Mise à jour
Mise à jour de la base de données, veuillez patienter...
source: La Quadrature du Net
Tribune de Guinness, doctorante en informatique et membre de La Quadrature du Net
À l’heure où toutes les puissances de la planète se mettent à réfléchir à des solutions de traçage de contact (contact tracing), les GAFAM sautent sur l’occasion et Apple et Google proposent leur propre protocole.
On peut donc se poser quelques minutes et regarder, analyser, chercher, et trouver les avantages et les inconvénients de ce protocole par rapport à ses deux grands concurrents, NTC et DP-3T, qui sont similaires.
Commençons par résumer le fonctionnement de ce protocole. Je me base sur les documents publiés sur le site de la grande pomme. Comme ses concurrents, il utilise le Bluetooth ainsi qu’un serveur dont le rôle est de recevoir les signalements de personnes infecté·es, et de communiquer aux utilisateurices de l’application les listes des personnes infectées par SARS-Cov2 qu’elles auraient pu croiser.
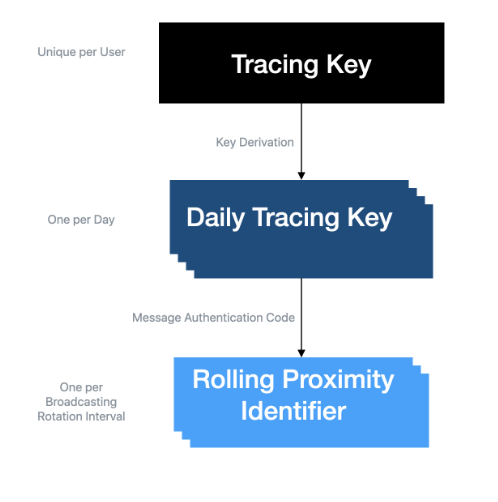
Le protocole utilisant de nombreux protocoles et fonctions cryptographiques, et étant assez long, je ne vais pas l’expliquer en détail, et si vous voulez plus d’informations, vous pouvez vous référer à la note en bas de page.1L’application commence par générer un identifiant unique de 256 bits. Suffisamment long pour qu’il n’y ait pas de risque de collisions (deux personnes qui génèrent par hasard – ou non – le même identifiant), et ce même si toute la population terrestre utilisait l’application. Cet identifiant est appelé Tracing Key.
Puis, chaque jour, un identifiant pour la journée (appelé Daily Tracing Key) est calculé à partir de la Tracing Key. Pour ce faire, on utilise la fonction à sens unique HKDF, qui permet à partir de paramètres d’entrée de générer une clef unique et à partir de laquelle il est impossible en pratique de remonter aux informations d’origine. Dans notre cas, les paramètres d’entrée sont la Tracing Key et le numéro du jour courant, ce qui nous permet de calculer une clef journalière de 128 bits.
Pour la dernière étape, le protocole dérive un nouvel identifiant, celui qui sera communiqué via Bluetooth aux autres utilisateurices de l’application: le Rolling Proximity Identifier (RPI) un « identifiant de proximité continu » au sens où celui-ci change constamment. Il est recalculé toutes les 15 minutes, chaque fois que l’adresse physique de la puce Bluetooth change et on stocke un nombre appelé TINj qui augmente de 1 toutes les 15 minutes de même que j ; à la différence que j est réinitialisé chaque jour. On utilise pour calculer la RPI la fonction HMAC, une autre fonction à sens unique, qui utilise comme paramètres la Daily Tracing Key du jour courant ainsi que le TINj du quart d’heure en cours.
Finalement, la partie intéressante : que se passe-t-il lorsqu’une personne est déclarée infectée ?
L’application crée une clef de diagnostic, qui n’a ici aucune fonction cryptographique : on envoie les dernières 14 Daily Tracing Keys, ainsi que les numéros des jours associés, puis on continue chaque jour d’envoyer les 14 dernières Daily Tracing Keys ainsi que le jour associé (voir ce PDF au paragraphe §CTSelfTracingInfoRequest) . Cette clef est ensuite envoyée sur un serveur qui stocke toutes les clefs de diagnostic.
Par ailleurs, de manière fréquente, les client·es récupèrent la liste des clefs de diagnostic, utilisent ces clefs pour recalculer tous les RPI, et voir si dans la liste des personnes croisées, on retrouve un de ces RPI. Si c’est le cas, on prévient l’utilisateurice.<script type="text/javascript"> jQuery("#footnote_plugin_tooltip_6574_1").tooltip({ tip: "#footnote_plugin_tooltip_text_6574_1", tipClass: "footnote_tooltip", effect: "fade", fadeOutSpeed: 100, predelay: 400, position: "top right", relative: true, offset: [10, 10] });
Pour faire simple, on génère initialement une clef (Tracing Key ou TK), qu’on utilise chaque jour pour calculer une nouvelle clef (Daily Tracing Key ou DTK), qu’on utilise elle-même toutes les 15 minutes pour calculer une troisième clef (Rolling Proximity Identifier ou RPI), qu’on va appeler la «clef roulante de proximité», qui sera diffusée avec le Bluetooth.
