Mise à jour
Mise à jour de la base de données, veuillez patienter...
source: Framablog
Chaque mois le Fediverse s’enrichit de nouveaux projets, probablement parce nous désirons toujours plus de maîtrise de notre vie numérique.
Décentralisé et fédéré, ce réseau en archipel s’articule autour de briques technologiques qui permettent à ses composantes diverses de communiquer. Au point qu’à chaque rumeur de projet nouveau dans le monde du Libre la question est vite posée de savoir s’il sera « fédéré » et donc relié à d’autres projets.
Si vous désirez approfondir vos connaissances au plan technique et au plan de la réflexion sur la fédération, vous trouverez matière à vous enrichir dans les deux mémoires de Nathalie, stagiaire chez Framasoft l’année dernière.
Aujourd’hui, alors que l’idée de publier sur un blog semble en perte de vitesse, apparaît un nouvel intérêt pour la publication d’articles sur des plateformes libres et fédérées, comme Plume et WriteFreely. Maîtriser ses publications sans traqueurs ni publicités parasites, sans avoir à se plier aux injonctions des GAFAM pour se connecter et publier, sans avoir à brader ses données personnelles pour avoir un espace numérique d’expression, tout en étant diffusé dans un réseau de confiance et pouvoir interagir avec lui, voilà dans quelle mouvance se situe le projet DIFFU auquel nous vous invitons à contribuer et que vous présente l’interviewé du jour…
Bonjour, peux-tu te présenter, ainsi que tes activités ?

