Je voulais me lancer sur un seul tuto expliquant comment créer un petit projet mais plus j’avançais plus il y en avait à dire, aussi ai je scindé mon tuto en trois partie histoire de rendre la rédaction, comme la lecture, plus digeste.
Dans cette partie, nous allons apprendre à créer un serveur http “fonctionnel” avec nodejs et à publier un dossier web à travers ce serveur.
Si je précise “fonctionnel” c’est que, bien que notre serveur soit bien plus aboutis que les tutos de découverte
précédents, il lui manquera encore beaucoup de notions déjà existante dans les serveurs http existants.
En effet le but n’est pas de recréer un serveur http pour nodejs (nous verrons plus tard qu’il en existe déjà des tout fait parfaitement convenables comme express) mais de comprendre la logique de fonctionnement “basique” d’un serveur http tout en s’initiant à la technologie nodejs.
Notre fil conducteur sera un petit projet web qui permettra “d’échanger” du texte, des fichiers, des liens etc… entre membres d’un même groupe de travail.
Comme je suis un type sympa, je fournirais toute la partie ennuyeuse qui ne nous intéresse pas, à savoir la création et l’intégration de l’interface graphique.
Vous pouvez trouver cette interface ICI.
Bien, nous avons notre dossier web, créons maintenant un serveur qui tiens la route !! 
La structure du projet
Commençons par créer notre dossier projet :
Notre projet vas s’appeler hi! (c’est plus court que hello world) et vas se diviser en deux parties : le serveur http à proprement parler et le dossier de publication www dans lequel vas se trouver notre site web

Tout le code serveur sera donc placé dans server.js, conf.json permettra de stocker les constantes de configuration de ce dernier, 404.html sera un exemple d’erreur http, et le contenu du dossier www sera notre projet web (que je vous ai fournis ci dessus).
On retrouve les dossiers habituel d’un site web : css qui contiendra les fichiers de styles css, font qui contiendra les polices (ben oui on vas pas bosser en arial on a quand même plus de classe que ça) un dossier img pour (taddaaaa) les images !! Un dossier js pour le javascript. blablablah!!
Je ne m’étendrais pas sur le squelette en question, je part du principe que vous avez déjà des notions de javascript/css/html/ajax bref le b.a.-ba du site web, le but étant ici de nous concentrer sur nodejs.
La création du serveur
Nous allons créer un “équivalent” d’apache/lighttpd/nginx ou autre en plus light évidemment) que nous avons évoqué en tuto #1 (d’ailleurs j’en profiterais pour donner la réponse à l’énigme de l’image in-affichable  )
)
On vas commencer par le serveur, ouvrons la page server.js et créons notre serveur http comme nous l’avons vu en tuto 1 avec tout de même quelques améliorations
Inclusion de la librairie http permettant de créer un serveur web
http = require('http');Récupération de la librairie url qui facilite l’analyse de l’url des requêtes reçues
url = require('url');Récupération de la librairie fs qui permet la gestion de fichiers (écriture, lecture…)
fs = require('fs');Création d’un serveur http sur un port pris totalement au hasard, le 69.
var httpServer = http.createServer(onRequest);
httpServer.listen(69);
On ne prends pas le port 80 pour une raison pratique : il est souvent déjà pris pas un wamp, un apache ou n’importe quoi d’autre qui tourne sur votre machine.
Dès qu’une requête est reçu sur 127.0.0.1:69, la fonction onRequest (que nous allons écrire) est exécutée et prends pour paramètres un objet requête (ce qui est reçu) et un objet réponse (ce que le serveur vas retourner).
Écrivons maintenant la fonction onRequest qui vas faire tout le boulot de traitement du serveur :
function onRequest(request, response) {On récupère l’url requise et on la parse pour n’avoir que la partie qui nous intéresse
var pathname = url.parse(request.url).pathname;
On récupère l’extension du fichier requis (html,css,js,jpg…)
var extension = pathname.split('.').pop();Si l’utilisateur ne spécifie pas de page dans la barre d’adresse, on prend l’index par défaut :’index.html’
if(pathname=='/') pathname = "index.html";
On définis l’entête de réponse au code 200 signifiant : “succès de la requête” et on vas également définir le type mime du fichier de retour (image/jpg pour un jpg, text/css pour un css etc..)
En effet c’est pour cette raison que notre image ne s’affichait pas en tutos 1, car nous tentions de la retourner au format text/hml, chaque fichier publié par notre serveur doit impérativement signaler
son type de contenu au client (le navigateur) sans quoi celui ci sera mal interprété.
