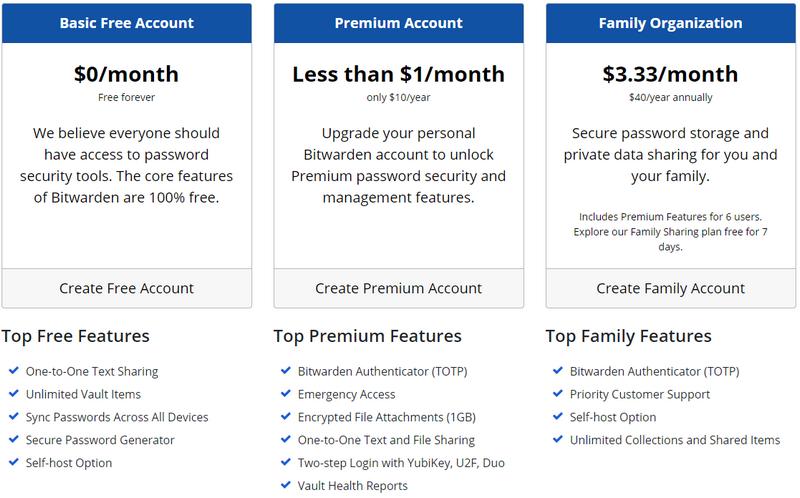
OnePlus a dévoilé une nouvelle application baptisée Clipt dont l'objectif est de faciliter le partage de contenus, que ce soit des photos, des documents, des liens ou des photos, entre tous les types d'appareils.
Vous avez besoin de partager des données entre votre smartphone Android ou iOS et votre ordinateur sous macOS ou Windows ? Peut-être même que vous avez besoin de partager des données entre deux smartphones ? La nouvelle application développée par OnePlus, le fabricant de smartphones, devrait vous intéresser. Plus précisément, c'est OneLab Studio, le studio de développement de OnePlus qui est à l'origine de l'application.
Quand on voit ce que permet de faire Clipt à première vue, on pense directement à Google Drive, OneDrive ou encore Dropbox. Néanmoins, avec Clipt, OnePlus veut simplifier le processus de partage et surtout cet échange de fichiers sera limité à quelques éléments. C'est vraiment pour du partage et de l'échange, et non du stockage sur le long terme. Explications.
Tout d'abord, il faut savoir que Clipt s'appuie sur Google Drive pour stocker les données (vous êtes déçu, je sais). L'espace d'échange de Clipt se veut temporaire : seuls les 10 derniers fichiers déposés sont conservés, donc vous n'êtes pas obligé d'opter pour un forfait payant de Google Drive. Lorsqu'un fichier est partagé avec Clipt, il est automatiquement chiffré : vous êtes le seul à pouvoir le consulter. L'application est optimisée pour partager des documents, des photos, des liens, mais aussi du texte notamment avec l'historique du presse-papier.
La version Android est disponible tandis que la version iOS est en cours de développement. Vous l'aurez surement deviné, Clipt n'est pas réservé aux smartphones OnePlus, mais l'application est bien ouverte à tous. Sur Windows ou macOS il ne semble pas y avoir de client Clipt, mais une extension pour navigateur en l'occurrence Chrome. Il faut utiliser le même compte Google Drive sur tous les appareils.
Dans ce tutoriel, nous allons apprendre à créer un compte Bitwarden et à utiliser Bitwarden pour vous faciliter la gestion de vos mots de passe au quotidien.
Tutoriel disponible au format vidéo (plus complète sur la partie démo) :
Toujours les jours, nous faisons usage des mots de passe, que ce soit pour se connecter sur un site d'e-commerce, sur le site de notre banque, pour ouvrir sa session sur une machine au travail ou à la maison, ou encore pour s'authentifier sur un site X ou Y, tout simplement.
Pour des raisons de sécurité et par précaution (notamment en cas de fuite de données faisant suite à un piratage), il est préférable de ne pas utiliser le même mot de passe sur deux sites différents. La question, c'est, comment vais-je faire pour mémoriser des dizaines voire des centaines de mots de passe dans ma petite tête ? Même si j'arrive à les mémoriser, comment faire pour ne pas les confondre ? Autant de questions auxquelles on peut répondre à l'aide d'un logiciel que l'on appelle un "Gestionnaire de mots de passe".
Il existe de nombreuses solutions sur le marché, des gratuites, des payantes, certaines Open source d'autres non... La différence se fait sur la sécurité et sur les fonctionnalités. En ce qui me concerne, je suis adepte de plusieurs gestionnaires de mots de passe :
KeePass qui est un gestionnaire de mots de passe open source et gratuit, avec stockage de la base de mots de passe en local
LastPassqui est un gestionnaire de mots de passe propriétaire, avec des versions gratuites et payantes, et un stockage sécurisé dans le Cloud. Néanmoins, la version gratuite a pris du plomb dans l'aile récemment puisqu'il n'est plus possible de synchroniser et d'accéder à son coffre-fort depuis plusieurs types d'appareils. Très contraignant... Pour moi, c'est rédhibitoire : j'ai besoin de cette fonctionnalité.
Ce qui m'amène à vous présenter Bitwarden, un gestionnaire de mots de passe que j'utilisais par ailleurs, et la décision de LastPass quant à la synchronisation multiappareils m'a définitivement convaincu de passer sur Bitwarden. Cet outil permet dans sa version gratuite d'utiliser la synchronisation multiappareils.
Bitwarden, c'est quoi ? Bitwarden est un gestionnaire de mots de passe open source, disponible en version gratuite et payante. Le coffre-fort de vos identifiants peut-être hébergé directement par Bitwarden, mais il est possible d'héberger sa propre instance de Bitwarden. Par exemple, on peut le déployer sur un NAS (Synology, ASUSTOR, etc.), ou sur sa propre machine Windows ou Linux, notamment grâce à la solution Docker.
Bitwarden est une solution sécurisée et régulièrement auditée par des cabinets externes spécialisés. Sachez également que Bitwarden ne peut pas accéder à vos identifiants et mots de passe : vous êtes le seul à pouvoir le faire, car pour déchiffrer et déverrouiller votre coffre-fort, il faut connaître le mot de passe maître (nous y reviendrons).
Dans ce tutoriel, je vous propose de voir comment utiliser Bitwarden dans sa version gratuite, en s'appuyant sur l'offre Cloud de Bitwarden. L'objectif étant de permettre au plus grand nombre de gérer ses mots de passe efficacement, sans avoir une grande connaissance technique.
En fait, héberger soi-même Bitwarden c'est bien, car on maîtrise pleinement son coffre-fort, mais il faut penser à aller plus loin et en faire une sauvegarde : héberger soi-même, cela veut aussi dire assurer soi-même les sauvegardes.
Si vous prêts, suivez-moi...
II. Créer un compte Bitwarden
Pour commencer, il faut créer un compte sur le site Bitwarden, voici le lien : Bitwarden
Dès que vous êtes sur le site, cliquez en haut à droite sur "Get Started".
Pour créer un compte, vous avez besoin d'une adresse e-mail : indiquez votre e-mail dans le champ "Adresse e-mail", jusque là ça devrait aller. Ensuite, précisez votre nom.
Un troisième champ se présente à l'écran : Mot de passe maître. Qu'est-ce que c'est que ce truc ? En bref, c'est le seul mot de passe que vous devez retenir : c'est la clé de votre coffre-fort. Pour accéder à votre banque de mots de passe, il faut indiquer le mot de passe maître pour déverrouiller l'accès.
Ce qui signifie que ce mot de passe doit être complexe ! J'entends par là, un mot de passe de 10 caractères minimum, en mixant au minimum l'usage de trois types de caractères différents parmi les types suivants : les minuscules, les majuscules, les chiffres et les caractères spéciaux.
Attention :n'oubliez pas que si vous perdez ce mot de passe, vous perdez l'accès à votre compte Bitwarden ! Il faut aussi avoir conscience que si quelqu'un devine ce mot de passe, il peut accéder à votre compte Bitwarden, et donc à tous vos mots de passe ! D'où l'utilité de choisir un mot de passe complexe.
Il n'est pas indispensable de renseigner le champ "Indice du mot de passe maître" : si vous pouvez éviter d'indiquer un indice, c'est mieux. Cochez la case et cliquez sur "Soumettre".