Jean-Pierre et une partie de l’équipe de développement en arrière-plan
Bonjour Framasoft. Je m’appelle Jean-Pierre Morfin, on me connaît aussi sur les réseaux sociaux et dans le monde du libre sous le pseudo jpfox. J’ai 46 ans, je vis avec ma tribu familiale recomposée dans un village ardéchois où je pratique un peu (pas assez) le vélo. Informaticien depuis mon enfance, je suis membre du GULL G3L basé à Valence, où je gère avec d’autres l’activité C.H.A.T.O.N.S qui propose plusieurs services comme Mastodon, Diaspora, TT-Rss, boite mail, owncloud…
Passionnés par le libre, Michaël, un ami de longue date et moi-même avons créé en 2010 ce qui s’appelle désormais une Entreprise du Numérique Libre nommée Befox qui propose ses services aux TPE/PME dans la Drôme et l’Ardèche principalement : réalisation de sites à base de solutions libres comme Prestashop, Drupal ou autres, installation Dolibarr et interconnexion entre différents logiciels ou plateformes, hébergement applicatif, évolutions chez nos fidèles clients constituent l’essentiel de notre activité.
Et donc, vous voulez vous lancer dans le développement d’un nouveau logiciel fédéré, « Diffu ». Pourquoi ?
Tout d’abord nous avons ressenti tous les deux le besoin de retourner aux fondamentaux du Libre, et quoi de plus fondamental que le développement d’un logiciel ? Lors de nos divagations sur le Fédiverse, les remarques récurrentes qu’on y trouve ici ou là contre l’utilisation de Medium, nous ont fait penser qu’une alternative pouvait être intéressante. De plus, l’ouverture d’un compte Medium se fait nécessairement avec un compte Facebook ou Google, c’est leur façon d’authentifier un utilisateur ; en bons adeptes de la dégafamisation, c’est une raison de plus de créer une alternative à cette plateforme.
Voyant le succès et tout le potentiel de La Fédération, il fallait que cette nouvelle solution entre de ce cadre-là, car recréer une plateforme unique de publication ou un nouveau moteur de blog avec une gestion interne des commentaires ne présente aucun intérêt. Avec Diffu, la publication d’un article sur une des instances du réseau sera poussée sur le Fédiverse et les commentaires et réactions faits sur Mastodon, Pleroma, Hubzilla ou autre… seront agrégés pour être restitués directement sur la page de l’article. J’invite les lecteurs à jeter un œil à la maquette que nous avons réalisée pour se faire une idée, elle n’est pas fonctionnelle car cela reste encore un projet.
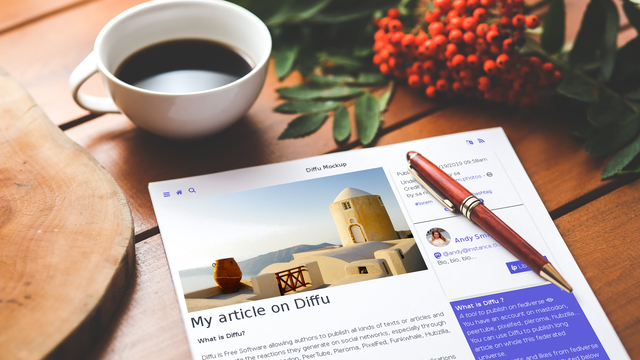
Quant au nom Diffu, on lui trouve deux sens : abréviation de Diffusion, ce qui reste l’objectif d’une plateforme de publication d’articles. Et dans sa prononciation à l’anglaise Diff You qui peut se comprendre Differentiate yourself – Différenciez vous ! C’est un peu ce que l’on fait lorsqu’on livre son avis, son expertise, ses opinions ou ses pensées dans un article.
Il existe déjà des logiciels fédérés de publication, tels que Plume ou WriteFreely. Quelles différences entre Diffu et ces projets ?
Absolument, ces deux applications libres, elles aussi, proposent de nombreux points de similitude avec Diffu notamment dans l’interconnexion avec le Fediverse et la possibilité de réagir aux articles avec un simple compte compatible avec ActivityPub.
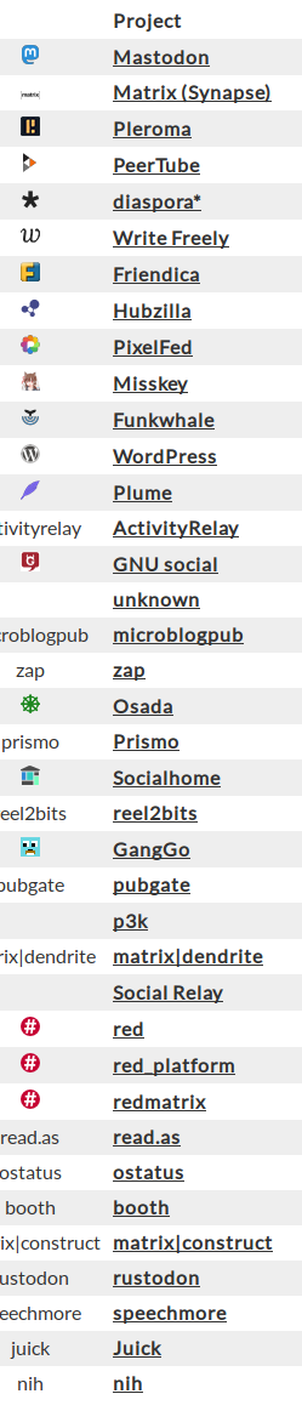
À ce jour 38 projets dans la Fédération, selon le site https://the-federation.info/#projects
La première différence est que pour Plume et WriteFreely, il est nécessaire de créer un compte sur l’instance que l’on souhaite utiliser. Avec Diffu, suivant les restrictions définies par l’administrateur⋅e de l’instance, il sera possible de créer un article juste en donnant son identifiant Mastodon par exemple (pas le mot de passe, hein, juste le pseudo et le nom de l’instance). L’auteur recevra un lien secret par message direct sur son compte Mastodon lui permettant d’accéder à son environnement de publication et de rédiger un nouvel article. Ce dernier sera associé à son auteur ou autrice, son profil Mastodon s’affichant en signature de l’article. Lors de la publication de l’article sur le Fediverse, l’autrice ou l’auteur sera mentionné⋅e dans le pouet qu’il n’aura plus qu’à repartager. L’adresse de la page de l’article sera utilisable sur les autres réseaux sociaux bien évidemment.
Nous voyons plus les instances Diffu comme des services proposés aux possesseurs de comptes ActivityPub. Comme on crée un Framadate ou un Framapad en deux clics, on pourra créer un article.
Les modes de modération et de workflow proposés par Diffu, la thématique choisie, les langues acceptées, la définition des règles de gestion permettront aux administrateurs de définir le public pouvant poster sur leur instance. Il sera par exemple possible de n’autoriser que les auteurs ayant un compte sur telle instance Mastodon, Diffu devenant un service complémentaire que pourrait proposer un CHATONS à ses utilisateurs Mastodon.
Ou, à l’opposé, un défenseur de la liberté d’expression peut laisser son instance Diffu open bar, au risque de voir son instance bloquée par d’autres acteurs du Fediverse, la régulation se faisant à plusieurs niveaux. Nous travaillons encore sur la définition des options de modération possibles, le but étant de laisser à l’administrateur⋅e toute la maîtrise des règles du jeu.
Les options retenues seront clairement explicites sur son instance pour que chacun⋅e puisse choisir la bonne plateforme qui lui convient le mieux. On imagine déjà faire un annuaire reprenant les règles de chaque instance pour aider les auteurs et autrices à trouver la plus appropriée à leur publication. Quitte à écrire sur plusieurs instances en fonction du sujet de l’article : « J’ai testé un nouveau vélo à assistance électrique » sur diffu.velo-zone.fr et « Comment installer LineageOS sur un Moto G4 » sur diffu.g3l.org.
L’autre différence avec Plume et WriteFreely est le langage retenu pour le développement de Diffu. Nous avons choisi PHP car il reste à nos yeux le plus simple à installer dans un environnement web et nous allons tout faire pour que ce soit vraiment le cas. Le locataire d’un simple hébergement mutualisé pourra installer Diffu : on dézippe le fichier de la dernière version, on envoie le tout par ftp sur le site, on accède à la page de configuration pour définir les options de son instance et ça fonctionne. Idem pour les mises à jour.
Nous avons déjà des contacts avec les dev de Plume qui sont tout aussi motivés que nous pour connecter nos plateformes et permettre une interaction entre les utilisateurs. C’est la magie du Fediverse !
Vous êtes en phase de crowdfunding pour le projet Diffu. À quoi va servir cet argent ?
Tout simplement à nous libérer du temps pour développer ce logiciel. On ne peut malheureusement pas se permettre de laisser en plan l’activité de Befox pendant des semaines car cela correspondrait à une absence complète de revenu pour nous deux. C’est donc notre société Befox qui va récolter le fruit de cette campagne et le transformer en rémunération. Nous avons visé au plus juste l’objectif de cette campagne de financement même si on sait que l’on va passer pas mal de temps en plus sur ce projet mais quand on aime…
Il faut aussi mentionner les 8 % de la campagne destinés à rétribuer la plateforme de financement Ulule.
Comment envisages-tu l’avenir de Diffu ?
Comme tout projet libre, après la publication des premières versions, la mise en ligne du code source, nous allons être à l’écoute des utilisateurs pour ajouter les fonctionnalités les plus attendues, garder la compatibilité avec le maximum d’acteurs du Fediverse. On sait que le protocole ActivityPub et ceux qui s’y rattachent peuvent avoir des interprétations différentes. On le voit pour les plateformes déjà en places comme Pleroma, Mastodon, Hubzilla, GNUSocial, PeerTube, PixelFed, WriteFreely et Plume… c’est une nécessité de collaborer avec les autres équipes de développement pour une meilleure expérience des utilisateurs.
Comme souvent ici, on te laisse le mot de la fin, pour poser LA question que tu aurais aimé qu’on te pose, et à laquelle tu aimerais répondre…
La question que l’on peut poser à tous les développeurs du Libre : quel éditeur de sources, Vim ou Emacs ?