Ce qu’il faut retenir, c’est que l’identifiant qui est diffusé via le Bluetooth change toutes les 15 minutes, et qu’il est impossible en pratique de déduire l’identité d’une personne en ne connaissant que cet identifiant ou plusieurs de ces identifiants.
Par ailleurs, si on se déclare comme malade, on envoie au serveur central la liste des paires (DTK, jour de création de la DTK) des 14 derniers jours, et de même pendant les 14 jours suivants. Cet ensemble forme ce qu’on appelle la clef de diagnostic.
D’un point de vue cryptographique, tous les spécialistes du domaine (Anne Canteaut, Leo Colisson et d’autres personnes, chercheureuses au LIP6, Sorbonne Université) avec lesquels j’ai eu l’occasion de parler sont d’accord : les algorithmes utilisés sont bien connus et éprouvés. Pour les spécialistes du domaine, la documentation sur la partie cryptographique explique l’utilisation des méthodes HMAC et HKDF avec l’algorithme de hashage SHA256. Les clefs sont toutes de taille suffisante pour qu’on ne puisse pas toutes les générer en les pré-calculant en créant une table de correspondance également appelée « Rainbow table » qui permettrait de remonter aux Tracing Keys . L’attaque envisagée ici consiste à générer le plus de TK possibles, leurs DTK correspondantes et lorsque des DTK sont révélées sur quelques jours, utiliser la table de correspondance pré-calculée pour remonter à la TK.
On peut faire un gros reproche cependant : la non-utilisation de sel (une chaîne de caractères aléatoires, différente pour chaque personne et définie une fois pour toutes, qu’on ajoute aux données qu’on hashe) lors de l’appel à HMAC pour générer les DTK, ce qui est une aberration, et pire encore, aucune justification n’est donnée par Apple et Google.
Quand on écrit un protocole cryptographique, selon Apple et Google « with user privacy and security central to the design » (Traduction : « avec le respect de la vie privée de l’utilisateurice et la sécurité au centre de la conception »), on est en droit de chercher tous les moyens possibles de récupérer un peu d’information, de tracer les utilisateurices, de savoir qui iels sont.
À chaque fois que le téléphone du client récupère la liste des clefs de diagnostic des personnes déclarées malades, il doit calculer tous les RPI (144 par jour, faites moi confiance c’est dans le protocole, 144 * 15 min = 24 h) de toutes les clefs pour tous les jours. On peut imaginer ne récupérer que les nouvelles données chaque jour, mais ce n’est pas spécifié dans le protocole. Ainsi, au vu de la quantité de personnes infectées chaque jour, on va vite se retrouver à court de puissance de calcul dans le téléphone. On peut même s’imaginer faire des attaques par DoS (déni de service) en insérant de très nombreuses clefs de diagnostic dans le serveur pour bloquer les téléphones des utilisateurices.
En effet, quand on se déclare positif, il n’y a pas d’information ajoutée, pas d’autorité qui assure que la personne a bien été infectée, ce qui permet à tout le monde de se déclarer positif, en faisant l’hypothèse que la population jouera le jeu et ne se déclarera positive que si elle l’est vraiment.
Un design utilisant un serveur centralisé (possédé ici par Apple et Google), qui a donc accès aux adresses IP et d’autres informations de la part du client gagne beaucoup d’informations : il sait retrouver quel client est infecté, avoir son nom, ses informations personnelles, c’est-à-dire connaître parfaitement la personne infectée, quitte à revendre les données ou de l’espace publicitaire ciblé pour cette personne. Comment cela se passe-t-il ? Avec ses pisteurs embarqués dans plus de 45% des applications testées par Exodus Privacy, pisteurs qui partagent des informations privées, et qui vont utiliser la même adresse IP, Google va pouvoir par exemple recouper toutes ces informations avec l’adresse IP pour savoir à qui appartient quelle adresse IP à ce moment.
Lorsqu’on est infecté⋅e, on révèle ses DTK, donc tous les RPI passés. On peut donc corréler les partages de RPI passés avec d’autres informations qu’on a.
Pour aller plus loin, nous avons besoin d’introduire deux notions : celle d’adversaire actif, et celle d’adversaire passif. L’adversaire actif tente de gagner activement de l’information, en essayant de casser de la cryptographie, de récupérer des clefs, des identifiants. Nous avons vu précédemment qu’il a fort peu de chance d’y arriver.
L’adversaire passif quant à lui se contente de récupérer des RPIs, des adresses physiques de puces Bluetooth, et d’essayer de corréler ces informations.
