Nous sommes ravis et honorés d’accueillir Stéphane Bortzmeyer qui allie une compétence de haut niveau sur des questions assez techniques et une intéressante capacité à rendre assez claires des choses complexes. Nous le remercions de nous expliquer dans cet article quelles pratiques douteuses tentent certains fournisseurs d’accès à l’Internet, quelles menaces cela représente pour la confidentialité comme pour la neutralité du Net, et pourquoi la parade du chiffrement fait l’objet d’attaques répétées de leur part.
L’actualité de M. Bortzmeyer est son ouvrage à paraître intitulé Cyberstructure, L’Internet : un espace politique. Vous pouvez en lire un extrait et le commander en souscription jusqu’au 10 décembre, où vous pourrez rencontrer l’auteur à la librairie À Livr’ouvert.
Introduction
Pour vous connecter à l’Internet, vous avez besoin d’un FAI (Fournisseur d’Accès à l’Internet), une entreprise ou une association dont le métier est de relier des individus ou des organisations aux autres FAI. En effet, l’Internet est une coalition de réseaux, chaque FAI a le sien, et ce qui constitue l’Internet global, c’est la connexion de tous ces FAI entre eux. À part devenir soi-même FAI, la seule façon de se connecter à l’Internet est donc de passer par un de ces FAI. La question de la confiance est donc cruciale : qu’est-ce que mon FAI fait sans me le dire ?
Outre son travail visible (vous permettre de regarder Wikipédia, et des vidéos avec des chats mignons), le FAI peut se livrer à des pratiques plus contestables, que cet article va essayer d’expliquer. L’article est prévu pour un vaste public et va donc simplifier une réalité parfois assez compliquée.
Notons déjà tout de suite que je ne prétends pas que tous les FAI mettent en œuvre les mauvaises pratiques décrites ici. Il y a heureusement des FAI honnêtes. Mais toutes ces pratiques sont réellement utilisées aujourd’hui, au moins par certains FAI.
La langue française a un seul verbe, « pouvoir », pour désigner à la fois une possibilité technique (« ma voiture peut atteindre 140 km/h ») et un droit (« sur une route ordinaire, je peux aller jusqu’à 80 km/h »). Cette confusion des deux possibilités est très fréquente dans les discussions au sujet de l’Internet. Ici, je parlerais surtout des possibilités techniques. Les règles juridiques et morales encadrant les pratiques décrites ici varient selon les pays et sont parfois complexes (et je ne suis ni juriste ni moraliste) donc elles seront peu citées dans cet article.
Au sujet du numérique
Pour résumer les possibilités du FAI (Fournisseur d’Accès à l’Internet), il faut se rappeler de quelques propriétés essentielles du monde numérique :
- Modifier des données numériques ne laisse aucune trace. Contrairement à un message physique, dont l’altération, même faite avec soin, laisse toujours une trace, les messages envoyés sur l’Internet peuvent être changés sans que ce changement ne se voit.
- Copier des données numériques, par exemple à des fins de surveillance des communications, ne change pas ces données, et est indécelable. Elle est très lointaine, l’époque où (en tout cas dans les films policiers), on détectait une écoute à un « clic » entendu dans la communication ! Les promesses du genre « nous n’enregistrons pas vos données » sont donc impossibles à vérifier.
- Modifier les données ou bien les copier est très bon marché, avec les matériels et logiciels modernes. Le FAI qui voudrait le faire n’a même pas besoin de compétences pointues : les fournisseurs de matériel et de logiciel pour FAI ont travaillé pour lui et leur catalogue est rempli de solutions permettant modification et écoute des données, solutions qui ne sont jamais accompagnées d’avertissements légaux ou éthiques.