Image : https://framalab.org/gknd-creator/
La réponse en ce qui me concerne, c’est Vim bien sûr.
Plus sérieusement, cela me permet d’évoquer ce que je trouve génial avec les Logiciels Libres, le fait qu’il y en a pour tous les goûts, que si un outil ne te convient pas, tu peux en utiliser un autre ou modifier/faire modifier celui qui existe pour l’adapter à tes attentes.
Alors même si Plume et WriteFreely existent et font très bien certaines choses, ils sont tous les deux différents et je suis convaincu que Diffu a sa place et viendra en complément de ceux-ci. J’ai hâte de pouvoir m’investir à fond dans ce projet.
Merci pour cette interview, à bientôt sur le Fediverse !
Ce nouvel ouvrage vous entraîne dans les coulisses de nos usages numériques quotidiens et nous fait découvrir en profondeur la gestion des bases de données et le langage qui sert à interagir avec elles.
Vous n’avez jamais vu une base de données ? Moi non plus, mais comme vous, dès que je veux faire un achat en ligne ou simplement mener une recherche sur le Web, mon appareil s’adresse à une base de données.

Bon, SQL et SGBD, SGBDRO, les sigles ça fait peur, mais Vincent Lozano et Étienne Georges qui ont fait un travail remarquable ont prévu un précieux glossaire (la table des matières est à l’avenant).
Mais peut-être êtes-vous plutôt en train d’arborer un sourire un peu condescendant, parce que vous, vous nagez dans les bases de données avec l’aisance d’une anguille dans la mer des Sargasses. Eh bien, il y a fort à parier qu’au-delà des chapitres d’initiation, ce nouveau Framabook va vous faire découvrir ou redécouvrir des aspects méconnus de ce domaine vaste et évolutif.
Voici d’ailleurs quelques observations de Nailyk, qui a déjà parcouru l’ouvrage avec intérêt :
Un gros volume de 350 pages tout de même, mais les chapitres sont digestes. Pas trop longs, bien ordonnés et très bien regroupés.
Je trouve réducteur de le cantonner aux SGBD. Les notions de ses chapitres concernant le stockage des informations me semble être tout à fait appropriés pour d’autres sujets.
Même si vous n’êtes plus un débutant et bien que tout soit parfaitement détaillé, il faut parfois s’accrocher dur.
Heureusement, les touches d’humour font un bien fou à la lecture. La mise en forme, les typos et les schéma rendent la lecture vraiment agréable. Excellent livre que je m’empresserai de recommander à plusieurs personnes ! On sent le travail minutieux et c’est très agréable !

En 1993, dans le cadre de qu’on appelait le « service militaire » au service informatique d’une base aérienne, via un logiciel de la société Borland qui se nommait Paradox. Puis en 1999, lorsque j’ai été nommé maître de conférences à l’Énise, j’ai découvert PostgreSQL. J’ai développé pas mal d’applications de gestion en PHP puis jQuery qui s’appuyaient sur ce SGBD libre. L’Énise s’est ensuite équipée de la Rolls ( !) des systèmes de gestion de bases de données : Oracle.
L’idée forte est de retranscrire dans le manuel toute la chaîne de conception d’une base de données à partir de zéro. Ce qui va au-delà de ce que suggère notre titre, car il ne s’agit pas uniquement du langage SQL lui-même, mais des différentes étapes qui vont mener, à partir de l’idée « d’informatiser » un système, à la création d’une base. C’est ce qu’on appelle la modélisation conceptuelle et le livre l’aborde à partir de différentes études de cas.
Puisqu’il est question de bases de données, l’autre parti pris est de montrer comment sont stockées les informations basiques que l’on manipule tous les jours : les entiers, les nombres à virgule, les caractères, avec les petites subtilités pas forcément connues comme la précision des flottants et l’encodage UTF-8. Dans le même ordre d’idée, pour rester dans les principes fondamentaux, sont exposées dans le livre, quelques rudiments pour comprendre les algorithmes de tri et de recherche qui se cachent derrière le SELECT de SQL.
Enfin, concernant SQL lui-même, un accent est d’une part mis sur l’aspect traitement (procédures, triggers, vues) et sur le fait que les SGBD savent gérer les accès concurrents (plusieurs processus qui accèdent aux données en même temps), et sur l’aspect contraintes d’intégrité qui font la force et la particularité des SGBD relationnelles.
Ni Étienne, ni moi ne sommes des informaticiens de formation. Nous avons été tous deux formés en tant qu’ingénieurs généralistes et sommes des autodidactes en informatique, ce qui nous pas empêché d’en faire notre métier. C’est sans doute ce qui explique que ce livre n’est pas un livre orthodoxe, bâti comme un cours magistral, avec des théorèmes et des propriétés. Il y a un parti pris de didactique non dogmatique, qui amène à découvrir les concepts par l’exemple notamment.
Il l’est évidemment parce que PostgreSql est LE logiciel libre de gestion de bases de donnée relationnelles mais il l’est aussi dans l’esprit. Être capable d’analyser un système d’information existant, le modéliser et bâtir une base grâce à Sql constituent aujourd’hui des atouts maîtres pour être relativement libre, libre de développer ses propres applications notamment.
Pour découvrir l’ouvrage rendez-vous sur la page Framabook qui lui est dédiée
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.

