Sécurité des webapps : Le cas des fichiers de Backup
vendredi 27 mars 2020 à 09:00I. Présentation
La gestion d'un serveur web ou d'un site web nécessite couramment des opérations de modification et d'amélioration du code, parfois directement sur le serveur de production, ces manipulations peuvent toutefois faire naître des failles de sécurité importantes dont il est important d'être informé.
Nous allons ici étudier le cas des fichiers de sauvegarde et de leur présence dans les arborescences web. Nous verrons comment ceux-ci peuvent se créer, parfois de façon automatique et quels problèmes de sécurité ils posent.
II. Extension .swp .bak .old... tout sauf du PHP
Dans le domaine des applications web, on peut couramment retrouver deux types de fichiers de sauvegarde :
- Les fichiers créés automatiquement
- Les fichiers créés manuellement
Il faut tout d'abord savoir comment ces fichiers se retrouvent dans une arborescence web, et comment ils deviennent consultables depuis un simple navigateur web.
A. Les fichiers de sauvegarde générés automatiquement
Pour les fichier créés automatiquement, ils apparaissent notamment lorsque l'on édite un fichier. C'est le cas de certains éditeurs comme "vi" ou "vim" qui en créent dans "swap file" dès qu'un fichier est édité et que ces modifications ne sont pas sauvegardées.
Pour exemple, dans mon répertoire web /var/www/html, je possède un fichier "index.php". Son code source n'est donc pas visible par le public consultant mon site web. Afin d'améliorer ou de modifier mon index.php, je l'édite avec vim et commence à écrire à l'intérieur, dès lors, un fichier .index.php.swp va se créer dans mon arborescence de fichier :
drwxr-xr-x 2 www-data www-data 4096 juin 13 14:46 . drwxr-xr-x 3 root root 4096 juin 10 09:50 .. -rw-r--r-- 1 www-data www-data 75 juin 13 12:34 .htaccess -rw-r--r-- 1 www-data www-data 11104 juin 10 09:50 index.html -rw-r--r-- 1 www-data www-data 46 juin 13 14:46 index.php -rw-r--r-- 1 root root 12288 juin 13 14:47 .index.php.swp