Le compte est créé : identifiez-vous avec votre adresse e-mail et le mot de passe maître. Ne me dites pas que vous l'avez déjà oublié ?
Bienvenue dans votre coffre-fort Bitwarden : c'est là qu'il faudra stocker vos identifiants pour accéder à vos sites et applications favoris.
Avant d'aller plus loin, cliquez sur le bouton "Envoyer l'e-mail" en haut à droite, cela va permettre de valider le compte.
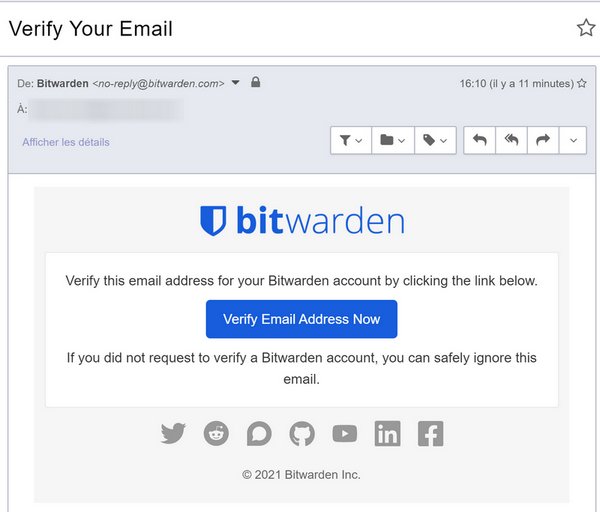
Vous allez recevoir un e-mail, cliquez sur "Verify Email Address Now".
Le coffre-fort est prêt à être utilisé ! L'étape suivante consiste à migrer ses données de LastPass vers Bitwarden. Si vous n'êtes pas concerné, vous pouvez passer directement à l'étape IV.
III. Importer ses données LastPass dans Bitwarden
Comme je le disais en introduction, mon objectif est de migrer de LastPass vers Bitwarden, je vous explique donc comment procéder si vous êtes dans le même cas.
Connectez-vous sur le site LastPass ou cliquez sur l'extension dans le navigateur puis sur "Open my vault". Ensuite, dans le menu cliquez sur "Advanced options" puis sur "Export" sous "Manage your vault".
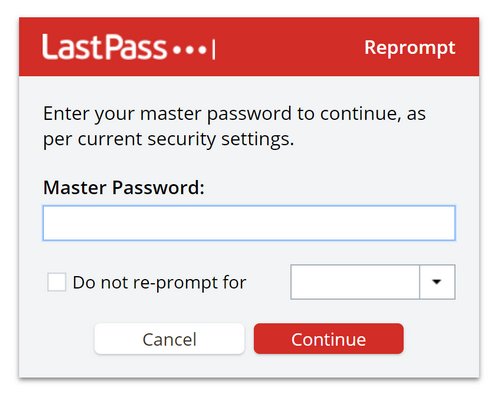
Saisissez le mot de passe maître de votre compte LastPass...
Un fichier CSV sera téléchargé. Attention, il contient le contenu de votre coffre-fort LastPass avec toutes les informations en claires : nom d'utilisateur, mots de passe, nom du site, etc... À la fin de l'opération de migration vers Bitwarden, pensez à supprimer ce fichier.
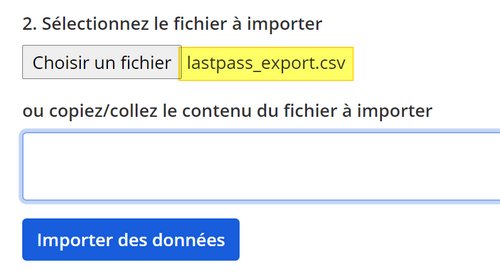
Retournez dans Bitwarden... Cliquez sur "Outils" dans le menu supérieur, puis à gauche sur "Importer des données". Pour répondre à la question "Sélectionnez le format du fichier importé", sélectionnez "LastPass (csv)".
Cliquez sur "Choisir un fichier" et sélectionnez le fichier lastpass_export.csv. Enfin, cliquez sur "Importer des données".
Votre coffre-fort Bitwarden contient désormais les données de votre coffre-fort LastPass ! Les dossiers sont également récupérés, ce qui est une bonne nouvelle !
Ce que je vous recommande, c'est de vérifier quelques identifiants migrés pour vérifier qu'il n'y a pas de trous dans la raquette comme on dit. De mon côté, je n'ai pas eu de soucis particuliers lors de ce transfert.
Une fois que vous êtes prêt (vous pouvez attendre 2-3 jours avant de faire cette action), je vous invite à supprimer votre compte LastPass. Puisque l'on ne va plus l'utiliser, ce n'est pas utile de le garder actif...
Pour utiliser son coffre-fort au quotidien, l'idée ce n'est pas d'accéder au site Bitwarden à chaque fois. L'idée ce n'est pas non plus de renseigner soi-même les identifiants mots de passe dans le coffre, ni d'aller piocher manuellement dans son coffre-fort pour se connecter à un site Internet.
En fait, Bitwarden propose un ensemble de clients pour interconnecter les systèmes d'exploitation et les navigateurs avec son coffre-fort. Il existe des clients Bitwarden pour Windows, Linux, macOS, Android, iOS... Mais aussi pour les navigateurs, notamment Chrome, Firefox, Edge et Safari.
Utilisez le lien ci-dessous pour télécharger et installer les clients Bitwarden correspondants à vos équipements et votre navigateur préféré.
L'application Windows permet d'avoir une interface très proche de celle du site Bitwarden. Tandis qu'au sein des navigateurs, l'extension permet d'accéder au contenu de son coffre au travers d'une interface minimaliste.
Au sein de l'extension, on remarque plusieurs sections :
Onglet : affiche les identifiants correspondants à l'onglet actif dans votre navigateur
Mon coffre : affiche le contenu complet de votre coffre-fort, et gérer vos identifiants
Send : affiche vos Send et vous permet d'en créer un nouveau. Send est une fonctionnalité récente de Bitwarden qui permet de partager du texte (par exemple un mot de passe) en toute sécurité avec un tiers
Générateur : un générateur de mots de passe pour vous aider à trouver un nouveau mot de passe pour chaque nouveau site
Paramètres : configuration du coffre-fort, mais aussi de l'extension. Cela permet notamment de définir à partir de combien de temps le coffre-fort se verrouille en cas d'inactivité
V. L'extension Bitwarden au quotidien
L'extension dans le navigateur est indispensable compte tenu du temps que l'on passe sur Internet à naviguer d'un site à l'autre. C'est un gain de temps énorme au quotidien, sans pour autant négliger la sécurité puisque l'on peut utiliser un mot de passe différent pour chaque site.
Prenons le cas où Bitwarden est installé dans un navigateur et que l'on est connecté avec son compte. Si l'on se connecte pour la première fois sur un site quelconque avec des identifiants existants, mais non renseignés dans le coffre-fort, un bandeau va apparaître : est-ce que Bitwarden doit se souvenir de ce mot de passe pour vous ?
Note : lorsque vous allez alimenter votre coffre-fort Bitwarden au fur et à mesure, profitez-en pour modifier vos mots de passe sur les différents sites. Si vous gériez tout de tête, il y a de fortes chances pour que vous utilisiez le même mot de passe sur plusieurs sites
Si vous cliquez sur "Oui, enregistrer maintenant", Bitwarden va créer une entrée dans votre coffre-fort. Cette entrée va contenir l'adresse du site Internet, le nom d'utilisateur et le mot de passe.
La prochaine fois que l'on reviendra sur ce même site, l'extension Bitwarden va afficher un petit "1" (voir ci-dessous) pour indiquer qu'il y a un identifiant dans le coffre qui correspond à ce site.
Il suffira de cliquer sur l'icône de l'extension Bitwarden, puis sur l'identifiant en question pour que le formulaire de connexion soit automatiquement renseigné avec le compte utilisateur et le mot de passe de ce site.
