Mise à jour
Mise à jour de la base de données, veuillez patienter...
Site original : Portail Yosko.net
ini_set('session.gc_maxlifetime', 3600); //durée augmentée à 1 heure
$config = array();
$config['LTDir'] = 'cache/'; //dossier où seront stockés les fichiers de session
$config['nbLTSession'] = 200; //nombre max de sessions long-terme simultanées
$config['LTDuration'] = 2592000; //durée d'une session long-terme (2592000 = 1 mois)
$isLoggedIn = logUser();
function logUser() {
global $config;
//démarrer la session PHP
session_start();
//déconnexion en cours ou IP incorrecte
if(isset($_GET['logout'])
|| isset($_SESSION['ip']) && $_SESSION['ip']!=getIpAddress()) {
//suppression de la session "long-terme"
unsetLTSession($_SESSION['uid']);
setcookie('yosloginlt', null, time()-31536000,
dirname($_SERVER['SCRIPT_NAME']).'/',
'', false, true);
//suppression de la session PHP
unset($_SESSION['uid']);
unset($_SESSION['ip']);
unset($_SESSION['login']);
unset($_SESSION['userRelatedInformation']);
session_set_cookie_params(time()-31536000, dirname($_SERVER['SCRIPT_NAME']).'/');
session_destroy();
header("Location: index.php");
//si la session PHP est expirée mais que le cookie de session long-terme existe
} elseif(!isset($_SESSION['uid']) && isset($_COOKIE['yosloginlt'])) {
//récupération des données de session long-terme
$LTSession = getLTSession($_COOKIE['yosloginlt']);
if($LTSession !== false) {
//rétablissement de la session PHP
$_SESSION['uid']=$_COOKIE['yosloginlt'];
$_SESSION['ip']=$LTSession['ip'];
$_SESSION['login']=$LTSession['login'];
} else {
//si le cookie ne correspond à aucune session, on le supprime
setcookie('yosloginlt', null, time()-31536000,
dirname($_SERVER['SCRIPT_NAME']).'/',
'', false, true);
}
//si l'utilisateur est en train de se connecter
} elseif (isset($_POST['submitLogin'])
&& isset($_POST['login']) && trim($_POST['login']) != ""
&& isset($_POST['password']) && trim($_POST['password']) != "") {
//récupération des données utilisateur
$user = getUser($_POST['login']);
//vérification du mot de passe
if(!empty($user) && sha1($_POST['password']) == $user['password']) {
//établissement de la session PHP
$_SESSION['uid']=sha1(uniqid('',true).'_'.mt_rand());
$_SESSION['ip']=getIpAddress();
$_SESSION['login']=$user['login'];
//si l'utilisateur a coché la case "se souvenir de moi"
if(isset($_POST['remember']) && $_POST['remember'] == "remember") {
//enregistrer la session long-terme
$LTSession = array();
$LTSession['login'] = $_SESSION['login'];
$LTSession['ip'] = $_SESSION['ip'];
setLTSession($_SESSION['uid'], $LTSession);
//nettoyage des vieilles sessions
flushOldLTSessions();
}
header("Location: $_SERVER[REQUEST_URI]");
}
}
//si l'utilisateur est connecté
if (!empty($_SESSION['uid'])) {
//mise à jour de la date d'expiration du cookie long-terme
if(isset($_COOKIE['yosloginlt'])
|| isset($_POST['remember']) && $_POST['remember'] == "remember") {
setcookie('yosloginlt', $_SESSION['uid'], time()+$config['LTDuration'],
dirname($_SERVER['SCRIPT_NAME']).'/',
'', false, true);
}
return true;
} else {
return false;
}
}
function getUser($login) {