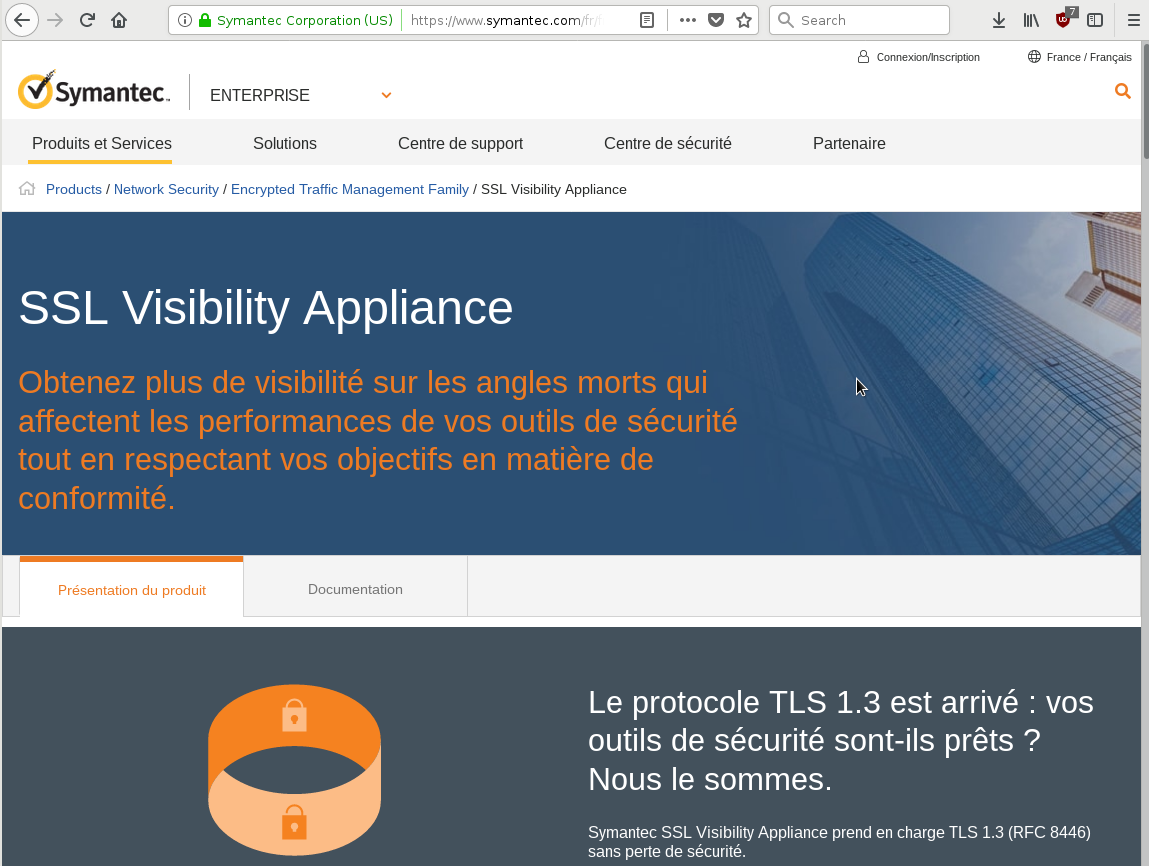
Une publicité pour un logiciel d’interception des communications, même chiffrées. Aucun avertissement légal ou éthique dans la page.
Modifier le trafic réseau
Commençons avec la possibilité technique de modification des données numériques. On a vu qu’elle était non seulement faisable, mais en outre facile. Citons quelques exemples où l’internaute ne recevait pas les données qui avaient été réellement envoyées, mais une version modifiée :
- de 2011 à 2013 (et peut-être davantage), en France, le FAI SFR modifiait les images envoyées via son réseau, pour en diminuer la taille. Une image perdait donc ainsi en qualité. Si la motivation (diminuer le débit) était compréhensible, le fait que les utilisateurs n’étaient pas informés indique bien que SFR était conscient du caractère répréhensible de cette pratique.
- en 2018 (et peut-être avant), Orange Tunisie modifiait les pages Web pour y insérer des publicités. La modification avait un intérêt financier évident pour le FAI, et aucun intérêt pour l’utilisateur. On lit parfois que la publicité sur les pages Web est une conséquence inévitable de la gratuité de l’accès à cette page mais, ici, bien qu’il soit client payant, l’utilisateur voit des publicités qui ne rapportent qu’au FAI. Comme d’habitude, l’utilisateur n’avait pas été notifié, et le responsable du compte Twitter d’Orange, sans aller jusqu’à nier la modification (qui est interdite par la loi tunisienne), la présentait comme un simple problème technique.
