Mise à jour
Mise à jour de la base de données, veuillez patienter...
Site original : bfontaine.net
While following a tutorial to install Virtualbox in order to have docker working on macOS, I
hit an issue where the docker-machine create command fails with an error that looks like this:
VBoxManage: error: Failed to create the host-only adapter
VBoxManage: error: VBoxNetAdpCtl: Error while adding new interface: failed to open /dev/vboxnetctl: No such file or directory
VBoxManage: error: Details: code NS_ERROR_FAILURE (0x80004005), component HostNetworkInterfaceWrap, interface IHostNetworkInterface
VBoxManage: error: Context: "RTEXITCODE handleCreate(HandlerArg *)" at line 95 of file VBoxManageHostonly.cpp
If you search on the Web, everybody says you have to open the Security & Privacy settings window
and allow the Oracle kernel extensions to run. But I didn’t have it. I tried uninstalling
Virtualbox, re-installing through the official website, reboot, uninstall, re-install with
brew cask but I always had the issue. Some people reported having a failed Virtualbox
installation but mine seemed ok.
I tried the spctl solution but it didn’t change anything.
In the end, I tried this StackOverflow answer:
sudo "/Library/Application Support/VirtualBox/LaunchDaemons/VirtualBoxStartup.sh" restart
It failed, but it told me to check the Security & Privacy setting window. I did, and I had the button everyone was talking about. I enabled the kernel extension, rebooted, and it worked.
Hope this can save some time to anyone having the same issue!
Code-Golf is the art of writing the shortest program in a given language that implements some given algorithm. It started in the 90’s in the Perl community and spread to other languages; there are now languages dedicated to code-golfing and StackExchange has a Q&A website for it.
In 2015, for example, I wrote a blog post showing how to write a JavaScript modules manager that fits in 140 chars (the maximum length of a tweet at that time).
4clojure is a well-known website to learn Clojure through exercises of increasing difficulty, but it has a lesser-known code-golf challenge which you can enable by clicking on “Leagues” in the top menu. If you check the code-golf checkbox, you then get a score on each problem that is the number of non-whitespace characters of your solution; the smaller the better.
The first thing you’ll note when code-golfing is that the reader syntax for
anonymous functions is a lot shorter than using fn:
; 18 chars
(fn [a b c] (* (+ a b) c))
; 13 chars
#(* (+ %1 %2) %3)
; 12 chars: -1 char because '%' is equivalent to '%1'
#(* (+ % %2) %3)
Unfortunately you can’t have a reader-syntax function inside another reader-syntax one, so you often have to transform the code not to use anonymous functions.
for is a very powerful tool for that, because it allows you to do the
equivalent of map, and a lot more, with no function:
; invalid!
#(map #(* 2 %) %)
; 19 chars
#(map (fn [x] (* 2 x)) %)
; 17 chars
#(map (partial * 2) %)
; 15 chars
#(for [x %] (* 2 x))
; Note that for this specific example
; the best solution uses `map`:
#(map + % %)
On some problems it can even be shorter than using map + filter:
; 31 chars
(fn [x a]
(map inc (filter #(< % a) x)))
; 26 chars
#(for [e x :when (< e a)] (inc e))
Some core functions are equivalent in some contexts and so the shorter one can substitute a longer one:
; 18 chars
#(filter identity %)
; 14 chars
#(filter comp %)
; 6 chars
(inc x)
(dec x)
; 5 chars
(+ x 1)
(- x 1)
; 12 chars
(reduce str x)
; 11 chars
(apply str x)
; 14 chars
(apply concat x)
; 13 chars
(mapcat comp x)
When you must use a long function name in multiple places, it might be shorter
to let that function with a one-letter symbol:
; 120 chars
#(clojure.set/difference
(clojure.set/union % %2)
(clojure.set/union
(clojure.set/difference % %2)
(clojure.set/difference %2 %)))
; 73 chars
#(let [d clojure.set/difference u clojure.set/union]
(d (u % %2) (u (d % %2) (d %2 %))))
; Note that for this specific example
; there is a 17-chars solution
#(set (filter %2 %))
Use indexed access on vectors:
; 15 chars
(first [:a :b :c])