return(array("login" => "yosko", "password" => sha1("yosko"));
}
function getIpAddress(){
foreach (array('HTTP_CLIENT_IP', 'HTTP_X_FORWARDED_FOR', 'HTTP_X_FORWARDED', 'HTTP_X_CLUSTER_CLIENT_IP', 'HTTP_FORWARDED_FOR', 'HTTP_FORWARDED', 'REMOTE_ADDR') as $key){
if (array_key_exists($key, $_SERVER) === true){
foreach (explode(',', $_SERVER[$key]) as $ip){
$ip = trim($ip); // just to be safe
if (filter_var($ip, FILTER_VALIDATE_IP, FILTER_FLAG_NO_PRIV_RANGE | FILTER_FLAG_NO_RES_RANGE) !== false){
return $ip;
}
}
}
}
}
function setLTSession($sid, $value) {
global $config;
$fp = fopen($config['LTDir'].$sid, 'w');
fwrite($fp, gzdeflate(json_encode($value)));
fclose($fp);
}
function getLTSession($sid) {
global $config;
$dir = $config['LTDir'];
$value = false;
if (file_exists($dir.$sid)) {
//expiration de la session long-terme
if(filemtime($dir.$sid)+$config['LTDuration'] <= time()) {
unsetLTSession($sid);
$value = false;
} else {
$value = json_decode(gzinflate(file_get_contents($dir.$sid)), true);
//mise-à-jour de la date de modification
touch($dir.$sid);
}
}
return($value);
}
function unsetLTSession($sid) {
global $config;
if (file_exists($config['LTDir'].$sid)) {
unlink($config['LTDir'].$sid);
}
}
function flushOldLTSessions() {
global $config;
$dir = $config['LTDir'];
//liste des fichiers de session
$files = array();
if ($dh = opendir($dir)) {
while ($file = readdir($dh)) {
if(!is_dir($dir.$file)) {
if ($file != "." && $file != "..") {
$files[$file] = filemtime($dir.$file);
}
}
}
closedir($dh);
}
//tri par date (plus récents en premier)
arsort($files);
//vérification de chaque fichier
$i = 1;
foreach($files as $file => $date) {
if ($i > $config['nbLTSession'] || $date+$config['LTDuration'] <= time()) {
unsetLTSession($file);
}
++$i;
}
}
DDb (la Dream Database, aka base de données de rêves) est un petit outil en ligne permettant de noter ses rêves et ceux de ses amis, et de les consulter.
En effet, le meilleur moyen de se souvenir de ses rêves c'est, paraît-il, de prendre l'habitude de les noter. Mais cela peut avoir d'autres utilités, comme aider à faire des rêves lucides (où l'on est conscient d'être dans un rêve, ce qui offre l'opportunité de modifier le cours du rêve).
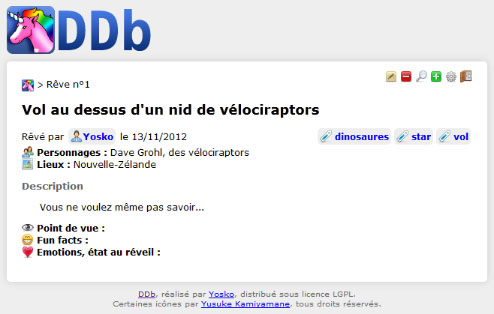
Grâce à la DDb, travaillez sur vos rêves et partagez-les entre amis. Vous pouvez ainsi les ajouter, les modifier, les supprimer, les rechercher sur divers critères. Je serais presque tenté d'ajouter que "la seule limite est votre imagination", mais ça serait sans doute un peu prétentieux.
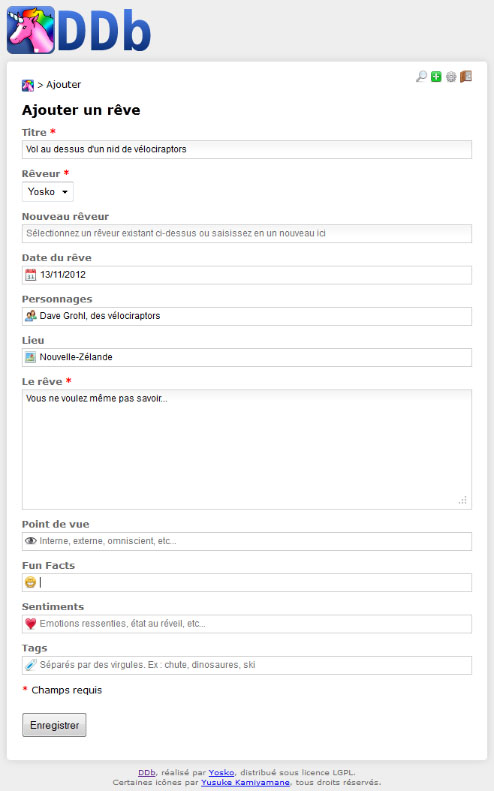
EDIT : DDb est réalisé en HTML5 / PHP / PDO-SQLite (merci H3 pour la remarque :-P)
EDIT bis : DDb comporte désormais un flux RSS et une option de connexion "se souvenir de moi"
J'ai essayé de faire en sorte que l'installation soit la plus simple possible (vu qu'il s'agit d'un petit script, ça aurait été dommage de compliquer les choses). Pour plus d'info, rendez-vous sur la page dédiée au projet :
Et surtout, si vous rencontrez le moindre problème ou que vous avez des idées d'améliorations, n'hésitez pas à m'en faire part !
