Mise à jour
Mise à jour de la base de données, veuillez patienter...
Site original : blogiGor
I have a capacity for war
I have a capacity for hate
I have a capacity for insanity
for anger
for lies.
Five hundred twenty-five thousand six hundred minutes
times two
before I break
into an explosion of thoughts
and insurgents soft-kills
and career moves.
A capacity for destruction
A capacity for loss
A capacity for death
Violence
Nothingness.
Twenty four months of pain and disgust
Actions of my hands accuse me guilty
Charge: unclear details and shaky intel
Still, I pulled the trigger.
There's a limit to madness, gauge clocks out at two years
But they serve up poison like entrees at Blueberry Hill
Crazy with a side of numb.
It took 63,072,000 seconds to go from me to somebody else
To change.
Mike Ladd: Everyday when you left Predator, what was the first thing you would do? And what would you think about before you went to bed that night?
Lynn Hill: The first thing I would do is stand outside and I would walk to my car and I would sit in the car and decompress everything that happened that day. Try so hard to strip off everything that wasn't me; trying to deal with the guilt of what I did that day; and hoping that when I put the car in drive that it didn't feel like a joystick that I had been flying all day; and when I drive it would be silent just hearing the humming of the car with the windows up so I couldn't have anything distracting me, just have white noise.
And when I was in bed, the last thing I would think about was the families of these other people, and how they look like me, and that I could have been on the other side of those crosshairs. And why was I the one who was able to be here and that the other Sergeants had to be over there.
ML: Did that affect your dreams?
LH: It affected my dreams, where I was thinking I should've been the one there. And sometimes it was just black; it was like smoke that would... whool around me in my head, and I was always in my car on a cliff ready to drop off.
ML: That was the dream ? You in a car on a cliff ready to jump off?
LH: That was my dream. That any minute I could just drive off and it would end it all and it would be over. And there was a black cloud over me, like Predator, just somebody watching me always, like Big Brother. And it was just looming. Because it's kind of like you're Linus (laughs) from Peanuts: that dark coud just follows you everywhere. And you can't really shake it, because a part of this is kinda your fault.
By Lynn Hill
Je suis capable de guerre
Je suis capable de haine
Je suis capable de démence
de colère
de mensonges.
Cinq cent mille six cent minutes
fois deux
avant d'éclater
en une explosion de pensées
et de moyens de protection insurgés
et de réorientation de carrière.
Une capacité de destruction
Une capacité de perte
Une capacité de mort
de violence
de néant.
Vingt quatre mois de souffrance et de dégoût
Les actes de mes mains me condamnent
Charge : détails peu clairs et renseignements incertains
Pourtant, j'ai pressé sur la détente.
Il y a une limite à la folie, la jauge butte à 2 ans
Mais ils distribuent du poison comme ces entrées à Blueberry Hill
Le délire avec un côté engourdi.
Il faut 63'072'000 secondes pour aller de moi à quelqu'un d'autre
Pour changer.
Mike Ladd : Quand tu quittais Predator1, chaque jour, que faisais-tu en premier ? Et à quoi pensais-tu avant d'aller au lit, ce soir-là ?
Lynn Hill : La première chose que je faisais était de sortir et de marcher jusqu'à ma voiture et je m'asseyais dans la voiture et je décompressais de tout ce qui s'était passé ce jour-là. Essayer obstinément de me débarrasser de tout ce qui n'était pas moi ; essayer de faire face à la culpabilité de ce que j'avais fait ce jour-là ; et espérer que lorsque je démarrais la voiture, ça ne ressemble pas au joystick que j'avais piloté tout au long de la journée ; et quand je conduisais, c'était silencieux, simplement entendre le murmure de la voiture, les fenêtres fermées pour que rien ne puisse me distraire, rien que du bruit blanc.
Et quand j'étais au lit, la dernière chose que je pensais étaient aux familles de ces autres personnes, comment ils me ressemblaient, et que j'aurais pu être de l'autre côté de ces viseurs. Et aux raisons pour lesquelles j'étais en mesure d'être ici et que les autres Sergents devaient être là-bas.
ML : Est-ce que ça avait un effet sur tes rêves ?
LH : Ça avait un effet sur mes rêves, dans lesquels je pensais que j'aurais dû être là-bas. Et parfois c'était juste noir ; c'était comme de la fumée qui... s'enroulait2 autour de moi, dans ma tête, et j'étais toujours dans ma voiture au bord d'une falaise, prête à tomber.