Depuis deux ans, le nombre de services de surveillance des contenus a explosé. Reste que, malgré les exemples montés en épingle par ces services pour promouvoir l’efficacité de leurs solutions, rien ne prouve que ces outils fonctionnent, comme le pointe le Centre pour la Justice dans un article analysant le phénomène des outils de surveillance scolaire (qui souligne qu’au moins 63 districts scolaires sur les 13 000 que comptent les États-Unis auraient acheté ce type services). Or, soulignent les experts du Brennan Center, en raison des problèmes d’analyse de la langue notamment, les outils de surveillance des médias sociaux sont susceptibles d’étiqueter de façon disproportionnée certains élèves plus que d’autres, et notamment les élèves de couleurs ou d’origines minoritaires, qui sont souvent punis plus sévèrement que les élèves blancs identifiés de façon similaire. Ils rappellent d’ailleurs que les recherches montrent qu’à mesure que les mesures de sécurité scolaires prolifèrent, les élèves se sentent souvent moins en sécurité. De plus, une surveillance excessive et inutile (absolument pas proportionnelle à ses finalités, dirions-nous de ce côté de l’Atlantique) risque d’avoir un impact négatif sur la vie privée des élèves et nuire à leur capacité de s’exprimer.
« la goutte d’eau qui a fait déborder le vase, c’est lors de notre réunion de correcteurs, cette semaine. Nous avons demandé à notre inspecteur de nous réunir pour parler de nos inquiétudes, puisque la plupart des collègues, toutes disciplines confondues, sont désormais hostiles au projet de lycée Blanquer. Il nous a menacé de nous envoyer les CRS. Dire à des profs de philo, formés au débat et à la discussion, qu’on n’a pas le droit, ne serait-ce que de parler, c’est inentendable. »
« On veut faire croire que tirer au LBD (lanceur de balles de défense) serait une violence policière, que lancer une grenade de désencerclement serait une violence policière, que donner un coup de matraque serait encore une violence policière. Mais ce serait oublier les circonstances et le cadre d’emploi. C’est cela la réalité, tout le reste, c’est de la polémique. »

Amazon est au centre d’un scandale qui s’aggrave en Allemagne : le géant des achats en ligne se trouve sous l’accusation d’avoir employé des agents de sécurité ayant des liens néonazis pour intimider ses travailleurs étrangers.
La chaîne de télévision allemande ARD a fait ces allégations dans un documentaire sur le traitement réservé par Amazon à plus de 5 000 employés temporaires venus de toute l’Europe pour travailler dans ses centres de conditionnement et de distribution allemands.
Le film montre des gardes d’une société du nom de HESS Security, omniprésents, portant des uniformes noirs ainsi que des bottes et des coupes de cheveux militaires. Ils sont employés pour maintenir l’ordre dans les foyers et les hôtels bon marché où les travailleurs étrangers séjournent. « Beaucoup d’ouvriers ont peur », ont déclaré les responsables du programme.

Les philosophes Michel Foucault et Gilles Deleuze ont défini de façon très précise plusieurs types de coercitions exercées par les sociétés sur leurs membres : ils distinguent en particulier la « société disciplinaire » (telles que la société en trois ordres d’Ancien Régime ou la caserne-hôpital-usine du XIXe siècle) de la « société de contrôle » qui est la nôtre aujourd’hui.
Dans une « société de contrôle », les mécanismes de coercition ne sont pas mis en œuvre par des autorités constituées qui les appliquent au corps social par contact local (autorité familiale, pression hiérarchique dans l’usine, surveillant de prison, etc.), mais sont incorporées par chacun (métaphoriquement et littéralement, jusqu’à l’intérieur du corps et de l’esprit), qui se surveille lui-même et se soumet à la surveillance opérée par d’autres points distants du corps social, grâce à une circulation rapide et fluide de l’information d’un bord à l’autre de la société. Wikipédia donne un bon aperçu du concept, dont on trouvera une lecture plus approfondie ici. Qui peut souhaiter d’être soumis à un contrôle dont les critères lui échappent ? C’est pourtant ce que nous acceptons, en laissant s’installer partout la vidéosurveillance et la reconnaissance faciale.

Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
La semaine dernière, le visage de Dong Mingzhu, la présidente d’un important fabricant de climatiseurs en Chine, a été exposé sur un écran géant à Ningbo, une grande ville portuaire de la province du Zhejiang, dans l’est de la Chine, pour lui faire honte publiquement pour avoir enfreint une loi routière. Le Zhejiang est l’une des provinces qui a déployé l’an dernier une technologie de reconnaissance faciale pour humilier les citoyens qui déambulent en mettant leurs photos sur d’immenses écrans LED. Mais les caméras n’ont pas attrapé Mingzhu en train de traverser illégalement – elles ont identifié une photo d’elle sur une publicité de bus
Ce ne sont là que quelques-uns des moyens ingénieux par lesquels la police de la sûreté de l’Etat – mieux connue sous le nom de Stasi – espionna des individus entre 1950 et 1990, dont beaucoup sont maintenant exposés au musée de la Stasi à Berlin.
À l’heure actuelle, la police allemande – à l’instar de nombreuses forces de l’ordre – souhaite non seulement avoir accès à des données téléphoniques, mais également à des informations recueillies par des assistants numériques tels que Google Home et Amazon Echo.

