Mise à jour
Mise à jour de la base de données, veuillez patienter...
source: Korben
Ce week end, je vous ai expliqué comment balancer vos backups automatiquement sur Amazon S3, mais si voulez faire certaines choses manuellement, il existe l'outil parfait pour ça : S3cmd.
S3cmd, c'est tout simplement une interface en ligne de commande pour piloter son Amazon S3.
Pour l'installer (ubuntu / debian), faites (sinon, les binaires sont là) :
sudo apt-get s3cmd
Ensuite, il faut le configurer :
s3cmd --configure
Suivez les instructions. En gros, vous avez besoin de votre clé d'accès et de votre clé secrète S3. Pour savoir comment les récupérer, je vous invite à lire la partie sur IAM dans ce tuto.
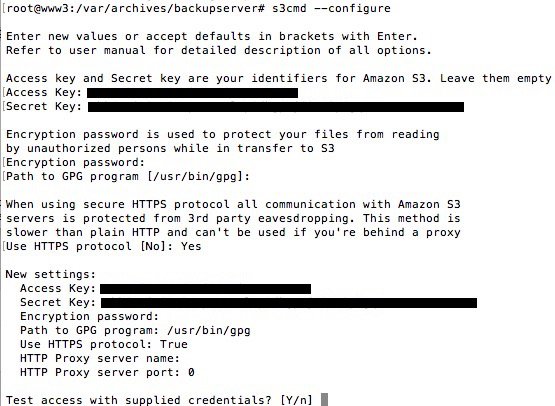
Le processus de config vous demandera aussi un mot de passe pour chiffrer les fichiers envoyés vers le S3. Ce n'est pas obligatoire, à vous de voir. Par contre, je vous recommande vivement d'accepter l'utilisation du protocole HTTPS ("Use HTTPS protocol : Yes") pour que les fichiers soient transmis au serveur S3 avec un minimum de sécurité. Si ce sont des fichiers publics, vous pouvez passer en HTTP, ce sera un peu plus rapide.
Voilà, maintenant que c'est configuré, on va pouvoir jouer. Première étape, lister les buckets présents sur Amazon S3 :
s3cmd ls
Ensuite, pour créer un nouveau bucket :
s3cmd mb s3://monbucket
Maintenant on va mettre des trucs dedans avec le paramètre put :
s3cmd put fichier.jpg s3://monbucket
Pour y balancer carrément un répertoire, il faut utiliser le paramètre -r
s3cmd put -r monrepertoire s3://monbucket
Attention, petite subtilité, si vous voulez uploader uniquement le contenu de ce répertoire (et pas le répertoire lui-même), pensez à mettre un / après le nom :
s3cmd put -r monrepertoire/ s3://monbucket
Maintenant pour vérifier que tout est bien en place sur le bucket, il suffit de faire un petit ls
s3cmd ls s3://monbucket
Pour connaitre la taille de votre bucket, faites un
s3cmd du s3://monbucket
Pour récupérer l'un de ces fichiers, utilisons maintenant get
s3cmd get s3://monbucket/fichier.jpg
Pour copier un fichier d'un endroit à un autre du bucket (ou de 2 buckets différents), faites :
s3cmd cp s3://monbucket/fichier.jpg s3://monbucket/autre_dossier/fichier.jpg
Pour déplacer un fichier, même principe :
s3cmd mv s3://monbucket/fichier.jpg s3://monbucket/autre_dossier/fichier.jpg
Voilà, maintenant vous maitrisez S3cmd. Maintenant si vous voulez supprimer un truc (fichier ou dossier), il faut faire :
s3cmd del s3://monbucket/fichier.jpg
Vous pouvez aussi utiliser l'alias "rm" à la place de "del".
