocker les fichiers des machines virtuelles. Si vous voulez aller plus loin, vous pouvez donc ajouter un disque virtuel local à votre VM ESXi dans Workstation, ce qui vous permettra ensuite de créer un datastore dans la console ESXi Host Client.
Ce nouveau datastore pourra être utilisé pour créer des machines virtuelles sur votre hôte ESXi... qui est lui-même une machine virtuelle. C'est un niveau supplémentaire d'imbrication : une VM qui s'exécute sur la VM ESXi représentée plus haut dans le schéma. Mais rassurez-vous, un tutoriel à venir vous indiquera les étapes à suivre au besoin.
Passons à l'installation de l'hyperviseur.
IV. Installer un hôte ESXi 8.0
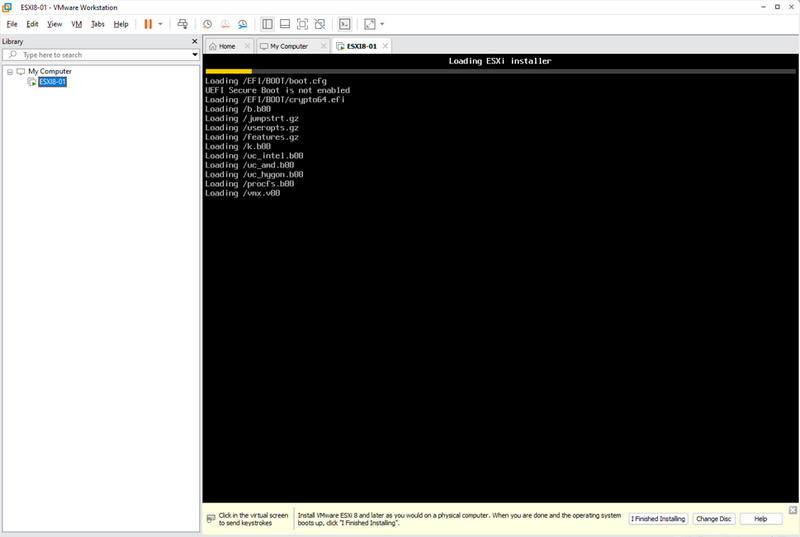
Après avoir terminé la création de votre machine virtuelle, elle sera mise sous tension dans Workstation 17. Le chargement de ESXi installer peut prendre quelques minutes, selon les ressources que vous avez allouées à la VM.
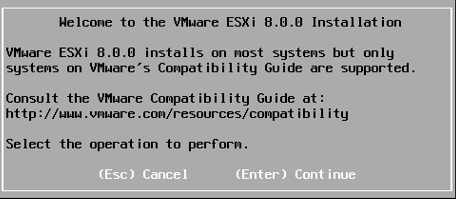
Lorsque vous verrez le message « Welcome to the VMware ESXi 8.0.0 Installation » s’afficher, appuyez sur « Enter ».
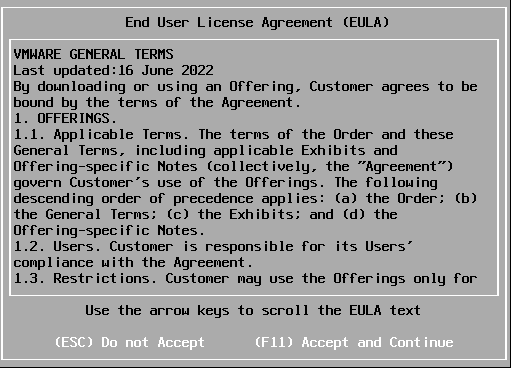
Acceptez les conditions de la licence en appuyant sur « F11 ».
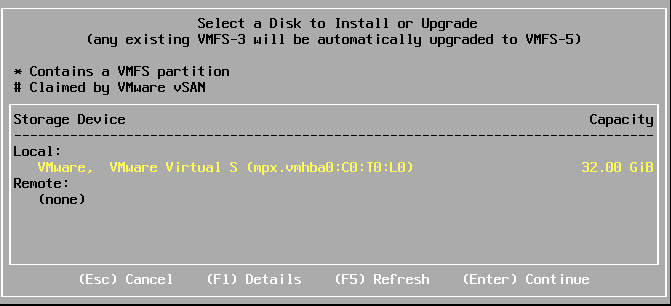
Comme vous avez installé un seul disque, vous pouvez appuyer sur « Enter » pour continuer l’installation.
