Résoudre rapidement Sutom / Wordle avec les Regex
vendredi 21 janvier 2022 à 13:51S’il y a bien un truc puissant en programmation, ce sont les expressions régulières, ou « regular expressions », Regex pour les intimes.
J’en avais déjà fait une petite introduction que je vous conseille de lire.
Aujourd’hui, voyons un usage à ces choses-là.
Depuis le début de l’année, le jeu Wordle (en anglais) et Sutom (en français) sont devenus viraux. Leur principe est celui du jeu télévisé « Motus ».
Sutom ?
Le principe du jeu est le suivant.
Le but est de deviner un mot.
La première lettre nous est toujours fournie. On connaît également la longueur du mot.
On a droit à 6 essais pour deviner le mot :

À chaque fois qu’on essaye un mot, on a des indices :
- les lettres bien placées sont en rouge
- les lettres présentes mais à leur mauvaise place sont en jaune
- les autres lettres ne figurent pas dans le mot
Dans cet exemple, celui du 21 janvier 2022, si j’essaye le mot « Diamètre », j’obtiens :
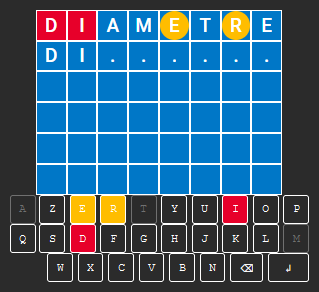
Je sais désormais que :
– Le mot fait 8 lettres (incluant le D au début)
– D et I sont bien placés
– E et R sont mal placés (mais présents).
– A, T et M sont exclus (grisés sur le clavier)
D’essai en essai, on accumule les indices et la solution nous apparaît plus ou moins facilement.
Motus était un jeu télévisé, mais sur ces petits jeux en ligne, il n’y a rien à gagner. Il y a un seul mot par jour.
Si vous trouvez, vous recevez un code rigolo à partager sur les réseaux sociaux qui représentent les couleurs des cases du tableau. Comme personne n’essaie les mêmes mots, il est généralement unique à vous pour ce jour-là. C’est amusant :).
Utiliser les Regex pour jouer à Sutom
Sutom demande deux choses qu’un ordinateur a :
- de la mémoire (du vocabulaire)
- de la logique
Il suffit d’une liste de mots connus suffisamment complète ainsi que quelques règles de base pour permettre à un ordinateur de jouer à Sutom.
On pourrait créer un solveur où l’on prend la grille en photo et il nous donne la réponse. Ce serait un exercice intéressant à plusieurs niveaux, mais ce n’est pas ce que je vais faire ici.
Je me contenterai ici d’utiliser une liste de mots et les Regex mentionnées plus haut pour trouver la solution grâce aux indices du jeu.
J’ai fait cette page : Rechercher un mot. Elle contient 340 000 mots et un champ de recherche.
L’intérêt est que la recherche fonctionne par Regex !
Le but de cet article est de créer une Regex puissante qui va très vite filtrer les mots et nous sortir le bon, généralement après 1 ou 2 essais seulement.
Pour l’exemple du 21 janvier 2022, le mot commence par D et fait 8 lettres.
On a donc cette Regex :
D.{7}$Vous pouvez copier ça dans le champ de recherche de la page de recherche de mots.
La Regex signifie « un “D”, suivi de 7 lettres » (donc bien 8 au total). Le « $ » à la fin signifie que c’est la fin du mot après ça. Si on ne le met pas, il va nous sortir les mots de 8 lettres ou plus. Or nous ne voulons que les mots de 8 lettres.
À ce stade, ma page me sort 37 042 mots. On peut en utiliser un de la liste ou en poser un qu’on connaitrait déjà.
Dans mon cas, j’essaye « DIAMETRE ». J’obtiens les informations suivantes :
– D et I sont bien placés
– E et R sont mal placés (mais présents).
– A, T et M sont exclus (grisés sur le clavier)
Il faut donc un mot qui débute par DI, qui ne contienne pas A, T, M, mais qui contienne E, R. et dont la longueur totale fasse toujours 7 lettres.
Le début de la Regex est simple : le mot commence par DI.
La Regex débute donc tout naturellement par :
diEnsuite, il faut dire que parmi tous les mots commençant par « DI », on veut ceux comportant E et R.