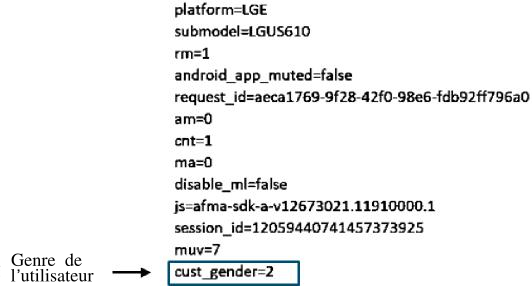
- en 2015 (et peut-être avant), Verizon Afrique du Sud modifiait les échanges effectués entre le téléphone et un site Web pour ajouter aux demandes du téléphone des informations comme l’IMEI (un identificateur unique du téléphone) ou bien le numéro de téléphone de l’utilisateur. Cela donnait aux gérants des sites Web des informations que l’utilisateur n’aurait pas donné volontairement. On peut supposer que le FAI se faisait payer par ces gérants de sites en échange de ce service.
Il s’agit uniquement des cas connus, c’est-à-dire de ceux où des experts ont décortiqué ce qui se passait et l’ont documenté. Il y a certainement de nombreux autres cas qui passent inaperçus. Ce n’est pas par hasard si la majorité de ces manipulations se déroulent dans les pays du Sud, où il y a moins d’experts disponibles pour l’analyse, et où l’absence de démocratie politique n’encourage pas les citoyens à regarder de près ce qui se passe. Il n’est pas étonnant que ces modifications du trafic qui passe dans le réseau soient la règle en Chine. Ces changements du trafic en cours de route sont plus fréquents sur les réseaux de mobiles (téléphone mobile) car c’est depuis longtemps un monde plus fermé et davantage contrôlé, où les FAI ont pris de mauvaises habitudes.
Quelles sont les motivations des FAI pour ces modifications ? Elles sont variées, souvent commerciales (insertion de publicités) mais peuvent être également légales (obligation de censure passant techniquement par une modification des données).
Mais ces modifications sont une violation directe du principe de neutralité de l’intermédiaire (le FAI). La « neutralité de l’Internet » est parfois présentée à tort comme une affaire financière (répartition des bénéfices entre différents acteurs de l’Internet) alors qu’elle est avant tout une protection des utilisateurs : imaginez si la Poste modifiait le contenu de vos lettres avant de les distribuer !
Les FAI qui osent faire cela le savent très bien et, dans tous les cas cités, aucune information des utilisateurs n’avait été faite. Évidemment, « nous changerons vos données au passage, pour améliorer nos bénéfices » est plus difficile à vendre aux clients que « super génial haut débit, vos vidéos et vos jeux plus rapides ! » Parfois, même une fois les interférences avec le trafic analysées et publiées, elles sont niées, mais la plupart du temps, le FAI arrête ces pratiques temporairement, sans explications ni excuses.