Rappellez-vous, après l'adaptation d'Anime Girl Generator en C#.Net, je vous avais évoqué mon envie d'en faire une variante en C++/Qt multiplateforme et open-source. Si je n'ai pas immédiatement envisagé de la réaliser, j'ai commencé à travailler sur un autre outil qui a finalement dérivé pour fourni des fonctionnalités apparentées. J'ai l'honneur de vous présenter : Avator !
En réalité, j'étais parti sur un outil de gestion des couleurs en Pixel-Art suite à mes recherches sur le sujet. Mais une fois le premier jet en place, j'ai re-codé la plupart des fonctionnalités qui m'intéressaient de ma version d'AGG.
Et un petit aperçu, un :
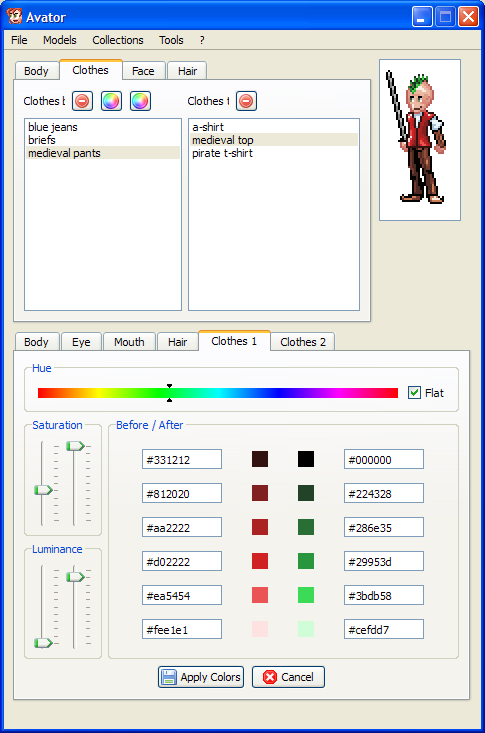
Si vous avez des questions, des remarques, des préréglages de couleurs à proposer ou des ressources particulières que vous souhaiteriez utiliser dans Avator, n'hésitez pas à me contacter.
Pour ceux que ça intéresse (je ne voudrais pas saouler les autres avec mes propos techniques) :
La gestion des couleurs est un peu particulière, puisqu'elle a été pensée pour mes travaux en pixel art. Elle peut même sembler complexe de prime abord, mais les variations d'ombre et de lumière d'une même couleur sont calculée selon un procédé artistique et mathématique censé faciliter vos choix.
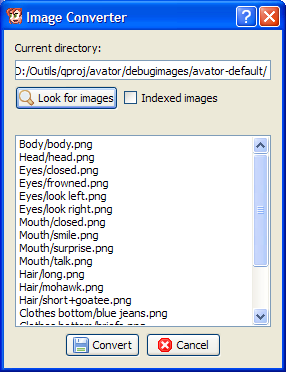
Si j'ai abordé les couleurs sous cet angle, c'était en réalité pour répondre à un besoin personnel : je galère toujours à sélectionner mes couleurs pour mes dessins en pixel art, et j'ai justement l'intention d'en faire beaucoup dans un avenir proche (j'ai hâte de vous montrer ça, mais y'a encore un sacré boulot à abattre avant que ça ne devienne possible).