ML : C'était ton rêve ? Toi dans une voiture au bord d'une falaise, prête à sauter ?
LH : C'était mon rêve. Qu'à chaque minute je pouvais sortir de la route et que ça arrêterait tout et que ce serait fini. Et il y avait un nuage noir au-dessus de moi, comme Predator, quelqu'un qui m'observait continuellement, comme Big Brother. Et c'était visible. Parce que c'est comme si tu étais Linus (rires) des Peanuts3 : ce nuage noir pouvait te suivre partout. Et tu ne peux pas vraiment le semer, parce qu'en partie c'est en quelque sorte ta faute.
Par Lynn Hill
Il s'agit du troisième morceau du disque de Vijay Iyer, Mike Ladd, Maurice Decaul, Lynn Hill (et quelques autres), intitulé Holding It Down : The Veterans' Dream Project. Cet album porte les mots de vétérans des guerres criminelles (par définition, mais dans ces cas aussi selon les lois internationales) en Afghanistan et en Irak.
J'ai commencé à traduire maladroitement ces textes en novembre 2013 et depuis décembre de la même année, je n'ai plus rien traduit. Il se trouve que dans la suite des assassinats perpétrés le 7 janvier 2015 dans les locaux de Charlie Hebdo, au cours de différentes lectures (par exemple l'art de la guerre) ou relectures (comme The due-process-free assassination of U.S. citizens is now reality), j'ai pensé reprendre ces traductions.
Il me semble de plus en plus frappant que la majorité des civils, qu'ils soient d'Europe de l'Ouest, des États-Unis d'Amérique du Nord, d'Afrique du Nord et de l'Ouest, de la péninsule arabique, du Proche-Orient, du Moyen-Orient ou d'Extrême-Orient, sont les victimes des guerriers, de nos États ou de leurs opposants. Toute forme d'union nationale, parce qu'elle est nationale, est un piège pour nous embrigader dans une guerre qui n'est pas la nôtre, du moins pas la mienne.
Je ne reconnais aucun gouvernement, qu'il soit élu dans un système représentatif ou auto-institué. Les bandes de cons, ça tue énormément.
Si tu as des améliorations de traduction à suggérer, n'hésite pas à les indiquer dans les commentaires ou à les proposer via github, sur le fichier capacity-lynn-bronx-ny.md. Merci.
Si l'on veut la paix, commençons par la faire.
Drone de l'armée US : https://fr.wikipedia.org/wiki/MQ-1_Predator↩
to whool around, je n'ai pas trouvé de trace de ce verbe dans un quelconque dictionnaire, je suppose une licence, de l'argot ou une erreur typographique, mais je n'ai aucune piste concrète↩
mots introuvables faute de les chercher
la sécheresse courante du lavabo aux égouts
flots en colère
jouée
paysages sans reliefs
à force d'hyperboles et de superlatifs
se tourner se détourner
"comme si nous étions déjà libres"
et s'y mettre
les armes et le brouhaha
stériles
surlignent le vide
le vide
pourvu que ça se vende
pourvu que ça marge
pourvu que ça surface
la vitesse sature les sens
la masse saumure le sens
le contresens interdit
sans voix
sans un regard
la tête dans le néant
bruyant
clignotant
en solde
en rang au pas même désordonné
se tourner se détourner
"comme si nous étions déjà libres"
et s'y mettre
mots introuvables faute de les chercher
la sécheresse courante du lavabo aux égouts
flots en colère
jouée
paysages sans reliefs
à force d'hyperboles et de superlatifs
se tourner se détourner
"comme si nous étions déjà libres"
et s'y mettre
les armes et le brouhaha
stériles
surlignent le vide
le vide
pourvu que ça se vende
pourvu que ça marge
pourvu que ça surface
la vitesse sature les sens
la masse saumure le sens
le contresens interdit
sans voix
sans un regard
la tête dans le néant
bruyant
clignotant
en solde
en rang au pas même désordonné
se tourner se détourner
"comme si nous étions déjà libres"
et s'y mettre
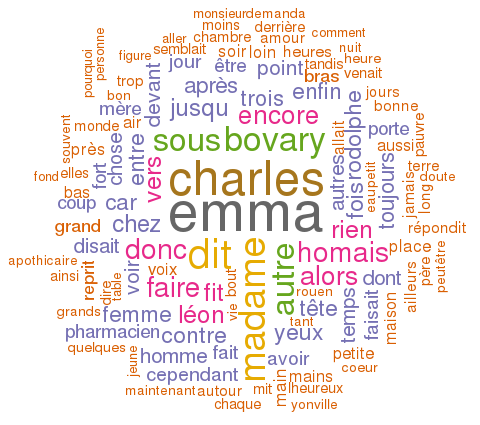
Dans le cadre d'un cours de statistiques appliquées à la recherche du 1er semestre du master en science de l'information, on a touché un peu à R et un tout petit peu plus à RStudio, qui n'est qu'un IDE pour R, et comme je m'y étais déjà un peu intéressé, j'en ai profité pour aller voir plus loin. Plus loin, c'était peut-être plus près, comme toujours ça dépend des points de vue. Je me suis donc amusé à faire des wordclouds, ou des nuages de mots, afin d'en montrer la fréquence d'utilisation, à partir d'un "corpus", en l'occurrence le Madame Bovary de Flaubert.
