For nearly two decades, this organization has worked to make the world a more open and equitable place.
When CC first launched in 2001, I was a recently-elected Member of the European Parliament at a time when copyright and access issues were beginning to receive attention.
But throughout my 20 years as a legislator, directly representing over five million people in Scotland and delivering change for over 500 million Europeans, I took on the task of championing digital policy issues including copyright reform, citizen privacy and data protection, and improving public access to digital tools.
As I reflect, we today find ourselves in a very different world. And as I look to the future, I know the work of CC has never been more important.
We have the opportunity to play a leading role in the global fight to remove obstacles to the sharing of knowledge and creativity.
This matters because of the pressing challenges facing us, as the coronavirus pandemic continues to wreak human and economic devastation across the globe.
Inequality is on the rise, and injustices have been exposed.
The tragic killing of George Floyd sparked the global Black Lives Matter movement, while there have been pro-democracy protests in several countries, including in Belarus only last week.
The challenges and the crises we have witnessed during this extraordinary year have raised legitimate questions about power and privilege.
Who has access to knowledge in our unequal society?
We know that too often it is the hands of the few, not the many, and access is often denied to women, people of color, LGBTQI communities and people from the global South.
We have a role to challenge power and privilege, and the solution to that is to open up access and share knowledge.
During the coronavirus crisis, we saw some progress being made.
It’s a shame that it took a global pandemic to realize this, but I hope the lesson has now been learned.
Yet for every step forward there is also a step backwards.
Some nations have imposed restrictions on the right to information and not all have reinstated them.
And too much knowledge remains out of reach, with museum and library doors still shut in many countries, and digital access not available for so many.
Breaking down barriers is not easy.
Take the example of the National Emergency Library, designed by the Internet Archive to make over 1.3 million e-books available for checkout, free of charge during the pandemic.
I have been a longstanding champion of the need to unlock digital access to drive a new era of development, growth, and productivity for everyone in society.
I’m excited by the opportunity to make a difference.
The work of CC has already proved crucial during this devastating pandemic. The Open COVID Pledge has made it easier for universities, companies, and other holders of intellectual property rights to support the development of medicines, test kits, vaccines, and other scientific discoveries.
Last month we introduced the CC Chapter in Italy to you! This month we’re traveling north to the CC Chapter in The Netherlands! TheCreative Commons Global Network (CCGN) consists of 43 CC Country Chapters spread across the globe. They’re the home for a community of advocates, activists, educators, artists, lawyers, and users who share CC’s vision and values. They implement and strengthen open access policies, copyright reform, open education, and open culture in the communities in which they live.
To help showcase their work, we’re excited to continue our blog series and social media initiative: CC Network Fridays. At least one Friday a month, we’ll travel around the world through our blog and on Twitter (using#CCNetworkFridays) to a different CC Chapter, introducing their teams, discussing their work, and celebrating their commitment to open!
Next up is CC Netherlands!
The CC Dutch Chapter was formed in September 2018. Its Chapter Lead is Maarten Zeinstra and its representative to the CC Global Network Council is Lisette Kalshoven. Since the beginning, the Chapter has been involved in promoting and supporting openly licensed music, open GLAM, open education but over the last year, in particular, it has enhanced its activities covering almost allCCGN Platforms. To learn more about their work, we reached out to CC Netherlands to ask a few questions. They responded in both English and Dutch!
CC: What open movement work is your Chapter actively involved in? What would you like to achieve with your work?
CC Netherlands: We like to work together with the whole open sector. Open Licenses are awesome, but even more so when applied to sectors that really benefit knowledge creation and sharing. That’s why we have members from diverse backgrounds. You can see all Open Netherland members here. Are you a person living in the Netherlands? Join us!
CC: Op welke open thema’s is jullie chapter actief? Wat zouden jullie graag willen bereiken?
CC Nederland: Wij werken graag samen met de hele open sector. Open licenties zijn fantastisch, nog meer als ze daadwerkelijk gebruikt worden door de sectoren die kennis creeëren en delen. Daarom hebben we leden van diverse sectoren. Op onze site kun je zien wie er allemaal lid is van Open Nederland. Woon je ook in Nederland! Sluit je dan aan!