Ce dernier type d’adversaire a existé et existe encore . Par exemple, la ville de Londres a longtemps équipé ses poubelles de puces WiFi, permettant de suivre à la trace les smartphones dans la ville. En France, l’entreprise Retency, ou encore les Aéroports de Paris font la même chose avec le Bluetooth. Ces entreprises ont donc des réseaux de capture de données, et se révéler comme positif à SARS-Cov2 permet alors à ces entreprises, qui auront capté les RPIs envoyés, de pister la personne, de corréler avec les données de la publicité ciblée afin d’identifier les personnes infectées et donc revendre des listes de personnes infectées.
On peut aussi imaginer des implémentations du protocole qui stockent des données en plus de celles demandées par le protocole, telles que la localisation GPS, ou qui envoient des données sensibles à un serveur tiers.
D’autres attaques existent, dans le cadre d’un adversaire malveillant, mais nous ne nous attarderons pas dessus ; un article publié il y a quelques jours (en anglais) les décrit très bien : https://eprint.iacr.org/2020/399.pdf.
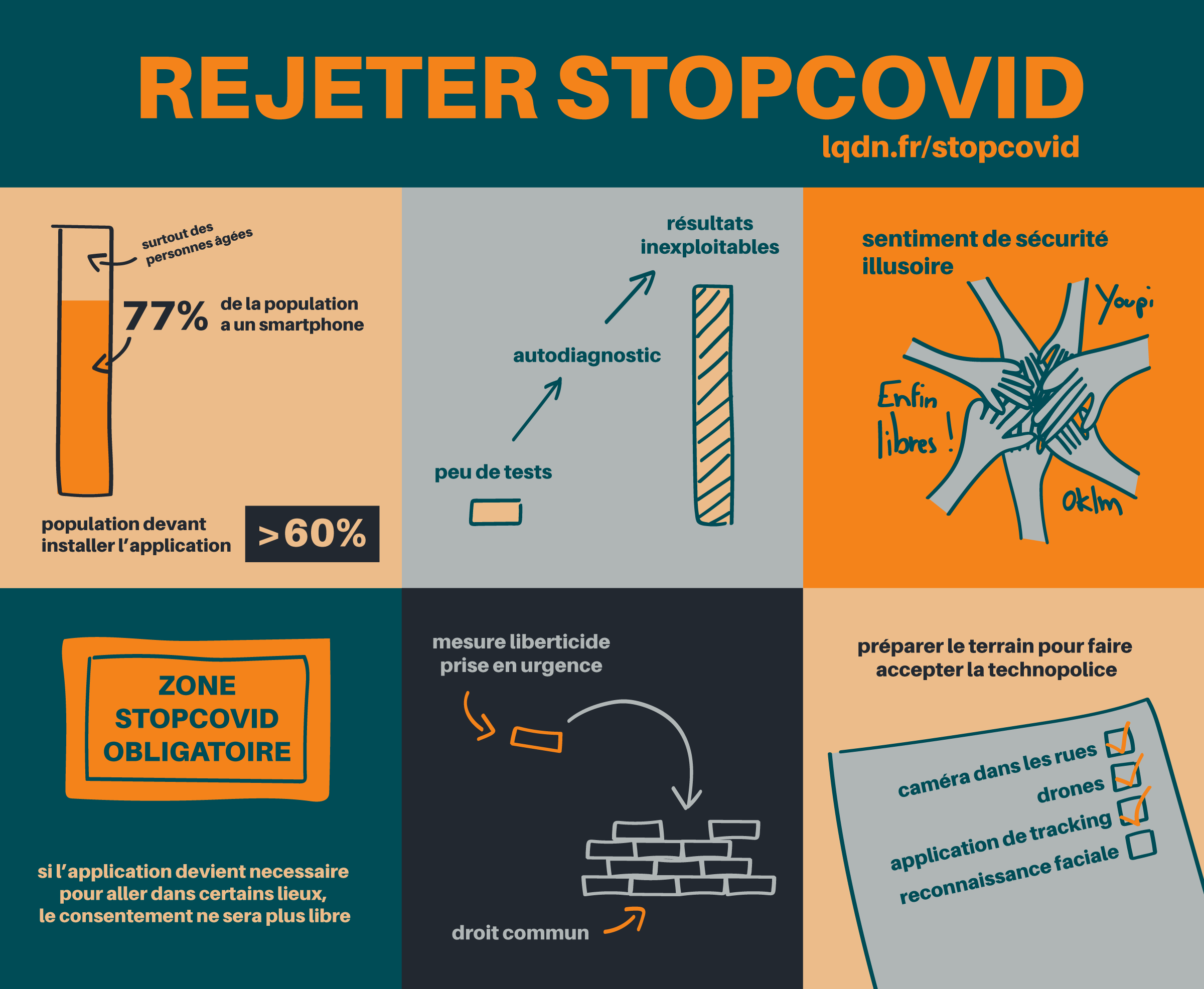
Nous pouvons ainsi voir que, même si le protocole est annoncé comme ayant la sécurité et le respect de la vie privée en son centre, il n’est pas exempt de défauts, et il y a même, à mon avis, des choix techniques qui ont été faits qui peuvent permettre le traçage publicitaire même si on ne peut en prouver la volonté. Alors même que tous les pays du monde sont en crise, et devraient investir dans du matériel médical, dans du personnel, dans les hôpitaux, dans la recherche de traitements contre SARS-Cov2, ils préfèrent se tourner vers un solutionnisme technologique qui non seulement n’a aucune assurance de fonctionner, mais qui également demande que plus de 60 % de la population utilise l’application pour être efficace (voir cet article pour plus d’informations).