Ici, j'édite mon fichier en tant que root, vous pouvez néanmoins voir que tout le monde pourra quand même lire mon fichier "-rw-r--r--". Si j'accède à ce fichier via un navigateur web :
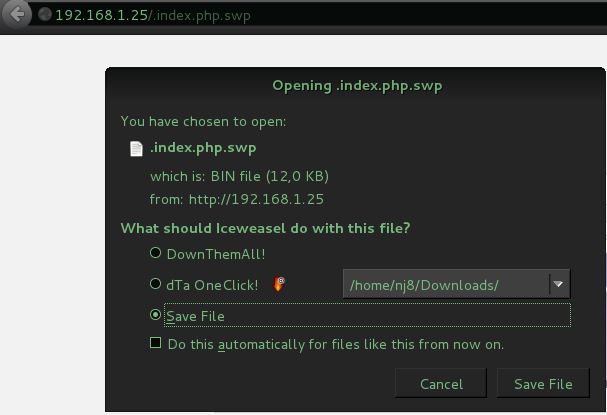
En effet, étant donné que le fichier que je demande à mon serveur web ne comporte pas l'extension d'un fichier exécutable par le serveur tel que .php, il va le traiter comme un fichier .txt, une image ou un autre document et me proposer de le télécharger, une fois téléchargé, voici son contenu :
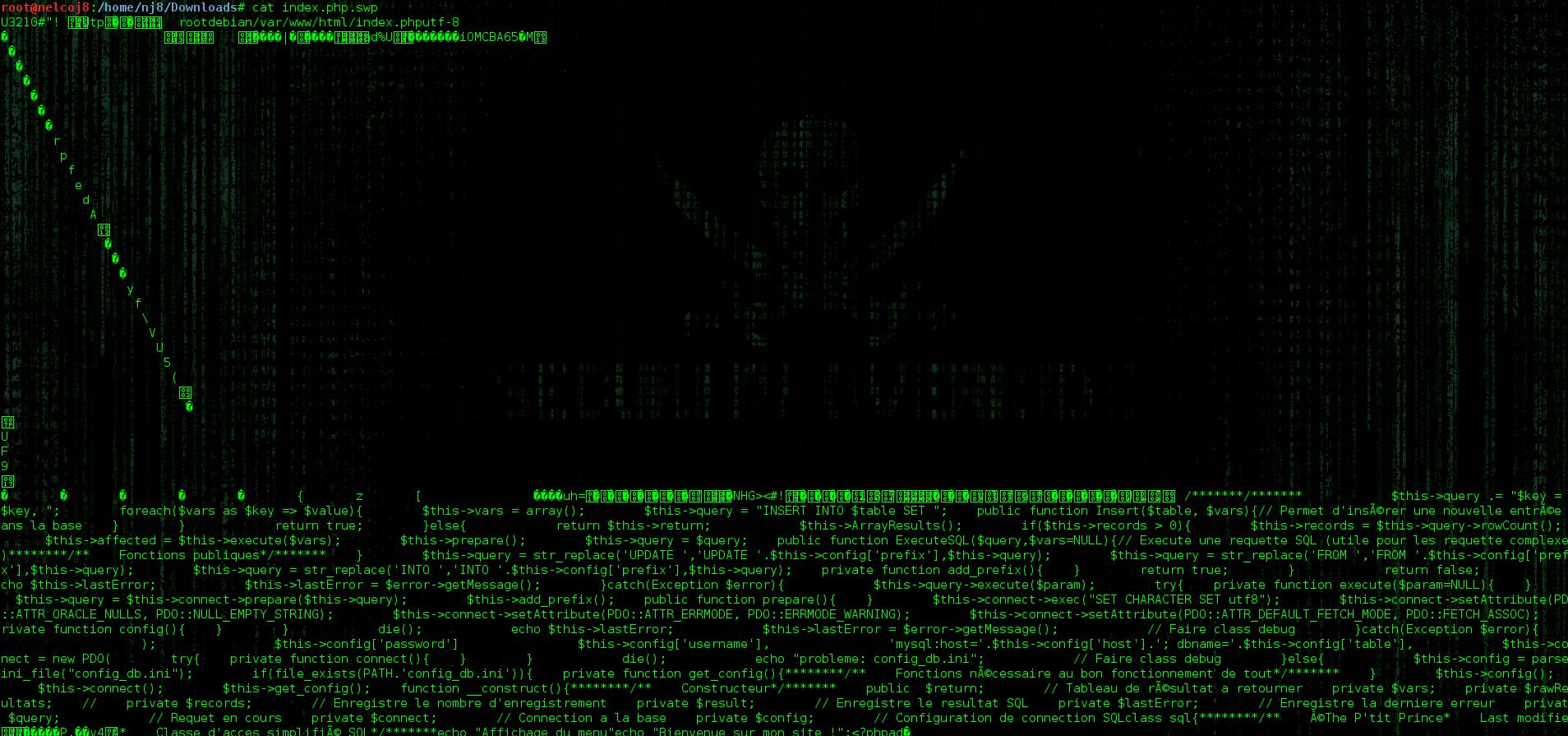
Ici, et pour détailler un peu ce qui est affiché, il s'agit de tous les caractères et lignes de code que j'ai ajouté dans mon fichier index.php depuis que je l'ai ouvert avec vim.
Techniquement, les fichiers .SWP ou "vi Swap File" sont des fichiers créés par vi (ou ses variantes, vim, gvim,etc.), ils stockent une version temporaire du fichier édité. Cela permet par exemple à un autre programme d'ouvrir le même fichier sans entrer en conflit avec vim. Dès qu'un fichier est édité par vim, la copie en .swp de ce fichier est créée dans le répertoire courant et avec les droits de l'utilisateur exécutant vim. Par exemple, si le fichier "login.php" est ouvert avec vim, puis que l'on commence à l'éditer (à changer son contenu), un fichier .login.php.swp va alors être créé. Une autre raison légitime de ce mode de fonctionnement est le fait qu'en cas de crash ou de fermeture du programme vim (exemple avec un "kill -9"), le fichier .swp va permettre de reprendre l'édition au moment du crash en utilisant l'option "Recover" de vim, on pourra d'ailleurs avoir le message "Swap file .login.php.swp already exists".