Surveiller le trafic réseau
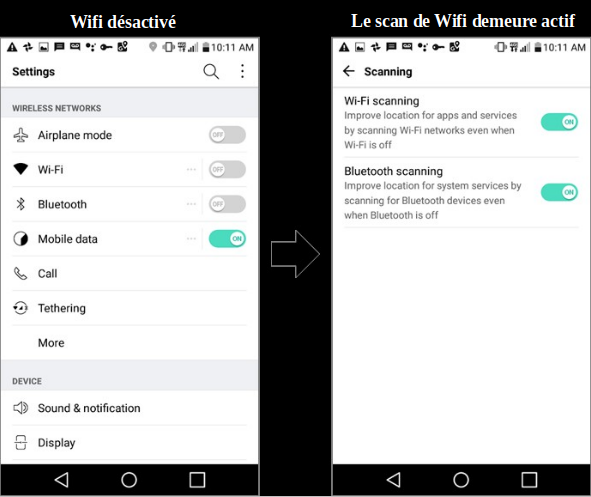
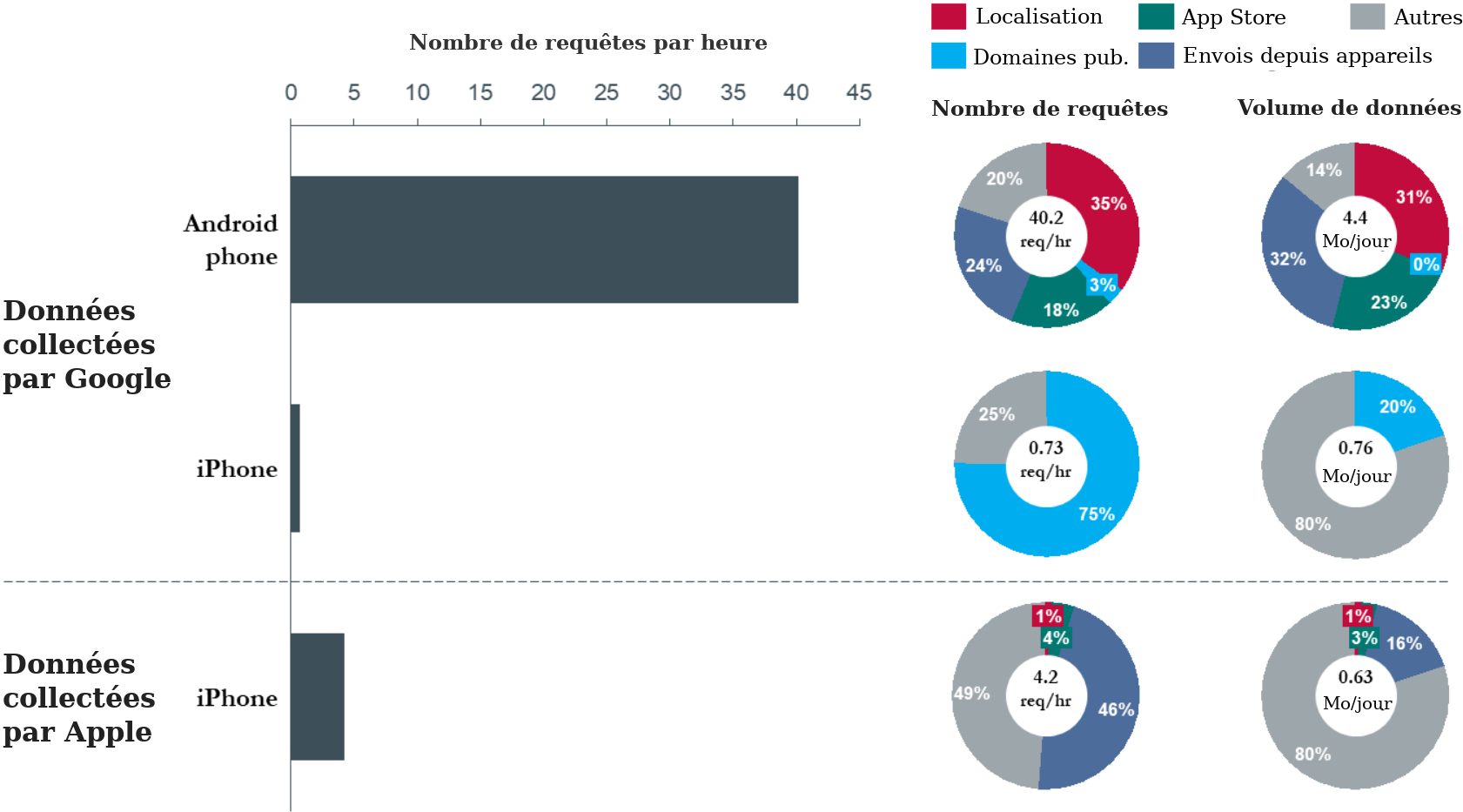
De même que le numérique permet de modifier les données en cours de route, il rend possible leur écoute, à des fins de surveillance, politique ou commerciale. Récolter des quantités massives de données, et les analyser, est désormais relativement simple. Ne croyez pas que vos données à vous sont perdues dans la masse : extraire l’aiguille de la botte de foin est justement ce que les ordinateurs savent faire le mieux.