D’autant plus qu’une telle application ne peut être efficace qu’avec un dépistage massif de la population, ce que le gouvernement n’est actuellement pas en état de fournir (à raison de 700k tests par semaine, tel qu’annoncé par Édouard Philippe dans son allocution du 28 avril, il faudrait environ 2 ans pour dépister toute la population).
Pour plus d’informations sur les possibles attaques des protocoles de contact tracing, en particulier par des adversaires malveillants, je vous conseille l’excellent site risques-tracage.fr écrit par des chercheureuses INRIA spécialistes du domaine.
References
| 1. | ↑ | L’application commence par générer un identifiant unique de 256 bits. Suffisamment long pour qu’il n’y ait pas de risque de collisions (deux personnes qui génèrent par hasard – ou non – le même identifiant), et ce même si toute la population terrestre utilisait l’application. Cet identifiant est appelé Tracing Key. Puis, chaque jour, un identifiant pour la journée (appelé Daily Tracing Key) est calculé à partir de la Tracing Key. Pour ce faire, on utilise la fonction à sens unique HKDF, qui permet à partir de paramètres d’entrée de générer une clef unique et à partir de laquelle il est impossible en pratique de remonter aux informations d’origine. Dans notre cas, les paramètres d’entrée sont la Tracing Key et le numéro du jour courant, ce qui nous permet de calculer une clef journalière de 128 bits. Pour la dernière étape, le protocole dérive un nouvel identifiant, celui qui sera communiqué via Bluetooth aux autres utilisateurices de l’application: le Rolling Proximity Identifier (RPI) un « identifiant de proximité continu » au sens où celui-ci change constamment. Il est recalculé toutes les 15 minutes, chaque fois que l’adresse physique de la puce Bluetooth change et on stocke un nombre appelé TINj qui augmente de 1 toutes les 15 minutes de même que j ; à la différence que j est réinitialisé chaque jour. On utilise pour calculer la RPI la fonction HMAC, une autre fonction à sens unique, qui utilise comme paramètres la Daily Tracing Key du jour courant ainsi que le TINj du quart d’heure en cours. Finalement, la partie intéressante : que se passe-t-il lorsqu’une personne est déclarée infectée ? L’application crée une clef de diagnostic, qui n’a ici aucune fonction cryptographique : on envoie les dernières 14 Daily Tracing Keys, ainsi que les numéros des jours associés, puis on continue chaque jour d’envoyer les 14 dernières Daily Tracing Keys ainsi que le jour associé (voir ce PDF au paragraphe §CTSelfTracingInfoRequest) . Cette clef est ensuite envoyée sur un serveur qui stocke toutes les clefs de diagnostic. Par ailleurs, de manière fréquente, les client·es récupèrent la liste des clefs de diagnostic, utilisent ces clefs pour recalculer tous les RPI, et voir si dans la liste des personnes croisées, on retrouve un de ces RPI. Si c’est le cas, on prévient l’utilisateurice. |
L’application StopCovid ne fera finalement pas l’objet d’un vote à l’Assemblée nationale, le gouvernement se refusant à tout risque de vote contraire à sa volonté. Pourtant, les prises de position s’accumulent contre elle et son avenir semble chaque jour plus incertain.
Hier, la CNIL a rendu son avis à son sujet. Contrairement au Conseil national du numérique (CNNum) qui s’est prononcé vendredi en faveur de l’application, la CNIL n’a pas entièrement fui le débat : elle exige que le gouvernement démontre l’utilité concrète de StopCovid, ce qu’aucune étude ou analyse ne soutient actuellement. Hélas, alors que la CNIL aurait dû s’arrêter à ce simple constat pour demander l’arrêt de ce dangereux et inutile projet, elle s’est égarée dans le faux-débat tendu par le gouvernement : rechercher des « garanties », forcément illusoires, pour encadrer l’application.