Sachez enfin que pour supprimer totalement un bucket il faut que ce dernier soit vide. Pensez donc bien à en supprimer tout le contenu avant de supprimer le bucket en lui-même. Voici comment supprimer un bucket vide :
s3cmd rb s3://monbucket
Si vous placez des choses dans Glacier comme je vous ai expliqué sur mon tuto précédent, vous pouvez aussi restaurer des fichiers à partir de celui-ci avec la commande
s3cmd restore s3://monbucket/fichier.jpg
Si vous avez besoin de synchroniser un répertoire local avec un répertoire S3, utilisez la commande sync. Elle utilisera les MD5 des fichiers pour savoir quoi envoyer et quoi mettre à jour sur votre S3 ou en local sur votre disque dur.
s3cmd sync monrepertoire s3://monbucket/monrepertoire
Et voilà.. Rien de plus simple à utiliser en fait, alors pourquoi s'en passer ?
S3cmd propose aussi des choses un peu plus évoluées pour gérer les droits d'accès, jouer avec les archives splittées, régler le cycle de vie des buckets, ou encore publier sur le web mais je n'ai pas encore testé toute cette partie, donc je vous invite à vous pencher sur la doc ;-).
Cet article merveilleux et sans aucun égal intitulé : Installer et utiliser s3cmd pour gérer Amazon S3 en ligne de commande ; a été publié sur Korben, le seul site qui t'aime plus fort que tes parents.
Voici un service original qui m'a été remonté par Guillaume. Cela s'appelle Dply et ça permet en quelques secondes et gratuitement, d'avoir un serveur virtuel (VPS) pour tester votre code ou vos applications.
Les VPS ont la config suivante : 1 CPU, 512 MB de RAM et 20 GB de SSD. Pour avoir votre instance, il suffit de se connecter avec son compte Github et d'utiliser la clé SSH de celui-ci.
Niveau OS, vous pouvez avoir sur le serveur, les distribs suivantes :
Alors je disais que c'était gratuit, mais pour être plus précis, c'est gratuit pendant 2h. Au-delà, il faudra payer... Mais bon, ça reste raisonnable. Voici les tarifs :
Cela peut permettre à n'importe qui de tester rapidement un script ou un bout de code, directement sur un serveur, sans avoir à mobiliser des ressources ou à prendre des risques avec un serveur déjà utilisé pour autre chose.
Bref, à bookmarker pour le jour où vous avez besoin d'un serveur ou d'un peu de ressource.
Cet article merveilleux et sans aucun égal intitulé : Dply – Un VPS gratuit pour 2h ; a été publié sur Korben, le seul site qui t'aime plus fort que tes parents.
Dans la vie, y'a 2 choses vraiment importantes.
Alors on va voir aujourd'hui comment mettre en place une sauvegarde d'un Linux avec upload vers Amazon S3 (mais vous pourrez aussi faire de l'upload vers FTP ou un autre serveur via SSH).
Et pour cela, on va utiliser Backup Manager. Le site officiel a disparu, mais les sources sont sur Github et apparemment toujours maintenues. Vous allez voir c'est très simple.

Placez vous dans votre répertoire home
cd ~
Et clonez le dépôt git
git clone https://github.com/sukria/Backup-Manager.git
Placez vous dedans
cd Backup-Manager
et installez Backup Manager avec la commande (vous devrez peut être utiliser sudo)
make install
Copiez le fichier de conf dans /etc/.
cp /usr/share/backup-manager/backup-manager.conf.tpl /etc/backup-manager.conf
Puis ouvrez ce fichier.
nano /etc/backup-manager.conf
On va regarder ça ensemble et je vais me concentrer uniquement sur les paramètres essentiels. Pour le reste, je vous laisserai vous documenter.
Dans la section Repository, choisissez le répertoire (BM_REPOSITORY_ROOT) où seront stockés les backups en local. Par défaut c'est /var/archives.
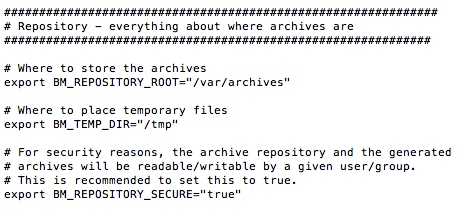
Si vous avez de la place sur votre disque à cet endroit, créez un répertoire /var/archives (mkdir /var/archives) et ne touchez pas à ce paramètre.
Concernant les backups, vous devez aussi préciser le nombre de jours que vous voulez garder (BM_ARCHIVE_TTL). Ici c'est 5 jours, mais en ce qui me concerne, je mets un peu plus, car j'ai de la place sur le disque dur.