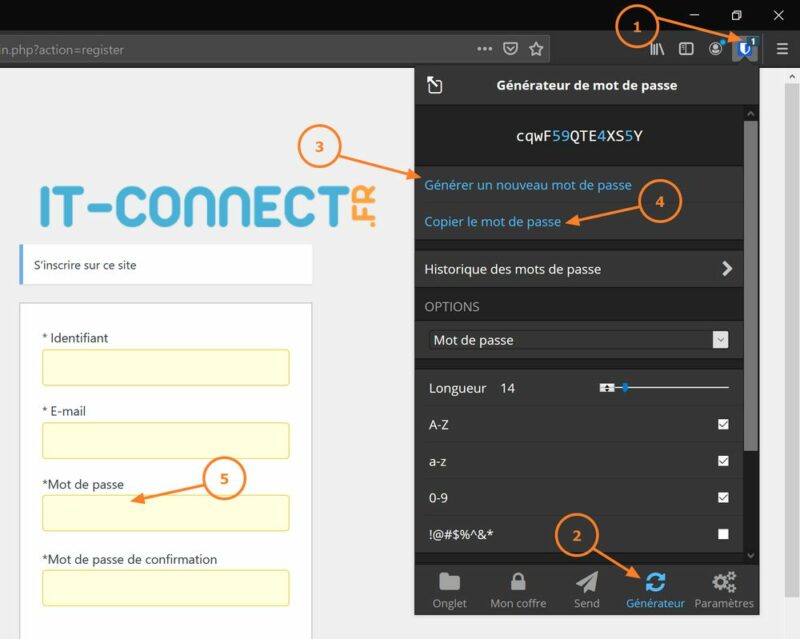
Autre cas de figure : l'inscription sur un nouveau site. Dans ce cas, au moment de devoir indiquer un mot de passe pour l'inscription, suivez la procédure suivante :
1 - Cliquez sur l'icône de l'extension Bitwarden
2 - Cliquez sur l'onglet "Générateur"
3 - Cliquez sur "Générer un nouveau mot de passe"
4 - Cliquez sur "Copier le mot de passe"
5 - Collez le mot de passe dans le formulaire d'inscription (deux fois)
Une fois l'inscription validée, cliquez sur "Oui, enregistrer maintenant" : Bitwarden contient désormais une nouvelle entrée pour ce site ! Vous n'avez pas besoin de retenir le mot de passe (ni même de le connaître en fait) : c'est Bitwarden qui gère !
Lors de votre prochaine connexion sur ce site, il vous suffira d'aller piocher dans votre coffre lorsque vous serez sur la page de connexion.
VI. Ajouter un identifiant manuellement dans Bitwarden
Nous avons vu comment utiliser l'extension pour les navigateurs, mais il y a des cas de figure où vous allez devoir alimenter vous-même votre coffre-fort. Par exemple, pour stocker une clé de licence ou encore des informations de connexion d'une session Windows, etc.
Dans ce cas, on peut passer par le client Windows, Linux ou Mac, mais aussi par l'interface Web de Bitwarden. Ce qui revient quasiment au même en fait, en termes d'ergonomie.
Pour accéder à son coffre-fort en mode Web, voici l'adresse : vault.bitwarden.com
Cliquez ensuite sur "Ajouter un élément", en haut à droite.
Il ne reste plus qu'à remplir le formulaire et cliquer sur "Enregistrer", tout en sachant que chaque entrée est modifiable par la suite. Il y a plusieurs champs à remplir : Nom, Dossier (pour garder un coffre-fort organisé), Nom d'utilisateur, et Mot de passe.
S'il s'agit d'un site Internet, il est intéressant de renseigner aussi le champ "URI 1" qui va correspondre à l'adresse du site Internet. Mais bon, pour les identifiants des sites Internet, en règle général c'est l'extension qui alimente elle-même notre coffre .
VII. Le mot de la fin
J'espère qu'au travers de cet article j'ai pu vous convaincre de l'utilité d'un gestionnaire de mots de passe, et surtout que j'ai pu vous donner l'envie de vous y mettre si ce n'est pas déjà le cas ! Que ce soit via Bitwarden ou une autre solution, je vous recommande vivement d'utiliser un gestionnaire de mots de passe. C'est réellement indispensable au quotidien, que ce soit pour gérer sa vie numérique ou au travail pour gérer ses identifiants et mots de passe.
Si vous souhaitez aller un peu plus loin, vous pouvez héberger vous-même Bitwarden sur votre NAS ou votre machine. Je vous invite également à consulter la version vidéo de ce tutoriel où la démonstration va plus loin puisque je vous parle de Bitwarden Send, mais aussi des Collections.
La vidéo est là pour vous proposer quelque chose de plus interactif et plus détaillé que les explications écrites. À consommer sans modération, et n'oubliez pas l'essentiel : utiliser un mot de passe différent par site/application et surtout mémorisez votre mot de passe maître.
Nous allons dans cet article nous intéresser aux durcissements recommandés par l'ANSSI sur les sysctl réseau dans son guideRecommandation de configuration d'un système GNU/Linux. Je vais dans cet article suivre la même approche que dans l'article précédent, dans lequel vous trouverez également quelques exemples d'utilisation de la commande sysctl pour lire et écrire des paramètres.
Pour les paramètres sysctlau niveau réseau, celles-ci peuvent être appliquées à plusieurs niveaux, ce qui détermine le nom précis du paramètre à modifier. On peut par exemple différencier les paramètres s'appliquant sur les interfaces IPv4 (net.ipv4.X.X) ou IPv6 (net.ipv6.X.X), mais également spécifier une interface précise (net.ipv4.eth0), les mots-clés all et default sont utilisés respectivement pour appliquer un paramètre sur toutes les interfaces ou pour les interfaces nouvellement créées (configuration par défaut si rien n'est spécifié).
Ça, c'était la théorie, la réalité est un chouilla plus obscure (voir ce mail https://marc.info/?l=linux-kernel&m=123606366021995&w=2) et je vous déconseille, pour résumer, de paramétrer des valeurs différentes pour le all et le default d'une même sysctl sous peine de vous retrouver avec des comportements difficiles à déboguer ou à comprendre.
II. Durcissement des sysctl réseau Linux
A. IP Forwarding
Le premier durcissement généralement recommandé en ce qui concerne les sysctl réseau est la désactivation de l'IP forwarding. Ce sysctl, lorsqu'il est à 1, permet au serveur de faire transiter des paquets d'une interface vers une autre, à l'image d'un routeur. Lorsque cette fonctionnalité n'est pas utile au fonctionnement du serveur, il est recommandé de désactiver l'IP forwarding :
net.ipv4.ip_forward = 0
Ainsi, le serveur ne sera pas autorisé à faire du routing, c'est-à-dire faire suivre des paquets d'une interface vers une autre, et ne pourra être utilisé comme un routeur entre deux réseaux. Dans le cas où votre serveur dispose de deux interfaces, dont une vers un réseau non maitrisé (Internet par exemple), les paquets provenant d'internet ne pourront atteindre directement les autres serveurs du réseau non exposé (deuxième interface de votre serveur), car le serveur ne fera pas suivre ces paquets, même s'il connait la route par lesquels ils sont censés passer.
Dans le cas où ce sysctl est à 1 (IP forwarding activé), alors les paquets reçus par le serveur sans lui être destinés, mais pour lesquels il connait une route seront automatiquement envoyés sur cette route, le serveur pourrait alors servir de pont entre deux réseaux sans que cela ne soit voulu.
À noter que ce paramétrage ne protège pas de tout, si votre serveur est compromis ou si l'application web qu'il héberge est ciblée par une attaque SSRF (Server Side Request Forgery), alors les IP du réseau "interne" pourront tout de même être atteintes.
B. Filtrage par chemin inverse
Le filtrage par chemin inverse ou Reverse Path Filtering est un mécanisme du noyau Linux consistant à vérifier si l'adresse source indiquée dans les paquets reçus par une interface est routable par cette interface. En d'autres termes, lorsque notre serveur va recevoir un paquet sur une interface, il va l'ouvrir, regarder quelle est son adresse IP source, puis utiliser sa table de routage pour voir s’il contient une route capable de joindre cette IP source pour l'interface par laquelle il a reçu ce paquet (qui deviendra une IP destination en cas de réponse :)). On pourrait décrire ce mécanisme comme un contrôle de cohérence du serveur qui reçoit un paquet, le serveur cherche à vérifier s'il est normal ou cohérent de recevoir un paquet avec telle IP source sur cette interface.
Dans le cas où ce "contrôle de cohérence" échoue, le paquet est supprimé ("droppé" pourrait-on dire en bon français). L'ANSSI recommande d'activer cette fonctionnalité en mettant une valeur 1 aux sysctl suivants :
À noter que les systèmes Red Hat possèdent une option supplémentaire (2) permettant d'accepter un paquet si son IP source est routable par n'importe quelle interface du serveur, et non pas uniquement par l'interface ayant réceptionné le paquet analysé.