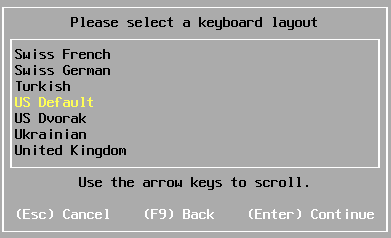
Sélectionnez la disposition du clavier et appuyez sur « Enter » pour continuer.
La capture d’écran indique un clavier QWERTY (ce que l’auteur utilise), mais vous pouvez sélectionner "French" (France) pour un clavier AZERTY FR. Il suffit de monter dans le menu avec la flèche en haut pour retrouver cette option.
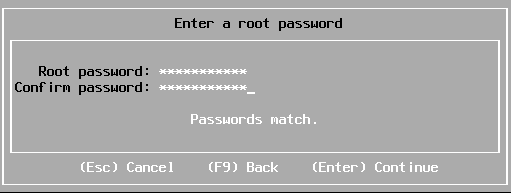
Saisissez un mot de passe complexe pour l’utilisateur « root » et appuyez sur « Enter » pour continuer.
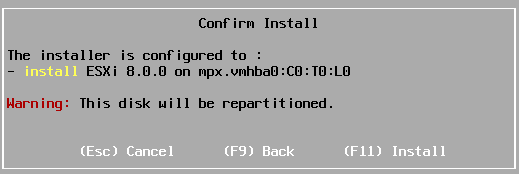
Appuyez sur « F11 » pour démarrer l’installation.
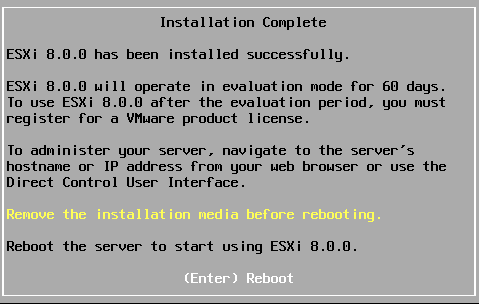
L’installation de ESXi 8.0 prend quelques minutes. Lorsque ce sera terminé, un message « Installation Complete » va s’afficher. Félicitations, vous avez installé un hyperviseur de type 1 dans une machine virtuelle sur un hyperviseur de type 2. Vous venez de créer un environnement de virtualisation imbriquée !
Appuyez sur « Enter » pour redémarrer votre serveur hôte ESXi.
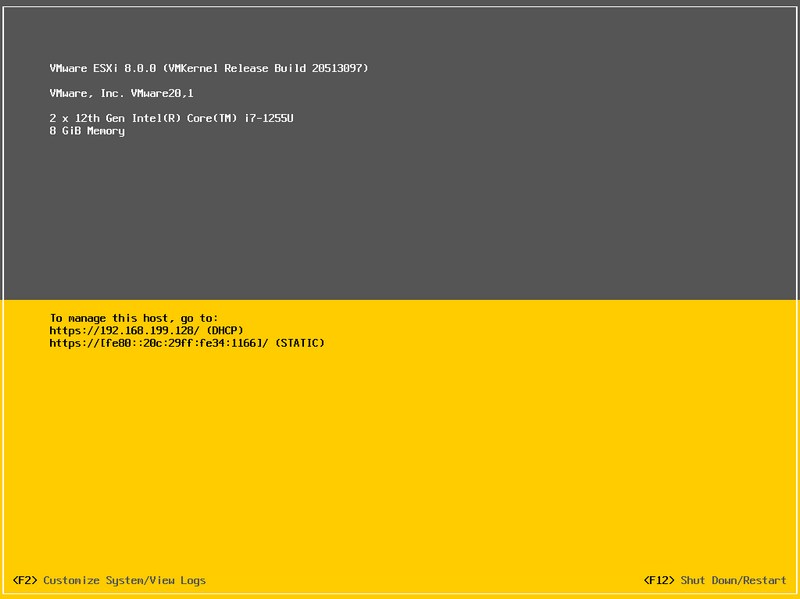
Lorsque le redémarrage sera complété, vous verrez l’interface DCUI (Direct Console User Interface). Au besoin, vous pouvez personnaliser la configuration réseau en appuyant sur « F2 », mais vous voulez sûrement découvrir l’interface web de ESXi avant !