; 11 chars
([:a :b :c] 0)
Use set literals as functions:
; 16 chars
(remove #(= :a %) x)
; 14 chars
(remove #{:a} x)
Inverse conditions to use shorter functions:
; 15 chars
(if (empty? p) a b)
; 12 chars
(if (seq p) b a)
Inlined code is sometimes shorter:
; 24 chars
(let [p (* 3 a)]
(if (< p 5)
a
p))
; 19 chars
(if (< (* 3 a) 5)
a
(* 3 a))
Use 1 instead of :else/:default in cond:
; 24 chars
(cond
(= m p) a
(< m p) b
:else c)
; 20 chars
(cond
(= m p) a
(< m p) b
1 c)
Use maps instead of ifs for conditions on equality (this one really makes
the code harder to read):
; 13 chars
(if (= "L" x) a b)
; 12 chars
(case x "L" a b)
; 10 chars
({"L" a} x b)
For the latest StackExchange “time”-themed contest, I made a gif showing the evolution of StackOverflow from 2008 to today:

(click on the image to play it again)
The first step was to find a decent API for the Internet Archive. It
supports Memento, an HTTP-based protocol defined in the RFC 7089 in
2013. Using the memento_client wrapper, we can get the closest snapshot
of a website at a given date with the following Python code:
from datetime import datetime, timedelta
from memento_client import MementoClient
mc = MementoClient(timegate_uri="https://web.archive.org/web/",
check_native_timegate=False)
def get_snapshot_url(url, dt):
info = mc.get_memento_info(url, dt)
closest = info.get("mementos", {}).get("closest")
if closest:
return closest["uri"][0]
# As an example, let’s look at StackOverflow two weeks ago
url = "https://stackoverflow.com/"
two_weeks_ago = datetime.now() - timedelta(weeks=2)
snapshot_url = get_snapshot_url(url, two_weeks_ago)
print("StackOverflow from ~2 weeks ago: %s" % snapshot_url)
Don’t forget to install the memento_client lib:
pip install memento_client
Note this gives us the closest snapshot, so it might not be exactly two weeks ago.
We can use this code to loop using an increasing time delta in order to get snapshots at different times. But we don’t only want to get the URLs. We wants to make a screenshot of each one.
The easiest way to programmatically take a screenshot of a webpage is probably to use Selenium. I used Chrome as a driver; you can either download it from the ChromeDriver website or run the following command if you’re on a Mac with Homebrew:
brew install bfontaine/utils/chromedriver
We also need to install Selenium for Python:
pip install selenium
The code is pretty short:
from selenium import webdriver
def make_screenshot(url, filename):
driver = webdriver.Chrome("chromedriver")
driver.get(url)
driver.save_screenshot(filename)
driver.quit()
url = "https://web.archive.org/web/20181119211854/https://stackoverflow.com/"
make_screenshot(url, "stackoverflow_20181119211854.png")
If you run the code above, you should see a Chrome window open, go at the URL
by itself, then close once the page is fully charged. You now have a screenshot
of this page in stackoverflow_20181119211854.png! However, you’ll quickly
notice the screenshot includes the Wayback Machine’s header over the top of the
website:

This is handy when browsing through snapshots by hand, but not so much when we access them from Python.
Fortunately, we can get a header-less URL by changing it a bit: we can
append id_ to the end of the date in order to get the page exactly as it was
when the bot crawled it. However, this means it links to CSS and JS files that
may not exist anymore. We can get a URL to an archived page that has been
slightly modified to replace links with their archived version using im_
instead.
https://web.archive.org/web/20181119211854/...https://web.archive.org/web/20181119211854id_/...https://web.archive.org/web/20181119211854im_/...Re-running the code using the modified URL gives us the correct screenshot:
url = "https://web.archive.org/web/20181119211854im_/https://stackoverflow.com/"
make_screenshot(url, "stackoverflow_20181119211854.png")
Joining the two bits of code we can make screenshots of a URL at different intervals. You may want to check the images once it’s done to remove inconsistencies. For example, the archived snapshots of Google’s homepage aren’t all in the same language.