Le reverse path filtering est en réalité un mécanisme créé pour limiter les attaques par Déni de Service (Denial of Service ou DoS). L'une des techniques de déni de service profite du Three way Handshake TCP combiné à de l'IP spoofing. Plus clairement, l'attaquant va envoyer des milliers de paquets TCP SYN au serveur avec des adresses IP usurpées ou n'existant pas. Le serveur va alors renvoyer à ces adresses IP un paquet SYN/ACK et n'obtiendra jamais de réponse. Ainsi, les connexions resteront ouvertes pendant un long moment, ce qui les rendra indisponibles pour de nouvelles connexions légitimes. Un peu comme si l'on réservait toutes les tables d'un restaurant sur une semaine sans venir y manger :).
Lorsqu'une telle attaque intervient avec un rp_filter activé, la plupart des paquets seront droppés dès leur réception, car le système remarquera qu'ils ne sont pas légitimes pour arriver sur une interface réseau donnée.
C. Redirections ICMP
L'ICMP (Internet Control Message Protocol) est un protocole qui ne se réduit pas au ping, les paquets echo request (paquet ICMP de type 8) et echo reply (paquet ICMP de type 0) observés lorsqu'on fait un ping ne sont qu'une petite partie des capacités de ce protocole. Parmi les fonctions méconnues de ce dernier, les paquets ICMP de type 5, nommés Redirect Messages sont utilisés afin d'avertir un hôte nous ayant envoyé un message qu'une autre route est possible (et plus rapide) pour joindre l'hôte qu'il cherche à contacter.
Ce mécanisme se nomme l'ICMP redirect est n'est utilisé qu'à de rares occasions (voire jamais) sur un système d'information moderne correctement configuré, et comme tout en sécurité, si c'est inutile, c'est à désactiver.
En soit, ce mécanisme de l'ICMP redirectpermet donc à un hôte recevant un paquet de faire passer son correspondant par un autre chemin réseau, en lui indiquant une nouvelle route qu'il intégrera durablement dans sa table de routage, un attaquant utilisant ce mécanisme envers un système peut donc modifier le chemin qu'emprunterons les futurs paquets, et pourquoi pas provoquer une attaque de type Man in the Middle ou une simple interruption de service. C'est pourquoi l'ANSSI recommande de désactiver l'acceptation et l'envoi de paquets ICMP redirect.
Le sysctl secure_redirects correspond à une option permettant à l'hôte d'accepter un paquet ICMP redirect uniquement si celui provient de l'adresse IP d'une des passerelles enregistrées au niveau de la configuration réseau. On cherche ici a maintenir l'utilisation de l'ICMP redirect, mais à réduire les hôtes pouvant nous envoyés de tels paquets à une liste de confiance.
D. Source routing
Pour l'expéditeur d'un paquet IP, le mécanisme du source routing consiste en la possibilité de définir la route prise par ce paquet sur le réseau. Alors que dans la plupart des cas, un paquet IP est envoyé par son expéditeur sur la passerelle réseau, qui définit ensuite en fonction de sa table de routage quel sera le prochain saut ou la prochaine passerelle à atteindre. Dans le cas d'un source routing, l'expéditeur peut inclure dans le paquet IP une liste d'adresses IP par lequel le paquet devra passer et ainsi modifier la décision nominale des différentes passerelles du réseau qui seront traversées. En d'autres termes, l'expéditeur peut manipuler une partie de la décision des passerelles concernant le routage des paquets. Également, le chemin par lequel le paquet est passé peut être transmis à son destinataire, qui prendra potentiellement ce chemin pour ses réponses. Les guides de bonnes pratiques recommandent de désactiver cette fonctionnalité :
Dans les faits, le source routing au niveau d'un paquet IP n'est presque jamais utilisé, il peut être utile pour du débogage (notamment pour du traceroute). En plus d'aider à dresser une cartographie du réseau, le source routing reste intéressant pour un attaquant, car il peut permettre de joindre une machine sur un réseau qui n'est, selon les tables de routages habituelles, pas accessibles au travers un serveur ayant deux interfaces réseau par exemple.
E. Journalisation des martians packet
L'IANA définit un paquet "martien" comme un paquet qui arrive sur une interface n'utilisant pas le réseau source ou destination du paquet reçu. Pour Linux, il s’agit de tout paquet qui arrive sur une interface qui n’est en aucun cas configurée pour ce sous-réseau.
net.ipv4.conf.all.log_martians = 1
L'objectif de la journalisation des IP "anormales" est justement de pouvoir investiguer, voire alerter et réagir sur un comportement réseau qui n'est pas usuel. Il est en effet courant qu'un attaquant produise ce genre de comportements anormaux lors d'une phase de cartographie, d'une analyse comportementale d'un hôte ou d'un service pour en déterminer la nature (version, technologie précise), voir de causer un bug ou d'exploiter une vulnérabilité.
Dans les faits, la journalisation d'un tel paquet aura aussi de grandes chances de provenir d'une erreur de configuration au niveau des routes et des routeurs du réseau, le but pourrait donc également être d'avertir les administrateurs d'un potentiel problème de routage.
F. RFC 1337
La RFC 1337 est une RFC de type Informationnal (non obligatoire en somme) qui décrit un bug théoriquement possible sur des connexions TCP, ce bug est nommé "TIME-WAIT Assassination hazards". En somme, il s'agit d'une "lacune" dans la conception de TCP/IP qui rend possible la fermeture d'une connexion en TIME-WAIT par un paquet provenant d'une ancienne session TCP (arrivé en retard ou en dupliqué à cause d'une latence quelconque). Ce cas de figure théorique peut donc perturber des communications établies entre un client et un serveur :
net.ipv4.tcp_rfc1337 = 1
Cette protection vise donc à se protéger d'une anomalie potentielle dans les communications TCP, qui n'est pas le fruit d'une attaque ciblée visant à avoir un résultat précis.
G. Ignorer les réponses non conformes à la RFC 1122
Certains routeurs sur Internet ignorent les normes établies dans la RFC 1122 et envoient de fausses réponses aux trames de diffusion. Normalement, ces violations sont journalisées via les fonctions de journalisation du noyau, mais si vous ne voulez pas voir ces messages d'erreur dans vos journaux, vous pouvez activer cette variable, ce qui conduira à ignorer totalement tous ces messages d'erreur.
La RFC 1122 normalise ce que toute machine terminale (host, par opposition à routeur) connectée à l'Internet devrait savoir. Je vous invite à consulter la description de Stéphane Borztmeyer sur son blog pour plus de détails : RFC 1122: Requirements for Internet Hosts - Communication Layers
net.ipv4.icmp_ignore_bogus_error_responses = 1
L'objectif est donc simplement d'économiser un tout petit peu d'espace disque et d'éviter la présence de certains évènements inutiles dans les journaux. Peu d'impact en termes de sécurité donc.
H. Augmenter la plage pour les ports éphémères
Les ports éphémères sont les ports utilisés comme port source lorsqu'un système initie une connexion vers un serveur (alors nommés "port client"). Ces ports peuvent également être utilisés par certains protocoles dans une seconde phase d'échange avec le client après un premier échange sur un port "officiel". C'est notamment le cas pour les protocoles TFTP ou RPC. Sur les serveurs à haut trafic (reverse proxy ou load balancer), il est recommandé d'élargir la plage de port par rapport à celle par défaut :
net.ipv4.ip_local_port_range = 32768 65535
À noter que 65535 est la valeur la plus haute pouvant être acceptée. La valeur la plus basse (ici 32768) peut aller jusqu'à 0, gardez cependant à l'esprit que de nombreux ports sont réservés à des usages spécifiques (22 pour SSH, 80 pour HTTP, etc.). Il est donc plus sage de ne pas empiéter sur ces ports-là.
Le gain n'est pas très significatif, mais ce faisant, nous permettons au serveur d'établir plus de connexions et limitons ainsi les risques de saturation de ces ports pouvant être provoqués intentionnellement (attaque par déni de service) ou non (trafic réseau exceptionnellement élevé).