Je me suis principalement basé sur ce tutoriel.
Pour l'installation de R, c'est assez simple et bien documenté. Je l'ai fait sur deux postes, l'un sous Fedora 20 avec un simple yum install r-base en root, l'autre sous Debian Wheezy, d'abord avec le même simple apt-get install r-base en root également, mais en fait j'ai constaté plus tard que la version des dépôts ne permet pas toujours d'installer les libraries voulue, donc il est préférable d'ajouter le dépôt C-RAN, comme indiqué là : http://cran.r-project.org/bin/linux/debian/README.html. Il manque juste l'info sur la clé publique du dépôt. Un gpg --keyserver subkeys.pgp.net --recv-key 381BA480 a bien fonctionné de mon côté.
Pour RStudio, il faut télécharger le paquet ad hoc, par exemple le rpm ou le deb et l'installer avec yum ou apt-get, ceci afin d'avoir bien toutes les dépendances. Du moins, c'est ce que j'ai constaté. Et c'est parti.
La première chose à faire, c'est de se munir d'un corpus de texte(s), s'il(s) est (ou sont) en .txt, c'est mieux. Pour ma part, pour mon premier test, j'ai pensé à du Flaubert, va savoir pourquoi. Dans ce genre de situation, j'aime bien aller sur Project Gutenberg, parce qu'on y trouve des œuvres en format texte, et j'ai même trouvé Madame Bovary en français, assez facilement pour une fois. Je l'ai téléchargé, enregistré à quelque part. Je l'ai un brin "nettoyé" avec un éditeur de texte pour supprimer les infos ajoutées par le projet en anglais, avant et après le texte, ce qui a dû me prendre une minute.
On peut ouvrir RStudio et installer les libraries dont on a besoin : tm pour le text mining, wordcloud pour le wordcloud, si, si, je te jure, et en testant j'ai vu qu'il était utile d'installer aussi SnowballC pour faire du stemming. Plusieurs manière de le faire, soit avec les commandes, soit avec l'interface graphique de RStudio, ce qui revient quand même au même :
install.packages("tm")
install.packages("wordcloud")
install.packages("SnowballC")
Ce qui doit pouvoir se simplifier en install.packages(c("tm","wordcloud","SnowballC"). En passant par l'interface graphique, ça se passe dans la fenêtre en bas à droite, l'onglet Packages, bouton Install. Un fois les paquets installés, on peut se lancer dans le script lui-même.
On commence par charger les libraries nécessaires :
library ("tm")
library ("wordcloud")
library ("SnowballC")
Puis, on crée le corpus :
bovary <- Corpus(DirSource("~/informatique/R/wordcloud/tmp/", encoding = "UTF-8"), readerControl = list(reader=readPlain, language="fr"))
bovary est le nom que j'ai donné au corpus. Corpus est une commande qui crée un corpus à partir de textes. Le DirSource donne le chemin vers le dossier qui contient le ou les textes à intégrer dans le corpus. On voit que l'on peut préciser l'encodage des textes. Attention, tous les textes contenus dans le dossiers vont être traités... readerControl précise quel lecteur il faut utiliser et la langue. En réalité, la commande proposée par le tutoriel cité plus haut fonctionne tout aussi bien :
bovary <- Corpus(DirSource("~/informatique/R/wordcloud/tmp/")
Puis, il s'agit de préparer le textes en supprimant les espaces surnuméraires, les majuscules, les mots vides (stop words) et la ponctuation.