CC: What exciting project has your Chapter engaged in recently?
CC Netherlands: We are worried about the implementation of the DSM directive in Dutch copyright law. Exceptions and limitations are paramount in a working copyright system, and automatic filtering threatens those. We have been active in working towards a positive implementation of the new ‘Copyright Directive’ (#DSM) – informing government and parliament on the importance of open knowledge, licenses and broad implementation of exceptions and limitations.
CC: Wat is een project waar jullie chapter recent aan gewerkt heeft?
CC Nederland: Wij maken ons zorgen over de manier waarop de Europese richtlijn voor auteursrechten in Nederland wordt geïmplementeerd. Uitzonderingen en beperkingen op het auteursrecht zijn belangrijk voor een goed werkend stelsel. Automatische filters zijn hier een bedreiging voor. De afgelopen tijd hebben we ons ingezet om de implementatie positief te beïnvloeden, o.a. door de overheid en het parlement te informeren over het belang van open kennis, licenties en een juiste implementatie van de uitzonderingen en beperkingen.
CC: What do you find inspiring and rewarding about your work in the open movement?
CC Netherlands: The Dutch Chapter and @OpenNederland, the association that runs the Chapter, brings people together from all the corners of the open world in NL, open design, healthcare, heritage, education, and more. Thus far this has led to crossovers that did not take place before, like looking at open education from the user experience of a student: what can open education mean for your entire learning path from toddler to adult?
CC: Wat vinden jullie inspirerend en waar halen jullie voldoening uit bij jullie werk in de open beweging?
CC Nederland: Het Nederlandse chapter en Open Nederland, de vereniging die het chapter ondersteund, brengen mensen bij elkaar uit alle hoeken van de open beweging. Bijvoorbeeld open design, gezondheidszorg, erfgoed, onderwijs en meer. Dit heeft al geleid tot kruisbestuivingen die niet eerder plaats hebben gevonden, zoals het bekijken van open onderwijs vanuit het perspectief van een leerling. Wat kan open onderwijs betekenen voor iemands onderwijs carrière, van kleuter tot volwassene?
CC: What projects in your country are using CC licenses that you’d like to highlight?
Dutch GLAMs have been active with open licensing for a long time. Beyond our beautiful Rijksmuseum, also have a look at the Re:VIVE project, which invites artists to remix old archival sounds; @benglabs, which aims to make audiovisual heritage open and searchable; or the beautiful collection of the city archive of Den Bosch, with these billiard playing ladies.
Kenny Vleugels, a game developer from NL, creates really cool CC0 game assets.
We like to party when it is Public Domain Day in the Netherlands. We organise a fun and informative day with lectures about the Public Domain, but also about the creators whose work now entered the Public Domain. See full videos and photos from the 2020 edition here. International coordination takes place through pdday.org.
Did you know the Dutch government uses CC0 as their standard on all text and data on websites? They have been doing so since 2010, and were—as far as we know—the first to do so. See the notice here.
We also have an award for the best re-use of open government data, the Stuiveling Open Data award. The 2019 winners researched fraud in healthcare using open data.
Sharing government news in the current Corona-crisis is more important than ever, but it can be tough to weed through. The Open State Foundation has made all local government news accessible through one platform, all openly licensed.
CC: Wat zijn projecten die CC licenties gebruiken en die je graag onder de aandacht wil brengen?
Nederlandse culturele instellingen delen hun collecties al geruime tijd met open licenties. Naast het welbekende Rijksmuseum zijn er ook initiatieven zoals
Re:VIVE, een project waarbij kunstenaars en muzikanten uitgenodigd worden om geluiden uit archieven te remixen,
@benglabs, dat audiovisuele archieven ontsluit en doorzoekbaar maakt,
Of de fantastische collectie van het archief van Den Bosch, met deze biljartsters.