Nous sommes entourés de caméras de surveillance qui nous enregistrent à chaque tournant. Mais la plupart du temps, lorsque ces caméras nous observent, personne ne regarde ce que ces caméras observent ou enregistrent parce que personne ne va payer une armée de gardes de sécurité pour une tâche aussi monotone et qui prendrait autant de temps.
Mais imaginez que toutes ces vidéos soient regardées – que des millions d’agents de sécurité les surveillent 24 heures sur 24, 7 jours sur 7. Imaginez cette armée composée de gardes qui n’ont pas besoin d’être payés, qui ne s’ennuient jamais, qui ne dorment jamais, qui ne manquent jamais un détail, et qui se souviennent de tout ce qu’ils ont vu. Une telle armée d’observateurs pourrait scruter chaque personne qu’ils voient, à la recherche de signes d’un comportement « suspect ». Avec un temps et une attention illimités, ils pourraient aussi enregistrer des détails sur toutes les personnes qu’ils voient – leurs vêtements, leurs expressions et leurs émotions, leur langage corporel, les gens avec qui ils sont et comment ils se rapportent à eux, et toutes leurs activités et leurs mouvements.
Ce scénario peut sembler tiré par les cheveux, mais c’est un monde qui pourrait bientôt arriver. Les gardes ne seront pas humains, bien sûr – ce seront des agents de l’IA.

[…] si elle s’affiche confiante quant au fait d’échapper à la prison, elle estime que le plus grave est déjà arrivé : « Le sauvetage humanitaire est criminalisé. »
[…] L’équipage est accusé d’avoir à plusieurs reprises aidé et encouragé l’immigration illégale pour être allé porter secours à des migrants qui se trouvaient dans les eaux territoriales libyennes. Pia Klemp répond qu’elle n’a fait que respecter le droit maritime international, qui impose de porter secours à toute personne en détresse.
[…] Selon l’ONU, 350 personnes sont mortes dans la traversée depuis le début de l’année, tandis que 1 940 atteignaient les côtes italiennes – soit un taux de mortalité de 15 %.
Mobilizon : dernière ligne droite de l’appel de fonds (linuxfr.org)
Encore un petit effort pour Mobilizon, un outil libre et fédéré qui nous permettra de sortir nos événements de Facebook !

En 2018, le gouvernement a donné la priorité à la transformation numérique des administrations pour atteindre l’objectif fixé par le président de la République de 100 % de services publics dématérialisés à horizon 2022. Une annonce qui inquiète de nombreux travailleurs sociaux en Seine-Saint-Denis, directement confrontés à des usagers touchés de plein fouet par ce développement du numérique […] « Il y a eu une accélération de la dématérialisation en France qui, pour un public dépendant des prestations sociales, est absolument sidérant. L’effet de cette simplification a bénéficié avant tout aux personnes qui savent utiliser Internet. » […] « Le numérique ne fait qu’accentuer les inégalités sociales, il ne les règle pas. Dans un département déjà sous-doté par rapport aux autres dans des services comme ceux de l’accès aux droits, la numérisation n’endiguera rien. On fait disparaître la file d’attente, mais on ne fait pas disparaître les gens qui ont des besoins. »