L’idée au cœur du droit des libertés fondamentales est que, par principe, il est interdit de limiter nos libertés. Elles ne peuvent l’être que par exception, et uniquement en démontrant qu’une telle limitation est utile à un intérêt supérieur, telle que la santé publique dans notre cas. Hier, la CNIL a rappelé ce principe cardinal, qu’elle applique naturellement de longue date. Par exemple, dans son avis sur les portiques de reconnaissance faciale dans des lycées de la région Sud, elle avait bien rappelé qu’il revenait au responsable de traitement de données« d’évaluer la nécessité et la proportionnalité du traitement envisagé ». Un tel raisonnement l’avait conduit à considérer que le projet de reconnaissance faciale était contraire au RGPD, car la région n’avait pas démontré cette nécessité.
Il ne fait pas de doute que StopCovid est une mesure limitant les libertés fondamentales, ce que la CNIL reconnaît facilement : risques d’attaques malveillantes, de discriminations, d’accoutumance à la surveillance constante, de dévoiement par le gouvernement. La CNIL exige donc que les prétendus bienfaits sanitaires de l’application soient démontrés avant que celle-ci ne soit déployée, ce qui fait jusqu’ici défaut. La rigueur du raisonnement de la CNIL tranche nettement avec l’avis du CNNum, qui conclut en faveur de StopCovid hors de toute méthode d’analyse sérieuse.
Toutefois, il faut regretter que la CNIL se soit arrêtée là, sans conclure et répondre elle-même à la question qu’elle a si justement posée. Si aucun élément factuel ne prouve l’efficacité d’une technique qu’elle reconnaît pourtant comme attentatoire aux libertés fondamentales, la mission de la CNIL est de déclarer celle-ci illégale. Déclarer illégaux des traitements de données injustifiés est une des missions centrales qui justifient l’existence de la CNIL.
Mais, refusant de tenir son rôle, la CNIL s’est ensuite perdue dans le débat vain souhaité par le gouvernement : chercher à tâtons les garanties pouvant encadrer cette pratique. Pourtant, les conditions pour que StopCovid respecte nos libertés sont impossibles à remplir. L’essence même du « traçage de contact », automatique comme manuel, rend impossible l’anonymat, et le contexte de crise sanitaire rend irréaliste la garantie d’un consentement libre.
Cédric O affirme que les données traitées par StopCovid « seraient anonymes ». De même, Bruno Sportisse, directeur de l’INRIA chargé du protocole ROBERT sur lequel reposera l’application, affirme que celle-ci serait « totalement anonyme ».
En pratique, une application anonyme n’aurait aucun intérêt : l’application doit envoyer à des personnes ciblées des alertes du type « vous avez été au contact de personnes malades, mettez-vous en quarantaine ». Du moment que chaque alerte est envoyée à des personnes ciblées, le système n’est plus anonyme : trivialement, il suffit qu’un tiers (un patron, un conjoint, etc.) puisse consulter votre téléphone pour constater que vous avez reçu une alerte. Des chercheu·ses de l’INRIA ont produit une excellente liste de quinze scénarios de ce type, démontrant à quel point il était simple de lever ce prétendu « anonymat ».
Hélas, le CNNum s’enfonce dans le déni de réalité et continue de prétendre que « les utilisateurs de l’application ne peuvent pas se réidentifier entre eux ». Dans une étrange note de bas de page, l’avis du CNNum admet que cette affirmation est peut-être fausse puis renvoie vers les scénarios de l’INRIA. Voilà la triste posture du CNNum : mentir dans le corps du texte et s’excuser en pied de page, en petits caractères.
De son côté, heureusement, la CNIL est plus honnête et ne cache pas ces failles : les données traitées par StopCovid sont des pseudonymes ré-identifiables. Mais elle refuse d’en tirer la moindre conséquence effective. Après avoir exigé quelques mesures de sécurité nécessaires qui ne changeront pas le fond du problème, elle semble se bercer dans l’illusion que le droit serait une garantie suffisante pour empêcher que ce pseudonymat si fragile ne soit levé. Au final, sa seule « garantie » n’est rien d’autre que ce cher RGPD que la CNIL échoue à faire respecter depuis deux ans, quand elle ne s’y refuse pas carrément (lire notre article sur les cookies publicitaires).
Tout comme l’utilisation faussée de la notion de données « anonymes », le gouvernement fonde la création de StopCovid sur le fait que l’application serait installée « volontairement ». Une telle présentation est encore mensongère : matériellement, l’État ne pourra pas s’assurer que l’application ne soit pas imposée par des tiers.
Si des employeurs, des restaurants ou des centres d’hébergement exigent que leurs salariés ou usagers utilisent StopCovid, que va faire Cédric O ? Leur envoyer la police pour forcer le passage ? Si la pression vient de la famille ou des amis, que va faire la CNIL ? Leur imposer des amendes en violation du RGPD – qu’encore une fois elle ne fait déjà pas respecter avec énormément de sites internet ?