Kenny Vleugels maakt gave CC0 gelicenseerde game componenten,
We vieren jaarlijks Publiek Domeindag, een leuke en informatieve dag waarbij we aandacht besteden aan de werken die publiek domein zijn geworden en de makers van deze werken. De foto’s en video’s van Publiek Domeindag 2020 zijn hier te zien. Internationale coördinatie van publiek Domeindag vieringen ondersteunen we met pdday.org.
Het delen van nieuws van de overheid is zeer belangrijk in de huidige Corona-crisis, maar het kan lastig zijn om de juiste informatie te vinden. Open State heeft al het nieuws op lokaal niveau op één platform gebundeld, onder een open licentie.
CC: What are your plans for the future?
CC Netherlands: We hope to grow our membership in the coming year, engage more with our community, and do more outward-facing projects.
CC: Wat zijn jullie toekomstplannen?
CC Nederland: We willen nog meer leden aantrekken, onze huidige leden activeren en meer betrekken bij onze werkzaamheden en meer zichtbare projecten doen.
CC: Anything else you want to share?
CC Netherlands: The rise of algorithms determining possible copyright infringement can also have a negative impact on open content, because these algorithms do not take open licensing in account enough. That’s why we’ve started working on “Filter me niet” (Filter me not) in which we look for ways to indicate that you’re purposefully CC licensing to let others remix your work. The first results are in Dutch only, here.
CC: Wat wil je verder nog delen?
CC Nederland: Toenemend gebruik van algoritmes, om potentiële auteursrechtenschendingen te identificeren, heeft negatieve consequenties voor open content. Deze algoritmes houden onvoldoende rekening met open licenties. Daarom zijn we Filter Me Niet begonnen, een project waarin we manieren onderzoeken om actief aan te geven dat je bewust Creative Commons licenties gebruikt om je werk beschikbaar te stellen voor hergebruik. Een eerste resultaat is te zien op www.filtermeniet.nl.
Thank you to theCC Netherlands team, especially Lisette Kalshoven and Sebastiaan ter Burg for contributing to the CC Network Fridays feature, and for all of their work in the open community! To see this conversation on Twitter, click here. To become a member of the CCGN,visit our website!
The wrap-up party for the annual CC Global Summit is always incredible, featuring local artists and musicians who send us off in style. Of course, things are a little different this year as we’ve transformed our in-person event to an entirely virtual one—but that doesn’t mean we can’t find a way to party together like we usually do!
This year, we want to close the CC Global Summit (19-24 October 2020) by celebrating with musical performances showcasing the artistic talent of our global community. We’re looking for musicians, singers, DJs, dancers, or performance artists! Some things to keep in mind:
The performances must be set to CC-licensed music
We’re prioritizing diversity in languages and are actively seeking non-English performances
You can perform in any genre but it must be in line with our Code of Conduct
The deadline to submit your application is Friday, August 28.
If selected, you’ll work with the CC Summit Production team to record a one-song video performance that will be included in our CC Summit Closing Concert. The concert will be pre-recorded and released at the closing of our virtual event and shared afterward on Youtube. Join us!
In the second part of our series on artificial intelligence (AI) and creativity, we get immersed in the fascinating universe of AI in an attempt to determine whether it is capable of creating works eligible for copyright protection. Below, we present two examples of an AI system generating arguably novel content through two different methods: Markov Chains and Artificial Neural Network. We then apply the copyright eligibility criteria explained in “Artificial Intelligence and Creativity: Why We’re Against Copyright Protection for AI-Generated Output” to each example.
Here’s the gist: Through the Jane Austen examples below, it’s clear that the seemingly “creative” choices made by the AI system are not attributable to any causal link between a human and the result, nor is it a human that defines the final form or expression of the work. The randomness elements incorporated in an AI program is what gives the illusion of creativity—and the closer one gets to a semblance of a creative work created by a human, the higher the similarity, thus the lower the originality. All this leads us to conclude that the copyright protection requirements of authorship and originality are not satisfied.
Method 1 – Markov Chains
Suppose you wanted to develop an AI system that could write like English novelist Jane Austen (1775-1817). To do this, one might model writing a sentence as a Markov chain. First discovered by Andrey Markov, a Markov chain is a stochastic model describing a sequence of events where the distribution of possibilities for the next event is dependent only on the current state of the sequence up to that point. These models were first applied to language by Claude Shannon in his groundbreaking paper, A Mathematical Theory of Communication.