Once we have all images, we can generate a gif using Imagemagick:
convert -delay 50 -loop 1 *.png stackoverflow.gif
I used the following parameters:
-delay 50: change frame every 0.5s. The number is in 100th of a second.-loop 1: loop only once over all the frames. The default is to make an
infinite loop but it doesn’t really make sense here.You may want to play with the -delay parameter depending on how many images
you have as well as how often the website changes.
I also made a version with Google (~10MB) at 5 frames per second,
with -delay 20. I used the same delay
as the StackOverflow gif: at least 5 weeks between each screenshot. You
can see which year the screenshot is from by looking at the bottom of each
image.
Two weeks ago I created and put online a box plot of 73k movies durations across the time.
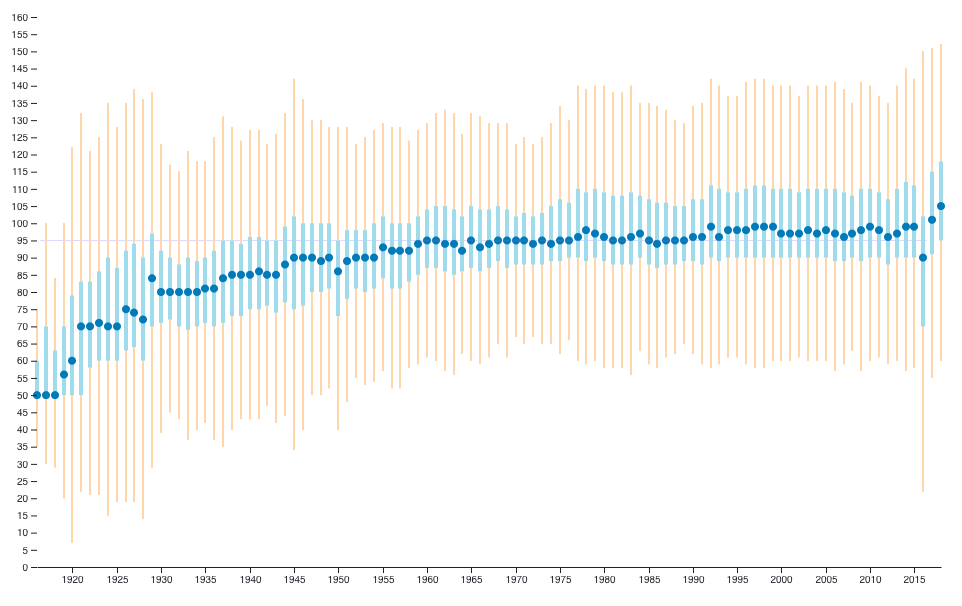
It started with a question: “Are movies getting longer and longer?”. Spoiler: Not really, except maybe in the last couple of years.
I used Wikidata’s online query service to export all movies then filtered those with both a publication date and a duration. This gave me a large JSON which I processed using Python in order to extract a couple numbers for each year: min, max, median, first and third quartiles.
The result fits in a small JSON file, which I then used to build a D3 using a few lines of JS. I used colorbrewer2 to find a colorblind-safe color palette.
You can see the result as well as the JS code on Observable.
To avoid outliers such as “Modern Times Forever” (240 hours) or
“The Burning of the Red Lotus Temple”, I used the interquartile
range (IQR) to limit the size of the bars: any movie whose duration is
below Q1-1.5×IQR or above Q3+1.5×IQR (where Q1 is the first quartile and
Q3 the third one) is not shown.
As one can see on the graph, the median duration quickly rises from 50 to 95 minutes from the 1920s to the 1960s, then doesn’t move much except in the last two years.
The first obvious limitation is the data: Wikidata has 200k+ movies but only 73k have both a publication date and a duration. It’s not complete enough to let me filter by movie type; e.g. feature film vs. others.