I. Utiliser les SYN cookies
Les SYN cookies sont des valeurs particulières des numéros de séquences initiales générés par un serveur (ISN: Initial Sequence Number) lors d'une demande de connexion TCP. Les bonnes pratiques de sécurité recommandent leur activation au niveau des échanges réseau :
net.ipv4.tcp_syncookies = 1
L'activation des SYN cookies au niveau du système permet de se protéger des attaques par inondation de requêtes SYN (SYN flooding) qui consiste à ouvrir un très grand nombre de connexions sur un serveur à l'aide de requêtes SYN, sans jamais donner suite au Three Way Handshake TCP (SYN, SYN/ACK, ACK). Le serveur maintient donc un ensemble de connexions en attente (attente de réception d'un ACK après envoi d'un SYN/ACK), ce qui finit par saturer les connexions disponibles pour les clients légitimes.
Ce mécanisme permet au serveur de garder la "tête froide" lorsqu'il est ciblé par une telle attaque, mais il n'est pas conçu pour améliorer les capacités du serveur dans un contexte normal de fonctionnement (autre qu'une attaque par SYN flood).
Attention toutefois : les SYN cookies ne sont en théorie pas conforme au protocole TCP et empêchent l'utilisation d'extension TCP, ils peuvent entraîner une dégradation sérieuse de certains services (par exemple le relais SMTP). Si vous voulez tester les effets des SYN cookies sur vos connexions réseau, vous pouvez paramétrer ce sysctl sur 2 pour activer sans condition la génération de SYN cookies.
J. Gestion de l'IPv6
Dans le cas où l'IPv6 n'est pas activement utilisé au sein de vos réseaux locaux (c'est très très souvent le cas), il est tout simplement recommandé de désactiver la prise en compte de l'IPv6 au niveau du noyau Linux.
La désactivation pure et simple de l'IPv6 permet de réduire la surface d'attaque du serveur, ce qui est l'un des principaux fondements de la sécurité. Dans bien des cas, l'IPv6 peut être utilisé pour détourner du trafic réseau, réaliser des attaques par déni de service ou contourner des politiques de filtrage lorsqu'il n'est pas activement utilisé et pris en compte dans la configuration et le durcissement global d'un système d'information.
K. Gestion de l'auto-configuration IPv6
Dans le cas, très rare selon moi, où vous utilisez de manière active l'IPv6 dans vos infrastructures internes, différents paramètres peuvent être utilisés afin de durcir la configuration de vos systèmes.
En IPv6, les router advertisements sont des paquets régulièrement envoyés par les routeurs d'un réseau pour s'annoncer aux éventuels nouveaux venus. Les informations contenues dans les router advertisements permettent à un nouvel hôte connecté de récupérer les caractéristiques essentielles du réseau, passerelles par défaut, routes et le préfixe servant à se forger une adresse IPv6 en auto configuration.
Dans le cas où les adresses IPv6 sont établies de manière statique sur vos réseaux, il est recommandé de désactiver la prise en charge des router advertisements afin de ne pas laisser la possibilité à un attaquant d'utiliser leur prise en charge sur les systèmes du réseau pour lui-même déterminer la configuration IPv6 de ces systèmes . En effet, quoi de plus simple que de se faire passer pour un routeur ou une passerelle pour réaliser une attaque par l'homme du milieu ?
# Ne pas accepter les router preferences par router advertisements
net.ipv6.conf.all.accept_ra_rtr_pref = 0
net.ipv6.conf.default.accept_ra_rtr_pref = 0
# Pas de configuration automatique des prefix par router advertisements
net.ipv6.conf.all.accept_ra_pinfo = 0
net.ipv6.conf.default.accept_ra_pinfo = 0
# Pas d’apprentissage de la passerelle par router advertisements
net.ipv6.conf.all.accept_ra_defrtr = 0
net.ipv6.conf.default.accept_ra_defrtr = 0
# Pas de configuration auto des adresses à partir des router advertisements
net.ipv6.conf.all.autoconf = 0
net.ipv6.conf.default.autoconf = 0
L. Désactiver le support des "router solicitations" IPv6
En IPv6, le router sollicitation est un type de message qui permet à un hôte de demander à tous les routeurs présents sur le réseau local de lui envoyer un Router Advertisement, afin qu'il l'enregistre dans sa liste de voisins et qu'il puisse récupérer les éléments essentiels du réseau IPv6. Dans le cas où les adresses IPv6 sont paramétrées en statique, il est recommandé de désactiver ce mécanisme :
Pour être plus précis, ce sysctl configure le nombre de router sollicitation à envoyer sur le réseau avant de considérer qu'il n'y a pas de routeur sur le réseau. Désactiver ce comportement lorsque les adresses IPv6 sont statiques permet donc d'éviter du trafic inutile, mais également qu'un attaquant puisse répondre à ces sollicitations en vue de se faire passer pour un routeur IPv6 auprès de votre serveur, lui facilitant ainsi le travail pour la réalisation d'une attaque de type man in the middle.
M. Nombre maximal d’adresses autoconfigurées par interface
L'adressage IPv6 permet d'utiliser plusieurs adresses par interface. À moins que vous n'ayez un besoin particulier nécessitant plusieurs adresses IPv6 unicast global par interface, il est recommandé de paramétrer ce sysctl à 1, ce qui limite à 1 le nombre d'adresses unicast global par interface (16 possibles dans la configuration par défaut).
Attention, positionner ces sysctl à 0 rend illimité le nombre d'adresses possibles, ce qui finira par avoir un impact sur les performances de votre serveur.
J'ai toutefois du mal à trouver des risques concrets relatifs à la non-application de ce paramètre. D'après ma compréhension du paramètre dans son état par défaut et du fonctionnement de l'IPv6, sa non-application entrainera la possibilité pour un attaquant de générer la création d'une adresse IPv6 sur sa cible puisque dans un environnement "normal", les 16 slots disponibles sur l'interface IPv6 ne seront pas toutes utilisées. En principe on laisse donc au travers la configuration par défaut, des paramètres non utilisés qui n'attendent qu'à recevoir les faux router avertissements d'un attaquant. Alors que si le nombre d'adresses IPv6 est limité à 1 par interface est que celle-ci est déjà configurée lors de la venue de l'attaquant (en statique qui plus est), ce dernier n'aura pas de porte d'entrée possible.
N'hésitez pas à ajouter des informations de compréhension supplémentaires dans les commentaires si vous en avez à ce sujet :).
III. Conclusion
Voilà, nous avons fait le tour des durcissements sysctl recommandés par l'ANSSI dans son guide Recommandations de configuration d'un système GNU/Linux. Vous aurez compris que les raisons de certains durcissements sont faciles à appréhender alors que d'autres sont plus bien abstraits ou répondent à des cas très spécifiques. Quoi qu'il en soit j'espère vous avoir apporté une lumière supplémentaire sur ces éléments.
N'hésitez pas à signaler toute erreur ou précision technique dans les commentaires
Nous allons dans cet article nous intéresser aux durcissements du noyau proposés par le guide de configuration de l'ANSSI à travers les sysctl. Les guides de bonnes pratiques et de configuration de l'ANSSI sont pour la plupart très pertinents, mais il arrive qu'ils manquent de détails et que la cohérence de certains durcissements puisse être difficile à appréhender. Je vais donc ici m'efforcer de décortiquer les recommandations 22 et 23 du Guide Recommandation de configuration d'un système GNU/Linux de l'ANSSI qui portent sur les paramétrages des sysctl réseau et système en vue du durcissement d'un noyau Linux. Nous parlerons dans cet article des sysctl système et un prochain article portera sur les sysctl réseau.
J'essaierai notamment de mettre en avant les implications en termes de sécurité et les attaques qu'un durcissement permet d'éviter, sans oublier les potentiels effets de bords si ceux-ci sont connus et les éventuelles questions qui restent en suspens après avoir tenté de creuser ce sujet.
Sur les OS Linux, sysctl est utilisé afin de consulter et modifier les paramètres du noyau, cela nous permet donc de configurer certains comportements du noyau comme la prise en compte de l'IPv6 sur nos interfaces réseau ou l'activation de l'ASLR. Les paramètres utilisables sont ceux listés dans le répertoire /proc/sys.