An image of the title page from the first edition of Jane Austen’s “Sense and Sensibility (1811)”. This image is in the public domain via the Lilly Library at Indiana University. Access it here.
For example, the word “Mrs.” (capitalized and with punctuation) occurs 2,157 times in the complete works of Jane Austen, and words following “Mrs.” are “Annesley,” “Gardiner,” “F.”, etc. The AI system would then randomly select from the list of words that follow “Mrs.” to get a possible continuation of a sentence starting with “Mrs.” By leaving the repeated elements in the list and selecting from it uniformly at random, a preference for selecting words that occur more frequently after the “seed” (or initial) word is ensured.
Let’s say the AI system randomly selects “Annesley” from the list to follow “Mrs.” This process can then be repeated with the list of words that follow “Annesley.” The word “Annesley” is less common (occurring only two times) and is followed by “to” and “is.” This process can be repeated multiple times to create a growing sentence stub and eventually construct something that resembles a sentence, like:
Mrs. Annesley to it, to be mistress as the room for drawing room to be at the best known intimately judge wisely.
This “sentence” uses real words, which are chosen from Austen’s works, but doesn’t make much sense linguistically or grammatically. In order for the AI system to have more context when choosing words, a standard idea is to try to find words that follow multi-word snippets, rather than single words. In this example, you might look at the list of words that follow the two-word snippet “Mrs. Annesley,” which include “to” and “is.” Note: These are the same words that follow the one-word snippet, “Annesley.”
If you randomly select “to” to follow “Mrs. Annesley,” then you have to find the list of words following the snippet “Annesley to,” and so on. Continuing in this manner, you could construct a sentence like:
Annesley to Miss Thorpe, and then only think! I found that I am sure you would think tall, and on this second interview, such she did not doubt your inclination.
Although this sentence is fragmented, it makes more sense than the previous sentence constructed from one-word snippets. Now let’s look at an example constructed using three-word snippets, starting with “Mrs. Annesley to”:
Mrs. Annesley to Miss Darcy had been standing near enough for her to refuse the correspondence; it was impossible for me not to hear it.
At this level of context, we’re starting to see correct grammar. The sentence almost seems like it could have been written by Austen herself (on a bad day). However, this sentence is completely machine-generated. The longest snippet of words in this sentence that also appear consecutively in Austen’s works is:
…for her to refuse the correspondence; it was impossible for…
However, the context around that snippet is different from Austen’s original work and is actually composed of different sections from several of her works. Here’s an example using four-word snippets, starting with “Mrs. Annesley to Miss”:
Mrs. Annesley to Miss Darcy had been given, to remind her of what anxiety was; but when she saw, on her frequent and minute examination, that every symptom of recovery continued, and saw Marianne at six o’clock sink into a quiet, steady, and to all appearance comfortable, sleep, she silenced every doubt.
In this case, the method is beginning to lose originality. In fact, this sentence is composed of two snippets directly from Austen’s original works:
Mrs. Annesley to Miss Darcy had been given, to remind her of…
…to remind her of what anxiety was; but when she saw, on her frequent and minute examination, that every symptom of recovery continued, and saw Marianne at six o’clock sink into a quiet, steady, and to all appearance comfortable, sleep, she silenced every doubt.
These snippets are stitched together at “to remind her of.” The first snippet is from Austen’s novel Pride and Prejudice and the second is from Sense and Sensibility.
From these examples, it’s clear that expanding the “context” (i.e., the snippet length) increases the probability that the AI system will produce something akin to proper English, but it also decreases the originality of the output. To increase originality, the system requires more text from the original author’s works to be given as input. Even with this simple method, a system can produce fairly realistic English prose. In fact, the actual limit on the quality of content generated by this method turns out to be processing power, computation time, and storage. Also, since the goal is to generate prose only in the style of Jane Austen, the set of possible input text is limited to her works.