Comme nous ne cessons de le répéter, il est urgent que ce débat prenne fin, par le rejet de ce projet. L’attention du public, du Parlement et de la recherche doit se rediriger vers les nombreuses autres solutions proposées : production de masques, de tests, traçage de contacts réalisé par des humains, sans avoir à réinventer la roue. Leur efficacité semble tellement moins hasardeuse. Surtout, contrairement à StopCovid, ces solutions ne risquent pas de légitimer sur le long terme l’ensemble de la Technopolice, qui cherche depuis des années à rendre acceptable la surveillance constante de nos corps dans l’espace public par la reconnaissance faciale, les drones ou la vidéo automatisée.
Les 28 et 29 avril, dans le cadre des mesures de déconfinement, l’Assemblée nationale débattra de StopCovid, sans toutefois voter spécifiquement à son sujet. L’Assemblée doit exiger la fin de cette application. Rendez-vous sur cette page pour contacter les député·es.
Nous reproduisons, avec l’accord de leurs auteurs, la tribune parue aujourd’hui dans le quotidien Le Monde concernant l’application StopCovid, écrite par Antonio Casilli, Paul-Olivier Dehaye, Jean-Baptiste Soufron, et signée par UGICT-CGT et La Quadrature du Net. Le débat au parlement se déroulera le 28 avril et nous vous invitons à contacter votre député⋅e pour lui faire part de votre opposition au projet et de lui demander de voter contre.
Tribune. Le mardi 28 avril, les parlementaires français seront amenés à voter sur StopCovid, l’application mobile de traçage des individus imposée par l’exécutif. Nous souhaitons que, par leur vote, ils convainquent ce dernier de renoncer à cette idée tant qu’il est encore temps. Non pas de l’améliorer, mais d’y renoncer tout court. En fait, même si toutes les garanties légales et techniques étaient mises en place (anonymisation des données, open source, technologies Bluetooth, consentement des utilisateurs, protocole décentralisé, etc.), StopCovid serait exposée au plus grand des dangers : celui de se transformer sous peu en « StopCovid Analytica », une nouvelle version du scandale Cambridge Analytica [siphonnage des données privées de dizaines de millions de comptes Facebook].
L’application StopCovid a été imaginée comme un outil pour permettre de sortir la population française de la situation de restriction des libertés publiques provoquée par le Covid-19. En réalité, cette « solution » technologique ne serait qu’une continuation du confinement par d’autres moyens. Si, avec ce dernier, nous avons fait l’expérience d’une assignation à résidence collective, les applications mobiles de surveillance risquent de banaliser le port du bracelet électronique.
Le terme n’est pas exagéré : c’est déjà le cas à Hong-Kong, qui impose un capteur au poignet des personnes en quarantaine, et c’est l’objet de tests en Corée du Sud et au Liechtenstein pour certaines catégories de citoyens à risque. StopCovid, elle, a vocation à être installée dans les smartphones, mais elle concerne tous les citoyens, malades ou non. Malgré le fait que son installation soit présentée comme facultative dans d’autres pays, tels l’Italie, on assiste à la transformation de cette démarche volontaire en obligation.
L’affaire Cambridge Analytica, révélée au grand jour en 2018, avait comme point de départ les travaux de chercheurs de l’université anglaise. Une application appelée « Thisisyourdigitallife », présentée comme un simple quiz psychologique, avait d’abord été proposée à des utilisateurs de la plate-forme de microtravail Amazon Mechanical Turk. Ensuite, ces derniers avaient été amenés à donner accès au profil Facebook de tous leurs contacts. C’était, en quelque sorte, du traçage numérique des contacts avant la lettre.
A aucun moment ces sujets n’avaient consenti à la réutilisation de leurs informations dans le cadre de la campagne du Brexit ou dans l’élection présidentielle de Donald Trump. Cela est arrivé ensuite, lorsque les chercheurs ont voulu monétiser les données, initialement collectées dans un but théoriquement désintéressé, par le biais de l’entreprise Cambridge Analytica. En principe, cette démarche respectait les lois des différents pays et les règles de ces grandes plates-formes. Néanmoins, de puissants algorithmes ont été mis au service des intérêts personnels et de la soif de pouvoir d’hommes politiques sans scrupule.
Les mêmes ingrédients sont réunis ici : des scientifiques « de bonne volonté », des géants de la « tech », des intérêts politiques. Dans le cas de StopCovid, c’est le consortium universitaire européen Pan-European Privacy Preserving Proximity Tracing (PEPP-PT), qui a vu le jour à la suite de la pandémie. Ces scientifiques se sont attelés à la tâche de concevoir dans l’urgence le capteur de contacts le plus puissant, dans le respect des lois. Cela s’articule avec les intérêts économiques d’acteurs privés, tels les grands groupes industriels nationaux, le secteur automobile et les banques en Italie, les télécoms et les professionnels de l’hébergement informatique en France. Mais surtout les GAFA, les géants américains du numérique, se sont emparés du sujet.