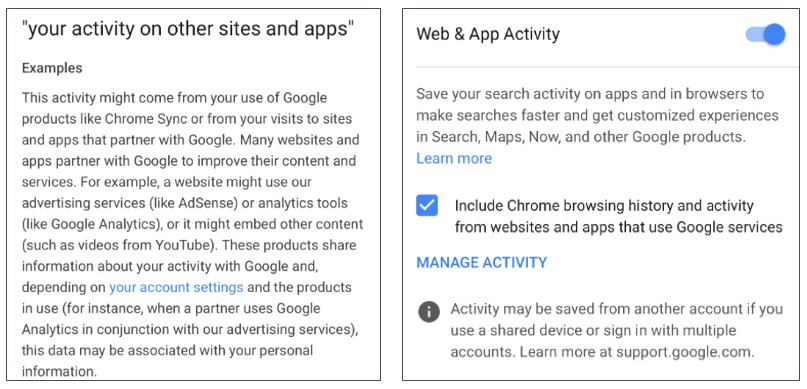
Grâce au courage du lanceur d’alerte Edward Snowden, la surveillance exercée par les États, en exploitant ces possibilités du numérique, est bien connue. Mais il n’y a pas que les États. Les grands intermédiaires que beaucoup de gens utilisent comme médiateurs de leurs communications (tels que Google ou Facebook) surveillent également massivement leurs utilisateurs, en profitant de leur position d’intermédiaire. Le FAI est également un intermédiaire, mais d’un type différent. Il a davantage de mal à analyser l’information reçue, car elle n’est pas structurée pour lui. Mais par contre, il voit passer tout le trafic réseau, alors que même le plus gros des GAFA (Google, Apple, Facebook, Amazon) n’en voit qu’une partie.
L’existence de cette surveillance par les FAI ne fait aucun doute, mais est beaucoup plus difficile à prouver que la modification des données. Comme pour la modification des données, c’est parfois une obligation légale, où l’État demande aux FAI leur assistance dans la surveillance. Et c’est parfois une décision d’un FAI.
Les données ainsi récoltées sont parfois agrégées (regroupées en catégories assez vastes pour que l’utilisateur individuel puisse espérer qu’on ne trouve pas trace de ses activités), par exemple quand elles sont utilisées à des fins statistiques. Elles sont dans ce cas moins dangereuses que des données individuelles. Mais attention : le diable est dans les détails. Il faut être sûr que l’agrégation a bien noyé les détails individuels. Quand un intermédiaire de communication proclame bien fort que les données sont « anonymisées », méfiez-vous. Le terme est utilisé à tort et à travers, et désigne souvent des simples remplacements d’un identificateur personnel par un autre, tout aussi personnel.
La solution du chiffrement
Ces pratiques de modification ou de surveillance des données sont parfois légales et parfois pas. Même quand elles sont illégales, on a vu qu’elles étaient néanmoins pratiquées, et jamais réprimées par la justice. Il est donc nécessaire de ne pas compter uniquement sur les protections juridiques mais également de déployer des protections techniques contre la modification et l’écoute. Deux catégories importantes de protections existent : minimiser les données envoyées, et les chiffrer. La minimisation consiste à envoyer moins de données, et elle fait partie des protections imposées par le RGPD (Règlement [européen] Général sur la Protection des Données). Combinée au chiffrement, elle protège contre la surveillance. Le chiffrement, lui, est la seule protection contre la modification des données.
Mais c’est quoi, le chiffrement ? Le terme désigne un ensemble de techniques, issues de la mathématique, et qui permet d’empêcher la lecture ou la modification d’un message. Plus exactement, la lecture est toujours possible, mais elle ne permet plus de comprendre le message, transformé en une série de caractères incompréhensibles si on ne connait pas la clé de déchiffrement. Et la modification reste possible mais elle est détectable : au déchiffrement, on voit que les données ont été modifiées. On ne pourra pas les lire mais, au moins, on ne recevra pas des données qui ne sont pas les données authentiques.