The Markov chain described above is just one example of a more general concept called a language model. In technical terms, language models are probability distributions over sequences of words in a language. In our case, we are interested in the probability that a word will occur as the next word, given a sequence of words up to some point. In this model, selecting at random from the probability distribution of possible words following the sequence up to the current point allows us to generate “prose.” As of this writing, one of the most recent large language models is called GPT-3, and was produced by an organization called OpenAI.
Method 2 – Artificial Neural Network
GPT-3 is a considerably more sophisticated model than the Markov chain. In fact, it’s an example of an Artificial Neural Network (ANN). An ANN model is quite complicated, but here’s the gist: it’s a computational model based on the neural networks of the human brain.1 Just as our brains are composed of interconnected processing elements (i.e. neurons) to process information, this artificial system also consists of a neural network that works together to solve a specific problem. Further, just as humans learn when given more information and subsequently change their actions to solve a problem, this artificial system also learns based on its inputs and outputs.
For example, to train an ANN model to predict the next word in a sequence, we make many predictions from different snippets of text per second and use a mathematical process to adjust the ANN model after each incorrect prediction. The adjustments are in the form of slightly changing the values of different numerical parameters in the model. Because the same parameters are used for each snippet, we need many of them to make a general enough model so that we can make predictions based on any arbitrary input sequence. (The large version of GPT-3 has around 175,000,000,000 parameters!) After several iterations of the process above to improve the model, we can generate new text by feeding the model existing text, appending whatever word it predicts next, and finally feeding the result back into the model. In reality, this process is a bit more complicated than described above but the general idea is that it allows us to generate a novel output on each run, rather than the same thing over and over.
Unfortunately, Brent (CC’s data engineer) couldn’t run the large model on his laptop, so he settled for using GPT-3’s predecessor GPT-2, which only has 117,000,000 parameters. The model comes “trained” out of the box, meaning it has already gone through many iterations of the process described above on English text. A user can “fine-tune” the model by performing further iterations on a sample of the English text of their choosing. Here is an example of the output after training the model for around 10 minutes on Jane Austen’s work:
“Yes, I suppose,” replied Emma, “but I do not think she does a great deal of good, of course, I dare say; but if she could, she might, I must say, but she is a great lady at heart, I do not know whether we know that Mr. Elliot is his kindest sister.”
Note that while it’s not making much sense as a story, there are no real grammatical mistakes, and the “voice” does seem to closely echo Jane Austen’s. In general, every AI method for generating novel content, written or otherwise, involves developing a (potentially quite sophisticated) mathematical model that emulates some intelligent behavior. Then, content can be generated by selecting randomly from a probability space defined by that model.
Applying copyright theories to our AI-generated Jane Austen sentences
On a theoretical level, ideas regarding “authorship” and “originality” as we examined them in the first post of this series appear to be at odds with any conception of AI (i.e. non-human) creativity. As we’ve seen in our Jane Austen example, the seemingly “creative” choices made by the AI system are not attributable to any causal link between a human and the result, nor is it a human that defines the final form or expression of the work. Where humans (such as AI programmers or users) are indeed involved in the creation of AI-generated output in the models described above, this involvement is solely mechanical, and not authorial or creative. The randomness elements incorporated in an AI program is what gives the illusion of creativity—and the closer one gets to a semblance of a creative work created by a human, the higher the similarity, thus the lower the originality. All this leads us to conclude that the copyright protection requirements of authorship and originality are not satisfied.
All said, as much as AI has advanced in the past few years, there exists no clarity, let alone consensus, over how to define the nascent and uncharted field of AI technology. Any attempt at regulation is premature, especially through an already over-taxed copyright system that has been commandeered for purposes that extend well beyond its original intended purposes. AI needs to be properly explored and understood before copyright or any intellectual property issues can be properly considered. That’s why AI-generated outputs should be in the public domain, at least pending a clearer understanding of this evolving technology.
Notes
1. In more technical terms, an ANN can be defined as a class of functions that take vectors in from some vector space and map those vectors to a different vector space. Transitions between functions within the class are defined via an operator which is itself a mathematical function. The operator is designed to “train” the ANN model by minimizing some cost function associated with the output.