![]()
On va ensuite choisir la méthode de sauvegarde. Vous pouvez faire uniquement un export tarball (archive simple) ou un export tarball incrémentale (archive complète + archives différentielles), un export svn, un export mysql...etc.
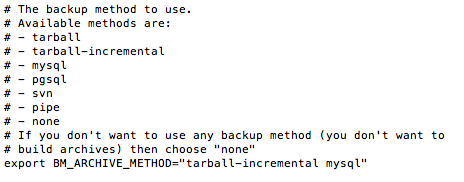
Comme vous pouvez le voir, moi j'ai mis pour le paramètre BM_ARCHIVE_METHOD : "tarball-incremental mysql"
Cela va déclencher un backup incrémental et un backup MySQL. Sachez que même si vous choisissez tarball-incremental, vous devez quand même éditer la section tarball ci-dessous.
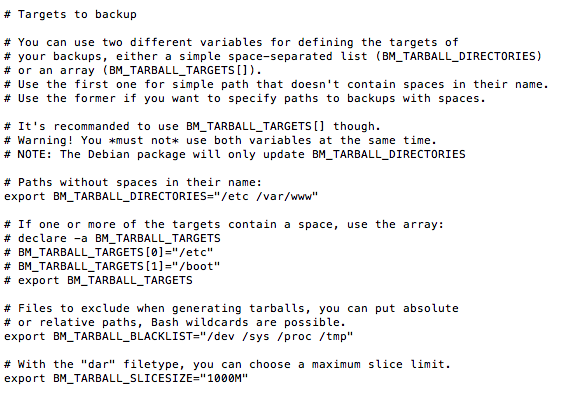
Au niveau de BM_TARBALL_DIRECTORIES, vous devez lister les répertoires que vous souhaitez sauvegarder. En ce qui me concerne, ce sera /etc et /var/www. Mais ça peut aussi être /home/ ...etc
Un peu plus bas, BM_TARBALL_BLACKLIST concerne les répertoires à exclure du backup. Cela peut être pratique si vous voulez sauvegarder tout votre répertoire /home, mais pas /home/archives qui contient vos backups ou d'autres choses dont vous n'avez pas besoin..
Enfin, BM_TARBALL_SLICESIZE permet de choisir des tailles max d'archives. Ici ce sera donc des archives de 1GB max à chaque fois.
Passons ensuite aux spécificités de l'incrémental.
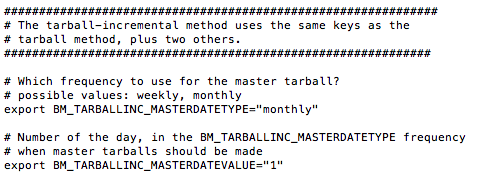
BM_TARBALLINC_MASTERDATETYPE vous permet de préciser si vous voulez une archive master par semaine ou par mois. Et ensuite de spécifier la fréquence de celle-ci (BM_TARBALLINC_MASTERDATEVALUE). Donc là, dans mon exemple, le master sera réalisé 1 fois par mois.
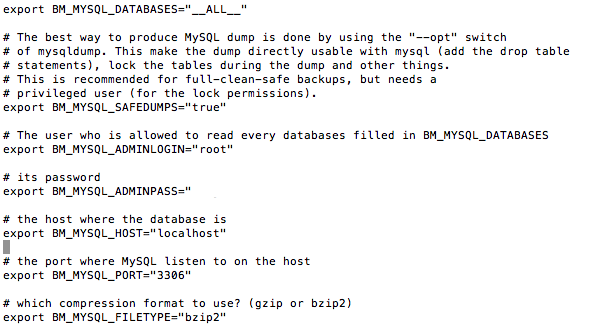
Passons ensuite à la conf MySQL. Ici, c'est du classique... login, mot de passe, port de MySQL...Etc
Petit parenthèse, concernant l'export MySQL, j'ai eu des petites erreurs de type
errno: 24 - Too many open files
Dans ce cas, pensez à ajouter le paramètre "open_files_limit = 3000" (je vous laisse choisir le nombre en fonction de vos besoins), dans la config mysqld.cnf et à relance MySQL.