Dans le contexte du Web, la technique de chiffrement la plus fréquente se nomme HTTPS (HyperText Transfer Protocol Secure). C’est celle qui est utilisée quand une adresse Web commence par https:// , ou quand vous voyez un cadenas vert dans votre navigateur, à gauche de l’adresse. HTTPS sert à assurer que les pages Web que vous recevez sont exactement celles envoyées par le serveur Web, et il sert également à empêcher des indiscrets de lire au passage vos demandes et les réponses. Ainsi, dans le cas de la manipulation faite par Orange Tunisie citée plus haut, HTTPS aurait empêché cet ajout de publicités.
Pour toutes ces raisons, HTTPS est aujourd’hui massivement déployé. Vous le voyez de plus en plus souvent par exemple sur ce blog que vous êtes en train de lire.
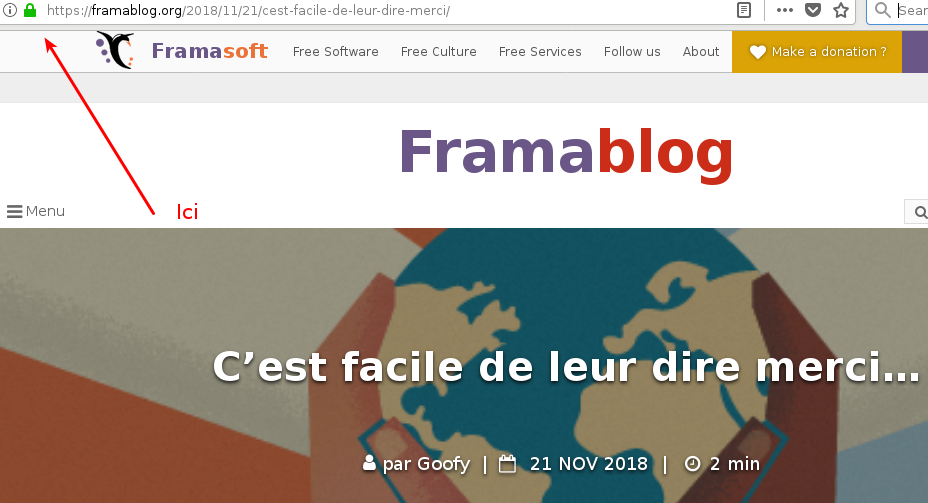
Tous les sites Web sérieux ont aujourd’hui HTTPS
Le chiffrement n’est pas utilisé que par HTTPS. Si vous utilisez un VPN (Virtual Private Network, « réseau privé virtuel »), celui-ci chiffre en général les données, et la motivation des utilisateurs de VPN est en effet en général d’échapper à la surveillance et à la modification des données par les FAI. C’est particulièrement important pour les accès publics (hôtels, aéroports, Wifi du TGV) où les manipulations et filtrages sont quasi-systématiques.
Comme toute technique de sécurité, le chiffrement n’est pas parfait, et il a ses limites. Notamment, la communication expose des métadonnées (qui communique, quand, même si on n’a pas le contenu de la communication) et ces métadonnées peuvent être aussi révélatrices que la communication elle-même. Le système « Tor », qui peut être vu comme un type de VPN particulièrement perfectionné, réduit considérablement ces métadonnées.
Le chiffrement est donc une technique indispensable aujourd’hui. Mais il ne plait pas à tout le monde. Lors du FIC (Forum International de la Cybersécurité) en 2015, le représentant d’un gros FAI français déplorait en public qu’en raison du chiffrement, le FAI ne pouvait plus voir ce que faisaient ses clients. Et ce raisonnement est apparu dans un document d’une organisation de normalisation, l’IETF (Internet Engineering Task Force). Ce document, nommé « RFC 8404 » décrit toutes les pratiques des FAI qui peuvent être rendues difficiles ou impossibles par le chiffrement. Avant le déploiement massif du chiffrement, beaucoup de FAI avaient pris l’habitude de regarder trop en détail le trafic qui circulait sur leur réseau. C’était parfois pour des motivations honorables, par exemple pour mieux comprendre ce qui passait sur le réseau afin de l’améliorer. Mais, aujourd’hui, compte-tenu de ce qu’on sait sur l’ampleur massive de la surveillance, il est urgent de changer ses pratiques, au lieu de simplement regretter que ce qui était largement admis autrefois soit maintenant rejeté.