Il faut noter que lorsque le fichier est finalement sauvegardé, son swap file au format .swp est supprimé. Toutefois, lorsque le fichier est quitté de manière non standard (exemple, coupure SSH lors de l'édition via une connexion SSH, extinction brute, kill -9...), le fichier .swp n'est alors pas supprimé et son existence persiste jusqu'à une suppression manuelle.
Outre vim, d'autres programmes ont le même comportement sur différentes plate-formes, c'est le cas d'emacs par exemple, qui créé automatiquement une version backup des fichiers édités dans certains cas d'édition.
B. Les fichiers de sauvegarde générés manuellement
Les cas les plus courant concernent les fichiers de sauvegarde créés manuellement, et bien souvent oubliés dans l'arborescence web. Il est (très) courant, avant de devoir éditer des fichiers, d'en créer des sauvegardes par sécurité. Une habitude répandue consiste à exécuter cette simple commande :
cp fichieramodifier.php fichieramodifier.php.bak
Ou encore :
cp fichieramodifier.php fichieramodifier.php.old
En soit, cela est une excellente habitude, car on peut alors revenir rapidement à une version d'origine du fichier en cas de mauvaise manipulation, d'erreur de code, etc. Cependant, ces fichiers se retrouvent dans l'arborescence web et sont alors consultables pour n'importe quel visiteur. On se retrouve alors également avec la possibilité de les télécharger pour en visionner le contenu, simplement en allant avec un navigateur sur l'URL http://monsite/fichieramodifier.php.bak
Également, on peut être amené à vouloir sauvegarder l'intégralité d'un site web ou d'un répertoire dans une archive, par exemple une archive au format .tar.gz ou .zip, par manque de prudence, ces archives se retrouvent elles aussi dans l'arborescence web et sont alors directement téléchargeables depuis un navigateur.
Les backups de base de données, par exemple dans des fichiers .sql sont aussi très pratiques pour effectuer rapidement des sauvegardes d'une application web, également, ces fichiers peuvent se retrouver dans bien des cas dans l'arborescence web, voire directement indexés sur des moteurs de recherche.
C. Les répertoires de backups
Une bonne habitude à prendre en tant que sysadmin ou webmaster est le versionning et le stockage des sauvegardes faites. Toutefois, il faut absolument éviter de stocker ces répertoires à l'intérieur même du répertoire web de l'application ou du serveur web. Il est aujourd'hui courant de trouver des accès sur des URLs du type :
- site.demo/old
- site.demo/backups
- site.demo/save
Bien que cette habitude soit une bonne chose, entreposer les backups d'une application web ou d'une base de données à l'intérieur même de celle-ci est très dangereux car ces répertoires, s'ils ne sont pas protégés, peuvent alors être consultés librement depuis un navigateur web.
Dans les cas les plus courants, on oublie de vérifier la présence de ces fichiers et de les supprimer, dans les cas plus spécifiques, ils sont accessibles via une mauvaise gestion des droits ou des failles LFI (Local File Inclusion).
III. L'accès au code source, un problème ?
Nous avons vu que ces fichiers pouvaient être créés de façon automatique ou de façon manuelle et également que leur présence dans l'arborescence web peut être beaucoup moins temporaire que prévue. Mais en quoi ces fichiers posent-ils un problème de sécurité ?
En soit, l'accès au code source d'un fichier HTML est la condition même du bon fonctionnement d'un serveur web. Lorsqu'une requête est faite à un serveur, le code HTML est envoyé dans son intégralité au client pour que son navigateur lui affiche correctement les images, couleurs et textes transmis. Néanmoins, le code PHP est lui un code exécuté du côté du serveur "server side code" est n'a aucunement pour vocation d'être lu par les visiteurs d'un site web ou par les navigateurs.