Voilà, c'est terminé pour cette première partie. On va donc faire un test sans s'occuper de l'upload. Pour cela, mettez "none" dans le paramètre BM_UPLOAD_METHOD.
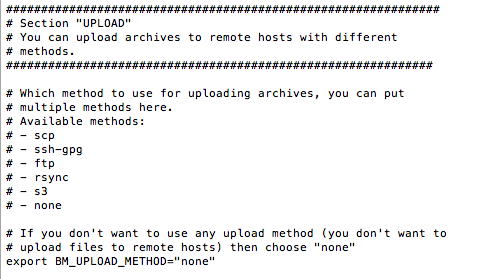
Sauvegardez le fichier, et lancez la commande
backup-manager -v
Et là, vous verrez si tout se passe bien. Si vous avez des erreurs, il y a des chances que ça concerne MySQL. Pensez à bien lire les logs d'erreur retournés pour comprendre de quoi il s'agit.
Pour surveiller que le backup est en cours, jetez un oeil dans votre répertoire /var/archives en faisant des "ls -l" à la suite pour voir la taille des fichiers augmenter.
Bon, ça, c'était le plus long à faire. Maintenant on va balancer tout ça sur Amazon S3. Vous pouvez bien sûr choisir une autre méthode d'upload comme FTP ou transfert via SSH. Et vous pouvez en mettre plusieurs... Par exemple envoyer le backup vers un FTP et vers S3.
Mettez donc le paramètre BM_UPLOAD_METHOD sur s3
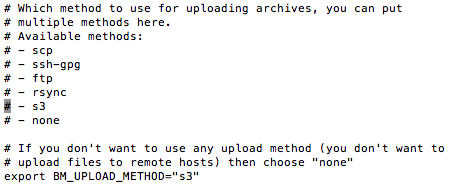
Alors concernant S3, il y a besoin de 3 paramètres :
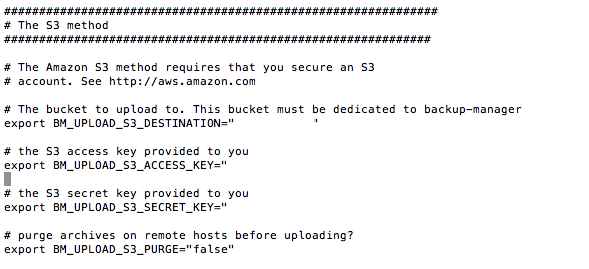
BM_UPLOAD_S3_DESTINATION c'est ce qu'on appelle le Bucket. Pas besoin de le créer en amont sur Amazon S3. Mettez ce que vous voulez et le script le créera pour vous directement.
BM_UPLOAD_S3_ACCESS_KEY et BM_UPLOAD_S3_SECRET_KEY, ce sont les identifiants S3 dont vous avez besoin. Pour cela, rendez vous ici sur votre compte S3 :
Cliquez sur Manage Users

Et ajoutez un nouvel utilisateur
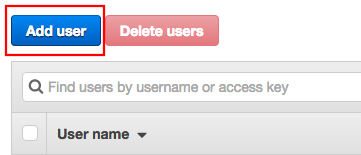
Donnez lui un nom et cochez la case programmatic access.
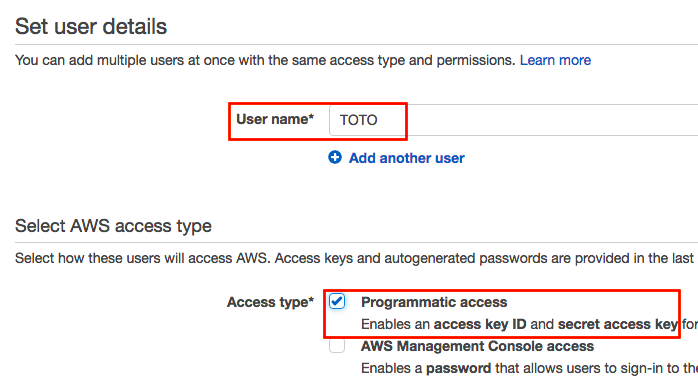
Si vous n'avez pas encore créé de groupe avec les droits sur la partie S3, faites-le.