On parle souvent de sysctl pour décrire une clé de configuration paramétrable par la commande sysctl. Ne soyez donc pas étonné de lire "On configure le sysctl net.ipv4.ip_forward à 0" pour indiquer que la clé de configuration net.ipv4.ip_forward doit être définie à 0, par exemple
Pour les systèmes utilisant systemd, la configuration des sysctl se trouve dans /etc/sysctl.d/.conf, /usr/lib/sysctl.d/.conf. et /etc/sysctl.conf.
Attention, depuis récemment (2017) il se peut que certains systèmes utilisant systemd n'appliquent plus les configurations sysctl indiquées dans /etc/sysctl.conf. Seuls les fichiers ayant une extensions .conf et situés dans les répertoires /etc/sysctl.d ou /usr/lib/sysctl.d sont appliqués.
II. Comment modifier un sysctl
Il existe deux possibilités de modification d'un sysctl, soit de façon temporaire, c'est à dire valable jusqu'au prochain redémarrage, soit de façon persistante, c'est à dire qui persiste après un redémarrage.
Pour modifier une configuration sysctl de façon temporaire, on peut modifier à chaud la valeur stockée dans le fichier correspondant au sysctl à modifier, par exemple :
# echo 1 > /proc/sys/kernel/sysrq
Ou utiliser la commande sysctl pour faire cette même opération :
# sysctl -w kernel.sysrq=1
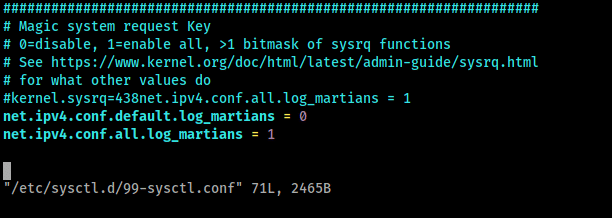
Pour modifier un sysctl de façon persistante, il faut aller modifier le fichier configuration (/etc/sysctl.d/99-sysctl.conf, ou autre fichier finissant par .conf dans le même dossier) et y modifier ou ajouter notre valeur pour le sysctl souhaité :
Modification persistante d'une sysctl
Pour être techniquement plus précis, une configuration modifiant un sysctl est appelée clé. Ici la clé est donc net.ipv4.conf.default.log_martians et 0 est la valeur associée à cette clé.
Pour afficher l'ensemble des sysctl actuellement utilisées et appliquées, la commande suivante est à utiliser :
# sysctl -a
Enfin pour récupérer un sysctl précis, la commande suivante est à utiliser :
# sysctl -n net.ipv4.conf.eth1.log_martians
III. Durcissement des sysctl système Linux
A. Désactivation des SysReq
Les SysReq ou Magic System Request Key sont une fonctionnalité du noyau Linux permettant, via une combinaison de touche réalisable à tout moment, de lancer des commandes bas niveau, par exemple afin de pouvoir redémarrer un système bloqué sans corrompre le système de fichiers ou tuer un programme paralysant les ressources du système. Parmi les actions réalisables :
Déterminer le niveau de log de la console
Redémarrer l'ordinateur reBoot
Redémarrer via kexec pour faire un crashdump Crashdump
Envoyer un signal de terminaison (SIGTERM) à tous les processus (sauf init) tErm
Tuer le processus qui consomme le plus de mémoire (via oom-killer)
Envoyer un signal de fin (SIGKILL, plus ferme que SIGTERM) à tous les processus (sauf init)
Tuer tous les processus de la console virtuelle courante.
Envoyer un signal de fin (SIGKILL, plus ferme que SIGTERM) à tous les processus (même init)
Afficher le contenu actuel de la mémoire Memory
Éteindre le systeme via APM Out
Afficher sur la console les registres et drapeaux actuels Print
Basculer la gestion du clavier de mode brute (raw) à XLATE
Synchroniser les disques (tente d'écrire toutes les données non sauvegardées)
Afficher une liste des taches et autres informations dans la console
Remonter les disques en lecture seule
À noter que même si les SysReq sont activées, une partie seulement de ces actions sont réalisables dans la configuration par défaut. D'autres requièrent une configuration spécifique. Cette combinaison de touche clavier doit être réalisée sur un terminal "physique", entendez par là qu'une connexion SSH ne sera pas suffisante, en théorie :).
Il existe en effet une petite astuce permettant d'exécuter des SysReq depuis une connexion distante, et cela en utilisant directement une fonctionnalité "native" de sysctl, le fichier /proc/sysrq-trigger. Si l'on souhaite redémarrer le système par exemple, il faut envoyer l'instruction "b", et donc :
echo "b" > /proc/sysrq-trigger
Ce fichier n'est cependant modifiable que par l'utilisateur root :
Pour gérer cela, il faut se rendre dans le fichier /proc/sys/kernel/sysrq ou utiliser la clé kernel.sysrq dans un fichier de configuration sysctl.
Positionner la valeur 1 permet d'activer l'utilisation des SysReq (valeur par défaut sur une majorité de systèmes), positionner la valeur 0 interdit toute utilisation des SysReq. Lorsque la valeur est autre que 0 ou 1, c'est que certaines commandes sont autorisées, d'autres non, à utiliser en connaissance de cause donc. À nouveau, comme cette fonctionnalité est très rarement utilisée, voir inconnue des sysadmins la plupart du temps, mieux vaut la désactiver :
kernel . sysrq = 0
L'ANSSI recommande en effet de positionner la valeur de cette clé à 0 afin de désactiver totalement leur utilisation. On peut imaginer les effets de bords possibles grâce à ces commandes, notamment en ce qui concerne la possibilité de tuer des processus, afficher les registres CPU, démonter un système de fichier, redémarrer la machine, etc. À noter que le plus grand danger reste l'exploitation de ces SysReq à partir d'un terminal physique par un utilisateur non privilégié, mais leur utilisation n'est pas forcément restreinte au terminal physique comme je l'ai indiqué précédemment.
La frontière entre physique et virtuel s'étant quelque peu estompée ces dernières années, j'ignore par exemple si l'on peut lancer des SysReq à partir d'un clavier virtuel, dans le cas d'un accès distant VNC, via une console d'hyperviseur type VMWare/Proxmox, etc.
B. Interdire les core dump des exécutables setuid
Par défaut, le système va réaliser un core dump (extraction de la mémoire) des processus s'arrêtant brusquement, cela est notamment pratique pour du debug, avoir une photo à l'instant du crash permet de voir quelles données ou actions ont potentiellement causé ce crash.
Cependant, ces dumps sont exécutés par le kernel et écrits sur le système avec les droits de l'utilisateur courant (celui ayant lancé la commande). Dans le cadre de l'utilisation d'un exécutable setuid ou setgid, l'extraction mémoire contiendra les informations d'un programme exécuté avec les droits d'un autre utilisateur, probablement avec un plus haut niveau de privilège que l'utilisateur courant ou root, mais sera écrit sur le système avec les droits de l'utilisateur courant (non privilégié). Ainsi, des informations sensibles, permettant potentiellement une élévation de privilège, pourront se trouver dans ce type de fichier et lisible par l'utilisateur courant.
Afin de contrôler ce comportement, on peut utiliser la clé fs.suid_dumpable afin de ne pas produire de core dump pour les exécutables possédant un bit setuid ou setgid.
fs.suid_dumpable = 0
L'ANSSI recommande de passer la valeur de la clé fs.suid_dumpable à 0 pour désactiver tout core dump sur les exécutables possédant un bit setuid ou setgid, et ainsi éviter d'éventuelles fuites de données sensibles concernant les attributs, les fichiers accédés ou d'autres actions d'un utilisateur privilégié.
C. Déréférencement des liens de fichiers
Une des vulnérabilités courantes sous Linux concernant les liens symboliques est le symlink-based time-of-check-time-of-use race (ou symlink race condition). Il s'agit d'un delta de temps entre le moment où un fichier est contrôlé (pour voir si les droits d'accès sont suffisants) et celui où il est utilisé par un programme.