Pour rappel, lorsqu'un client demande l'affichage d'une page web en allant par exemple sur "http://site.demo/index.php", le serveur exécute le script "index.php" qui va alors générer dynamiquement un code HTML, c'est ce code HTML qui sera renvoyé au client, et non le code PHP. C'est pour cette raison que le code PHP est un code côté serveur, car c'est le serveur qui le lit et l'exécute :
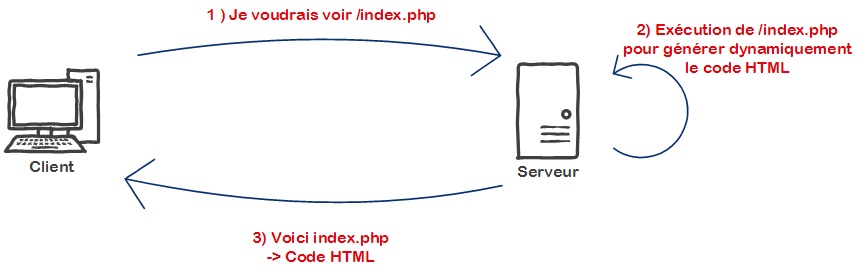 Si un client arrive à télécharger le code PHP, comme dans les contextes vus plus haut, cela peut être relativement dangereux :
Si un client arrive à télécharger le code PHP, comme dans les contextes vus plus haut, cela peut être relativement dangereux :
- La lecture du code PHP peut donner accès à des informations comme des noms de variables, des chemins d'accès aux fichiers, des noms de répertoire
- La lecture du code PHP peut permettre une analyse du code, beaucoup plus efficace en terme de recherche de vulnérabilité que celle faite dans la position du client web
- Cela peut également permettre de voir les commentaires PHP insérés dans le script PHP, avec toutes les informations qu'ils peuvent contenir
- Plus rarement, et même si cela est hautement déconseillé, on pourra parfois retrouver des informations telles que des noms d'utilisateurs ou mots de passe directement dans le code PHP ou dans les commentaires.
On comprend alors mieux pourquoi ce code PHP n'a absolument par pour vocation d'être vu par les visiteurs d'un site web, il fait partie du "backoffice" dans le fonctionnement du serveur web et peut contenir des informations sensibles.
IV. Quelques outils offensifs
Bien souvent lors de l'audit d'un site web et d'un test d'intrusion, personne se mettant dans la peau de l'attaquant va effectuer la recherche des fichiers de backups de façon manuelle. En effet, la création d'un fichier XXXXXX.php.bak n'est pas une norme et est loin d'être systématique comme pourrait l'être la présence d'un "install.php" à la racine d'une application web.
Cependant, différents outils permettent d'automatiser leur détection, on retrouve par exemple l'utilisation des Googles Dorks, très efficace lorsque ces fichiers de sauvegarde se retrouvent indexés. Par exemple, l'utilisation des directives "inurl:.php.bak" ou "filetype:bak OR filetype:old" permet de retrouver les fichiers de sauvegarde oubliés d'un serveur web.
Il faut toutefois noter que bien que ces fichiers traînent souvent dans les serveurs web, ceux-ci ne sont pas systématiquement indexés par les moteurs de recherche, c'est le cas des applications web internes par exemple.
On peut également facilement construire un outils qui, pour chaque URL trouvée et renvoyant un code 200 sur une application web (exemple : index.php), va tester l'équivalence avec des syntaxes propres aux fichiers de sauvegarde :
- index.php.bak
- index.bak
- index.php.old
- index.old
- .index.php.swp
- etc.
V. Les protections à mettre en place, techniques et humaines
Afin de protéger les serveurs et applications web des extractions d'informations vues précédemment, plusieurs systèmes peuvent être mis en place :
A. Interdire les extensions de "backup"
Commençons par les protections techniques, lorsqu'il est nécessaire d'effectuer un fichier de backup temporaire, on peut observer une certaine logique générale qui est de mettre ces fichiers en .bak ou .old. Libre à vous d'utiliser d'autres syntaxes comme .save, .backup ou .nimportequoi. la logique de protection restera la même du moment que vous adaptez la méthode de protection à vos habitudes.
Sous Apache, il est possible de mettre en place une restriction par .htaccess qui va permettre d'interdire toute lecture de certaines extensions de fichier. On peut alors se permettre de dire au serveur web "Refuse l'accès à toutes les ressources ayant comme extension .bak". Bien entendu, on peu remplacer .bak par ce que l'on souhaite. Il faut néanmoins, dans votre équipe de travail, normaliser le fait que les fichiers de backup temporaires seront .bak et pas .baks, .old ou .backup.