L’infrastructure de la surveillance de masse est trop complexe et l’oligopole technologique trop puissant pour qu’il soit utile de parler de consentement individuel. Même les experts n’ont pas une vue d’ensemble de l’économie de la surveillance, en partie parce que ses bénéficiaires sont secrets, et en partie parce que tout le système est en mutation. Dire aux gens qu’ils sont propriétaires de leurs données et qu’ils devraient décider quoi en faire n’est qu’un autre moyen de les priver de leur pouvoir.
Notre discours sur la protection de la vie privée doit être élargi pour aborder les questions fondamentales sur le rôle de l’automatisation : Dans quelle mesure le fait de vivre dans un monde saturé de surveillance est-il compatible avec le pluralisme et la démocratie ? Quelles sont les conséquences de l’éducation d’une génération d’enfants dont chaque action alimente une base de données d’entreprise ? Que signifie être manipulé dès le plus jeune âge par des algorithmes d’apprentissage automatique qui apprennent de manière adaptative à façonner notre comportement ?
Ainsi, au moment même où les industriels démantèlent le système de la consigne, s’exonérant des coûts de retraitement, et prennent des décisions structurellement antiécologiques, ils en appellent à la responsabilisation écologique des consommateurs. Un cas typique de double morale, où l’on proclame une norme valant pour tous sauf pour soi. Responsabiliser les autres pour mieux se déresponsabiliser soi-même.
Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
Protocole, HTTP, interopérabilité, ça vous parle ? Et normes, spécifications, RFC, ça va toujours ? Si vous avez besoin d’y voir un peu plus clair, l’article ci-dessous est un morceau de choix rédigé par Stéphane Bortzmeyer qui s’est efforcé de rendre accessibles ces notions fondamentales.
Le 21 mai 2019, soixante-neuf organisations, dont Framasoft, ont signé un appel à ce que soit imposé, éventuellement par la loi, un minimum d’interopérabilité pour les gros acteurs commerciaux du Web.
« Interopérabilité » est un joli mot, mais qui ne fait pas forcément partie du vocabulaire de tout le monde, et qui mérite donc d’être expliqué. On va donc parler d’interopérabilité, de protocoles, d’interfaces, de normes, et j’espère réussir à le faire tout en restant compréhensible (si vous êtes informaticien·ne professionnel·lle, vous savez déjà tout cela ; mais l’appel des 69 organisations concerne tout le monde).
Le Web, ou en fait tout l’Internet, repose sur des protocoles de communication. Un protocole, c’est un ensemble de règles qu’il faut suivre si on veut communiquer. Le terme vient de la communication humaine, par exemple, lorsqu’on rencontre quelqu’un, on se serre la main, ou bien on se présente si l’autre ne vous connaît pas, etc. Chez les humains, le protocole n’est pas rigide (sauf en cas de réception par la reine d’Angleterre dans son palais, mais cela doit être rare chez les lectrices et lecteurs du Framablog). Si la personne avec qui vous communiquez ne respecte pas exactement le protocole, la communication peut tout de même avoir lieu, quitte à se dire que cette personne est bien impolie. Mais les logiciels ne fonctionnent pas comme des humains. Contrairement aux humains, ils n’ont pas de souplesse, les règles doivent être suivies exactement. Sur un réseau comme l’Internet, pour que deux logiciels puissent communiquer, chacun doit donc suivre exactement les mêmes règles, et c’est l’ensemble de ces règles qui fait un protocole.
Un exemple concret ? Sur le Web, pour que votre navigateur puisse afficher la page web désirée, il doit demander à un serveur web un ou plusieurs fichiers. La demande se fait obligatoirement en envoyant au serveur le mot GET (« donne », en anglais) suivi du nom du fichier, suivi du mot « HTTP/1.1 ». Si un navigateur web s’avisait d’envoyer le nom du fichier avant le mot GET, le serveur ne comprendrait rien, et renverrait plutôt un message d’erreur. En parlant d’erreurs, vous avez peut-être déjà rencontré le chiffre 404 qui est simplement le code d’erreur qu’utilisent les logiciels qui parlent HTTP pour signaler que la page demandée n’existe pas. Ces codes numériques, conçus pour être utilisés entre logiciels, ont l’avantage sur les textes de ne pas être ambigus, et de ne pas dépendre d’une langue humaine particulière. Cet exemple décrit une toute petite partie du protocole nommé HTTP (pour Hypertext Transfer Protocol) qui est le plus utilisé sur le Web.
Il existe des protocoles bien plus complexes. Le point important est que, derrière votre écran, les logiciels communiquent entre eux en utilisant ces protocoles. Certains servent directement aux logiciels que vous utilisez (comme HTTP, qui permet à votre navigateur Web de communiquer avec le serveur qui détient les pages désirées), d’autres protocoles relèvent de l’infrastructure logicielle de l’Internet ; vos logiciels n’interagissent pas directement avec eux, mais ils sont indispensables.
Le protocole, ces règles de communication, sont indispensables dans un réseau comme l’Internet. Sans protocole, deux logiciels ne pourraient tout simplement pas communiquer, même si les câbles sont bien en place et les machines allumées. Sans protocole, les logiciels seraient dans la situation de deux humains, un Français ne parlant que français, et un Japonais ne parlant que japonais. Même si chacun a un téléphone et connaît le numéro de l’autre, aucune vraie communication ne pourra prendre place. Tout l’Internet repose donc sur cette notion de protocole.
Le protocole permet l’interopérabilité. L’interopérabilité est la capacité à communiquer de deux logiciels différents, issus d’équipes de développement différentes. Si une université bolivienne peut échanger avec une entreprise indienne, c’est parce que toutes les deux utilisent des protocoles communs.

Un exemple classique d’interopérabilité : la prise électrique. Kae [CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons
Seuls les protocoles ont besoin d’être communs : l’Internet n’oblige pas à utiliser les mêmes logiciels, ni à ce que les logiciels aient la même interface avec l’utilisateur. Si je prends l’exemple de deux logiciels qui parlent le protocole HTTP, le navigateur Mozilla Firefox (que vous êtes peut-être en train d’utiliser pour lire cet article) et le programme curl (utilisé surtout par les informaticiens pour des opérations techniques), ces deux logiciels ont des usages très différents, des interfaces avec l’utilisateur reposant sur des principes opposés, mais tous les deux parlent le même protocole HTTP. Le protocole, c’est ce qu’on parle avec les autres logiciels (l’interface avec l’utilisateur étant, elle, pour les humain·e·s.).
La distinction entre protocole et logiciel est cruciale. Si j’utilise le logiciel A parce que je le préfère et vous le logiciel B, tant que les deux logiciels parlent le même protocole, aucun problème, ce sera juste un choix individuel. Malgré leurs différences, notamment d’interface utilisateur, les deux logiciels pourront communiquer. Si, en revanche, chaque logiciel vient avec son propre protocole, il n’y aura pas de communication, comme dans l’exemple du Français et du Japonais plus haut.
Alors, est-ce que tous les logiciels utilisent des protocoles communs, permettant à tout le monde de communiquer avec bonheur ? Non, et ce n’est d’ailleurs pas obligatoire. L’Internet est un réseau à « permission facultative ». Contrairement aux anciennes tentatives de réseaux informatiques qui étaient contrôlés par les opérateurs téléphoniques, et qui décidaient de quels protocoles et quelles applications tourneraient sur leurs réseaux, sur l’Internet, vous pouvez inventer votre propre protocole, écrire les logiciels qui le parlent et les diffuser en espérant avoir du succès. C’est d’ailleurs ainsi qu’a été inventé le Web : Tim Berners-Lee (et Robert Cailliau) n’ont pas eu à demander la permission de qui que ce soit. Ils ont défini le protocole HTTP, ont écrit les applications et leur invention a connu le succès que l’on sait.
Cette liberté d’innovation sans permission est donc une bonne chose. Mais elle a aussi des inconvénients. Si chaque développeur ou développeuse d’applications invente son propre protocole, il n’y aura plus de communication ou, plus précisément, il n’y aura plus d’interopérabilité. Chaque utilisatrice et chaque utilisateur ne pourra plus communiquer qu’avec les gens ayant choisi le même logiciel. Certains services sur l’Internet bénéficient d’une bonne interopérabilité, le courrier électronique, par exemple. D’autres sont au contraire composés d’un ensemble de silos fermés, ne communiquant pas entre eux. C’est par exemple le cas des messageries instantanées. Chaque application a son propre protocole, les personnes utilisant WhatsApp ne peuvent pas échanger avec celles utilisant Telegram, qui ne peuvent pas communiquer avec celles qui préfèrent Signal ou Riot. Alors que l’Internet était conçu pour faciliter la communication, ces silos enferment au contraire leurs utilisateurs et utilisatrices dans un espace clos.
La situation est la même pour les réseaux sociaux commerciaux comme Facebook. Vous ne pouvez communiquer qu’avec les gens qui sont eux-mêmes sur Facebook. Les pratiques de la société qui gère ce réseau sont déplorables, par exemple en matière de captation et d’utilisation des données personnelles mais, quand on suggère aux personnes qui utilisent Facebook de quitter ce silo, la réponse la plus courante est « je ne peux pas, tou·te·s mes ami·e·s y sont, et je ne pourrais plus communiquer avec eux et elles si je partais ». Cet exemple illustre très bien les dangers des protocoles liés à une entreprise et, au contraire, l’importance de l’interopérabilité.