Cette liste de pratiques de certains FAI est une information intéressante mais il est dommage que ce document de l’IETF les présente comme si elles étaient toutes légitimes, alors que beaucoup sont scandaleuses et ne devraient pas être tolérées. Si le chiffrement les empêche, tant mieux !
Conclusion
Le déploiement massif du chiffrement est en partie le résultat des pratiques déplorables de certains FAI. Il est donc anormal que ceux-ci se plaignent des difficultés que leur pose le chiffrement. Ils sont les premiers responsables de la méfiance des utilisateurs !
J’ai surtout parlé ici des risques que le FAI écoute les messages, ou les modifie. Mais la place cruciale du FAI dans la communication fait qu’il existe d’autres risques, comme celui de censure de certaines activités ou certains services, ou de coupure d’accès. À l’heure où la connexion à l’Internet est indispensable pour tant d’activités, une telle coupure serait très dommageable.
Quelles sont les solutions, alors ? Se passer de FAI n’est pas réaliste. Certes, des bricoleurs peuvent connecter quelques maisons proches en utilisant des techniques fondées sur les ondes radio, mais cela ne s’étend pas à tout l’Internet. Par contre, il ne faut pas croire qu’un FAI est forcément une grosse entreprise commerciale. Ce peut être une collectivité locale, une association, un regroupement de citoyens. Dans certains pays, des règles très strictes imposées par l’État limitent cette activité de FAI, afin de permettre le maintien du contrôle des citoyens. Heureusement, ce n’est pas (encore ?) le cas en France. Par exemple, la FFDN (Fédération des Fournisseurs d’Accès Internet Associatifs) regroupe de nombreux FAI associatifs en France. Ceux-ci se sont engagés à ne pas recourir aux pratiques décrites plus haut, et notamment à respecter le principe de neutralité.
Bien sûr, monter son propre FAI ne se fait pas en cinq minutes dans son garage. Mais c’est possible en regroupant un collectif de bonnes volontés.
Et, si on n’a pas la possibilité de participer à l’aventure de la création d’un FAI, et pas de FAI associatif proche, quelles sont les possibilités ? Peut-on choisir un bon FAI commercial, en tout cas un qui ne viole pas trop les droits des utilisateurs ? Il est difficile de répondre à cette question. En effet, aucun FAI commercial ne donne des informations détaillées sur ce qui est possible et ne l’est pas. Les manœuvres comme la modification des images dans les réseaux de mobiles sont toujours faites en douce, sans information des clients. Même si M. Toutlemonde était prêt à passer son week-end à comparer les offres de FAI, il ne trouverait pas l’information essentielle « est-ce que ce FAI s’engage à rester strictement neutre ? » En outre, contrairement à ce qui existe dans certains secteurs économiques, comme l’agro-alimentaire, il n’existe pas de terminologie standardisée sur les offres des FAI, ce qui rend toute comparaison difficile.
Dans ces conditions, il est difficile de compter sur le marché pour réguler les pratiques des FAI. Une régulation par l’État n’est pas forcément non plus souhaitable (on a vu que c’est parfois l’État qui oblige les FAI à surveiller les communications, ainsi qu’à modifier les données transmises). À l’heure actuelle, la régulation la plus efficace reste la dénonciation publique des mauvaises pratiques : les FAI reculent souvent, lorsque des modifications des données des utilisateurs sont analysées et citées en public. Cela nécessite du temps et des efforts de la part de ceux et celles qui font cette analyse, et il faut donc saluer leur rôle.

La guerre contre les pratiques douteuses, déjà au XIe siècle… – Image retrouvée sur ce site.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}