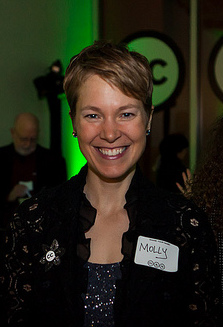The current dominant public policy discourse on the internet and human rights addresses the importance of the these new technologies to empower civil liberties. There is no better example of this than freedom of speech, traditionally mediated by power structures that do not allow it to flourish. Another important stream of this discourse hinges on the security and surveillance debate – massive surveillance through technology due to security needs is one of the most serious challenges we are facing today in the field.
In spite, or perhaps because of this, there is less attention paid to the way those technologies affect or enhance economic, social and cultural rights (ESCR). Being seen as second class rights (or even third class, in some cases), there is a need to start talking about the importance of them to dramatically improve the live conditions of the least advantaged groups within our societies, both in terms of access to infrastructure, educational resources, access to health care, to work conditions, between others.
The 2016 report includes the work of several people within the Creative Commons global community trying to address issues related with trade agreements and ESCR, the right to educational resources and the internet, and the digital protection of traditional knowledge. This report is a key document to better understand the connections between technological advances and social empowering of human rights, particularly where access to knowledge and cultural resources is a key element.
During Fair Use Week organizations and individuals are publishing blog posts, hosting workshops, and sharing educational resources about the implementation and importance of this essential limitation to the rights endowed by copyright. Fair use (and in other countries, the related “fair dealing”) is a flexible legal tool that permits some uses of copyrighted material without permission from the original rights holder, such as for use in news reporting, criticism, teaching, and other reasons.
Fair use and fair dealing are both a part of the larger constellation of limitations and exceptions to copyright. These limitations are a necessary check on the exclusive rights granted to copyright holders, and it’s important to expand and strengthen limitations and exceptions through fundamental copyright reform in order to protect the rights of the public in accessing and using creativity and culture.
We continue to support ongoing efforts to reform copyright law to strengthen users’ rights and expand the public domain. Last year the European Commission, the executive branch of the European Union, introduced its proposal for a Directive on copyright in the Digital Single Market. We’ve been working with Communia and other organisations to support positive changes to the EU copyright regulation, especially in promoting limitations and exceptions to the copyright rules that benefit users’ rights and the public interest.
How well does the Commission’s proposal balance the rights of content creators with the rights of the public? The answer: poorly. There are well-intentioned but flawed proposals for exceptions on digital education and text and data mining. Now the relevant committees are providing feedback and amendments to the original proposal, and the Committee on Culture and Education might be listening to the suggestions from civil society organisations. Its draft opinion suggests the introduction of additional exceptions for User-Generated Content, and Freedom of Panorama. These could help correct some of the imbalance in the Commission’s plan.
But perhaps the most troubling aspect of the proposal is Article 13, the section of the Commission’s legislation that would set up a preemptive copyright filtering mechanism for user contributed content. The Commission proposes that information society service providers (ISSP) that store and give access to copyrighted materials that their users upload must take specific measures to ensure that these materials do not contain other rightsholders’ works. In other words, ISSPs will need to adopt technology that would effectively recognize and prevent uploads of any content that includes even fragments of videos, music, pictures, and any other type of work that belongs to someone other than the person sharing it.
The filter mechanism would apply to all user-uploaded content. It would operate blindly—which means it couldn’t tell the difference between a piece of content being shared improperly and a piece of content being shared under an existing exception to copyright. As Communia wrote last week, upload filters don’t—and can’t—respect user rights:
Upload filters cannot recognize existing freedoms such as the right of quotation or parody. The draft opinion ignores case law of the Court of Justice of the European Union that states that monitoring content is in breach with freedom of expression and privacy.
This type of “shoot first, ask questions later” filtering approach is detrimental to users and could lead to a chilling effect on those who would otherwise attempt to use copyrighted content under an exception to copyright. The Commission’s proposal and the draft opinion of the Committee on Culture and Education suggests that the responsibility should be on users to complain if their content is taken down. This is an unfair burden.
The collateral damage to user rights associated with filtering mechanisms is not a new problem. For years platforms such as YouTube have struggled with how to fulfill their legal obligations to remove protected content posted without the permission of the copyright holder, while at the same time attempting to take into consideration that some uses of works are made under fair use or another exception to copyright.
As we continue the fight for sensible copyright reform in Europe, we know that any EU legislative requirement aimed at addressing the unauthorized use of third-party content needs to fully respect the freedoms enshrined by exceptions and limitations to copyright.