Finalisez la création de l'utilisateur

Puis récupérez l'Access Key ID et le Secret Access Key pour les mettre dans le fichier de conf de Backup Manager.
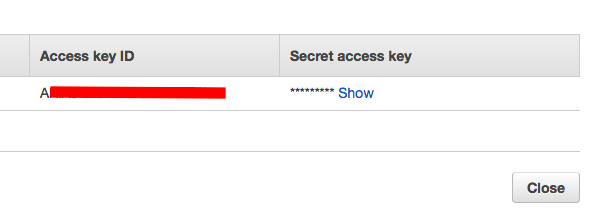
Et voilà... Maintenant y'a plus qu'à retester backup manager pour voir si le bucket est bien créé et si vos fichiers sont bien envoyés vers S3.
backup-manager -v
Comme Backup Manager utilise Perl, il est possible que vous ayez une de ce style :
Net::Amazon::S3 is not available, cannot use S3 service : Can't locate Net/Amazon/S3.pm in @INC (you may need to install the Net::Amazon::S3 module) (@INC contains: /etc$
BEGIN failed--compilation aborted at (eval 11) line 2.
The upload transfer "s3" failed.
Cela veut tout simplement dire que le module perl S3 n'est pas présent sur votre système. Faites donc un
sudo apt-get install libnet-amazon-s3-perl
Puis un
sudo cpan Net::Amazon::S3::Client
Et voilà ! Recommencez :
backup-manager -v
Normalement, si tout se passe bien, vos fichiers seront envoyés vers Amazon S3. Très bien !
Maintenant on va mettre tout ça dans la crontab pour que Backup Manager se lance tous les jours à minuit.
Lancez donc la commande
crontab -e
Et dedans, mettez
0 2 * * * backup-manager
Le 2 veut dire que ça va se lancer tous les jours à 2h du mat. Je ne rentre pas plus dans le détail car cet article est déjà assez long. Si vous voulez mettre autre chose, et que vous ne maitrisez pas la syntaxe cron, allez faire un tour sur ce site.
Un autre truc qui peut être intéressant aussi, c'est d'utiliser Amazon Glacier, en plus de S3. On peut par exemple directement depuis les paramètres de S3, mettre en place un cycle de vie de nos sauvegardes. Les conserver par exemple 30 jours sur Amazon S3, puis les basculer sur Glacier au bout de 30 jours et les supprimer de S3 au bout de 90. Ainsi, elles seront archivées ad vitam eternam (ou à peu près ) dans Glacier.
Si ça vous branche, voici comment faire. Placez-vous sur votre Bucket S3 fraichement créé qui contient vos sauvegardes, cliquez sur "Properties", et "Add Rule" dans la section Lifecycle.