Il s’agit d’utiliser une assertion positive avant (positive lookahead), pour dire « je veux un E et un R après le DI ». Il existe aussi des assertions arrière, pour vérifier ce qui se trouve avant, mais ça ne nous intéresse pas ici.
L’assertion positive est inclue dans notre Regex sous la forme (?=REGEX). Elle contient elle-même une seconde Regex.
Notre Regex interne est la forme « une lettre suivie de E ou R ». Notre assertion en entier donne donc :
(?=.*([er]))Maintenant un peu de technique interne aux Regex.
Normalement quand on cherche « ABC », il cherche un « A » suivi d’un « B » suivi d’un « C ». La chaîne « A1B1C1 » ne marche pas, car les trois lettres ne se suivent pas.
Effectivement, après avoir matché le « A », le parseur se positionne après le A. Il regarde donc s’il y a un « B » juste après, et ainsi de suite, à chaque fois en venant avancer dans la chaîne.
Les assertions servent à matcher des trucs, mais ne font pas avancer dans notre Regex globale. Ainsi, quand on matche notre « AB », on avance de deux lettres dans le mot.
Quand on utilise l’assertion, on va parcourir le reste du mot et renvoyer un TRUE si un E et un R sont trouvés. Si c’est le cas, l’assertion est valide (elle retourne TRUE), mais l’on vient se remettre juste après le DI.
À ce stade, la Regex entière a filtrée les mots débutant par DI et contenant un E et un R.
Il reste à filtrer les mots pour éliminer ceux avec A, T, M.
Pour ça, on veut exclure des mots. On va utiliser une assertion négative avant (negative lookahead) pour dire « je ne veux pas de A, T, M après le “DI” ».
L’assertion négative se construit avec (?!REGEX). Elle est négative, car on retourne FALSE si la REGEX à l’intérieur de l’assertion retourne TRUE.
Dans notre cas, on veut refuser A, T et M. Ce qui donne :
(?!.*[atm])Maintenant, il nous reste à dire qu’il nous faut 6 lettres.
Inutile de lister les lettres : on peut utiliser le simple « . ». Les assertions ont déjà filtré les lettres qui nous intéressent ou non. On a donc :
.{6}Mis bout à bout, on a :
di(?=.*([er]))(?!.*([atm])).{6}$Le filtre me trouve 79 mots (sur 340 000). Pas mal, mais pas suffisant pour gagner au jeu. Il faut en essayer un au hasard. J’essaye donc le mot « DISPOSER ».
Qui donne :
![]()
J’apprends donc que le mot est de forme « DI...SER ». J’apprends également qu’on peut éliminer les lettres O et P, en plus de A, T, M.
On peut donc modifier notre assertion négative avant pour filtrer ces deux lettres supplémentaires. De plus, le E et le R sont bien placés : on sait où ils sont. Notre assertion positive avant devient inutile.
La Regex globale devient :
di(?!.*([atopm])).{3}ser$Qui signifie :
- « di »
- puis « on ne veut pas de A, T, O, P, M »
- puis on revient après le « di », on met trois lettres n’importe lesquelles
- puis on met « ser »
- et c’est la fin du mot.
Et là, bim, mon outil de recherche ne me sort plus qu’un seul mot.
Il se trouve que c’est le bon :
SUTOM #14 3/6
🟥🟥🟦🟦🟡🟦🟡🟦
🟥🟥🟦🟦🟦🟥🟥🟥
🟥🟥🟥🟥🟥🟥🟥🟥Bingo !
Ou plutôt « Motus » !
(ou Sutom)
Bien-sûr cela fonctionne, car tous les mots dans le dictionnaire utilisé par le jeu sont contenus dans le dictionnaire de ma page.
Ma page n’utilise pas le même dictionnaire. C’est volontaire, car je veux un dictionnaire plus large. Mais il arrive bien à filtrer des choses.
Notez que ma page permet de filtrer les accents et les tirets aussi. Sutom ne les affiche pas (ou plutôt il compte le É ou le È comme un E).
Enfin, j’ai aussi un outil de visualisation de Regex. Il est repris d’un code déjà existant (pas de moi) mais ça permet de visualiser ce que signifient les expressions assez compliquées de Regex.