Previously, ESA released individual images under Creative Commons licenses, but this organizational shift marks a substantial change in the way that ESA shares with the world. The choice of CC BY-SA clears ESA’s content for use in larger repositories like Wikipedia (and Wikimedia Commons), as well as by any individual member of the public. It also reaffirms the organization’s commitment to widely sharing open data and imagery across the web.
“This evolution in opening access to ESA’s images, information, and knowledge is an important element of our goal to inform, innovate, interact, and inspire in the Space 4.0 landscape,” said ESA Director General Jan Woerner in the organization’s announcement about the new policy.
Because many ESA images are created in collaboration with partners, this first release under CC BY-SA is limited to content that is completely owned by ESA (or for which any third-party rights have been cleared). The organization plans to release other sets of images under CC BY-SA in future phases of this new Open Access project.
I am thrilled to announce the appointment of two new members of the Creative Commons Board of Directors: Molly Shaffer Van Houweling and Ruth Okediji. In addition, the board has selected Molly Shaffer Van Houweling to serve as Board Chair. Molly is a brilliant and accomplished legal academic with an extensive history with Creative Commons and the open movement. Ruth is a highly esteemed international copyright and intellectual property lawyer, professor, and author. She is also a keynote speaker at this year’s Creative Commons global summit.
Molly was Creative Commons’ first Executive Director from 2001-2002. As one of the key members of the original CC team, she was critical in designing CC’s legal infrastructure and drafting the legal language for Creative Commons copyright licenses. Since then, she has served in various roles on the CC Board of Directors and Advisory Council. She is a Professor of Law and Associate Dean at University of California at Berkeley, School of Law, where she has taught since 2005. Her work in internet and technology policy and copyright is vast, and she has held fellowships at Harvard’s Berkman Center and Stanford’s Center for Internet and Society. She also serves on the board of directors at Author’s Alliance and was an early employee at ICANN. Molly is also one of the fastest women in the world on a bicycle, setting a 2015 World Record by cycling 46.273 km in an hour. She is also a five-time UCI Amateur Road World Champion.
Ruth Okediji is William L. Prosser professor of law at the University of Minnesota. Ruth was also part of the process of negotiating the recently approved Marrakesh treaty; she joined the Nigerian delegation and helped lead the African Group. Her upcoming book, Copyright Law in an Age of Limitations and Exceptions, will be published in March by Cambridge University Press. Professor Okediji is the author of several books on copyright and intellectual property and is regularly cited for her work on IP in developing countries. She is an editor and reviewer of the Journal of World Intellectual Property, and has chaired the Association of American Law Schools Committee on Law and Computers, its Committee on Intellectual Property, and its Nominating Committee for Officers and Members of the Executive Committee.
CC’s outgoing board chair, Paul Brest, will remain on the board for the balance of the year to facilitate the transition for Molly. Our current vice chair Chris Thorne, was reinstated. Paul has been a tremendous board chair, guiding CC through many challenges and new opportunities, and we would like to thank him for his service to the organization. I’m personally grateful for his friendship, guidance and ongoing support.
CC is very excited to welcome Molly and Ruth to the Board of Directors. The accomplishments of these remarkable women as lawyers, academics, and trusted advisors to Creative Commons cannot be overstated. On behalf of the entire CC board, I am thrilled to welcome them in their new roles.
The Institute for Infinitely Small Things addresses the commons through an art for all approach to engage with the political through their work in public spaces. As a research and art praxis group, their work is interdisciplinary and site-specific, yet it draws on data, multimedia, and documentation to concretize their ephemeral performance pieces on the web and beyond.
Over the past thirteen years, the collective has “conducted creative, participatory research to temporarily transform public spaces dominated by non-public agendas,” engaging with “social and political tiny things.” In encouraging interaction with the spaces that surround their installations, the Institute’s work is personal and political and works as a vehicle for local change wherever they find themselves.
Many of the Institute’s projects can be perused on the website of Berlin-based artist Nicole Siggins, who answered questions for this interview, or at their website.
As an artist-run organization concerned with public engagement, what kinds of tactics do you use to encourage participation in your projects?
We perform many of our actions in public view, whether that be on the street in the middle of a busy square, while engaging a classroom, or in an exhibition space. When working in public space we use humor and spectacle to spark curiously in the people around us. This in turn brings people in closer to us, where we can then engage them in the project by asking questions about what they see and perceive, both in the actions we are taking and how it relates to the world and spaces around them. Tactics we have used in the past are wearing lab coats, moving our bodies in unexpected ways, using the landscape in a way that is different from its intended use, creating barriers, getting in the way, and obstructing pathways as a way of encouraging interaction.