On vas donc créer un petit tableau json contenant quelques types mimes que nous allons utiliser :
var mime = {
"css" : "text/css",
"gif" : "image/gif",
"jpg" : "image/jpeg",
"jpeg": "image/jpeg",
"js" : "application/javascript",
"ttf" : "font/ttf",
"png" : "image/png"
}On retournera donc le bon type mime en fonction de l’extension du fichier, ainsi qu’un code d’en-tête “200″ signifiant que la requête s’est déroulée sans erreur :).
response.writeHead(200, {'Content-Type': mime[extension]});
try {On tente de lire le contenu du fichier demandé (en ajoutant la racine du dossier client : “www” ) et on le retourne à l’utilisateur
response.end(fs.readFileSync("./www/" + pathname));
}catch(e){Si la lecture du fichier à échouée on renvoie un code d’erreur 404
response.writeHead(404, {'Content-Type': 'text/html'});on affiche le contenu de la page 404.html
response.end(fs.readFileSync('404.html'));
}
}Notre serveur est terminé, nous pouvons dès à présent le lancer!!
Hey mais t’oublis la ptite page 404 que tu appelle en cas d’erreur!!
C’était pour voir si vous suiviez ! 
Donc on vas se créer une petite page 404.html au même niveau que le fichier server.js (inutile de la mettre dans le dossier www, c’est une page utilisée par le serveur) :
404.html
<h1>Erreur 404 - Fichier non trouvé</h1>
<p>Pas de bol, réessayez sans les moufles :D</p>
On fait sobre sur ce coup la, parce qu’on s’en fou un peu de la 404 et qu’on veux tester notre serveur :p.
Nous voila enfin avec un serveur opérationnel !
Attends la tu ne vas pas nous laisser avec toutes ces constantes dégueulasses en dur dans le code ?!!!
Okay okay, on vas faire un ptit fichier de config pour stoker tout ça :p, mais c’est vraiment parce que c’est vous (et parce que c’est hyper simple à faire en node :p)
On créé un fichier conf.json au même niveau que “server.js”, dans ce fichier on vas mettre les constantes (numéro de port du serveur, types mimes etc…) au format json :
conf.json
{
"http" : {
"index": "index.html",
"port": 69,
"www": "./www/",
"mime": {
"css" : "text/css",
"gif" : "image/gif",
"jpg" : "image/jpeg",
"jpeg": "image/jpeg",
"js" : "application/javascript",
"ttf" : "font/ttf",
"png" : "image/png"
},
"error" : {
"404" : "404.html"
}
}
}Et maintenant on vas inclure ce fichier de conf dans notre server.js le plus simplement du monde :
conf = require('./conf.json');on peut alors se servir de notre objet json de conf dans l’ensemble du serveur :
//Récupération de nos configuration personnalisées
conf = require('./conf.json');
//Inclusion de la librairie http permettant de créer un serveur web
http = require('http');
//Récupération de la librairie url qui facilite l'analyse de l'url des requêtes reçues
url = require('url');
//Récupération de la librairie fs qui permet la gestion de fichiers (écriture, lecture...)
fs = require('fs');
//Création d'un serveur http sur le port spécifié dans conf.json (section http)
//Dès qu'une requête est reçu sur 127.0.0.1:port, la fonction onRequest est exécutée
//et prends pour paramètre un objet requête (ce qui est reçu) et un objet réponse (ce que le serveur vas retourner)
var httpServer = http.createServer(onRequest).listen(conf.http.port);
//Fonction onRequest est exécutée à chaque requête sur le serveur
function onRequest(request, response) {
//On récupère l'url requise et on la parse pour n'avoir que la partie qui nous intéresse
var pathname = url.parse(request.url).pathname;
//On récupère l'extension du fichier requis (html,css,js,jpg...)
var extension = pathname.split('.').pop();
//Si l'utilisateur ne spécifie pas de page, on prend l'index par défaut 'index.html' (spécifié dans conf.json)
if(pathname=='/') pathname = conf.http.index;
//On définis l’entête de réponse au code 200 signifiant : "succès de la requete" et
//on définit le type mime du fichier de retour (image/jpg pour un jpg, text/css pour un css etc..)