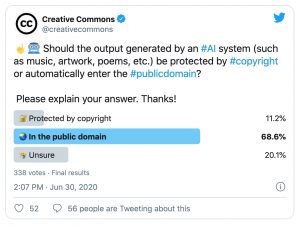
Should novel output (such as music, artworks, poems, etc.) generated by artificial intelligence1 (AI) be protected by copyright? While this question seems straightforward, the answer certainly isn’t. It brings together technical, legal, and philosophical questions regarding “creativity,” and whether machines can be considered “authors” that produce “original” works.
A screenshot of our June 2020 Twitter Poll results.
In search of an answer, we ran an admittedly unscientific Twitter poll over five days in June. Interestingly, almost 70% of a total of 338 respondents indicated that novel outputs from an AI system belong in the public domain, while 20% weren’t sure. For example, one commentator said that “since an AI will (given the same inputs and the same model) produce the same output every time, it’s hard to argue it’s unique and creative,” another succinctly argued: “system-generated activities = no creative input, therefore, no copyright,” while another respondent noted that it “depends on the nature of the AI, and the source materials used…I don’t think you could make a blanket rule for all AI.” This question was also debated at the World Intellectual Property Organization’s (WIPO) Conversation on Intellectual Property and Artificial Intelligence (Second Session) held from 7-9 July 2020. To share our general policy views on this topic from a global perspective, Creative Commons submitted a written statement and made two oral interventions (here and here).
In this blog post, the first in a series on AI and creativity, we explore some of the fundamentals of copyright protection in an attempt to determine whether AI is capable of creating works eligible for copyright protection. In the second blog post, “Artificial Intelligence and Creativity: Can Machines Write Like Jane Austen?“ we walk you through two practical examples of an AI system generating arguably novel content and apply copyright eligibility criteria to them. By doing so, we hope to shed light on some of the copyright issues arising around the nascent field of AI technology.
What works can benefit from copyright protection?
In order to determine what constitutes a creative work eligible for copyright protection, most national copyright regimes rely on the concepts of authorship and originality, among others.
The concept of authorship
For a work to be protected by copyright, there needs to be creative involvement on the part of an “author.” At the international level, the Berne Convention stipulates that “protection shall operate for the benefit of the author” (art 2.6), but doesn’t define “author.” Likewise, in the European Union (EU) copyright law,2 there is no definition of “author” but case-law has established that only human creations are protected.3 This premise is reflected in the national laws of countries of civil law tradition, such as France, Germany, and Spain, which state that works must bear the imprint of the author’s personality. As AI systems do not have a personality that they could imprint on what they produce, authorship is beyond limits for AI.
This “selfie” taken by a Macaca nigra female in 2011 after picking up photographer David Slater’s camera in Indonesia. It was at the heart of the monkey selfie copyright dispute. Access it here.
In countries of common law tradition (Canada, UK, Australia, New Zealand, USA, etc.), copyright law follows the utilitarian theory, according to which incentives and rewards for the creation of works are provided in exchange for access by the public, as a matter of social welfare. Under this theory, personality is not as central to the notion of authorship, suggesting that a door might be left open for non-human authors. However, the 2016 Monkey selfie case in the US determined that there could be no copyright in pictures taken by a monkey, precisely because the pictures were taken without any human intervention. In that same vein, the US Copyright Office considers that works created by animals are not entitled to registration; thus, a work must be authored by a human to be registrable. Though touted by some as a way around the problem, the US work-for-hire doctrine also falls short of providing a solution, for it still requires a human to have been hired to create a work, whose copyright is owned by their employer.
As AI systems do not have a personality that they could imprint on what they produce, authorship is beyond limits for AI.
Nevertheless, some countries (e.g. United Kingdom, Ireland, and New Zealand) do grant copyright-like protection to computer-generated works. The UK Copyright Designs and Patents Act 1988, for example, creates a legal fiction for computer-generated works where there is no human author. Section 9(3) states that “the author shall be taken to be the person by whom the arrangements necessary for the creation of the work are undertaken.” An important nuance is that this provision assumes some form of creative intervention by a human and not autonomous, human-less generation by a computer program alone.