En gros, chaque zone de couleur comporte un maximum de 6 variantes (en dégradé, exprimant les zones d'ombres et de lumières). Plutôt que de refaire une rotation basique de couleur comme le fait AGG, j'ai préféré me baser sur mes travaux récents pour essayer d'obtenir toujours des couleurs "réalistes". En effet, la rotation donnait parfois des résultats très artificiels et assez dégueulasse...
PS : un grand merci à tous ceux qui ont accepté de tester ça en avant-première, et ont gentiment essuyé les premiers plâtres. On ne m'a remonté que peu de bugs, mais je suis sûr qu'il en reste !
Cela fait plusieurs mois que j'entend parler de l'obsolescence soit-disant avérée (ou tout du moins programmée) de RSS et de son compagnon, Atom. Tout récemment encore, Google a prit des décisions sur feedburner qui laissent entendre qu'ils souhaitent s'en éloigner (ce n'est pas forcément plus mal, puisqu'il s'agissait d'une "petite" partie, très fermée, des flux).
De mon côté, j'ai tendance à ressentir chaque jour un peu plus l'utilité de ces flux d'information. Je n'ai commencé à les utilisé qu'il y a peu (début 2010), et je peux de moins en moins m'en passer. J'agrémente jour après jour mon aggrégateur d'agrébles sources d'informations (ouais je sais, mes allitérations sont nazes...).
Il y a bien quelques outils qu'on tend à considérer comme des concurrents : les microblogs et autres outils de repost permettent à autrui d'aggréger l'information à votre place, ne vous en laissant que la crème de la crème comme susbtrat à votre vision du monde (ou de la toile). Mais n'est-ce pas là leur plus grand défaut ? Tout l'intérêt que je vois à mes flux, c'est que je les choisis, les prend de divers horizons, que je cherche à conserver un esprit critique sur mes sources d'informations (pas que j'y arrive particulièrement, hein... surtout si on considère que 80% de mes flux concernent les lolcats et les mèmes...). Et puis même pour suivre des microblogs, je passe par des flux.
J'en viens à me demander si ceux qui déclarent RSS comme mort n'y cherchaient pas, à tort, un outil supplémentaire pour faire des sous, et n'y auraient vu qu'un moyen de perdre des visiteurs sur leur site... Bref des gens qui ne veulent pas qu'on leur impose de fournir leurs données sous forme de flux parce que ça n'est pas assez rentable (et qu'on ne me parle pas de feedburner)...
J'en ai probablement oublié des très importants (voir vitaux), mais on va s'arrêter là pour l'instant.
Keep Calm and Rock On.
EDIT : promis, idleman, la prochaine fois je fais plus court... Ah mince, non, je vais devoir présenter Avator, et ça va être dur de faire concis... -__-

mogrify -resize 3.125% *.png
#include <QImage>
#include <QPainter>
#include <QFile>
#include <QDebug>
int main(int argc, char *argv[]) {
const int TILE_SIZE = 64;
// const int TILE_SIZE = 2048;
const int NORTH_SIZE = 14;
const int EAST_SIZE = 33;
const int SOUTH_SIZE = 23;
const int WEST_SIZE = 48;
QImage *resultImage = new QImage(TILE_SIZE * (EAST_SIZE + WEST_SIZE) ,TILE_SIZE * (NORTH_SIZE + SOUTH_SIZE), QImage::Format_ARGB32);
resultImage->fill(Qt::gray);
for(int i=0; i < (EAST_SIZE+WEST_SIZE); i++) {
for(int j=0; j < (NORTH_SIZE+SOUTH_SIZE); j++) {
QString filePath = "thumbs/";
// QString filePath = "images/";
if(j < NORTH_SIZE) {
filePath += QString::number(NORTH_SIZE-j) + "n";
} else {
filePath += QString::number(j-NORTH_SIZE+1) + "s";
}
if(i < EAST_SIZE) {
filePath += QString::number(EAST_SIZE-i) + "w";
} else {
filePath += QString::number(i-EAST_SIZE+1) + "e";
}
filePath += ".png";
QFile imageFile(filePath);
if(imageFile.exists()) {
qDebug() << filePath;
QPainter painter;
painter.begin(resultImage);
painter.drawImage(i*TILE_SIZE, j*TILE_SIZE, QImage(filePath));
painter.end();
}
}
}
resultImage->save("result.png");
}