A good deal of your work is temporal, yet it is the kind of art that thrives on the internet – videos, remixes, and datasets, like the Corporate Commands dataset. How do you balance site-specific installations with sharing your work online? Do you believe that making your work accessible to a larger audience will encourage its dissemination?
It is important to us that the work continue on its own path once we are finished with it. We are less interested in claiming ownership over the works than we are these works existing on their own to inspire others to engage more consciously and constructively with the world around them. Site specific installations are important because we get to engage with the local public in a space that belongs to them. This is, at heart, the core of the work. However, we truly hope that seeing our work online encourages others to continue to engage with the subject matter long after any site specific installation is over. We do hope that making our work accessible to a larger audience will encourage its dissemination and will encourage people to come up with their own similar ideas or begin their own Institute like groups.
The Institute for Infinitely Small Things – Corporate Commands: Say It With Flowers via EyebeamCC BY-NC 2.0
So many of your installations involve seeking meaning in objects, work, capital, feelings, and politics. How do you bring the personal into the political in your work? How do you conceive of these interventions and installations?
We believe that the personal is the political. Our ideas come from what is going on around us in our political and personal climate. For example, our project “Unmarked Package: A Case for Feeling Insecure” brought us through may different Chicago neighborhoods, setting up a temporary installation of empty boxes which were wrapped in white paper and marked “unmarked package” on all four sides. We then spoke with the residents of each neighborhood about how they would react if they saw an unmarked package and if being super vigilant made them feel safer. This idea emerged from living in a world where we are repeatedly told over intercoms and loudspeakers in train stations and airports to be cautions and to be on the look out for “suspicious behaviour” or “unmarked packages.” Our project was a vehicle to better understand the permeating culture of fear that exists all around us and to engage the public on whether these announcements and behaviors overall made us feel more safe or threatened. Thus, the objects that appear in our works are only a vessel to get the conversation going and to begin a dialogue about what is happening around us in our world.
As a research institute, you came of age during the Bush administration and continued to create work through Occupy and other social movements. How do you see your work changing in scope with the new administration in the US? What’s next for the institute?
There is definitely a lot to talk about with the new administration in the USA. Last spring we ran the Campaign Limericks project, a series of events that analysed the speeches of all the political candidates using DataBasic. The goal of the project was to remix the presidential candidates’ speeches into limericks by finding the most used words in the speeches. It went over well and some of the limericks came out really great! We had events in Boston, Des Moines, and Hartford. Our projects tend to emerge out of community discussion. Right now there is so much going on with the new administration that it is difficult to focus on one topic. However, the ideas of borders, space, and fear have been past topics of our work that only seem more relevant in the current political climate. We hope that we are able to find ways to speak to a greater audience and bring more light to the issues at hand. We want to get people involved and to feel like they are an important piece in changing the world and raising awareness.
What do the commons mean to you? How does your work foster a robust global commons? What do you see as the future of the commons?
In Boston, when we refer to commons, we are often speaking about a physical space, such as the Boston Common. In this sense, our work relates to and promotes interest in the public spaces around us and how they are used. We hope to influence others to take stock of the spaces around them and have a critical view about why things happen as they do. Why are all the streets in Cambridge, Massachusetts named after white men when the current city is so diverse? Why are people harassed and accused of having crossed the border when a border itself is placed right though their previously existing community? Why is it impossible to find something free to to in Harvard Square? The commons and public space should belong to everyone. Our work aims to help people think about and realize that in their own lives.
As for the more abstract commons (information, ideas and concepts that are free for anyone to use) the Institute works to involve everyone in the art we perform. We strive to show that art and research is the commons – it’s accessible to everyone! Making art and using performative research to get people thinking and talking helps bring people together to have important conversations about what is going on in our communities. Sharing our art and ideas on the Internet further spreads the invitation to the wider world. In this way, we use the commons in both senses to invite people to begin to have these important conversations.
 The current dominant public policy discourse on the internet and human rights addresses the importance of the these new technologies to empower civil liberties. There is no better example of this than freedom of speech, traditionally mediated by power structures that do not allow it to flourish. Another important stream of this discourse hinges on the security and surveillance debate – massive surveillance through technology due to security needs is one of the most serious challenges we are facing today in the field.
The current dominant public policy discourse on the internet and human rights addresses the importance of the these new technologies to empower civil liberties. There is no better example of this than freedom of speech, traditionally mediated by power structures that do not allow it to flourish. Another important stream of this discourse hinges on the security and surveillance debate – massive surveillance through technology due to security needs is one of the most serious challenges we are facing today in the field.