Cette fois, ce ne sont pas Facebook et Amazon, mais Google et Apple, qui ont tout de suite proposé de fournir une nouvelle structure pour diffuser les applications de suivi de contacts sur leurs plates-formes. La menace qui plane au-delà de tous ces acteurs vient des ambitions de certains milieux politiques européens d’afficher leur détermination dans la lutte contre le Covid19, en se targuant d’une solution technique à grande échelle, utilisant les données personnelles pour la « campagne du déconfinement ».
Le projet StopCovid n’offre aucune garantie sur les finalités exactes de la collecte de ces données. L’exécutif français ne s’autorise pas à réfléchir à la phase qui suit la collecte, c’est-à-dire au traitement qui sera fait de ces informations sensibles. Quels algorithmes les analyseront ? Avec quelles autres données seront-elles croisées sur le moyen et le court terme ? Son court-termisme s’accompagne d’une myopie sur les dimensions sociales des données.
Que se passerait-il si, comme plusieurs scientifiques de l’Inria, du CNRS et d’Informatics Europe s’époumonent à nous le dire, malgré une collecte initiale de données réduite au minimum, des entreprises ou des puissances étrangères décidaient de créer des « applications parasites » qui, comme Cambridge Analytica, croiseraient les données anonymisées de StopCovid avec d’autres bases de données nominatives ? Que se passerait-il, par exemple, si une plate-forme de livraison à domicile décidait (cela s’est passé récemment en Chine) de donner des informations en temps réel sur la santé de ses coursiers ? Comment pourrait-on empêcher un employeur ou un donneur d’ordres de profiter dans le futur des données sur l’état de santé et les habitudes sociales des travailleurs ?
L’affaire Cambridge Analytica nous a permis de comprendre que les jeux de pouvoir violents et partisans autour de la maîtrise de nos données personnelles ont des conséquences directes sur l’ensemble de la vie réelle. Il ne s’agit pas d’une lubie abstraite. Le cas de StopCovid est tout aussi marquant. En focalisant des ressources, l’attention du public et celle des parlementaires sur une solution technique probablement inefficace, le gouvernement nous détourne des urgences les plus criantes : la pénurie de masques, de tests et de médicaments, ou les inégalités d’exposition au risque d’infection.
Cette malheureuse diversion n’aurait pas lieu si le gouvernement n’imposait pas ses stratégies numériques, verticalement, n’étant plus guidé que par l’urgence de faire semblant d’agir. Face à ces enjeux, il faudrait au contraire impliquer activement et à parts égales les citoyens, les institutions, les organisations et les territoires pour repenser notre rapport à la technologie. Le modèle de gouvernance qui accompagnera StopCovid sera manifestement centré dans les mains d’une poignée d’acteurs étatiques et marchands. Une telle verticalité n’offre aucune garantie contre l’évolution rapide de l’application en un outil coercitif, imposé à tout le monde.
Ce dispositif entraînerait un recul fondamental en matière de libertés, à la fois symbolique et concret : tant sur la liberté de déplacement, notamment entre les pays qui refuseraient d’avoir des systèmes de traçage ou qui prendront ce prétexte pour renforcer leur forteresse, que sur la liberté de travailler, de se réunir ou sur la vie privée. Les pouvoirs publics, les entreprises et les chercheurs qui dans le courant des dernières semaines sont allés de l’avant avec cette proposition désastreuse, ressemblent à des apprentis sorciers qui manient des outils dont la puissance destructrice leur échappe. Et, comme dans le poème de Goethe, quand l’apprenti sorcier n’arrive plus à retenir les forces qu’il a invoquées, il finit par implorer une figure d’autorité, une puissance supérieure qui remette de l’ordre. Sauf que, comme le poète nous l’apprend, ce « maître habile » ne reprend ces outils « que pour les faire servir à ses desseins ».
Antonio Casilli, sociologue.
Paul-Olivier Dehaye, mathématicien.
Jean-Baptiste Soufron, avocat.
Cosignataires : Sophie Binet et Marie-José Kotlicki, cosecrétaires généraux de l’UGICT-CGT ; Raquel Radaut, membre de La Quadrature du Net.
Le 28 avril 2020, l’Assemblée nationale débattra pour rendre son avis sur le projet d’application StopCovid du gouvernement. Cette application risque d’être inefficace d’un point de vue sanitaire (voire contre-productive) tout en créant de graves risques pour nos libertés : discriminations de certaines personnes et légitimation de la surveillance de nos corps dans l’espace public (reconnaissance faciale, drone et toute la Technopolice).
Quelques textes à lire pour bien comprendre le sujet :
Contactons les député·es pour leur demander de mettre fin à ce débat inutile et dangereux.
<script src="https://www.laquadrature.net/wp-content/scripts/phone.js">
Dans sa décision QPC du 3 avril dernier, le Conseil constitutionnel a estimé que les algorithmes locaux, utilisés par les Universités pour sélectionner les étudiant·es dans le cadre de la procédure Parcoursup, doivent faire l’objet d’une publication après la procédure. Cette affaire, initiée par l’UNEF et dans laquelle La Quadrature du Net est intervenue, permet de lever – en partie – le voile sur l’opacité dangereuse des algorithmes qui sont utilisés de manière démesurée par l’État et ses administrations.