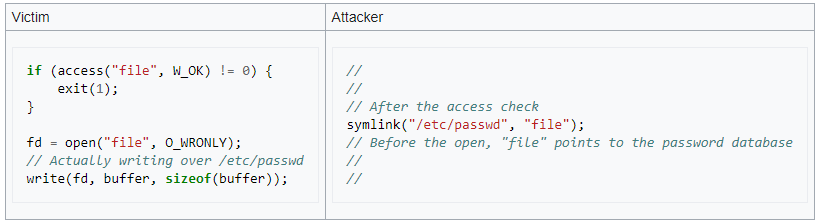
Pendant le laps de temps où ces deux opérations sont effectuées, un utilisateur malveillant peut créer un lien symbolique portant le nom de ce fichier et ainsi manipuler une partie de l'exécution du programme, qui s'exécute idéalement avec un plus haut niveau de privilège. Un exemple courant fourni comme explication est le suivant :
Exemple d'une attaque time-of-check to time-of-use - Wikipedia
Dans cet exemple, le programme contrôle les permissions d'un fichier file avec l'instruction access() en C. Puis, dans un deuxième temps si les permissions le permettent, il va écrire dans ce fichier. Dans le cadre d'une attaque, l'attaquant va laisser le fichier tel quel pour la première opération (par exemple créer lui-même le fichier file en permission 777 pour que le programme constate qu'il peut y écrire). Puis, il va remplacer ce fichier par un lien symbolique pointant vers /etc/passwd. Le programme s'exécutant avec un haut niveau de privilège va alors exécuter sa deuxième instruction et écrire dans le fichier file, qui sera en réalité/etc/passwd.
Un très bon labo est mis à disposition sur ce Gitlab Ranjelikasah/ace-Condition-Seedsecurity, je vous le recommande si vous souhaitez expérimenter par vous-même
Ce type d'attaque est notamment dangereuse sur les setuid/setgid, qui permettent d'exécuter un binaire avec les droits root (ou d'un autre utilisateur en fonction de leur configuration). C'est pourquoi il est recommandé de durcir ces sysctl qui ont plusieurs effets concernant les liens symboliques et les setuid.
Concernant les hardlinks et pour un utilisateur système créant un lien, l'une des conditions suivantes doit être remplie :
l'utilisateur peut seulement créer des liens vers des fichiers dont il est le propriétaire
l'utilisateur doit avoir les droits d'écriture et de lecture vers le fichier vers lequel souhaite créer un lien.
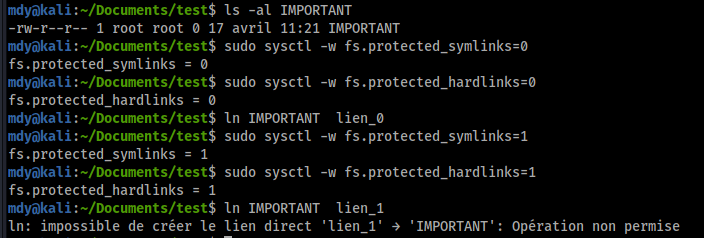
Démonstration de l'effet des durcissements sysctl sur la création des hardlinks
Concernant les symlinks et les processus qui sont amenés à suivre des liens symboliques vers des répertoires world-writable qui ont le sticky bit activé :
le processus suivant le lien symbolique doit être le propriétaire du lien symbolique
le propriétaire du répertoire est également le propriétaire du lien symbolique.
Si vous avez bien compris le fonctionnement de l'attaque présentée, vous comprendrez rapidement quelle devient impossible si ces conditions sont imposées via le durcissement sysctl :
Ce paramétrage permet en somme de durcir les conditions d'utilisation des symlinks et des hardlinks afin de se protéger des différentes attaques permettant une élévation de privilège
D. Activation de l’ ASLR
L'ASLR (Address Space Layout Randomization) est un mécanisme permettant de limiter les effets et de complexifier l'exploitation des attaques de type buffer overflow (dépassement de tampon). L'objectif est ici de placer la zone de données dans la mémoire virtuelle de façon aléatoire, changeant ainsi sa position à chaque exécution.
L'exploitation de buffer overflow consiste notamment à contrôler une partie des registres CPU afin de modifier le flux d'exécution d'un programme. Cela passe, entre autres, par le contrôle du registre EIP (Extended Instruction Pointer) qui permet d'indiquer à quel offset (adresse mémoire) la prochaine instruction à exécuter se trouve. En contrôlant le registre EIP, l'attaquant peut indiquer au programme de sauter à un offset précis et dont le contenu est sous son contrôle, notamment s'il a réussi à injecter du code malveillant (shellcode) à cet endroit de la mémoire. En modifiant la répartition et le positionnement des instructions, de la pile (stack), du tas (heap) et autres, en mémoire, l'attaquant n'est plus en capacité de pointer vers son shellcode car celui-ci ne sera jamais au même endroit à chaque exécution.
Pour activer l'ASLR, on peut utiliser la clé kernel.randomize_va_space et y positionner la valeur 2, qui permet de positionner de façon aléatoire (aka randomiser :/ ) la stack (pile), les pages CDSO (virtual dynamic shared object), la mémoire partagée et le segment de données (data segment), qui contient les variables globales et statiques initialisées par le programme. Positionner la valeur 1 aura le même effet, sauf pour le segment de données. La valeur 0 désactive l'ASLR.
kernel.randomize_va_space = 2
Pour plus d'information sur les buffer overflow, je vous oriente vers les très bons articles (en français) d'0x0ff :
Une vulnérabilité de type NULL pointer dereference est le fait pour un programme d'utiliser un pointeur non initialisé (valant NULL) ou pointant vers une adresse mémoire inexistante (0x00000000). De fait, lorsque ce programme utilisera ce pointeur dans ses instructions, cela causera un crash. Dans le contexte d'exécution du noyau ou d'un programme à haut niveau de privilège, le fait de déclencher intentionnellement l'utilisation d'un pointeur NULL par un attaquant lui permet de faire crasher le programme, voir le système.
Cependant, si l'attaquant parvient à identifier l'adresse mémoire du pointeur en question et à la manipuler pour y insérer les données de son choix avant qu'elle ne soit utilisée activement par le noyau ou un programme à haut niveau de privilège, alors il pourra contrôler son utilisation dans le programme exécuté, menant à une potentielle élévation de privilège.
En C, un pointeur est une variable qui permet de stocker non pas une valeur ("ABC" ou 12,28), mais une adresse mémoire. Lorsqu'un programme démarre, le système lui alloue une zone mémoire dans laquelle il peut s'organiser. Cette zone mémoire est constituée de "cases" de 8 bits (octets). Chacune de ces cases (appelées blocs) est identifiée par un numéro : son adresse. On peut alors accéder à une variable soit par son nom "agePersonne", soit par l'adresse du premier bloc alloué à la variable en question, c'est-à-dire son pointeur.
Il se trouve que le noyau a tendance à plutôt utiliser les adresses mémoires dites "basses", si l'attaquant parvient à manipuler les pointeurs visant des blocs d'adresses mémoires "basses", alors il a plus de chances de trouver un bloc d'adresse qui sera ensuite utilisé par le noyau.
La clé vm.mmap_min_addr est donc une constante qui permet d'empêcher les utilisateurs non privilégiés de créer des mapping mémoires en dessous de cette adresse. Elle permet de définir l'adresse minimale qu'un processus n'ayant pas les droits root peut mapper, adresse que nous allons rehausser par rapport à sa valeur par défaut (0) :
vm.mmap_min_addr = 65536
Attention toutefois à bien tester le fonctionnement de vos programmes et applications avec ce paramètre avant de passer en production.
F. Espace de choix plus grand pour les valeurs de PID
Sous Linux (et Windows), le PID (Process IDentifier) est un numéro unique assigné à un processus en cours d'exécution. Il permet son identification parmi d'autres processus pour leur gestion, par exemple lorsque l'on utilise les commandes ps ou kill.
Comme pour les ports clients, les PID sont en nombre limité sur un système. Il se peut donc que toute la plage de PID disponible soit saturée par un dysfonctionnement ou une attaque. Dès lors, aucun autre processus ne pourra être créé, car il n'aura aucun PID à utiliser. L'ANSSI recommande d'élargir la plage du nombre de PID disponible sur un système afin d'éviter ou de limiter de tels scénarios :
kernel.pid_max = 65536
Cette configuration permet donc de prévenir d'une saturation de PID entrainant une impossibilité de créer de nouveau processus. Sur les systèmes 32 bits, la valeur max est de 32 768 alors que pour les systèmes 64 bits, elle est de 2^22 (4 194 304, ça fait beaucoup de processus). À noter toutefois que les PID sont "recyclés", c'est-à-dire que lorsqu'un processus avec un certain PID se termine, ce PID peut être réutilisé plus tard par un autre processus. Ce durcissement vise donc à élargir le nombre de processus tournant simultanément sur votre système, ce qui ne sera le cas qu'en cas d'attaque ou pour des serveurs à très haute performance.