Dans la section jaune, notez l’adresse assignée automatiquement via le DHCP et entrez-la dans votre navigateur préféré.
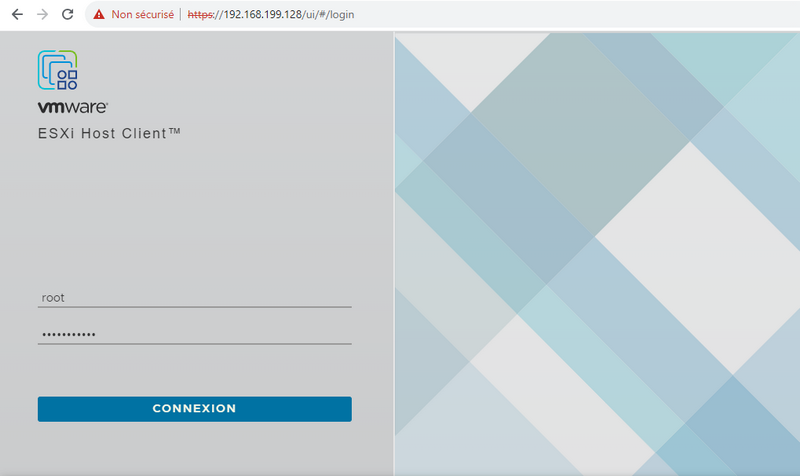
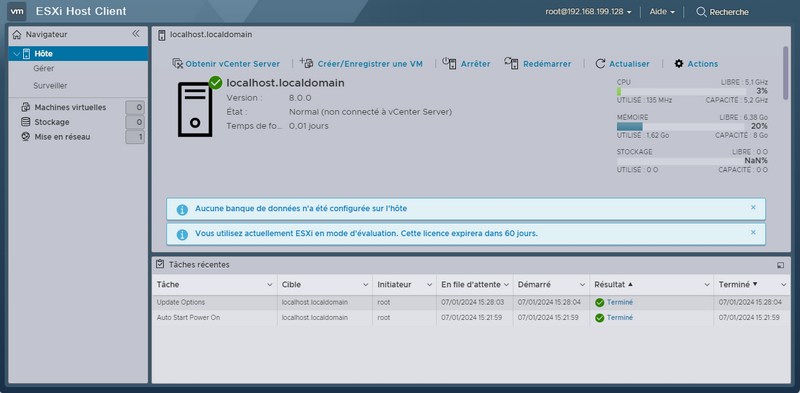
Acceptez l’avertissement du navigateur (il n’y a pas de certificat) et vous aurez accès à ESXi Host Client.
Connectez-vous avec le compte root pour découvrir l’interface web de votre hyperviseur.
Félicitations, vous pouvez maintenant explorer ESXi ! À vous maintenant de découvrir comment créer une banque de données (datastore) et de déployer une machine virtuelle… sur une machine virtuelle.
Pour aller plus loin, vous pouvez aussi tenter d’installer une appliance vCenter pour faire l’essai de vSphere, mais vous aurez besoin d’environ 600 Go de stockage et 14 Go de RAM !
V. Conclusion
Dans ce tutoriel, nous avons passé en revue les étapes permettant de créer un hyperviseur VMware ESXi 8.0 sur une machine virtuelle dans Workstation 17. Nous avons commencé par le déploiement de la VM pour ensuite faire l’installation de l’hyperviseur.
Cette expérience nous a permis de mettre en œuvre la notion de virtualisation imbriquée et de voir son potentiel pour mettre en place un lab VMware.
Dans un prochain article, nous verrons comment personnaliser la configuration de ESXi 8.0. En attendant, n’hésitez pas à explorer la console ESXi Host Client et découvrir les fonctionnalités très riches de cet hyperviseur de type 1 de VMware.
Vous avez complété la première étape pour éventuellement découvrir vSphere 8.0 que vous pouvez installer sur votre machine virtuelle ESXi et ajouter une nouvelle couche de virtualisation à votre environnement imbriqué.