Parcoursup est une plateforme développée par le gouvernement et qui a pour objectif de gérer les vœux d’affectation des futur·es étudiant·es de l’enseignement supérieur. À ce titre, chaque établissement peut s’aider d’algorithmes (appelés « algorithmes locaux », car propres à chaque établissement) pour se faciliter le travail de comparaison entre les candidat·es. En pratique, il s’agit de simples feuilles de calcul. Les critères de ces algorithmes et leurs pondérations ne sont pas connu·es, et des soupçons de pratiques discriminatoires, notamment fondées sur le lycée d’origine des candidat·es, ont été émis par le Défenseur des droits. L’UNEF, syndicat étudiant, a alors demandé la communication de ces algorithmes locaux et, face au refus des Universités, s’est retrouvé devant le Conseil constitutionnel. La Quadrature du Net s’est jointe à l’affaire, et nous avons soutenu l’impératif de transparence.
En effet, jusqu’à présent, les juges administratifs et le Conseil d’État interprétaient la loi comme interdisant toute publication de ces algorithmes locaux, c’est-à-dire les critères utilisés et leurs pondérations. Le secret des délibérations était brandi pour refuser la transparence, empêchant ainsi de contrôler leur usage et la présence éventuelle de pratiques discriminatoires.
Dans sa décision, si le Conseil constitutionnel a considéré que la loi attaquée est conforme à la Constitution, il y a rajouté une réserve d’interprétation1Une réserve d’interprétation est une clarification par le Conseil constitutionnel du sens de la loi, dans l’hypothèse où plusieurs lectures du texte auraient été possibles. La réserve d’interprétation permet de « sauver » un texte de loi en ne retenant qu’une interprétation conforme à la Constitution et en écartant toute autre lecture.<script type="text/javascript"> jQuery("#footnote_plugin_tooltip_9815_1").tooltip({ tip: "#footnote_plugin_tooltip_text_9815_1", tipClass: "footnote_tooltip", effect: "fade", fadeOutSpeed: 100, predelay: 400, position: "top right", relative: true, offset: [10, 10] }); : la liste exhaustive des critères utilisés par les Universités devra être publiée a posteriori. Cette réserve d’interprétation change radicalement le sens de la loi et c’est un début de victoire : elle crée une obligation de publication de l’ensemble des critères utilisés par les Universités, une fois la procédure de sélection terminée. En revanche, il est extrêmement regrettable que les pondérations appliquées à chaque critère ne soient pas couvertes par cette communication.
Autre point important, pour arriver à cette conclusion, le Conseil constitutionnel a dégagé un droit général de communication des documents administratifs, notion recouvrant les algorithmes2Pour rappel, c’est ce droit de communication que nous utilisons dans notre campagne Technopolice pour obtenir des documents sur les dispositifs de surveillance déployés par les communes.<script type="text/javascript"> jQuery("#footnote_plugin_tooltip_9815_2").tooltip({ tip: "#footnote_plugin_tooltip_text_9815_2", tipClass: "footnote_tooltip", effect: "fade", fadeOutSpeed: 100, predelay: 400, position: "top right", relative: true, offset: [10, 10] });. Il a ainsi estimé que seul un intérêt général peut limiter ce droit à communication, et à condition que cette limitation soit proportionnée. C’est ainsi que, pour la procédure Parcoursup attaquée, il a estimé que ce droit serait bafoué s’il n’y avait pas communication des critères de sélection une fois la procédure de sélection terminée.
Cette décision pose un cadre constitutionnel clair en matière de communication des algorithmes : la transparence est la règle, l’opacité l’exception. Le Conseil constitutionnel a écarté les menaces de fin du monde brandies par le gouvernement et les instances dirigeantes du monde universitaire qui défendaient bec et ongles leur secret. S’il est déplorable que l’usage même de ces algorithmes pour fonder des décisions administratives n’ait pas été une seule fois questionné par le Conseil, ni les pondérations appliquées aux critères dans Parcoursup incluses dans l’obligation de communication, une nouvelle voie s’ouvre toutefois à nous pour attaquer certaines pratiques du renseignement, autre domaine où la transparence n’est pas encore acquise.
References
| 1. | ↑ | Une réserve d’interprétation est une clarification par le Conseil constitutionnel du sens de la loi, dans l’hypothèse où plusieurs lectures du texte auraient été possibles. La réserve d’interprétation permet de « sauver » un texte de loi en ne retenant qu’une interprétation conforme à la Constitution et en écartant toute autre lecture. |
| 2. | ↑ | Pour rappel, c’est ce droit de communication que nous utilisons dans notre campagne Technopolice pour obtenir des documents sur les dispositifs de surveillance déployés par les communes. |