G. Obfuscation des adresses mémoires kernel
Un attaquant qui cherche à compromettre un noyau en cours d'exécution en écrasant les structures de données du noyau ou en forçant un jump (saut) vers un code de noyau spécifique doit, dans les deux cas, avoir une idée de l'emplacement des objets cibles en mémoire. Des techniques comme l'ASLR ont été créées dans l'espoir de "dissimuler" cette information, mais cet effort est vain si le noyau divulgue des informations sur l'endroit où il a été placé en mémoire. Il existe en effet plusieurs cas de figure où des adresses mémoires relatives au kernel peuvent être affichées (fuitées) vers l'espace utilisateur, qui obtient alors des informations intéressantes sur les pointeurs à cibler dans le cadre d'une attaque.
L'ANSSI recommande de paramétrer la directive suivante à 1 afin que, dans certains cas, les adresses mémoires relatives au noyau affichées par un programme soit dissimulées (remplacées par des 0) :
kernel.kptr_restrict = 1
Attention toutefois, cette dissimulation n'est effective uniquement si le programme utilise la notation %pK (au lieu de %p pour un pointeur "normal"). C'est-à-dire que le développeur a marqué le pointeur vers une adresse noyau comme tel et indique donc au système que l'information doit être protégée. Dans le cas où un programme ne respecte pas cette bonne pratique, le durcissement au niveau du sysctl est inutile.
Enfin, si l'utilisateur possède la capabilities CAP_SYSLOG dans le contexte d'exécution du programme, les adresses mémoire kernel seront affichées normalement (paramétrez la sysctl à 2 si vous souhaitez éviter ce cas de figure).
H. Restriction d’accès au buffer dmesg
Sous Linux, la commande dmesg permet de voir les journaux (plus précisément la mémoire tampon des messages) relatifs au kernel, par exemple ceux créés par les drivers, lors du démarrage du système ou au branchement d'un nouveau périphérique. Ces messages sont ensuite stockés dans le fichier /var/log/messages.
L'ANSSI recommande de configurer le sysctl suivant à 1 afin de n'autoriser que les utilisateurs privilégiés à consulter ce type d'information via la commande dmesg :
kernel.dmesg_restrict = 1
L'objectif est ici de dissimuler les informations relatives aux journaux du noyau de la vue des utilisateurs, ceux-ci peuvent en effet dans certains cas contenir des informations sensibles pouvant être utilisées dans le cadre de futures attaques.
Voici un exemple de l'utilisation de la commande dmesg par un utilisateur non privilégié avec le paramétrage à 1, puis à 0 :
Effet de la sysctl kernel.dmesg_restrict
I. Restreindre l’utilisation du sous-système perf
Sous Linux, le sous-système perf est une commande très complète et puissante qui permet de mesurer les performances d'un programme ou du système. Il réalise ces mesures en étant au plus proche de l'hardware, ce qui nécessite un niveau de privilège élevé.
L'ANSSI recommande le paramétrage à 2 de la sysctl suivante afin de limiter l'accès des utilisateurs non privilégiés à cette commande :
kernel.perf_event_paranoid = 2
Ainsi, un utilisateur non privilégié ne sera pas en mesure d'utiliser cette commande, qui peut notamment impacter les performances du système. Ce paramétrage est effectif sauf si l'utilisateur en question possède la capabilities CAP_SYS_ADMIN.
Également, les deux sysctl suivantes doivent être paramétrées à 1 :
Ces deux sysctl servent à gérer combien de ressource et de temps CPU le système de performance peut utiliser. Il s'agit d'un pourcentage (1% du temps CPU). Ces configurations visent à limiter l'impact du sous-système perf sur le système lors de son utilisation. Attention, mettre ces deux sysctl à 0 fait tout simplement sauter toute limite, ce qui serait contre-productif
Quoi qu'il en soit l'idée derrière le paramétrage de ces deux sysctl est de limiter l'impact du sous-système perf. sur les performances du système.
Rendez-vous dans le prochain article pour l'étude des durcissement des sysctl réseau :). N'hésitez pas à signaler toute erreur ou précision technique dans les commentaires
Pour ce Patch Tuesday de Mai 2021, Microsoft a corrigé 55 vulnérabilités, dont 4 considérées comme critiques et 3 failles Zero Day.
Trois failles Zero Day corrigées
Commençons par les trois failles Zero Day corrigées au sein des produits Microsoft. Bien qu'elles étaient connues publiquement, elles ne sont pas exploitées dans le cadre d'attaques. Les trois failles en question sont les suivantes :
Il s'agit d'une faille dans .NET et Visual Studio qui permet une élévation de privilèges. Cela concerne les framework .NET 5.0 et .NET Core 3.1, tandis que pour Visual Studio, il y a plusieurs versions touchées : Visual Studio 2019 version 16.X sur Windows et Visual Studio 2019 version 8.9 sur macOS.
Cette faille de sécurité au sein d'Exchange a été découverte lors de la compétition de hacking Pwn2Own 2021 par l'équipe Devcore. Il s'agit d'une attaque complexe à mettre en œuvre d'après Microsoft et qui nécessite des privilèges élevés. D'ailleurs, lors de la compétition Pwn2Own, l'équipe de Devcore a effectué une élévation de privilèges avant de pouvoir exploiter cette faille.
Voici les versions d'Exchange Server concernées :
Microsoft Exchange Server 2013 Cumulative Update 23 Microsoft Exchange Server 2016 Cumulative Update 19 et Cumulative Update 20 Microsoft Exchange Server 2019 Cumulative Update 9 et Cumulative Update 8
Cette troisième et dernière faille Zero Day touche la boîte à outils Microsoft Neural Network Intelligence (NNI). Il s'agit d'une faille qui permet une exécution de code à distance. Abhiram V. de chez Resec System a corrigé cette faille directement sur le Github du projet, en poussant une nouvelle version du fichier common_utils.py.
Mai 2021 - Patch cumulatif pour Windows 10
Pour information, voici les noms des KB pour Windows 10 :
- Windows 10 version 1507 — KB5003172 (OS Build 10240.18932)
- Windows 10 version 1607 — KB5003197 (OS Build 14393.4402)
- Windows 10 version 1703 — Fin de support
- Windows 10 version 1709 — Fin de support
- Windows 10 version 1803 — KB5003174 (OS Build 17134.2208)
- Windows 10 version 1809 — KB5003171 (OS Build 17763.1935)
- Windows 10 version 1909 — KB5003169 (OS Build 18363.1556)
- Windows 10 version 2004 et 20H2 — KB5003173 (OS Build 19041.985 et 19042.985)
Les autres mises à jour de Mai 2021...
Mise à part les failles Zero Day, Microsoft a corrigé des vulnérabilités dans d'autres produits comme Windows 10, Office ou encore Internet Explorer. La liste des produits est longue et variée comme d'habitude.
Attention à ces quatre failles considérées comme critiques :
D'ailleurs, la faille Hyper-V est particulièrement inquiétante : l'attaque s'effectue par le réseau, et Microsoft précise sur son site que le niveau de complexité pour l'exploiter est faible et qu'il ne faut pas spécialement de privilèges élevés. La Zero Day Initiative a attribué un score CVSS de 9.9 sur 10 à cette faille de sécurité.
La Zero Day Initiative alerte également les entreprises sur la faille qui touche la pile du protocole HTTP. En effet, cette faille permet à un attaquant non authentifié d'exécuter du code dans le noyau de Windows. Un paquet spécialement conçu peut affecter une machine non patchée. En plus, à la question "Is this wormable ?" Microsoft a précisé "Yes" sur son site donc on peut considérer que cette faille de sécurité est exploitable par un ver informatique.
Bon, maintenant, il ne reste plus qu'à espérer qu'il n'y ait pas de trop de problèmes sur nos machines dans les prochains jours après l'installation des patchs... En tout cas, pour le moment c'est Outlook qui est en difficulté : Outlook : une mise à jour vous empêche de lire ou d'écrire un nouvel e-mail
 Téléchargement sur Android (via le Play Store)
Téléchargement sur Android (via le Play Store) Tutoriel disponible au format vidéo (plus complète sur la partie démo) :
Tutoriel disponible au format vidéo (plus complète sur la partie démo) :