bovary <- tm_map(bovary, stripWhitespace)
bovary <- tm_map(bovary, content_transformer(tolower))
bovary <- tm_map(bovary, removeWords, c(stopwords("fr"), "comme", "tout", "plus", "deux", "bien", "quand", "quelque", "peu", "puis", "tous", "toute", "toutes", "oui", "non"))
bovary <- tm_map(bovary, removePunctuation)
Ce que j'ai remarqué, c'est qu'on obtient de meilleurs résultats en supprimant les mots vides avant d'enlever la pontctuation. Je me suis en effet retrouvé avec beaucoup de mots comme "jai" ou "cétait". Je pense que c'est aussi que la liste des mots vides doit être améliorée. Il ne serait pas inutile de regarder de plus près les possibilités de tm en langue française. Dans la commande removeWords, j'ai ajouter quelques mots qu'il m'a semblé utile de supprimer aussi. J'y suis arrivé en tâtonnant, ce qui n'est pas très rigoureux...
Enfin, on peut générer le wordcloud :
wordcloud(bovary, scale=c(3.5,0.35), max.words=120, random.order=FALSE, rot.per=0.35, use.r.layout=FALSE, colors=brewer.pal(8, "Dark2"))
Donc on applique la commande wordcloud sur le corpus traité. scale paramètre les tailles relatives des grandes lettres et des petites. J'ai dû pas mal jouer avec ce paramètre en supprimant des mots, sinon j'obtiens des erreurs, parce qu'il n'est pas possible d'afficher tous les mots. rot.per détermine le pourcentage de mots qui seront affichés verticalement. Le dernier argument correspond aux couleurs. On peut connaître la liste des palettes possibles avec la commande display.brewer.all().
Une fois le nuage généré, on peut l'exporter en format image. J'ai testé le SVG, mais le résultat n'est pas terrible, avec les mots qui se chevauchent. Je n'ai pas réussi à comprendre pourquoi. Mais en PNG, le résultat est relativement satisfaisant.
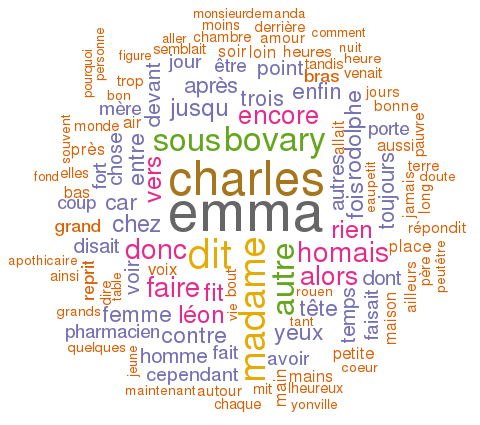
Dans le cadre d'un cours de statistiques appliquées à la recherche du 1er semestre du master en science de l'information, on a touché un peu à R et un tout petit peu plus à RStudio, qui n'est qu'un IDE pour R, et comme je m'y étais déjà un peu intéressé, j'en ai profité pour aller voir plus loin. Plus loin, c'était peut-être plus près, comme toujours ça dépend des points de vue. Je me suis donc amusé à faire des wordclouds, ou des nuages de mots, afin d'en montrer la fréquence d'utilisation, à partir d'un "corpus", en l'occurrence le Madame Bovary de Flaubert.
Je me suis principalement basé sur ce tutoriel.
Pour l'installation de R, c'est assez simple et bien documenté. Je l'ai fait sur deux postes, l'un sous Fedora 20 avec un simple yum install r-base en root, l'autre sous Debian Wheezy, d'abord avec le même simple apt-get install r-base en root également, mais en fait j'ai constaté plus tard que la version des dépôts ne permet pas toujours d'installer les libraries voulue, donc il est préférable d'ajouter le dépôt C-RAN, comme indiqué là : http://cran.r-project.org/bin/linux/debian/README.html. Il manque juste l'info sur la clé publique du dépôt. Un gpg --keyserver subkeys.pgp.net --recv-key 381BA480 a bien fonctionné de mon côté.
Pour RStudio, il faut télécharger le paquet ad hoc, par exemple le rpm ou le deb et l'installer avec yum ou apt-get, ceci afin d'avoir bien toutes les dépendances. Du moins, c'est ce que j'ai constaté. Et c'est parti.