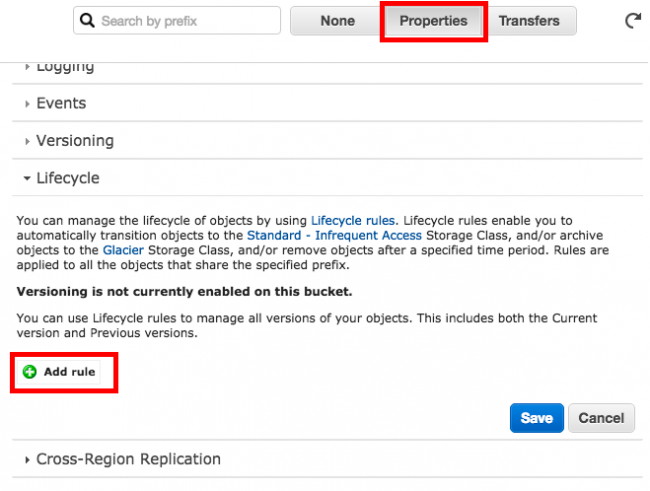
Choisissez d'appliquer cette future règle à votre Bucket
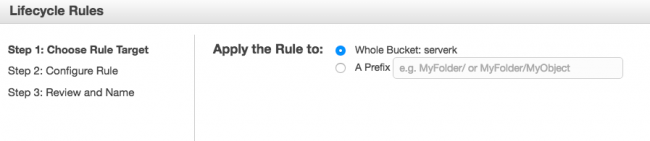
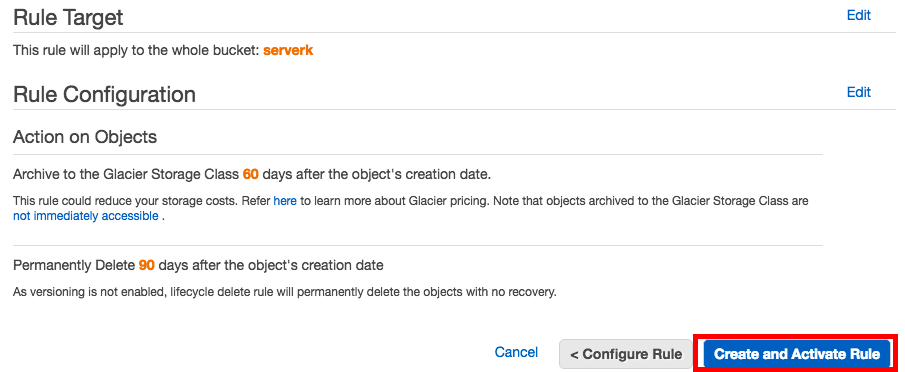
Puis c'est sur cette partie que vous devez régler le cycle de vie de vos backups. Ici, je choisis d'archiver vers glacier au bout de 60 jours et de supprimer mon archive sur S3 au bout de 120 jours.
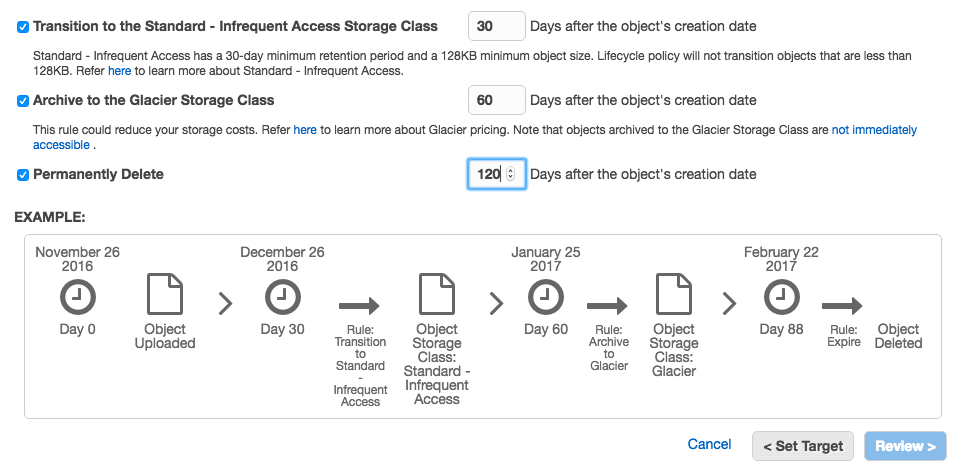
Une fois la règle créée, vous avez alors un résumé ici. Cliquez sur le bouton "Create and Activate rule".
Et voilà ! 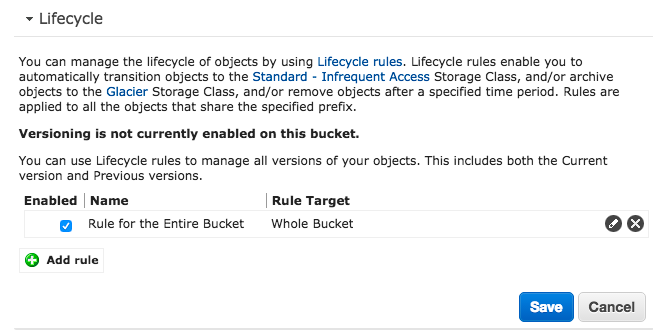
L'intérêt avec Glacier, c'est que c'est moins cher que S3 pour du stockage à long terme. Par contre, attention, si vous avez besoin de récupérer sur Glacier des archives de moins de 90 jours, vous devrez payer assez cher. Donc autant laisser une petite marge avant la suppression sur S3.