« La tour de Babel », tableau de Pieter Bruegel l’ancien. Domaine public (Google Art Project)
Mais pourquoi existe-t-il plusieurs protocoles pour un même service ? Il y a différentes raisons. Certaines sont d’ordre technique. Je ne les développerai pas ici, ce n’est pas un article technique, mais les protocoles ne sont pas tous équivalents, il y a des raisons techniques objectives qui peuvent faire choisir un protocole plutôt qu’un autre. Et puis deux personnes différentes peuvent estimer qu’en fait deux services ne sont pas réellement identiques et méritent donc des protocoles séparés, même si tout le monde n’est pas d’accord.
Mais il peut aussi y avoir des raisons commerciales : l’entreprise en position dominante n’a aucune envie que des acteurs plus petits la concurrencent, et ne souhaite pas permettre à des nouveaux entrants d’arriver. Elle a donc une forte motivation à n’utiliser qu’un protocole qui lui est propre, que personne d’autre ne connaît.
Enfin, il peut aussi y avoir des raisons plus psychologiques, comme la conviction chez l·e·a créat·eur·rice d’un protocole que son protocole est bien meilleur que les autres.
Un exemple d’un succès récent en termes d’adoption d’un nouveau protocole est donné par le fédivers. Ce terme, contraction de « fédération » et « univers » (et parfois écrit « fédiverse » par anglicisme) regroupe tous les serveurs qui échangent entre eux par le protocole ActvityPub, que l’appel des soixante-neuf organisations mentionne comme exemple. ActivityPub permet d’échanger des messages très divers. Les logiciels Mastodon et Pleroma se servent d’ActivityPub pour envoyer de courts textes, ce qu’on nomme du micro-blogging (ce que fait Twitter). PeerTube utilise ActivityPub pour permettre de voir les nouvelles vidéos et les commenter. WriteFreely fait de même avec les textes que ce logiciel de blog permet de rédiger et diffuser. Et, demain, Mobilizon utilisera ActivityPub pour les informations sur les événements qu’il permettra d’organiser. Il s’agit d’un nouvel exemple de la distinction entre protocole et logiciel. Bien que beaucoup de gens appellent le fédivers « Mastodon », c’est inexact. Mastodon n’est qu’un des logiciels qui permettent l’accès au fédivers.
Le terme d’ActivityPub n’est d’ailleurs pas idéal. Il y a en fait un ensemble de protocoles qui sont nécessaires pour communiquer au sein du fédivers. ActivityPub n’est que l’un d’entre eux, mais il a un peu donné son nom à l’ensemble.
Tous les logiciels de la mouvance des « réseaux sociaux décentralisés » n’utilisent pas ActivityPub. Par exemple, Diaspora ne s’en sert pas et n’est donc pas interopérable avec les autres.
Revenons maintenant l’appel cité au début, Que demande-t-il ? Cet appel réclame que l’interopérabilité soit imposée aux GAFA, ces grosses entreprises capitalistes qui sont en position dominante dans la communication. Tous sont des silos fermés. Aucun moyen de commenter une vidéo YouTube si on a un compte PeerTube, de suivre les messages sur Twitter ou Facebook si on est sur le fédivers. Ces GAFA ne changeront pas spontanément : il faudra les y forcer.
Il ne s’agit que de la communication externe. Cet appel est modéré dans le sens où il ne demande pas aux GAFA de changer leur interface utilisateur, ni leur organisation interne, ni leurs algorithmes de sélection des messages, ni leurs pratiques en matière de gestion des données personnelles. Il s’agit uniquement d’obtenir qu’ils permettent l’interopérabilité avec des services concurrents, de façon à permettre une réelle liberté de choix par les utilisateurs. Un tel ajout est simple à implémenter pour ces entreprises commerciales, qui disposent de fonds abondants et de nombreu·ses-x programmeur·e·s compétent·e·s. Et il « ouvrirait » le champ des possibles. Il s’agit donc de défendre les intérêts des utilisateurs et utilisatrices. (Alors que le gouvernement, dans ses commentaires, n’a cité que les intérêts des GAFA, comme si ceux-ci étaient des espèces menacées qu’il fallait défendre.)
Mais au fait, qui décide des protocoles, qui les crée ? Il n’y a pas de réponse simple à cette question. Il existe plein de protocoles différents et leurs origines sont variées. Parfois, ils sont rédigés, dans un texte qui décrit exactement ce que doivent faire les deux parties. C’est ce que l’on nomme une spécification. Mais parfois il n’y a pas vraiment de spécification, juste quelques vagues idées et un programme qui utilise ce protocole. Ainsi, le protocole BitTorrent, très utilisé pour l’échange de fichiers, et pour lequel il existe une très bonne interopérabilité, avec de nombreux logiciels, n’a pas fait l’objet d’une spécification complète. Rien n’y oblige développeurs et développeuses : l’Internet est « à permission facultative ». Dans de tels cas, celles et ceux qui voudraient créer un programme interopérable devront lire le code source (les instructions écrites par le ou la programmeur·e) ou analyser le trafic qui circule, pour essayer d’en déduire en quoi consiste le protocole (ce qu’on nomme la rétro-ingénierie). C’est évidemment plus long et plus difficile et il est donc très souhaitable, pour l’interopérabilité, qu’il existe une spécification écrite et correcte (il s’agit d’un exercice difficile, ce qui explique que certains protocoles n’en disposent pas).
Parfois, la spécification est adoptée formellement par un organisme dont le rôle est de développer et d’approuver des spécifications. C’est ce qu’on nomme la normalisation. Une spécification ainsi approuvée est une norme. L’intérêt d’une norme par rapport à une spécification ordinaire est qu’elle reflète a priori un consensus assez large d’une partie des acteurs, ce n’est plus un acte unilatéral. Les normes sont donc une bonne chose mais, rien n’étant parfait, leur développement est parfois laborieux et lent.