Pour mettre en place une telle protection avec un .htaccess sous Apache2, on peut utiliser la syntaxe suivante :
<Files ".bak"> Order Allow,Deny Allow from none Deny from all </Files>
Ainsi, dès que l'on souhaitera avoir accès à un fichier ayant comme extension ".bak", on aura une interdiction de la part du serveur (code d'erreur HTTP 403) :
 Je vous conseille alors de mettre un ensemble de règles comme celle-ci dans vos .htaccess couvrant la plupart des extensions vues ici (.bak, .swp, .old...), la règle ressemblera alors à cela :
Je vous conseille alors de mettre un ensemble de règles comme celle-ci dans vos .htaccess couvrant la plupart des extensions vues ici (.bak, .swp, .old...), la règle ressemblera alors à cela :
<Files ~"\.(bak|swp|old|sql|zip)$"> Order Allow,Deny Allow from none Deny from all </files>
Si vous avez un serveur web tournant sous Nginx, voici la configuration correspondante , à mettre dans le fichier de votre vhost :
location ~\.(bak|old|swp|sql|zip)$ {
return 403;
}
Libre à vous d'y ajouter les extensions souhaitées ou non. Le ".zip" par exemple peut être utile dans un contexte normal, si l'on met à disposition des utilisateurs des archives téléchargeables. Encore plus sécurisé, mais beaucoup plus restrictif, on peut tout simplement n'autoriser aucune extension, sauf celles spécifiées. On abandonne alors le mode "Liste noire" dans laquelle tout est autorisé sauf ce qui est explicitement interdit, au profit du mode "Liste blanche" dans laquelle tout est interdit sauf ce qui est explicitement autorisé. Dans le cadre d'Apache2 avec un .htaccess, cela donnera les règles suivantes :
// On interdit toutes les extensions
<Files ~ "\..*$"> Order Allow,Deny Allow from none Deny from all </Files>
// On autorise seulement ce qui est légitime, image, php, html ... <Files ~ "\.(html|php)$"> Order Deny,Allow Deny from none Allow from all </Files>
Cette dernière méthode est beaucoup moins simple à gérer mais évite les mauvaises surprises. On peut déjà penser à ajouter les extensions d'images pour avoir un site exploitable...
B. Partir à la chasse des extensions de backup
Une seconde opération qui pourrait être mise en place pourrait être le fait de faire tourner un script régulièrement sur l'arborescence web d'un serveur web. Ce script pourra alors partir à la recherche d'extension de backup comme les fichiers en .bak ou .old pour ensuite envoyer un mail à l'administrateur du serveur si de telles extensions sont trouvées. Ce genre de script peut être développé très rapidement en bash et améliorera à coup sûr la sécurité de vos serveurs web, un exemple de script que vous pouvez utiliser, je l'ai rédigé pour l'article, il peut donc certainement être amélioré :
#!/bin/bash
# Script to find backup extension files in web directory
# Create tmp file for output storage
TEMP=$(mktemp)
# Admin mail
AdmMail="foo@bar.test"
# Path to web directory
WebDir="/var/www/ogma-sec.fr"
# Bad extensions to find, please keep the regexp syntax
BadExtension=".*\.\(bak\|swp\|old\)$"
find $WebDir -regex $BadExtension > ${TEMP}
# If tmp file is not empty, send its content to admin
if [[ -s ${TEMP} ]] ; then
cat ${TEMP} | mail -s "Bad Extension finded ${hostname}" $AdmMail
fi ;
# Delete tmp file
rm ${TEMP}
Il suffira alors de configurer un crontab pour que ce script soit exécuté tous les jours par exemple.
C. Le cas de vim
Nous avons vu que vim créait pour des raisons plus que légitime des "Swap Files" au format .swp qui pouvaient être téléchargés pour obtenir le code source d'un script PHP par exemple. Vim étant un outil très puissant, nous pouvons résoudre ce problème de plusieurs façons.