IMDb lists 5.3M titles (most of which are TV episodes), but there’s no way to export them all.
In the end, there’s no way to know how representative Wikidata’s movies dataset is. It does give a hint, but this graph is not a definitive answer to the original question.
See the Python code.
Mattermost is a Slack-like self-hosted and open-source alternative. We
use it at work but for some reason link previews don’t work. Before diving into
Mattermost’s internals I wanted to see if I could write a quick workaround
using the fact that Mattermost does show an image if you post a link ending
with .png or .jpg.
When you post an image link, Mattermost makes a request to show it in the
application. It detects those images using a regexp; not by e.g.
sending a HEAD request to get the content type. If you have an image URL that
doesn’t end with common extentions Mattermost won’t show it.
Mattermost doesn’t serve you a preview of the image; it rather gives you an
img with the original URL. That means every single person reading the channel
will request the image from its original location. Slack, on the other hand,
fetch images, cache them, and serves them from its own domain,
https://slack-imgs.com. Slack uses a custom user-agent for its request so you
know where it comes from.
User-Agent: Slackbot-LinkExpanding 1.0 (…)
Mattermost, on the other hand, can’t use a custom user-agent because the request is done by your browser. The only thing distinguishing Mattermost’s request for a preview and any other request is it asks for an image:
Accept: image/webp,image/*,*/*;q=0.8
The header above is Chrome telling the Web server it can deal with WebP images, then images in any format, then anything; in that order. Note it explicitly says it accepts WebP images because some browsers don’t support the format.
Unfortunately not all browsers are explicit. Firefox sends Accept: */* since
Firefox 47 and so did IE8 and earlier versions. In those cases we can’t
really do anything beside complicated rules based on the user-agent and other
headers.
If we know how to tell if a request comes from Mattermost asking for an image preview rather than a “normal” user we can serve different contents to them: a link preview as an image to Mattermost, and the normal content to the user.
All we have to do is to make some sort of intelligent proxy. Using Flask we can make something like this:
from flask import Flask
app = Flask(__name__)
@app.route("/<path:path>/p.png")
def main(path):
if not request.headers.get("Accept", "").startswith("image/"):
return redirect(path)
return "Hello, I'm an image"
This is a small web application that takes any route in the form of
/<url>/p.png and either redirects you to that URL if your Accept header
doesn’t start with image/; either serves you a Hello, I'm an image page.
All we have to do now is to return an actual image in lieu of that placeholder text. I used Requests and Beautiful Soup to fetch and parse webpages, and Pillow to generate images.
When one requests http://example.com/http://...some...url.../p.png, the
app fetches that URL; parses it to extract its title and some excerpt; write
that on a blank image; and serves it.
Extracting the title is as easy as grabbing that title HTML tag. If
available, I also try the og:title and twitter:title meta tags. If none
of those are available, I fallback on the first h1 or h2 tag.
Getting an usable excerpt is not too hard; here again I search for common
meta tags: description, og:description, twitter:description. If I can’t
get any of them I take the first p that looks long enough.
You can check that code on GitHub.
The Pillow library makes it easy to write text on an image. I replaced the
(ugly) default font with Alegreya. The tricky part is mostly to fit the
text on the image. I used a combination of Draw#textsize
to get the dimensions of some text as if it were written on the image and
Python’s textwrap module to cut the title and excerpt so that
they wouldn’t cross the right side of the image.
I used fixed dimensions for all images (400×70) and kept a small padding along their sides. Previews with small or missing excerpts get some unused white space at the bottom; this could be fixed by pre-computing the final size of the image before creating it.


On most websites the preview works fine. We could tweak the text size as well as add a favicon or an extracted image.

In the end it took a couple hours to have a working prototype. Most of that time was spent dealing with encoding issues and trying various webpages to find edge cases.
The result is acceptable; it has the issue of not being accessible at all but that’s still better than nothing.
The source code is on GitHub.
{kind=link}