Écrire des normes correctes et consensuelles peut être laborieux. Codex Bodmer – Frater Rufillus (wohl tätig im Weißenauer Skriptorium) [Public domain]
Toutes les normes ne se valent pas. Certaines sont publiquement disponibles (comme les normes importantes de l’infrastructure de l’Internet, les RFC – Request For Comments), d’autres réservées à ceux qui paient, ou à ceux qui sont membres d’un club fermé. Certaines normes sont développées de manière publique, où tout le monde a accès aux informations, d’autres sont créées derrière des portes soigneusement closes. Lorsque la norme est développée par une organisation ouverte à tous et toutes, selon des procédures publiques, et que le résultat est publiquement disponible, on parle souvent de normes ouvertes. Et, bien sûr, ces normes ouvertes sont préférables pour l’interopérabilité.
L’une des organisations de normalisation ouverte les plus connues est l’IETF (Internet Engineering Task Force, qui produit notamment la majorité des RFC). L’IETF a développé et gère la norme décrivant le protocole HTTP, le premier cité dans cet article. Mais d’autres organisations de normalisation existent comme le W3C (World-Wide Web Consortium) qui est notamment responsable de la norme ActivityPub.
Par exemple, pour le cas des messageries instantanées que j’avais citées, il y a bien une norme, portant le doux nom de XMPP (Extensible Messaging and Presence Protocol). Google l’utilisait, puis l’a abandonnée, jouant plutôt le jeu de la fermeture.
L’interopérabilité n’est évidemment pas une solution magique à tous les problèmes. On l’a dit, l’appel des soixante-neuf organisations est très modéré puisqu’il demande seulement une ouverture à des tiers. Si cette demande se traduisait par une loi obligeant à cette interopérabilité, tout ne serait pas résolu.
D’abord, il existe beaucoup de moyens pour respecter la lettre d’un protocole tout en violant son esprit. On le voit pour le courrier électronique où Gmail, en position dominante, impose régulièrement de nouvelles exigences aux serveurs de messagerie avec lesquels il daigne communiquer. Le courrier électronique repose, contrairement à la messagerie instantanée, sur des normes ouvertes, mais on peut respecter ces normes tout en ajoutant des règles. Ce bras de fer vise à empêcher les serveurs indépendants de communiquer avec Gmail. Si une loi suivant les préconisations de l’appel était adoptée, nul doute que les GAFA tenteraient ce genre de jeu, et qu’il faudrait un mécanisme de suivi de l’application de la loi.
Plus subtil, l’entreprise qui voudrait « tricher » avec les obligations d’interopérabilité peut aussi prétendre vouloir « améliorer » le protocole. On ajoute deux ou trois choses qui n’étaient pas dans la norme et on exerce alors une pression sur les autres organisations pour qu’elles aussi ajoutent ces fonctions. C’est un exercice que les navigateurs web ont beaucoup pratiqué, pour réduire la concurrence.
Jouer avec les normes est d’autant plus facile que certaines normes sont mal écrites, laissant trop de choses dans le vague (et c’est justement le cas d’ActivityPub). Écrire une norme est un exercice difficile. Si on laisse beaucoup de choix aux programmeuses et programmeurs qui créeront les logiciels, il y a des risques de casser l’interopérabilité, suite à des choix trop différents. Mais si on contraint ces programmeuses et programmeurs, en imposant des règles très précises pour tous les détails, on empêche les logiciels d’évoluer en réponse aux changements de l’Internet ou des usages. La normalisation reste donc un art difficile, pour lequel on n’a pas de méthode parfaite.
Voilà, désolé d’avoir été long, mais les concepts de protocole et d’interopérabilité sont peu enseignés, alors qu’ils sont cruciaux pour le fonctionnement de l’Internet et surtout pour la liberté des citoyen·ne·s qui l’utilisent. J’espère les avoir expliqués clairement, et vous avoir convaincu⋅e de l’importance de l’interopérabilité. Pensez à soutenir l’appel des soixante-neuf organisations !
Et si vous voulez d’autres informations sur ce sujet, il y a :
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Kae [CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons](./media/6d31fe15.FilePower_connector_Legrand_32A.jpg){kind=link}
{kind=link}
![Codex Bodmer – Frater Rufillus (wohl tätig im Weißenauer Skriptorium) [Public domain]](./media/b5a58eb0.FileCodex_Bodmer_127_244r_detail_Rufillus.jpg){kind=link}