On peut tout d'abord commencer par demander à vim de ne plus produire de fichier swap en ajoutant la directive suivante dans la configuration de vim (/etc/vimrc ou /etc/vim/vimrc) :
set noswapfile
Si ces fichiers ont toujours un intérêt pour vous, il suffit de demander à vim de ne plus le stocker dans le répertoire courant mais plutôt dans un répertoire à part, loin de l'arborescence web et de vos applications web, par exemple dans /srv :
mkdir /srv/vim_swpfile
On va ensuite modifier le fichier de configuration de vim (/etc/vimrc ou /etc/vim/vimrc) pour y ajouter les options suivantes :
set backupdir=/srv/vim_swpfile set directory=/srv/vim_swpfile set undodir=/srv/vim_swpfile
À présent, les fichiers temporaires tels que les swap ne seront plus créés dans le répertoire courant mais dans un répertoire fixe, celui spécifié dans la configuration.
D. Umask : Limiter les droits
Une autre méthode pouvant être mise en place va consister à limiter les droits de lecture sur les fichiers de backup créés de manière automatique ou manuelle. En effet, nous avons vu que lorsqu'un fichier était créé manuellement, les droits de lecture étaient par défaut en lecture pour tous les utilisateurs "-rw-r--r--". Cela vient en réalité des droits qui sont affectés par défaut sur un fichier nouvellement créé : l'umask. Cela signifie que, pour tout fichier créé par un utilisateur dans un contexte de configuration par défaut sous Linux, tous les utilisateurs peuvent lire ce fichier. Nous allons donc mettre en place un durcissement de l'umask pour corriger cela. Techniquement c'est assez simple.
On se rend dans le fichier /etc/login.defs pour mettre "077" au lieu de "022" sur le champ "UMASK". On va ensuite dans le fichier /etc/pam.d/comm.session rajouter la ligne suivante :
session optional pam_umask.so
En redémarrant votre session, vous pourrez voir que votre umask est à 077 et que les fichiers créés ne sont plus lisibles par les "others" :
drwxr-xr-x 3 root root 4096 juin 10 09:50 .. -rw-r--r-- 1 www-data www-data 163 juin 13 15:56 .htaccess -rw------- 1 root root 11104 juin 13 17:16 index.bak <------ Illisible par apache(www-data) -rw-r--r-- 1 www-data www-data 11104 juin 10 09:50 index.html
Cela restreindra donc la lecture des fichiers de backups créés manuellement comme les zip, sql, bak, etc.. Mais ce n'est pas une mesure suffisante si elle est utilisée seule.
root@debian:/var/www/html# umask -p umask 0077
Si vous souhaitez comprendre plus en profondeur le concept et le fonctionnement de l'umask, je vous oriente vers un autre article que j'ai écrit à ce sujet : Gestion de l'umask sous Linux
E. Le sysadmin/webmaster
La meilleure des sécurité reste la prudence des administrateurs systèmes et des webmasters des sites et applications web. Plusieurs habitudes seront certainement à changer pour arriver à créer un contexte sécurisé vis à vis de la sécurité des fichiers de backup, comme par exemple :
- Éviter d'éditer les fichiers directement sur le serveur de production
- Si ce n'est pas possible, éviter d'éditer les fichiers directement dans l'arborescence du serveur web mais plutôt travailler en mode copie depuis un autre répertoire
- Lors de la création de backup de base de données ou de répertoire web, ne pas lancer les commandes de backups depuis l'arborescence web afin de ne pas stocker les .sql, ou .zip dans l'arborescence web
- Vérifier à deux fois qu'aucun fichier de sauvegarde (.swp, .bak) n'est laissé dans l'arborescence web à la fin de l'intervention...
Quoi qu'il en soit, il est primordial d'utiliser l'une de ces sécurité, dans les meilleurs cas, il est préférable d'en combiner plusieurs pour avoir une sécurité plus robuste, qu'elles soient humaines et/ou techniques.
D'autres sources d'informations à ce sujet :
- OWASP Testing guide v4 : OWASP Testing guide v4
Nous avons fait le tour de ce sujet pour cet article, il y a sûrement beaucoup de choses supplémentaires à dire, si vous avez des conseils ou des suggestions, n'hésitez pas à les partager des les commentaires, ils aideront beaucoup de monde.