La première chose à faire, c'est de se munir d'un corpus de texte(s), s'il(s) est (ou sont) en .txt, c'est mieux. Pour ma part, pour mon premier test, j'ai pensé à du Flaubert, va savoir pourquoi. Dans ce genre de situation, j'aime bien aller sur Project Gutenberg, parce qu'on y trouve des œuvres en format texte, et j'ai même trouvé Madame Bovary en français, assez facilement pour une fois. Je l'ai téléchargé, enregistré à quelque part. Je l'ai un brin "nettoyé" avec un éditeur de texte pour supprimer les infos ajoutées par le projet en anglais, avant et après le texte, ce qui a dû me prendre une minute.
On peut ouvrir RStudio et installer les libraries dont on a besoin : tm pour le text mining, wordcloud pour le wordcloud, si, si, je te jure, et en testant j'ai vu qu'il était utile d'installer aussi SnowballC pour faire du stemming. Plusieurs manière de le faire, soit avec les commandes, soit avec l'interface graphique de RStudio, ce qui revient quand même au même :
install.packages("tm")
install.packages("wordcloud")
install.packages("SnowballC")
Ce qui doit pouvoir se simplifier en install.packages(c("tm","wordcloud","SnowballC"). En passant par l'interface graphique, ça se passe dans la fenêtre en bas à droite, l'onglet Packages, bouton Install. Un fois les paquets installés, on peut se lancer dans le script lui-même.
On commence par charger les libraries nécessaires :
library ("tm")
library ("wordcloud")
library ("SnowballC")
Puis, on crée le corpus :
bovary <- Corpus(DirSource("~/informatique/R/wordcloud/tmp/", encoding = "UTF-8"), readerControl = list(reader=readPlain, language="fr"))
bovary est le nom que j'ai donné au corpus. Corpus est une commande qui crée un corpus à partir de textes. Le DirSource donne le chemin vers le dossier qui contient le ou les textes à intégrer dans le corpus. On voit que l'on peut préciser l'encodage des textes. Attention, tous les textes contenus dans le dossiers vont être traités... readerControl précise quel lecteur il faut utiliser et la langue. En réalité, la commande proposée par le tutoriel cité plus haut fonctionne tout aussi bien :
bovary <- Corpus(DirSource("~/informatique/R/wordcloud/tmp/")
Puis, il s'agit de préparer le textes en supprimant les espaces surnuméraires, les majuscules, les mots vides (stop words) et la ponctuation.
bovary <- tm_map(bovary, stripWhitespace)
bovary <- tm_map(bovary, content_transformer(tolower))
bovary <- tm_map(bovary, removeWords, c(stopwords("fr"), "comme", "tout", "plus", "deux", "bien", "quand", "quelque", "peu", "puis", "tous", "toute", "toutes", "oui", "non"))
bovary <- tm_map(bovary, removePunctuation)
Ce que j'ai remarqué, c'est qu'on obtient de meilleurs résultats en supprimant les mots vides avant d'enlever la pontctuation. Je me suis en effet retrouvé avec beaucoup de mots comme "jai" ou "cétait". Je pense que c'est aussi que la liste des mots vides doit être améliorée. Il ne serait pas inutile de regarder de plus près les possibilités de tm en langue française. Dans la commande removeWords, j'ai ajouter quelques mots qu'il m'a semblé utile de supprimer aussi. J'y suis arrivé en tâtonnant, ce qui n'est pas très rigoureux...
Enfin, on peut générer le wordcloud :
wordcloud(bovary, scale=c(3.5,0.35), max.words=120, random.order=FALSE, rot.per=0.35, use.r.layout=FALSE, colors=brewer.pal(8, "Dark2"))
Donc on applique la commande wordcloud sur le corpus traité. scale paramètre les tailles relatives des grandes lettres et des petites. J'ai dû pas mal jouer avec ce paramètre en supprimant des mots, sinon j'obtiens des erreurs, parce qu'il n'est pas possible d'afficher tous les mots. rot.per détermine le pourcentage de mots qui seront affichés verticalement. Le dernier argument correspond aux couleurs. On peut connaître la liste des palettes possibles avec la commande display.brewer.all().
Une fois le nuage généré, on peut l'exporter en format image. J'ai testé le SVG, mais le résultat n'est pas terrible, avec les mots qui se chevauchent. Je n'ai pas réussi à comprendre pourquoi. Mais en PNG, le résultat est relativement satisfaisant.