//Les types mimes sont définit dans le fichier json conf.
response.writeHead(200, {'Content-Type': conf.http.mime[extension]});
try {
//On lit le contenu du fichier demandé (en ajoutant la racine www spécifiée dans conf.json)
//et on le retour a l'utilisateur
response.end(fs.readFileSync(conf.http.www + pathname));
}catch(e){
//Si la lecture du fichier à échouée on renvoie un code d'erreur 404
response.writeHead(404, {'Content-Type': 'text/html'});
//on affiche le contenu de la page 404.html (chemin spécifiée dans conf.json)
response.end(e+fs.readFileSync(conf.http.error['404']));
}
}Les tests
On peut enfin tester notre serveur, ouvrons une console de commande et tapons :
cd /chemin/vers/notre/dossier/hi
node server.js
(nb: sous windows vous devrez d’abord taper la lettre du lecteur ou se trouve votre dossier hi, si votre dossier se trouve sur d:\dev\hi! il vous faudra taper “d:” puis cd d:\dev\hi! et enfin node server.js).
nb2: Si vous avez un pare-feu, il est possible que celui ci vous demande si vous voulez débloquer le serveur que vous venez de lancer, vous devez évidemment répondre oui.
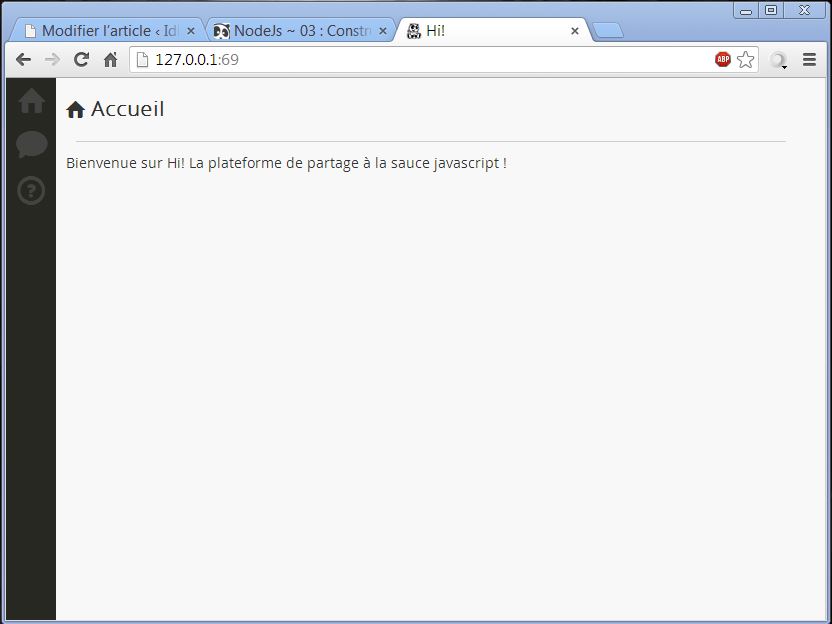
Si tout se passe bien la console ne devrait pas être très bavarde, elle se contentera de faire un saut de ligne mais votre serveur sera bien actif, ouvrez un navigateur et tapez l’adresse :
http://127.0.0.1:69
Et tattaaa! Vous arrivez sur notre magnifique squelette de site web avec le css et les images correctement chargées.
Pour stopper le serveur vous pouvez fermer la console ou appuyer sur ctrl+C deux fois (du moins sous Windows, sous linux je ne sais pas).
Pour ceux qui ont loupés un épisode voila les sources complètes ICI
Les améliorations
C’en est finit pour ce tuto, notez bien que nous n’avons fait que parcourir la surface du fonctionnement d’un serveur web, il manque de nombreuses améliorations à apporter, notamment des notions de sécurité et de nombreuses fonctionnalités “classiques” :
- Gestion des htaccess
- Gestion de toutes les erreurs http (500,403…, ici nous renvoyons la 404 pour tous type d’erreur ce qui est incorrect)
- Gestion de l’url rewritting
- Gestion des virtual host
Etc..etc… et le plus important : gestion des préprocesseurs, en effet nous retournons la sources de chaque fichier sans la traiter auparavant, ce qui rend impossible l’inclusion de code exécuter coté serveur directement sur nos pages du dossier www.
Ce qui pour le coup nous oblige à mélanger du code applicatif et du code serveur dans le même fichier, ce n’est évidemment pas l’idéal.
Nous pourrions développer cette partie, il suffit de créer une fonction qui traite la source avant de la retourner et qui utilise les expression régulière pour exécuter le code entre <?js et ?> coté serveur par exemple :), mais ça prendrais un temps monstrueux pour très
peu d’intérêt, d’autant qu’il existe déjà de nombreuses librairies qui s’en chargent, pour cette série de tutos nous nous cantonnerons donc à notre serveur de fortune :), pour les vrai site de production, on verra ensemble comment installer express et deux trois autres librairies indispensables.