The originality requirement
Common law jurisdictions generally have a low threshold for originality, requiring only a minimal level of creativity or intellectual labor and independent creation for a work to be protectable. The word “originality” in that context refers to the author as being the “origin” of a work, rather than to any creativity standard.4 Some other countries, like Brazil, approach originality from the negative, and state that all works of the (human) mind that do not fall within the list of works that are expressly defined as “unprotected works” can be protected.
Under EU law and case-law, a work is original if it reflects the “author’s own intellectual creation,”5 i.e. the expression of the author’s personal touch and the result of free and creative choices. In short, both EU and US law establish the need for the work to be the proximate (direct) causal result of human action. This implies that AI, as it is currently understood as intelligence completely implemented via computational means, cannot make free and creative choices on its own and that the concept of creativity is not applicable to machines.
Economics of AI-generated outputs: incentives, markets, and monopolies of exploitation
A generative adversarial network portrait painting constructed in 2018 by the collective, Obvious. It was the first artwork created using AI to be auctioned at Christie’s. Access it here.
Leaving aside theories of copyright protection and the rather abstract concepts of authorship and originality (and the even more hypothetical issue of machines having a personality and owning intellectual property rights), the real question we should ask ourselves relates to the economic environment around AI-generated content. Is there any market for AI-generated content? Do people really want to listen to Nirvana-esque algorithm-produced music or Google’s Deep-mind AI piano prowess, get immersed in the writings of a literary robot, or hang a computer-generated Rembrandt, a nightmarish Van Gogh-reminiscent Starry Night or a blurry portrait of a fictional aristocrat in their living room, not to mention to have to pay for any of that? And if so, would AI-generated products truly compete with artistic and literary works produced by humans, as substitute goods? Would the billions of AI-generated outputs produced faster than any human could produce or even consume, need any exclusivity (which is artificially inseminated in the market by means of a copyright “monopoly” of exploitation) to avoid market failure?
Of course, AI-technology developers might expect to be incentivized to invest in innovation, research, and development to help solve the world’s problems and to make AI as useful to society as possible. But copyright protection of the “artistic” outputs by an AI system is not the appropriate mechanism to stimulate this development. Unfair competition and patent law (and to a certain extent, existing copyright law protecting software as literary works) are far better suited to stimulate innovation and ensure a return on investment for the development of AI technology.
AI needs to be properly explored and understood before copyright or any intellectual property issues can be seriously considered.
All said, as much as AI has advanced in the past few years, there exists no clarity, let alone consensus, over how to define the nascent and uncharted field of AI technology. Any attempt at regulation is premature, especially through an already over-taxed copyright system that has been commandeered for purposes that extend well beyond its original intended purposes. AI needs to be properly explored and understood before copyright or any intellectual property issues can be seriously considered. That’s why AI-generated outputs should be in the public domain, at least pending a clearer understanding of this evolving technology.
1. There is as yet no widely accepted definition of “artificial intelligence.” We thus discuss this matter in general terms, and consider, strictly for the sake of discussion, that artificial intelligence is intelligence, or a simulation of intelligence, which is implemented via an automated machine, such as a digital computer.
2. Information Society Directive, 2001/29/EC.
3. Case C-145/10, Eva-Maria Painer v Standard Verlags GmbH 1 December 2011, Court of Justice of the European Union (CJEU).
4. For US case law on the concept of originality, see Alfred Bell & co. v. Catalda Fine Arts, Inc. 191 F2nd, Baltimore Orioles Inc. v. Major League Baseball Players Association, 805 F2nd 663 (7th Cir. 1986) and Feist Publications, Inc. v. Rural Tel. Serv. Co., 499 US 340 (1991).
5. Council Directive 2009/24/EC, Art 1(3), protection of computer programs as “the author’s own intellectual creation”; Database Directive 96/9/EC, Art 3(1); Case C‐5/08, Infopaq, ECLI:EU:C:2009:465; Information Society Directive, 2001/29/EC.
 : Featured image has icons by
: Featured image has icons by