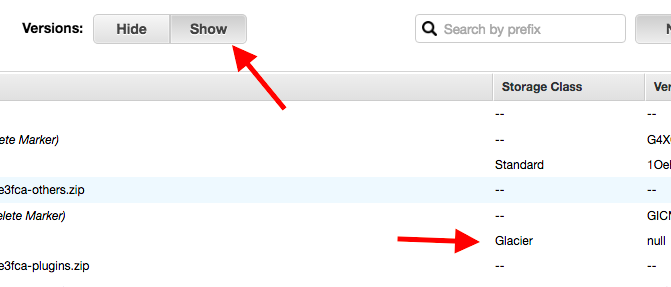
Ensuite pour voir vos backups Glacier, il vous suffira dans l'interface S3, de cliquer sur le bouton "Show".
Bon, voilà, j'ai fini. Un long tuto mais un tuto indispensable car une fois encore au risque de me répéter, les backups c'est HYPER IMPORTANT.
Enfin, pour terminer en beauté, pensez à récupérer de temps en temps vos backups et en vérifier le contenu, voire à remonter une base avec et votre site pour voir si tout se déroule bien. C'est tout aussi important !
Bonne sauvegarde à tous !
Cet article merveilleux et sans aucun égal intitulé : Sauvegardez votre serveur Linux sur Amazon S3 avec Backup Manager ; a été publié sur Korben, le seul site qui t'aime plus fort que tes parents.
Si entre les différentes annonces du Black Friday il vous reste encore un peu de temps pour coder, je vous propose de réviser vos gammes sur NodeJS avec François-Guillaume Ribreau et Julien Breux, développeurs chez iAdvize.
Une conférence mise en place avec eux pour un RJTalk, évènement dédié aux developpeurs que j'organise depuis cette année.
Respectivement Fullstack Hacker et Software Architect à Nantes, François-Guillaume Ribreau et Julien Breux ont beaucoup à dire à propos de leurs découvertes sur l’industrialisation de projets NodeJS.
Je vous laisse en compagnie des deux artistes ;)
Cet article merveilleux et sans aucun égal intitulé : Structurer ma première application NodeJS ; a été publié sur Korben, le seul site qui t'aime plus fort que tes parents.
Les machines à voter c'est l'avenir ! Surtout, car ça permet de truquer une élection beaucoup facilement qu'en cachant des bulletins de vote dans ses chaussettes .
Tenez par exemple, aux États-Unis pour l'élection de Trump, certaines machines utilisées lors de l'élection de Tump, sont des machines à voter de type Sequoia AVC Edge. Elles sont présentes dans 13 états américains. Et c'est intéressant, car les chercheurs en sécurité de Cylance se sont penchés sur celle-là.
En quelques étapes simples et sans droits particuliers, ils ont été capables de rediriger n'importe quel vote d'un candidat à un autre (genre, vous votez pour Hillary et ça incrémente le score de Trump), de changer le nom des candidats et, simplement en insérant dans la machine une mémoire flash PCMCIA, ils ont pu mettre à jour les données relatives au vote, grâce à un fichier spécialement forgé pour l'occasion et contenant de fausses données de vote.
Easy peasy quoi.
Voici la vidéo qui montre tout ça :
Bref, rien de bien rassurant une fois encore, sur la machine à voter électronique. D'ailleurs, des questions commencent à se poser sur la dernière élection...
Je suis à fond pour les nouvelles technos et le vote électronique, pourquoi pas, mais avant d'avoir confiance en ce machin, il va falloir que les mecs qui les fabrique aient quelques notions de sécurité et qu'ils imaginent un système plus complexe à détourner.
Une réflexion à reprendre depuis le début, un peu comme ce qu'a fait Kaspersky avec son OS finalement.
Cet article merveilleux et sans aucun égal intitulé : Machines à voter, machines à truquer ; a été publié sur Korben, le seul site qui t'aime plus fort que tes parents.